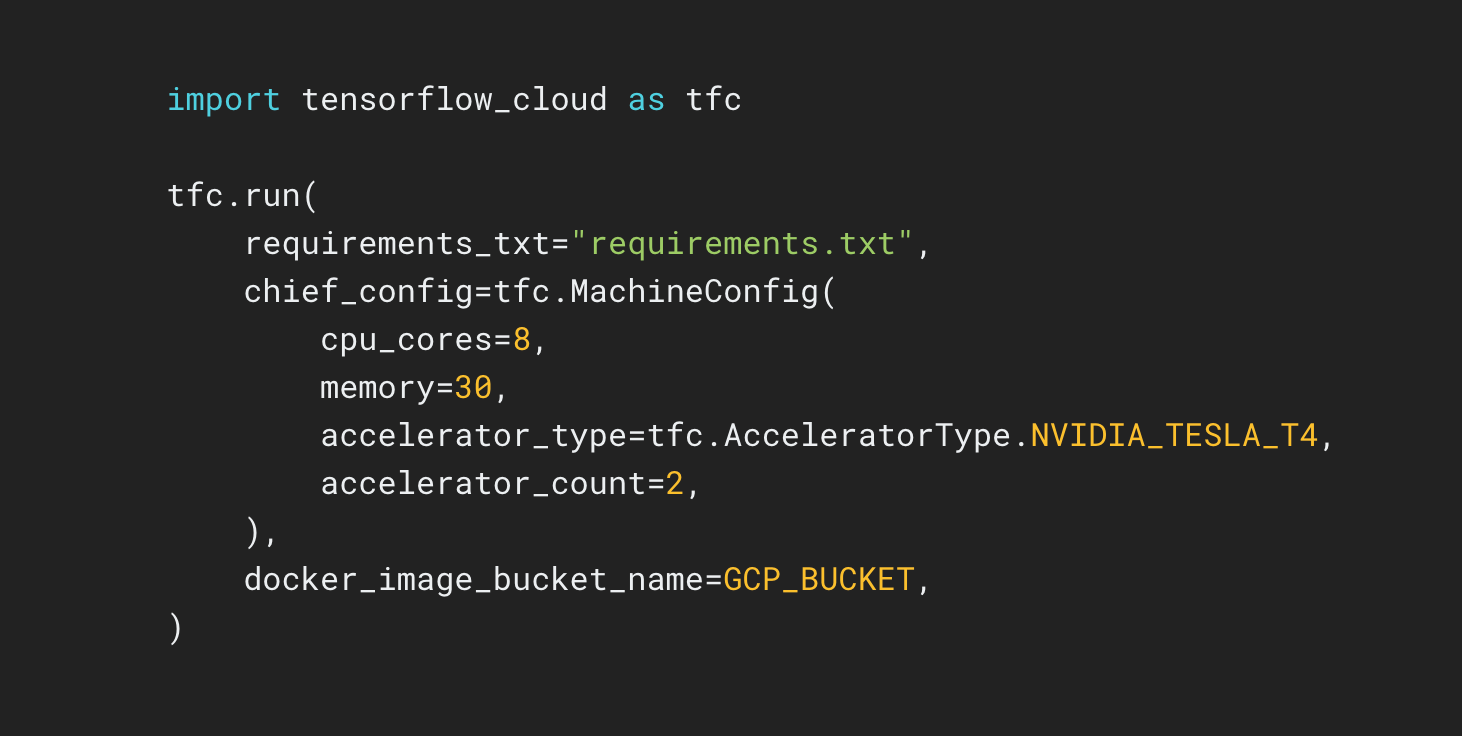
TensorFlow Cloud आपके स्थानीय परिवेश को Google क्लाउड से जोड़ने के लिए एक लाइब्रेरी है।
import tensorflow_cloud as tfc TF_GPU_IMAGE = "tensorflow/tensorflow:latest-gpu" run_parameters = { distribution_strategy='auto', requirements_txt='requirements.txt', docker_config=tfc.DockerConfig( parent_image=TF_GPU_IMAGE, image_build_bucket=GCS_BUCKET ), chief_config=tfc.COMMON_MACHINE_CONFIGS['K80_1X'], worker_config=tfc.COMMON_MACHINE_CONFIGS['K80_1X'], worker_count=3, job_labels={'job': "my_job"} } tfc.run(**run_parameters) # Runs your training on Google Cloud!
TensorFlow क्लाउड रिपॉजिटरी एपीआई प्रदान करता है जो स्थानीय मॉडल निर्माण और डिबगिंग से Google क्लाउड पर वितरित प्रशिक्षण और हाइपरपैरामीटर ट्यूनिंग में संक्रमण को आसान बनाता है। कोलाब या कागल नोटबुक या स्थानीय स्क्रिप्ट फ़ाइल के अंदर से, आप क्लाउड कंसोल का उपयोग किए बिना, अपने मॉडल को सीधे क्लाउड पर ट्यूनिंग या प्रशिक्षण के लिए भेज सकते हैं।