
जानें कि TensorFlow का उपयोग करके जिम्मेदार AI प्रथाओं को अपने ML वर्कफ़्लो में कैसे एकीकृत किया जाए
TensorFlow एमएल समुदाय के साथ संसाधनों और उपकरणों का संग्रह साझा करके AI के जिम्मेदार विकास में प्रगति करने में मदद करने के लिए प्रतिबद्ध है।

जिम्मेदार AI क्या है?
एआई का विकास चुनौतीपूर्ण, वास्तविक दुनिया की समस्याओं को हल करने के लिए नए अवसर पैदा कर रहा है। यह एआई सिस्टम बनाने के सर्वोत्तम तरीके के बारे में नए सवाल भी उठा रहा है जिससे सभी को लाभ होगा।

एआई के लिए अनुशंसित सर्वोत्तम अभ्यास
एआई सिस्टम को डिजाइन करते समय मानव-केंद्रित होते हुए सॉफ्टवेयर विकास की सर्वोत्तम प्रथाओं का पालन करना चाहिए
एमएल के लिए दृष्टिकोण

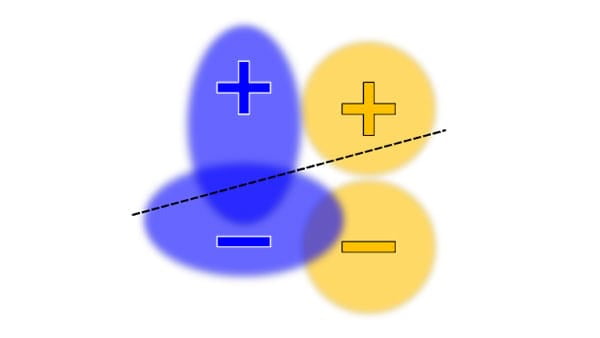
फेयरनेस
जैसे-जैसे एआई का प्रभाव सभी क्षेत्रों और समाजों में बढ़ रहा है, ऐसे सिस्टम की दिशा में काम करना महत्वपूर्ण है जो सभी के लिए निष्पक्ष और समावेशी हो

विवेचनीयता
एआई सिस्टम को समझना और उस पर भरोसा करना यह सुनिश्चित करने के लिए महत्वपूर्ण है कि वे इच्छानुसार काम कर रहे हैं

गोपनीयता
संवेदनशील डेटा से प्रशिक्षण मॉडल को गोपनीयता संरक्षण सुरक्षा उपायों की आवश्यकता होती है

सुरक्षा
संभावित खतरों की पहचान करने से एआई सिस्टम को सुरक्षित रखने में मदद मिल सकती है
आपके एमएल वर्कफ़्लो में जिम्मेदार AI
एमएल वर्कफ़्लो के हर चरण में जिम्मेदार एआई प्रथाओं को शामिल किया जा सकता है। प्रत्येक चरण पर विचार करने के लिए यहां कुछ प्रमुख प्रश्न दिए गए हैं।
मेरा एमएल सिस्टम किसके लिए है?
जिस तरह से वास्तविक उपयोगकर्ता आपके सिस्टम का अनुभव करते हैं, वह इसकी भविष्यवाणियों, सिफारिशों और निर्णयों के वास्तविक प्रभाव का आकलन करने के लिए आवश्यक है। अपनी विकास प्रक्रिया के प्रारंभ में ही विभिन्न प्रकार के उपयोगकर्ताओं से इनपुट प्राप्त करना सुनिश्चित करें।
क्या मैं एक प्रतिनिधि डेटासेट का उपयोग कर रहा हूँ?
क्या आपका डेटा इस तरह से नमूना किया गया है जो आपके उपयोगकर्ताओं का प्रतिनिधित्व करता है (उदाहरण के लिए सभी उम्र के लिए उपयोग किया जाएगा, लेकिन आपके पास केवल वरिष्ठ नागरिकों का प्रशिक्षण डेटा है) और वास्तविक दुनिया सेटिंग (उदाहरण के लिए वर्ष भर उपयोग किया जाएगा, लेकिन आपके पास केवल प्रशिक्षण है) गर्मियों से डेटा)?
क्या मेरे डेटा में वास्तविक दुनिया/मानवीय पूर्वाग्रह है?
डेटा में अंतर्निहित पूर्वाग्रह जटिल फीडबैक लूप में योगदान कर सकते हैं जो मौजूदा रूढ़िवादिता को सुदृढ़ करते हैं।
मुझे अपने मॉडल को प्रशिक्षित करने के लिए किन तरीकों का उपयोग करना चाहिए?
प्रशिक्षण विधियों का उपयोग करें जो मॉडल में निष्पक्षता, व्याख्यात्मकता, गोपनीयता और सुरक्षा का निर्माण करें।
मेरा मॉडल कैसा प्रदर्शन कर रहा है?
उपयोगकर्ताओं, उपयोग के मामलों और उपयोग के संदर्भों के व्यापक स्पेक्ट्रम में वास्तविक दुनिया के परिदृश्यों में उपयोगकर्ता अनुभव का मूल्यांकन करें। पहले डॉगफ़ूड में परीक्षण करें और पुनरावृति करें, इसके बाद लॉन्च के बाद परीक्षण जारी रखें।
क्या जटिल फीडबैक लूप हैं?
भले ही समग्र सिस्टम डिज़ाइन में सब कुछ सावधानी से तैयार किया गया हो, वास्तविक, लाइव डेटा पर लागू होने पर एमएल-आधारित मॉडल शायद ही कभी 100% पूर्णता के साथ काम करते हैं। जब किसी लाइव उत्पाद में कोई समस्या आती है, तो विचार करें कि क्या यह किसी मौजूदा सामाजिक नुकसान के साथ संरेखित है, और यह अल्पकालिक और दीर्घकालिक समाधानों से कैसे प्रभावित होगा।
TensorFlow के लिए जिम्मेदार AI उपकरण
उपरोक्त कुछ प्रश्नों से निपटने में सहायता के लिए TensorFlow पारिस्थितिकी तंत्र के पास उपकरणों और संसाधनों का एक सेट है।
समस्या को परिभाषित करें
रिस्पॉन्सिबल एआई को ध्यान में रखकर मॉडल डिजाइन करने के लिए निम्नलिखित संसाधनों का उपयोग करें।

एआई विकास प्रक्रिया और प्रमुख विचारों के बारे में और जानें।
रिस्पॉन्सिबल एआई के क्षेत्र में इंटरैक्टिव विज़ुअलाइज़ेशन, प्रमुख प्रश्नों और अवधारणाओं के माध्यम से अन्वेषण करें।
डेटा बनाना और तैयार करना
संभावित पूर्वाग्रहों के लिए डेटा की जांच करने के लिए निम्नलिखित टूल का उपयोग करें।
डेटा की गुणवत्ता में सुधार करने और निष्पक्षता और पूर्वाग्रह के मुद्दों को कम करने के लिए अपने डेटासेट की इंटरैक्टिव जांच करें।
समस्याओं का पता लगाने और अधिक प्रभावी फीचर सेट इंजीनियर करने के लिए डेटा का विश्लेषण और परिवर्तन करें।


आपके डेटा संग्रह और मॉडल निर्माण की ज़रूरतों को और अधिक मजबूत और समावेशी बनाने के लिए एक अधिक समावेशी स्किन टोन स्केल, ओपन लाइसेंस प्राप्त।
मॉडल बनाएं और प्रशिक्षित करें
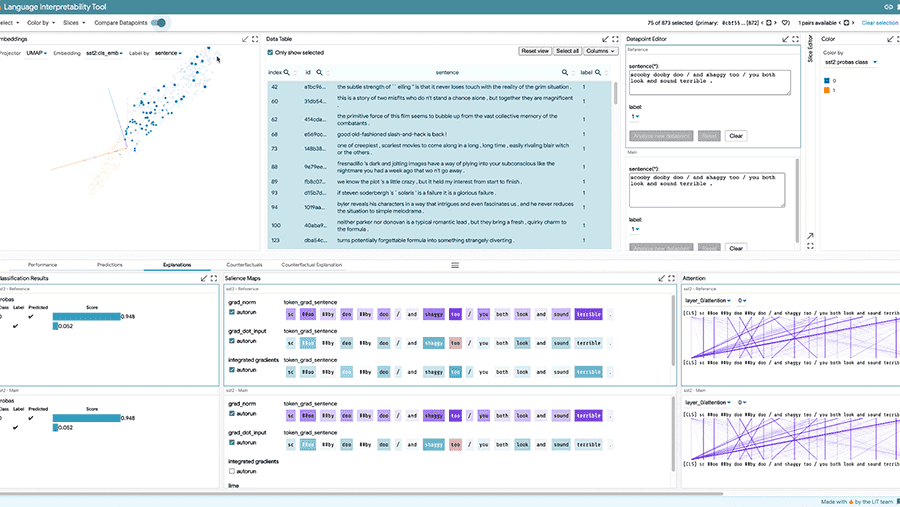
गोपनीयता-संरक्षण, व्याख्यात्मक तकनीकों और अधिक का उपयोग करके मॉडल को प्रशिक्षित करने के लिए निम्नलिखित टूल का उपयोग करें।

अधिक न्यायसंगत परिणामों को बढ़ावा देने के लिए मशीन लर्निंग मॉडल को प्रशिक्षित करें।
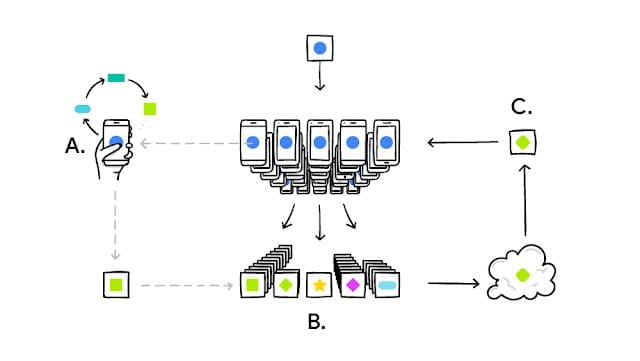
फ़ेडरेटेड शिक्षण तकनीकों का उपयोग करके मशीन लर्निंग मॉडल को प्रशिक्षित करें।
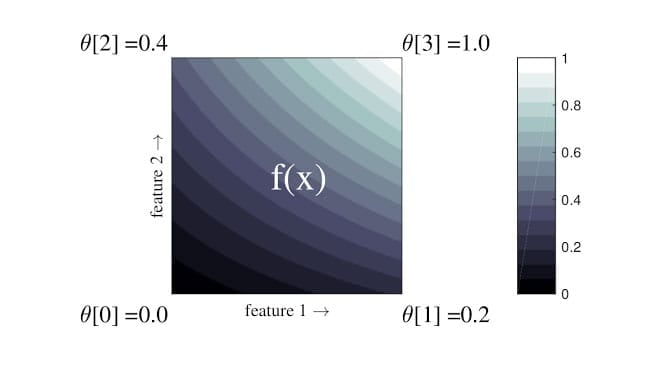
मॉडल का मूल्यांकन करें
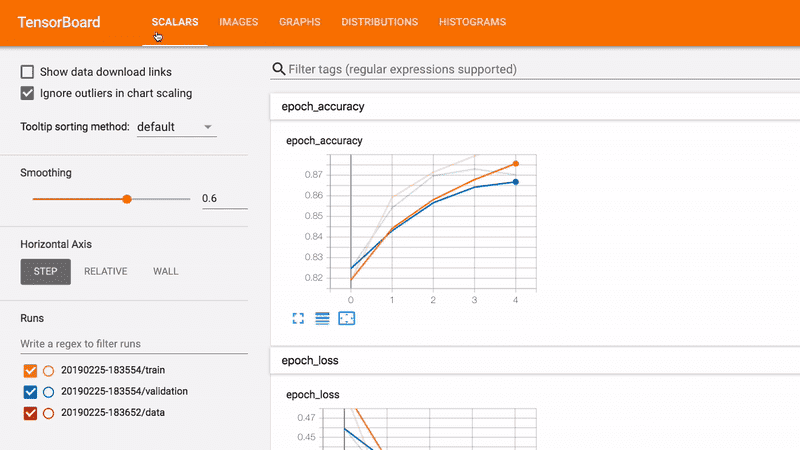
निम्नलिखित टूल का उपयोग करके मॉडल प्रदर्शन को डीबग करें, मूल्यांकन करें और विज़ुअलाइज़ करें।
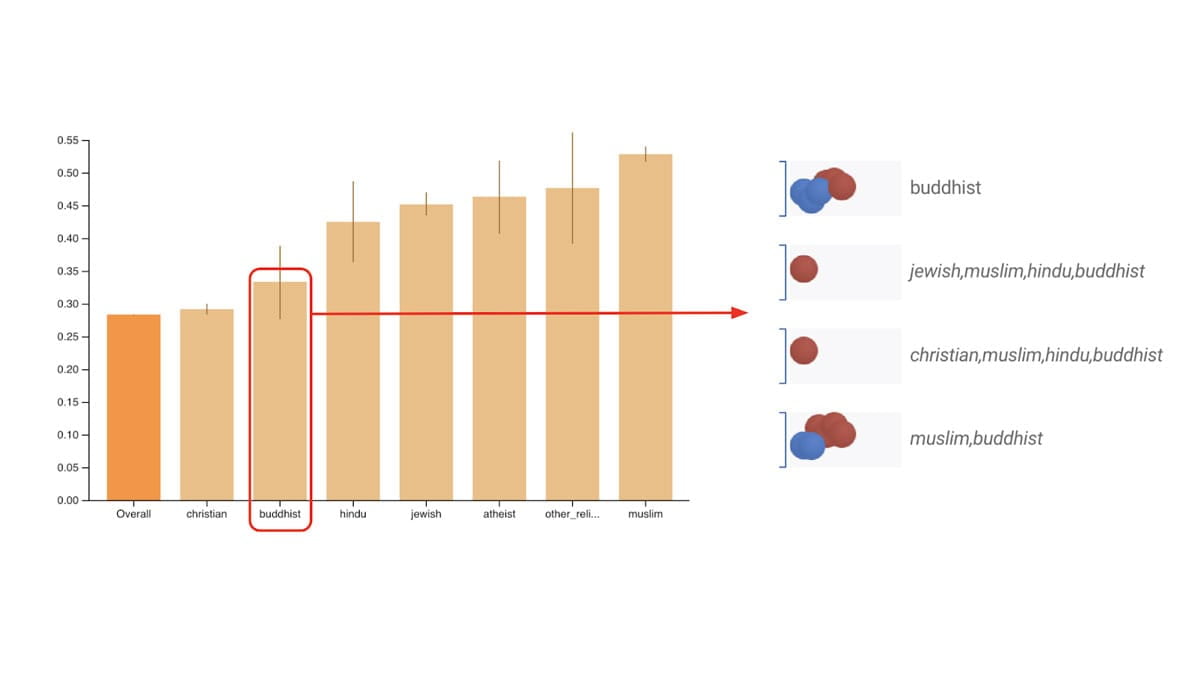
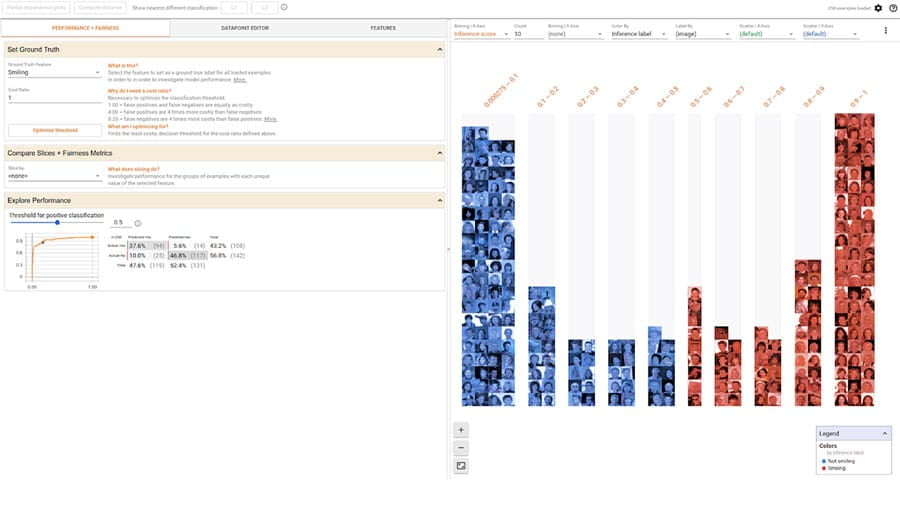
बाइनरी और मल्टी-क्लास क्लासिफायर के लिए सामान्य रूप से पहचाने जाने वाले निष्पक्षता मेट्रिक्स का मूल्यांकन करें।
वितरित तरीके से मॉडलों का मूल्यांकन करें और डेटा के विभिन्न स्लाइसों पर गणना करें।
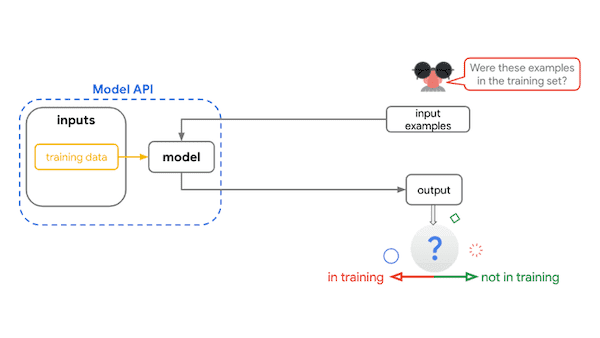
तैनात करें और निगरानी करें
मॉडल संदर्भ और विवरण के बारे में ट्रैक करने और संचार करने के लिए निम्नलिखित टूल का उपयोग करें।
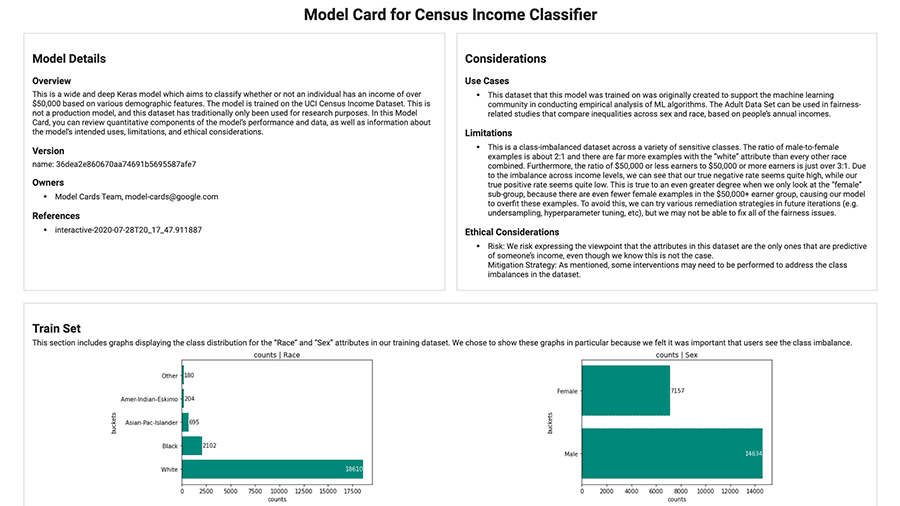

एमएल डेवलपर और डेटा वैज्ञानिक वर्कफ़्लो से जुड़े मेटाडेटा को रिकॉर्ड करें और पुनः प्राप्त करें।

सामूहिक संसाधन
जानें कि समुदाय क्या कर रहा है और इसमें शामिल होने के तरीके तलाशें।

Google के उत्पादों को अधिक समावेशी और आपकी भाषा, क्षेत्र और संस्कृति का प्रतिनिधि बनने में सहायता करें।

हमने प्रतिभागियों से जिम्मेदार AI सिद्धांतों को ध्यान में रखते हुए एक मॉडल या एप्लिकेशन बनाने के लिए TensorFlow 2.2 का उपयोग करने के लिए कहा। विजेताओं और अन्य अद्भुत परियोजनाओं को देखने के लिए गैलरी देखें।

एमएल, निष्पक्षता और गोपनीयता के बारे में सोचने के लिए एक रूपरेखा का परिचय।
जानें कि TensorFlow का उपयोग करके जिम्मेदार AI प्रथाओं को अपने ML वर्कफ़्लो में कैसे एकीकृत किया जाए
TensorFlow एमएल समुदाय के साथ संसाधनों और उपकरणों का संग्रह साझा करके AI के जिम्मेदार विकास में प्रगति करने में मदद करने के लिए प्रतिबद्ध है।
जिम्मेदार AI क्या है?
एआई का विकास चुनौतीपूर्ण, वास्तविक दुनिया की समस्याओं को हल करने के लिए नए अवसर पैदा कर रहा है। यह एआई सिस्टम बनाने के सर्वोत्तम तरीके के बारे में नए सवाल भी उठा रहा है जिससे सभी को लाभ होगा।
एआई के लिए अनुशंसित सर्वोत्तम अभ्यास
एआई सिस्टम को डिजाइन करते समय मानव-केंद्रित होते हुए सॉफ्टवेयर विकास की सर्वोत्तम प्रथाओं का पालन करना चाहिए
एमएल के लिए दृष्टिकोण
फेयरनेस
जैसे-जैसे एआई का प्रभाव सभी क्षेत्रों और समाजों में बढ़ रहा है, ऐसे सिस्टम की दिशा में काम करना महत्वपूर्ण है जो सभी के लिए निष्पक्ष और समावेशी हो
विवेचनीयता
एआई सिस्टम को समझना और उस पर भरोसा करना यह सुनिश्चित करने के लिए महत्वपूर्ण है कि वे इच्छानुसार काम कर रहे हैं
गोपनीयता
संवेदनशील डेटा से प्रशिक्षण मॉडल को गोपनीयता संरक्षण सुरक्षा उपायों की आवश्यकता होती है
सुरक्षा
संभावित खतरों की पहचान करने से एआई सिस्टम को सुरक्षित रखने में मदद मिल सकती है
आपके एमएल वर्कफ़्लो में जिम्मेदार AI
एमएल वर्कफ़्लो के हर चरण में जिम्मेदार एआई प्रथाओं को शामिल किया जा सकता है। प्रत्येक चरण पर विचार करने के लिए यहां कुछ प्रमुख प्रश्न दिए गए हैं।
मेरा एमएल सिस्टम किसके लिए है?
जिस तरह से वास्तविक उपयोगकर्ता आपके सिस्टम का अनुभव करते हैं, वह इसकी भविष्यवाणियों, सिफारिशों और निर्णयों के वास्तविक प्रभाव का आकलन करने के लिए आवश्यक है। अपनी विकास प्रक्रिया के प्रारंभ में ही विभिन्न प्रकार के उपयोगकर्ताओं से इनपुट प्राप्त करना सुनिश्चित करें।
क्या मैं एक प्रतिनिधि डेटासेट का उपयोग कर रहा हूँ?
क्या आपका डेटा इस तरह से नमूना किया गया है जो आपके उपयोगकर्ताओं का प्रतिनिधित्व करता है (उदाहरण के लिए सभी उम्र के लिए उपयोग किया जाएगा, लेकिन आपके पास केवल वरिष्ठ नागरिकों का प्रशिक्षण डेटा है) और वास्तविक दुनिया सेटिंग (उदाहरण के लिए वर्ष भर उपयोग किया जाएगा, लेकिन आपके पास केवल प्रशिक्षण है) गर्मियों से डेटा)?
क्या मेरे डेटा में वास्तविक दुनिया/मानवीय पूर्वाग्रह है?
डेटा में अंतर्निहित पूर्वाग्रह जटिल फीडबैक लूप में योगदान कर सकते हैं जो मौजूदा रूढ़िवादिता को सुदृढ़ करते हैं।
मुझे अपने मॉडल को प्रशिक्षित करने के लिए किन तरीकों का उपयोग करना चाहिए?
प्रशिक्षण विधियों का उपयोग करें जो मॉडल में निष्पक्षता, व्याख्यात्मकता, गोपनीयता और सुरक्षा का निर्माण करें।
मेरा मॉडल कैसा प्रदर्शन कर रहा है?
उपयोगकर्ताओं, उपयोग के मामलों और उपयोग के संदर्भों के व्यापक स्पेक्ट्रम में वास्तविक दुनिया के परिदृश्यों में उपयोगकर्ता अनुभव का मूल्यांकन करें। पहले डॉगफ़ूड में परीक्षण करें और पुनरावृति करें, इसके बाद लॉन्च के बाद परीक्षण जारी रखें।
क्या जटिल फीडबैक लूप हैं?
भले ही समग्र सिस्टम डिज़ाइन में सब कुछ सावधानी से तैयार किया गया हो, वास्तविक, लाइव डेटा पर लागू होने पर एमएल-आधारित मॉडल शायद ही कभी 100% पूर्णता के साथ काम करते हैं। जब किसी लाइव उत्पाद में कोई समस्या आती है, तो विचार करें कि क्या यह किसी मौजूदा सामाजिक नुकसान के साथ संरेखित है, और यह अल्पकालिक और दीर्घकालिक समाधानों से कैसे प्रभावित होगा।
TensorFlow के लिए जिम्मेदार AI उपकरण
उपरोक्त कुछ प्रश्नों से निपटने में सहायता के लिए TensorFlow पारिस्थितिकी तंत्र के पास उपकरणों और संसाधनों का एक सेट है।
समस्या को परिभाषित करें
रिस्पॉन्सिबल एआई को ध्यान में रखकर मॉडल डिजाइन करने के लिए निम्नलिखित संसाधनों का उपयोग करें।
एआई विकास प्रक्रिया और प्रमुख विचारों के बारे में और जानें।
रिस्पॉन्सिबल एआई के क्षेत्र में इंटरैक्टिव विज़ुअलाइज़ेशन, प्रमुख प्रश्नों और अवधारणाओं के माध्यम से अन्वेषण करें।
डेटा बनाना और तैयार करना
संभावित पूर्वाग्रहों के लिए डेटा की जांच करने के लिए निम्नलिखित टूल का उपयोग करें।
डेटा की गुणवत्ता में सुधार करने और निष्पक्षता और पूर्वाग्रह के मुद्दों को कम करने के लिए अपने डेटासेट की इंटरैक्टिव जांच करें।
समस्याओं का पता लगाने और अधिक प्रभावी फीचर सेट इंजीनियर करने के लिए डेटा का विश्लेषण और परिवर्तन करें।
आपके डेटा संग्रह और मॉडल निर्माण की ज़रूरतों को और अधिक मजबूत और समावेशी बनाने के लिए एक अधिक समावेशी स्किन टोन स्केल, ओपन लाइसेंस प्राप्त।
मॉडल बनाएं और प्रशिक्षित करें
गोपनीयता-संरक्षण, व्याख्यात्मक तकनीकों और अधिक का उपयोग करके मॉडल को प्रशिक्षित करने के लिए निम्नलिखित टूल का उपयोग करें।
अधिक न्यायसंगत परिणामों को बढ़ावा देने के लिए मशीन लर्निंग मॉडल को प्रशिक्षित करें।
फ़ेडरेटेड शिक्षण तकनीकों का उपयोग करके मशीन लर्निंग मॉडल को प्रशिक्षित करें।
मॉडल का मूल्यांकन करें
निम्नलिखित टूल का उपयोग करके मॉडल प्रदर्शन को डीबग करें, मूल्यांकन करें और विज़ुअलाइज़ करें।
बाइनरी और मल्टी-क्लास क्लासिफायर के लिए सामान्य रूप से पहचाने जाने वाले निष्पक्षता मेट्रिक्स का मूल्यांकन करें।
वितरित तरीके से मॉडलों का मूल्यांकन करें और डेटा के विभिन्न स्लाइसों पर गणना करें।
तैनात करें और निगरानी करें
मॉडल संदर्भ और विवरण के बारे में ट्रैक करने और संचार करने के लिए निम्नलिखित टूल का उपयोग करें।
एमएल डेवलपर और डेटा वैज्ञानिक वर्कफ़्लो से जुड़े मेटाडेटा को रिकॉर्ड करें और पुनः प्राप्त करें।
सामूहिक संसाधन
जानें कि समुदाय क्या कर रहा है और इसमें शामिल होने के तरीके तलाशें।
Google के उत्पादों को अधिक समावेशी और आपकी भाषा, क्षेत्र और संस्कृति का प्रतिनिधि बनने में सहायता करें।
हमने प्रतिभागियों से जिम्मेदार AI सिद्धांतों को ध्यान में रखते हुए एक मॉडल या एप्लिकेशन बनाने के लिए TensorFlow 2.2 का उपयोग करने के लिए कहा। विजेताओं और अन्य अद्भुत परियोजनाओं को देखने के लिए गैलरी देखें।
एमएल, निष्पक्षता और गोपनीयता के बारे में सोचने के लिए एक रूपरेखा का परिचय।