
एक बार जब आपका डेटा टीएफएक्स पाइपलाइन में होता है, तो आप इसका विश्लेषण और परिवर्तन करने के लिए टीएफएक्स घटकों का उपयोग कर सकते हैं। आप किसी मॉडल को प्रशिक्षित करने से पहले भी इन उपकरणों का उपयोग कर सकते हैं।
आपके डेटा का विश्लेषण और परिवर्तन करने के कई कारण हैं:
- अपने डेटा में समस्याओं का पता लगाने के लिए. सामान्य समस्याओं में शामिल हैं:
- गुम डेटा, जैसे खाली मान वाली सुविधाएँ।
- लेबल को सुविधाओं के रूप में माना जाता है, ताकि आपके मॉडल को प्रशिक्षण के दौरान सही उत्तर देखने को मिले।
- आपकी अपेक्षित सीमा से बाहर के मानों वाली विशेषताएँ।
- डेटा विसंगतियाँ.
- ट्रांसफर सीखे गए मॉडल में प्रीप्रोसेसिंग होती है जो प्रशिक्षण डेटा से मेल नहीं खाती है।
- अधिक प्रभावी फीचर सेट इंजीनियर करने के लिए। उदाहरण के लिए, आप पहचान सकते हैं:
- विशेष रूप से जानकारीपूर्ण विशेषताएं.
- निरर्थक विशेषताएँ.
- विशेषताएं जो पैमाने में इतनी व्यापक रूप से भिन्न होती हैं कि वे सीखने को धीमा कर सकती हैं।
- बहुत कम या कोई अद्वितीय पूर्वानुमानित जानकारी वाली विशेषताएँ।
टीएफएक्स उपकरण डेटा बग ढूंढने और फीचर इंजीनियरिंग में मदद कर सकते हैं।
टेंसरफ़्लो डेटा सत्यापन
सिंहावलोकन
TensorFlow डेटा सत्यापन प्रशिक्षण और डेटा परोसने में विसंगतियों की पहचान करता है, और डेटा की जांच करके स्वचालित रूप से एक स्कीमा बना सकता है। डेटा में विसंगतियों के विभिन्न वर्गों का पता लगाने के लिए घटक को कॉन्फ़िगर किया जा सकता है। यह
- उपयोगकर्ता की अपेक्षाओं को संहिताबद्ध करने वाली स्कीमा के विरुद्ध डेटा आंकड़ों की तुलना करके वैधता जांच करें।
- प्रशिक्षण और सेवा डेटा में उदाहरणों की तुलना करके प्रशिक्षण-सेवा विसंगति का पता लगाएं।
- डेटा की श्रृंखला को देखकर डेटा बहाव का पता लगाएं।
हम इनमें से प्रत्येक कार्यप्रणाली का स्वतंत्र रूप से दस्तावेज़ीकरण करते हैं:
स्कीमा आधारित उदाहरण सत्यापन
TensorFlow डेटा सत्यापन एक स्कीमा के विरुद्ध डेटा आँकड़ों की तुलना करके इनपुट डेटा में किसी भी विसंगति की पहचान करता है। स्कीमा उन गुणों को संहिताबद्ध करती है जिन्हें इनपुट डेटा से संतुष्ट करने की उम्मीद की जाती है, जैसे डेटा प्रकार या श्रेणीबद्ध मान, और उपयोगकर्ता द्वारा संशोधित या प्रतिस्थापित किया जा सकता है।
टेन्सरफ्लो डेटा वैलिडेशन को आमतौर पर टीएफएक्स पाइपलाइन के संदर्भ में कई बार लागू किया जाता है: (i) उदाहरणजेन से प्राप्त प्रत्येक विभाजन के लिए, (ii) ट्रांसफॉर्म द्वारा उपयोग किए गए सभी पूर्व-रूपांतरित डेटा के लिए और (iii) उत्पन्न सभी पोस्ट-ट्रांसफॉर्म डेटा के लिए परिवर्तन. जब ट्रांसफॉर्म (ii-iii) के संदर्भ में लागू किया जाता है, तो सांख्यिकी विकल्प और स्कीमा-आधारित बाधाओं को stats_options_updater_fn को परिभाषित करके सेट किया जा सकता है। असंरचित डेटा (जैसे पाठ सुविधाएँ) को मान्य करते समय यह विशेष रूप से उपयोगी है। उदाहरण के लिए उपयोगकर्ता कोड देखें.
उन्नत स्कीमा सुविधाएँ
यह अनुभाग अधिक उन्नत स्कीमा कॉन्फ़िगरेशन को शामिल करता है जो विशेष सेटअप में सहायता कर सकता है।
विरल विशेषताएँ
उदाहरणों में विरल सुविधाओं को एन्कोड करने से आमतौर पर कई विशेषताएं पेश की जाती हैं जिनसे सभी उदाहरणों के लिए समान वैधता की उम्मीद की जाती है। उदाहरण के लिए विरल सुविधा:
WeightedCategories = [('CategoryA', 0.3), ('CategoryX', 0.7)]
WeightedCategoriesIndex = ['CategoryA', 'CategoryX']
WeightedCategoriesValue = [0.3, 0.7]
sparse_feature {
name: 'WeightedCategories'
index_feature { name: 'WeightedCategoriesIndex' }
value_feature { name: 'WeightedCategoriesValue' }
}
विरल सुविधा परिभाषा के लिए एक या अधिक सूचकांक और एक मूल्य सुविधा की आवश्यकता होती है जो स्कीमा में मौजूद सुविधाओं को संदर्भित करती है। विरल सुविधाओं को स्पष्ट रूप से परिभाषित करने से टीएफडीवी यह जांचने में सक्षम हो जाता है कि सभी संदर्भित सुविधाओं की वैधता मेल खाती है।
कुछ उपयोग के मामले सुविधाओं के बीच समान वैधता प्रतिबंध पेश करते हैं, लेकिन जरूरी नहीं कि एक विरल सुविधा को एनकोड करें। विरल सुविधा का उपयोग करने से आपको अनब्लॉक हो जाना चाहिए, लेकिन यह आदर्श नहीं है।
स्कीमा वातावरण
डिफ़ॉल्ट सत्यापनों से यह मान लिया जाता है कि पाइपलाइन में सभी उदाहरण एक ही स्कीमा का पालन करते हैं। कुछ मामलों में स्कीमा में मामूली बदलाव करना आवश्यक है, उदाहरण के लिए प्रशिक्षण के दौरान लेबल के रूप में उपयोग की जाने वाली सुविधाओं की आवश्यकता होती है (और उन्हें मान्य किया जाना चाहिए), लेकिन सेवा के दौरान गायब हैं। ऐसी आवश्यकताओं को व्यक्त करने के लिए वातावरण का उपयोग किया जा सकता है, विशेष रूप से default_environment() , in_environment() , not_in_environment() ।
उदाहरण के लिए, मान लें कि प्रशिक्षण के लिए 'LABEL' नाम की एक सुविधा आवश्यक है, लेकिन सेवा से गायब होने की उम्मीद है। इसे इस प्रकार व्यक्त किया जा सकता है:
- स्कीमा में दो अलग-अलग वातावरण परिभाषित करें: ["सेवा", "प्रशिक्षण"] और 'लेबल' को केवल पर्यावरण "प्रशिक्षण" के साथ संबद्ध करें।
- प्रशिक्षण डेटा को पर्यावरण "प्रशिक्षण" के साथ और सेवारत डेटा को पर्यावरण "सर्विंग" के साथ संबद्ध करें।
स्कीमा जनरेशन
इनपुट डेटा स्कीमा को TensorFlow स्कीमा के एक उदाहरण के रूप में निर्दिष्ट किया गया है।
स्क्रैच से मैन्युअल रूप से एक स्कीमा बनाने के बजाय, एक डेवलपर टेन्सरफ्लो डेटा वैलिडेशन के स्वचालित स्कीमा निर्माण पर भरोसा कर सकता है। विशेष रूप से, TensorFlow डेटा सत्यापन स्वचालित रूप से पाइपलाइन में उपलब्ध प्रशिक्षण डेटा पर गणना किए गए आंकड़ों के आधार पर एक प्रारंभिक स्कीमा बनाता है। उपयोगकर्ता बस इस ऑटोजेनरेटेड स्कीमा की समीक्षा कर सकते हैं, इसे आवश्यकतानुसार संशोधित कर सकते हैं, इसे संस्करण नियंत्रण प्रणाली में जांच सकते हैं, और आगे के सत्यापन के लिए इसे स्पष्ट रूप से पाइपलाइन में डाल सकते हैं।
टीएफडीवी में स्वचालित रूप से एक स्कीमा उत्पन्न करने के लिए infer_schema() शामिल है। उदाहरण के लिए:
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
यह निम्नलिखित नियमों के आधार पर एक स्वचालित स्कीमा पीढ़ी को ट्रिगर करता है:
यदि कोई स्कीमा पहले से ही स्वतः उत्पन्न हो चुकी है तो इसका उपयोग वैसे ही किया जाता है।
अन्यथा, TensorFlow डेटा वैलिडेशन उपलब्ध डेटा आंकड़ों की जांच करता है और डेटा के लिए उपयुक्त स्कीमा की गणना करता है।
नोट: स्वतः-जनित स्कीमा सर्वोत्तम प्रयास है और केवल डेटा के मूल गुणों का अनुमान लगाने का प्रयास करता है। यह अपेक्षा की जाती है कि उपयोगकर्ता इसकी समीक्षा करें और आवश्यकतानुसार इसमें संशोधन करें।
प्रशिक्षण-सेवा तिरछा पता लगाना
सिंहावलोकन
TensorFlow डेटा सत्यापन प्रशिक्षण और सेवा डेटा के बीच वितरण विसंगति का पता लगा सकता है। वितरण विषमता तब होती है जब प्रशिक्षण डेटा के लिए फीचर मानों का वितरण सेवारत डेटा से काफी भिन्न होता है। वितरण विसंगति के प्रमुख कारणों में से एक वांछित कॉर्पस में प्रारंभिक डेटा की कमी को दूर करने के लिए डेटा उत्पादन के प्रशिक्षण के लिए या तो एक पूरी तरह से अलग कॉर्पस का उपयोग करना है। दूसरा कारण एक दोषपूर्ण नमूना तंत्र है जो प्रशिक्षण के लिए केवल सेवारत डेटा का एक उप-नमूना चुनता है।
उदाहरण परिदृश्य
ट्रेनिंग-सर्विंग स्क्यू डिटेक्शन को कॉन्फ़िगर करने के बारे में जानकारी के लिए टेन्सरफ्लो डेटा वैलिडेशन गेट स्टार्टेड गाइड देखें।
बहाव का पता लगाना
ड्रिफ्ट डिटेक्शन को डेटा के लगातार स्पैन (यानी, स्पैन एन और स्पैन एन+1 के बीच) के बीच समर्थित किया जाता है, जैसे कि प्रशिक्षण डेटा के विभिन्न दिनों के बीच। हम श्रेणीबद्ध विशेषताओं के लिए एल-अनंत दूरी और संख्यात्मक विशेषताओं के लिए अनुमानित जेन्सेन-शैनन विचलन के संदर्भ में बहाव व्यक्त करते हैं। आप सीमा दूरी निर्धारित कर सकते हैं ताकि जब बहाव स्वीकार्य सीमा से अधिक हो तो आपको चेतावनी मिले। सही दूरी तय करना आम तौर पर एक पुनरावृत्तीय प्रक्रिया है जिसके लिए डोमेन ज्ञान और प्रयोग की आवश्यकता होती है।
ड्रिफ्ट डिटेक्शन को कॉन्फ़िगर करने के बारे में जानकारी के लिए TensorFlow डेटा वैलिडेशन गेट स्टार्टेड गाइड देखें।
अपने डेटा की जाँच करने के लिए विज़ुअलाइज़ेशन का उपयोग करना
TensorFlow डेटा सत्यापन सुविधा मूल्यों के वितरण को देखने के लिए उपकरण प्रदान करता है। फ़ेसेट्स का उपयोग करके ज्यूपिटर नोटबुक में इन वितरणों की जांच करके आप डेटा के साथ सामान्य समस्याओं को पकड़ सकते हैं।
संदिग्ध वितरण की पहचान करना
आप फ़ीचर मानों के संदिग्ध वितरण को देखने के लिए फ़ेसेट्स अवलोकन डिस्प्ले का उपयोग करके अपने डेटा में सामान्य बग की पहचान कर सकते हैं।
असंतुलित डेटा
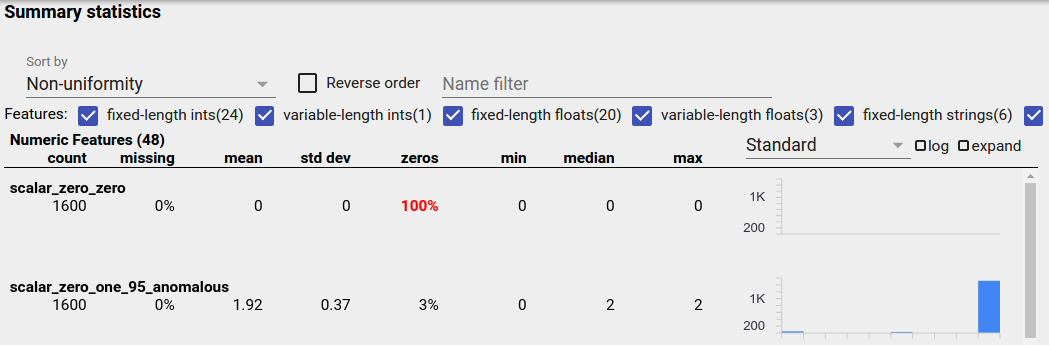
असंतुलित सुविधा वह विशेषता है जिसके लिए एक मान प्रमुख होता है। असंतुलित सुविधाएँ स्वाभाविक रूप से हो सकती हैं, लेकिन यदि किसी सुविधा का मूल्य हमेशा समान होता है तो आपके पास डेटा बग हो सकता है। पहलू अवलोकन में असंतुलित सुविधाओं का पता लगाने के लिए, "इसके अनुसार क्रमबद्ध करें" ड्रॉपडाउन से "गैर-एकरूपता" चुनें।
सबसे असंतुलित सुविधाओं को प्रत्येक सुविधा-प्रकार सूची के शीर्ष पर सूचीबद्ध किया जाएगा। उदाहरण के लिए, निम्नलिखित स्क्रीनशॉट "न्यूमेरिक फीचर्स" सूची के शीर्ष पर एक फीचर दिखाता है जो सभी शून्य है, और दूसरा जो अत्यधिक असंतुलित है:
समान रूप से वितरित डेटा
एक समान रूप से वितरित सुविधा वह है जिसके लिए सभी संभावित मान समान आवृत्ति के करीब दिखाई देते हैं। असंतुलित डेटा की तरह, यह वितरण स्वाभाविक रूप से हो सकता है, लेकिन डेटा बग द्वारा भी उत्पन्न किया जा सकता है।
पहलू अवलोकन में समान रूप से वितरित सुविधाओं का पता लगाने के लिए, "क्रमबद्ध करें" ड्रॉपडाउन से "गैर-एकरूपता" चुनें और "रिवर्स ऑर्डर" चेकबॉक्स को चेक करें:
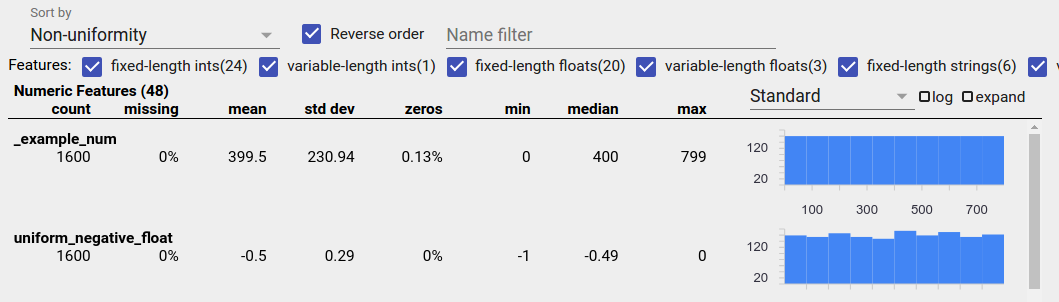
यदि 20 या उससे कम अद्वितीय मान हैं, तो स्ट्रिंग डेटा को बार चार्ट का उपयोग करके और 20 से अधिक अद्वितीय मान होने पर संचयी वितरण ग्राफ़ के रूप में दर्शाया जाता है। तो स्ट्रिंग डेटा के लिए, समान वितरण या तो ऊपर की तरह फ्लैट बार ग्राफ़ या नीचे की तरह सीधी रेखाओं के रूप में दिखाई दे सकते हैं:

बग जो समान रूप से वितरित डेटा उत्पन्न कर सकते हैं
यहां कुछ सामान्य बग हैं जो समान रूप से वितरित डेटा उत्पन्न कर सकते हैं:
तारीखों जैसे गैर-स्ट्रिंग डेटा प्रकारों को दर्शाने के लिए स्ट्रिंग्स का उपयोग करना। उदाहरण के लिए, आपके पास "2017-03-01-11-45-03" जैसे प्रतिनिधित्व के साथ डेटाटाइम सुविधा के लिए कई अद्वितीय मान होंगे। अद्वितीय मूल्यों को समान रूप से वितरित किया जाएगा।
सुविधाओं के रूप में "पंक्ति संख्या" जैसे सूचकांकों को शामिल करना। यहां फिर से आपके पास कई अद्वितीय मूल्य हैं।
लापता आँकड़े
यह जांचने के लिए कि क्या किसी सुविधा में मान पूरी तरह गायब हैं:
- "क्रमांकित करें" ड्रॉप-डाउन से "राशि गायब/शून्य" चुनें।
- "रिवर्स ऑर्डर" चेकबॉक्स को चेक करें।
- किसी सुविधा के लिए लुप्त मान वाले उदाहरणों का प्रतिशत देखने के लिए "लापता" कॉलम देखें।
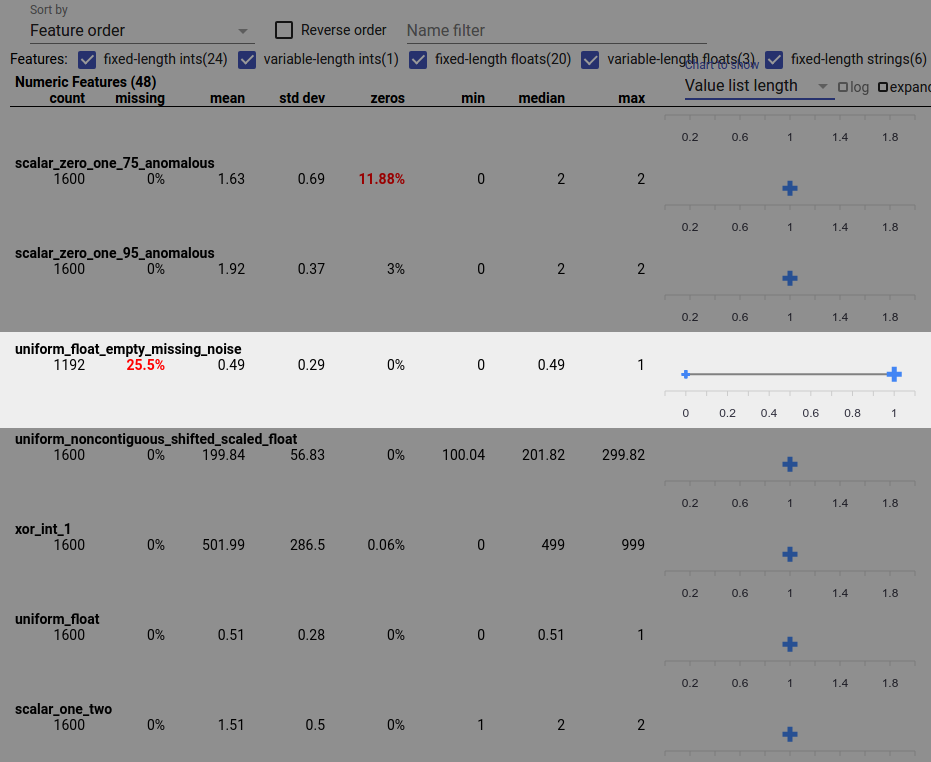
डेटा बग अपूर्ण फीचर मान का कारण भी बन सकता है। उदाहरण के लिए, आप उम्मीद कर सकते हैं कि किसी फीचर की मूल्य सूची में हमेशा तीन तत्व हों और आपको पता चले कि कभी-कभी इसमें केवल एक ही होता है। अपूर्ण मानों या अन्य मामलों की जांच करने के लिए जहां फीचर मान सूचियों में तत्वों की अपेक्षित संख्या नहीं है:
दाईं ओर "दिखाने के लिए चार्ट" ड्रॉप-डाउन मेनू से "मान सूची की लंबाई" चुनें।
प्रत्येक फीचर पंक्ति के दाईं ओर चार्ट को देखें। चार्ट सुविधा के लिए मूल्य सूची की लंबाई की सीमा दिखाता है। उदाहरण के लिए, नीचे दिए गए स्क्रीनशॉट में हाइलाइट की गई पंक्ति एक सुविधा दिखाती है जिसमें कुछ शून्य-लंबाई मान सूचियाँ हैं:
सुविधाओं के बीच पैमाने में बड़ा अंतर
यदि आपकी विशेषताएं पैमाने में व्यापक रूप से भिन्न हैं, तो मॉडल को सीखने में कठिनाई हो सकती है। उदाहरण के लिए, यदि कुछ विशेषताएँ 0 से 1 तक भिन्न हैं और अन्य 0 से 1,000,000,000 तक भिन्न हैं, तो आपके पैमाने में बड़ा अंतर है। व्यापक रूप से भिन्न पैमाने खोजने के लिए सुविधाओं में "अधिकतम" और "न्यूनतम" कॉलम की तुलना करें।
इन व्यापक विविधताओं को कम करने के लिए फीचर मानों को सामान्य बनाने पर विचार करें।
अमान्य लेबल वाले लेबल
TensorFlow के अनुमानकर्ताओं के पास लेबल के रूप में स्वीकार किए जाने वाले डेटा के प्रकार पर प्रतिबंध है। उदाहरण के लिए, बाइनरी क्लासिफायर आमतौर पर केवल {0, 1} लेबल के साथ काम करते हैं।
पहलू अवलोकन में लेबल मानों की समीक्षा करें और सुनिश्चित करें कि वे अनुमानकर्ताओं की आवश्यकताओं के अनुरूप हैं।