
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
मशीन लर्निंग में, किसी चीज़ को बेहतर बनाने के लिए आपको अक्सर उसे मापने में सक्षम होने की आवश्यकता होती है। TensorBoard मशीन लर्निंग वर्कफ़्लो के दौरान आवश्यक माप और विज़ुअलाइज़ेशन प्रदान करने के लिए एक उपकरण है। यह हानि और सटीकता जैसे प्रयोग मेट्रिक्स को ट्रैक करने में सक्षम बनाता है, मॉडल ग्राफ़ की कल्पना करता है, एम्बेडिंग को कम आयामी स्थान पर प्रोजेक्ट करता है, और बहुत कुछ।
यह क्विकस्टार्ट दिखाएगा कि कैसे जल्दी से TensorBoard के साथ शुरुआत करें। इस वेबसाइट की शेष मार्गदर्शिकाएँ विशिष्ट क्षमताओं के बारे में अधिक विवरण प्रदान करती हैं, जिनमें से कई यहाँ शामिल नहीं हैं।
# Load the TensorBoard notebook extension
%load_ext tensorboard
import tensorflow as tf
import datetime
# Clear any logs from previous runsrm -rf ./logs/
का उपयोग करते हुए MNIST उदाहरण के रूप में डाटासेट, डेटा सामान्य और एक समारोह है कि 10 वर्गों में छवियों को वर्गीकृत करने के लिए एक सरल Keras मॉडल बनाता है लिखें।
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
def create_model():
return tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 11493376/11490434 [==============================] - 0s 0us/step
Keras Model.fit () के साथ TensorBoard का उपयोग करना
जब Keras के साथ प्रशिक्षण Model.fit () , जोड़ने tf.keras.callbacks.TensorBoard कॉलबैक सुनिश्चित है कि लॉग बनाया है और जमा हो जाती है। इसके अतिरिक्त, सक्षम हिस्टोग्राम गणना हर युग के साथ histogram_freq=1 (यह डिफ़ॉल्ट रूप से बंद है)
विभिन्न प्रशिक्षण रन के आसान चयन की अनुमति देने के लिए लॉग को टाइमस्टैम्प्ड उपनिर्देशिका में रखें।
model = create_model()
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
log_dir = "logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
model.fit(x=x_train,
y=y_train,
epochs=5,
validation_data=(x_test, y_test),
callbacks=[tensorboard_callback])
Train on 60000 samples, validate on 10000 samples Epoch 1/5 60000/60000 [==============================] - 15s 246us/sample - loss: 0.2217 - accuracy: 0.9343 - val_loss: 0.1019 - val_accuracy: 0.9685 Epoch 2/5 60000/60000 [==============================] - 14s 229us/sample - loss: 0.0975 - accuracy: 0.9698 - val_loss: 0.0787 - val_accuracy: 0.9758 Epoch 3/5 60000/60000 [==============================] - 14s 231us/sample - loss: 0.0718 - accuracy: 0.9771 - val_loss: 0.0698 - val_accuracy: 0.9781 Epoch 4/5 60000/60000 [==============================] - 14s 227us/sample - loss: 0.0540 - accuracy: 0.9820 - val_loss: 0.0685 - val_accuracy: 0.9795 Epoch 5/5 60000/60000 [==============================] - 14s 228us/sample - loss: 0.0433 - accuracy: 0.9862 - val_loss: 0.0623 - val_accuracy: 0.9823 <tensorflow.python.keras.callbacks.History at 0x7fc8a5ee02e8>
TensorBoard को कमांड लाइन के माध्यम से या नोटबुक अनुभव के भीतर प्रारंभ करें। दो इंटरफेस आम तौर पर समान होते हैं। नोटबुक में, का उपयोग %tensorboard लाइन जादू। कमांड लाइन पर, "%" के बिना समान कमांड चलाएँ।
%tensorboard --logdir logs/fit
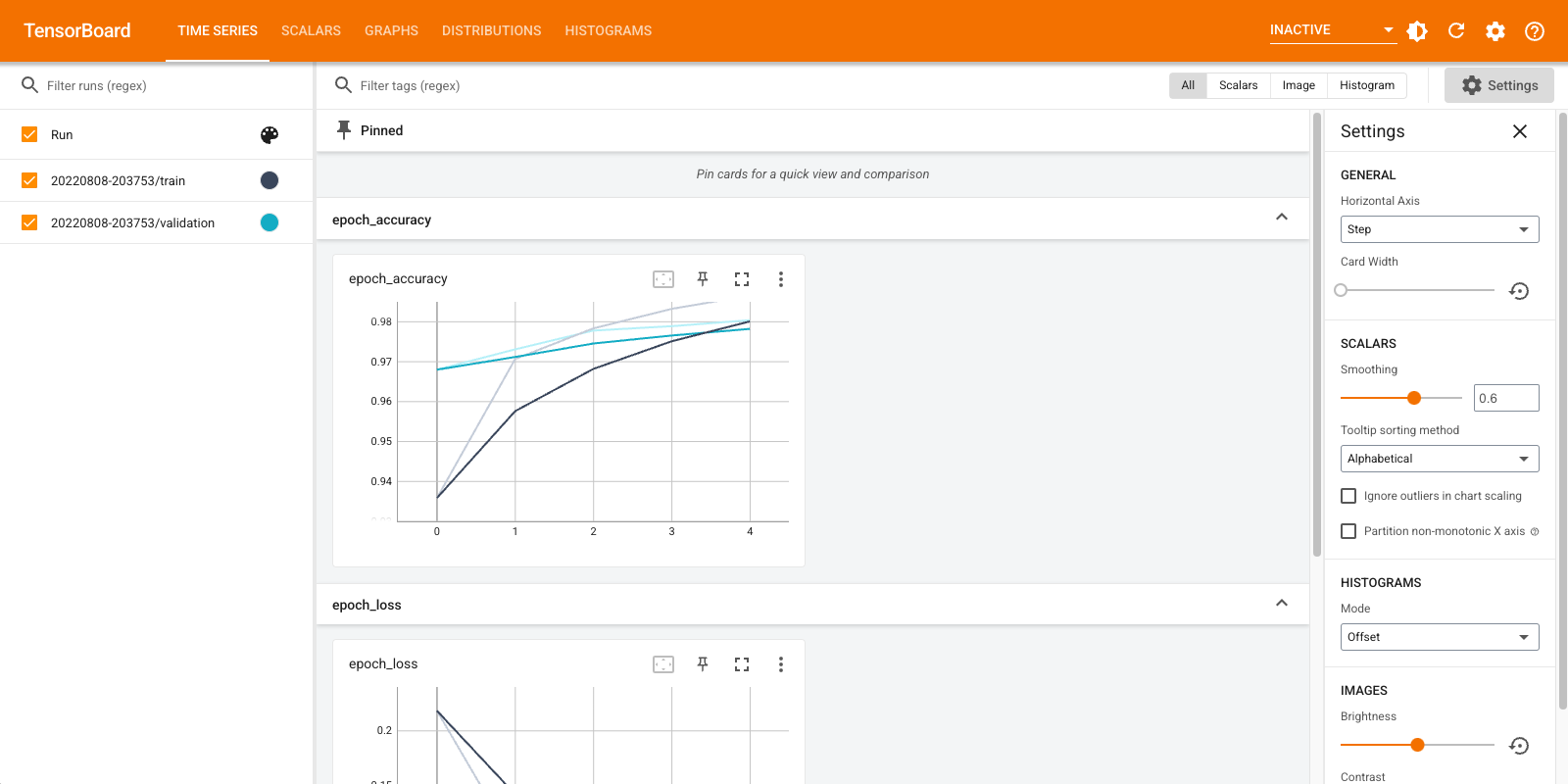
दिखाए गए डैशबोर्ड का संक्षिप्त अवलोकन (शीर्ष नेविगेशन बार में टैब):
- Scalars डैशबोर्ड से पता चलता है कि कैसे नुकसान और मीट्रिक हर युग के साथ बदल जाते हैं। आप इसका उपयोग प्रशिक्षण गति, सीखने की दर और अन्य अदिश मूल्यों को ट्रैक करने के लिए भी कर सकते हैं।
- रेखांकन डैशबोर्ड आप अपने मॉडल कल्पना में मदद करता है। इस मामले में, परतों का केरस ग्राफ दिखाया गया है जो यह सुनिश्चित करने में आपकी सहायता कर सकता है कि यह सही ढंग से बनाया गया है।
- वितरण और हिस्टोग्राम डैशबोर्ड्स समय के साथ एक टेन्सर का वितरण दिखा। यह वज़न और पूर्वाग्रहों की कल्पना करने और यह सत्यापित करने के लिए उपयोगी हो सकता है कि वे अपेक्षित तरीके से बदल रहे हैं।
जब आप अन्य प्रकार के डेटा लॉग करते हैं तो अतिरिक्त TensorBoard प्लगइन्स स्वचालित रूप से सक्षम हो जाते हैं। उदाहरण के लिए, Keras TensorBoard कॉलबैक आपको छवियों और एम्बेडिंग को भी लॉग करने देता है। आप ऊपर दाईं ओर "निष्क्रिय" ड्रॉपडाउन पर क्लिक करके देख सकते हैं कि TensorBoard में अन्य कौन से प्लगइन्स उपलब्ध हैं।
अन्य विधियों के साथ TensorBoard का उपयोग करना
जब इस तरह के रूप तरीकों के साथ प्रशिक्षण tf.GradientTape() , उपयोग tf.summary आवश्यक जानकारी लॉग इन करने की।
करने के लिए ऊपर के रूप में ही डाटासेट का उपयोग करें, लेकिन यह परिवर्तित tf.data.Dataset क्षमताओं batching का लाभ लेने के:
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
train_dataset = train_dataset.shuffle(60000).batch(64)
test_dataset = test_dataset.batch(64)
प्रशिक्षण कोड इस प्रकार उन्नत त्वरित प्रारंभ ट्यूटोरियल है, लेकिन शो कैसे TensorBoard मेट्रिक लॉग इन करें। हानि और अनुकूलक चुनें:
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
optimizer = tf.keras.optimizers.Adam()
स्टेटफुल मेट्रिक्स बनाएं जिनका उपयोग प्रशिक्षण के दौरान मूल्यों को संचित करने और किसी भी समय लॉग इन करने के लिए किया जा सकता है:
# Define our metrics
train_loss = tf.keras.metrics.Mean('train_loss', dtype=tf.float32)
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('train_accuracy')
test_loss = tf.keras.metrics.Mean('test_loss', dtype=tf.float32)
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('test_accuracy')
प्रशिक्षण और परीक्षण कार्यों को परिभाषित करें:
def train_step(model, optimizer, x_train, y_train):
with tf.GradientTape() as tape:
predictions = model(x_train, training=True)
loss = loss_object(y_train, predictions)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
train_loss(loss)
train_accuracy(y_train, predictions)
def test_step(model, x_test, y_test):
predictions = model(x_test)
loss = loss_object(y_test, predictions)
test_loss(loss)
test_accuracy(y_test, predictions)
एक अलग लॉग निर्देशिका में डिस्क को सारांश लिखने के लिए सारांश लेखकों को सेट करें:
current_time = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
train_log_dir = 'logs/gradient_tape/' + current_time + '/train'
test_log_dir = 'logs/gradient_tape/' + current_time + '/test'
train_summary_writer = tf.summary.create_file_writer(train_log_dir)
test_summary_writer = tf.summary.create_file_writer(test_log_dir)
प्रशिक्षण शुरू करो। का प्रयोग करें tf.summary.scalar() / प्रशिक्षण के दौरान मैट्रिक्स (नुकसान और सटीकता) लॉग इन करने के सारांश लेखकों के दायरे के भीतर परीक्षण डिस्क पर सारांश लिखने के लिए। आपके पास इस पर नियंत्रण होता है कि किस मीट्रिक को लॉग करना है और इसे कितनी बार करना है। अन्य tf.summary कार्यों अन्य प्रकार का डेटा प्रवेश करने सक्षम करें।
model = create_model() # reset our model
EPOCHS = 5
for epoch in range(EPOCHS):
for (x_train, y_train) in train_dataset:
train_step(model, optimizer, x_train, y_train)
with train_summary_writer.as_default():
tf.summary.scalar('loss', train_loss.result(), step=epoch)
tf.summary.scalar('accuracy', train_accuracy.result(), step=epoch)
for (x_test, y_test) in test_dataset:
test_step(model, x_test, y_test)
with test_summary_writer.as_default():
tf.summary.scalar('loss', test_loss.result(), step=epoch)
tf.summary.scalar('accuracy', test_accuracy.result(), step=epoch)
template = 'Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, Test Accuracy: {}'
print (template.format(epoch+1,
train_loss.result(),
train_accuracy.result()*100,
test_loss.result(),
test_accuracy.result()*100))
# Reset metrics every epoch
train_loss.reset_states()
test_loss.reset_states()
train_accuracy.reset_states()
test_accuracy.reset_states()
Epoch 1, Loss: 0.24321186542510986, Accuracy: 92.84333801269531, Test Loss: 0.13006582856178284, Test Accuracy: 95.9000015258789 Epoch 2, Loss: 0.10446818172931671, Accuracy: 96.84833526611328, Test Loss: 0.08867532759904861, Test Accuracy: 97.1199951171875 Epoch 3, Loss: 0.07096975296735764, Accuracy: 97.80166625976562, Test Loss: 0.07875105738639832, Test Accuracy: 97.48999786376953 Epoch 4, Loss: 0.05380449816584587, Accuracy: 98.34166717529297, Test Loss: 0.07712937891483307, Test Accuracy: 97.56999969482422 Epoch 5, Loss: 0.041443776339292526, Accuracy: 98.71833038330078, Test Loss: 0.07514958828687668, Test Accuracy: 97.5
TensorBoard को फिर से खोलें, इस बार इसे नई लॉग निर्देशिका पर इंगित करें। हम TensorBoard को भी शुरू कर सकते थे ताकि प्रशिक्षण की प्रगति की निगरानी की जा सके।
%tensorboard --logdir logs/gradient_tape
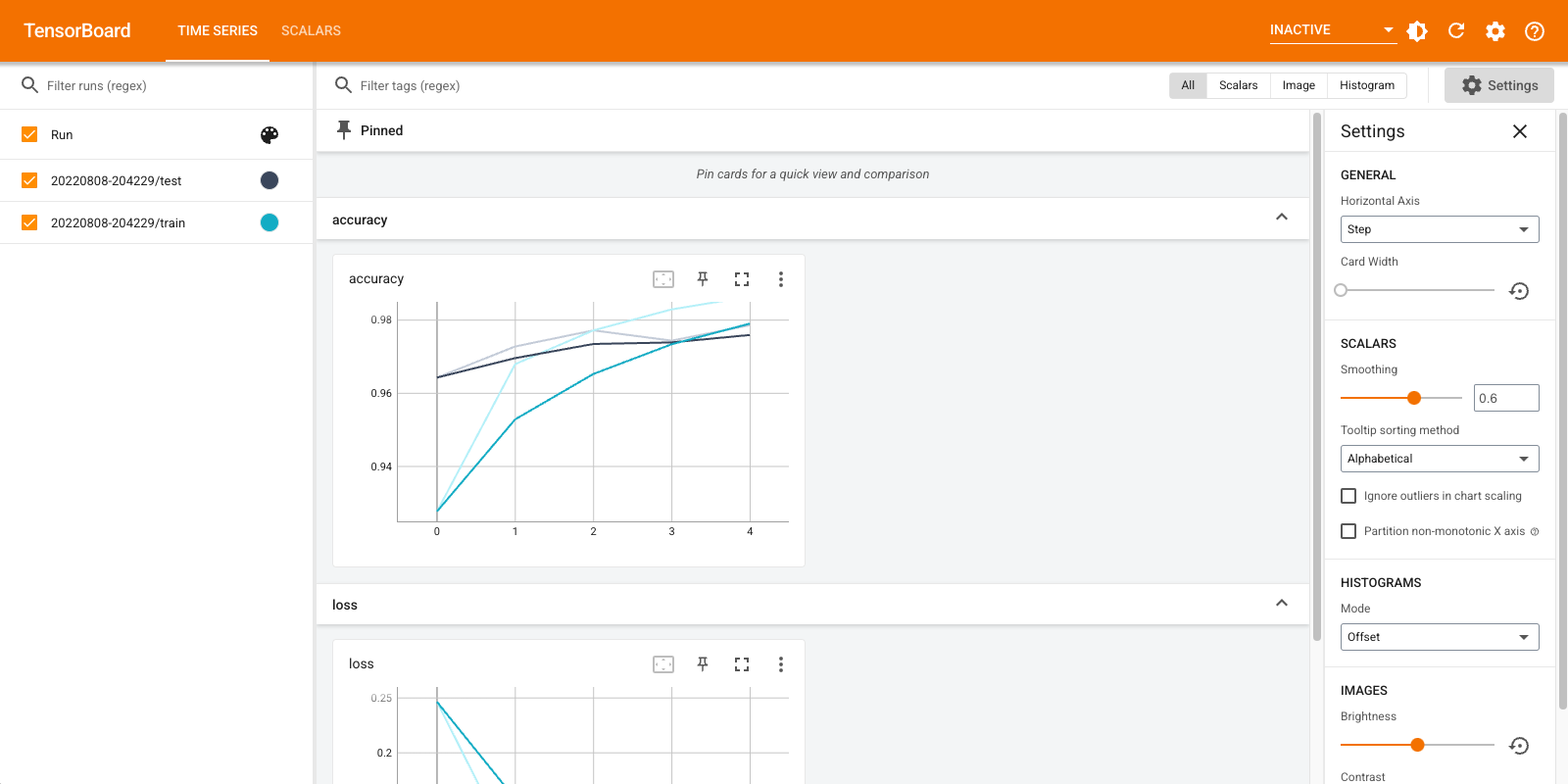
इतना ही! अब आप को देखा है दोनों Keras कॉलबैक के माध्यम से और के माध्यम से TensorBoard उपयोग करने के लिए कैसे tf.summary अधिक कस्टम परिदृश्यों के लिए।
TensorBoard.dev: अपने ML प्रयोग परिणामों को होस्ट और साझा करें
TensorBoard.dev एक नि: शुल्क सार्वजनिक सेवा है कि आप अपने TensorBoard लॉग अपलोड और एक स्थायी लिंक है कि शैक्षिक पेपर में हर कोई, ब्लॉग पोस्ट, सामाजिक मीडिया, आदि यह बेहतर reproducibility और सहयोग सक्षम कर सकते हैं के साथ साझा किया जा सकता प्राप्त करने के लिए सक्षम बनाता है।
TensorBoard.dev का उपयोग करने के लिए, निम्न आदेश चलाएँ:
!tensorboard dev upload \
--logdir logs/fit \
--name "(optional) My latest experiment" \
--description "(optional) Simple comparison of several hyperparameters" \
--one_shot
ध्यान दें कि यह मंगलाचरण विस्मयादिबोधक उपसर्ग का उपयोग करता है ( ! ) खोल के बजाय प्रतिशत उपसर्ग (आह्वान करने के लिए % ) colab जादू आह्वान करने के लिए। कमांड लाइन से इस कमांड को लागू करते समय किसी भी उपसर्ग की आवश्यकता नहीं होती है।
एक उदाहरण देखें यहाँ ।
कैसे TensorBoard.dev का उपयोग करने के बारे में अधिक जानकारी के लिए, देखें https://tensorboard.dev/#get-started