
परिचय
TFX एक Google-प्रोडक्शन-स्केल मशीन लर्निंग (ML) प्लेटफ़ॉर्म है जो TensorFlow पर आधारित है। यह आपके मशीन लर्निंग सिस्टम को परिभाषित करने, लॉन्च करने और मॉनिटर करने के लिए आवश्यक सामान्य घटकों को एकीकृत करने के लिए एक कॉन्फ़िगरेशन ढांचा और साझा लाइब्रेरी प्रदान करता है।
टीएफएक्स 1.0
हमें TFX 1.0.0 की उपलब्धता की घोषणा करते हुए खुशी हो रही है। यह टीएफएक्स की प्रारंभिक पोस्ट-बीटा रिलीज है, जो स्थिर सार्वजनिक एपीआई और कलाकृतियां प्रदान करती है। आप आश्वस्त हो सकते हैं कि आपकी भविष्य की टीएफएक्स पाइपलाइनें इस आरएफसी में परिभाषित संगतता दायरे के भीतर अपग्रेड के बाद भी काम करती रहेंगी।
इंस्टालेशन

![]()
pip install tfx
रात्रिकालीन पैकेज
TFX Google क्लाउड पर https://pypi-nightly.tensorflow.org पर रात्रिकालीन पैकेज भी होस्ट करता है। नवीनतम रात्रिकालीन पैकेज स्थापित करने के लिए, कृपया निम्नलिखित कमांड का उपयोग करें:
pip install --extra-index-url https://pypi-nightly.tensorflow.org/simple --pre tfx
यह TFX की प्रमुख निर्भरताओं जैसे कि TensorFlow मॉडल विश्लेषण (TFMA), TensorFlow डेटा वैलिडेशन (TFDV), TensorFlow ट्रांसफॉर्म (TFT), TFX बेसिक शेयर्ड लाइब्रेरीज़ (TFX-BSL), ML मेटाडेटा (MLMD) के लिए रात्रिकालीन पैकेज स्थापित करेगा।
टीएफएक्स के बारे में
टीएफएक्स उत्पादन परिवेश में एमएल वर्कफ़्लो के निर्माण और प्रबंधन के लिए एक मंच है। TFX निम्नलिखित प्रदान करता है:
एमएल पाइपलाइनों के निर्माण के लिए एक टूलकिट। टीएफएक्स पाइपलाइन आपको अपने एमएल वर्कफ़्लो को कई प्लेटफार्मों पर व्यवस्थित करने देती है, जैसे: अपाचे एयरफ्लो, अपाचे बीम और क्यूबफ़्लो पाइपलाइन।
मानक घटकों का एक सेट जिसे आप पाइपलाइन के एक भाग के रूप में, या अपनी एमएल प्रशिक्षण स्क्रिप्ट के एक भाग के रूप में उपयोग कर सकते हैं। टीएफएक्स मानक घटक आपको आसानी से एमएल प्रक्रिया का निर्माण शुरू करने में मदद करने के लिए सिद्ध कार्यक्षमता प्रदान करते हैं।
पुस्तकालय जो कई मानक घटकों के लिए आधार कार्यक्षमता प्रदान करते हैं। आप इस कार्यक्षमता को अपने स्वयं के कस्टम घटकों में जोड़ने के लिए टीएफएक्स लाइब्रेरी का उपयोग कर सकते हैं, या उन्हें अलग से उपयोग कर सकते हैं।
TFX एक Google-प्रोडक्शन-स्केल मशीन लर्निंग टूलकिट है जो TensorFlow पर आधारित है। यह आपके मशीन लर्निंग सिस्टम को परिभाषित करने, लॉन्च करने और मॉनिटर करने के लिए आवश्यक सामान्य घटकों को एकीकृत करने के लिए एक कॉन्फ़िगरेशन ढांचा और साझा लाइब्रेरी प्रदान करता है।
टीएफएक्स मानक घटक
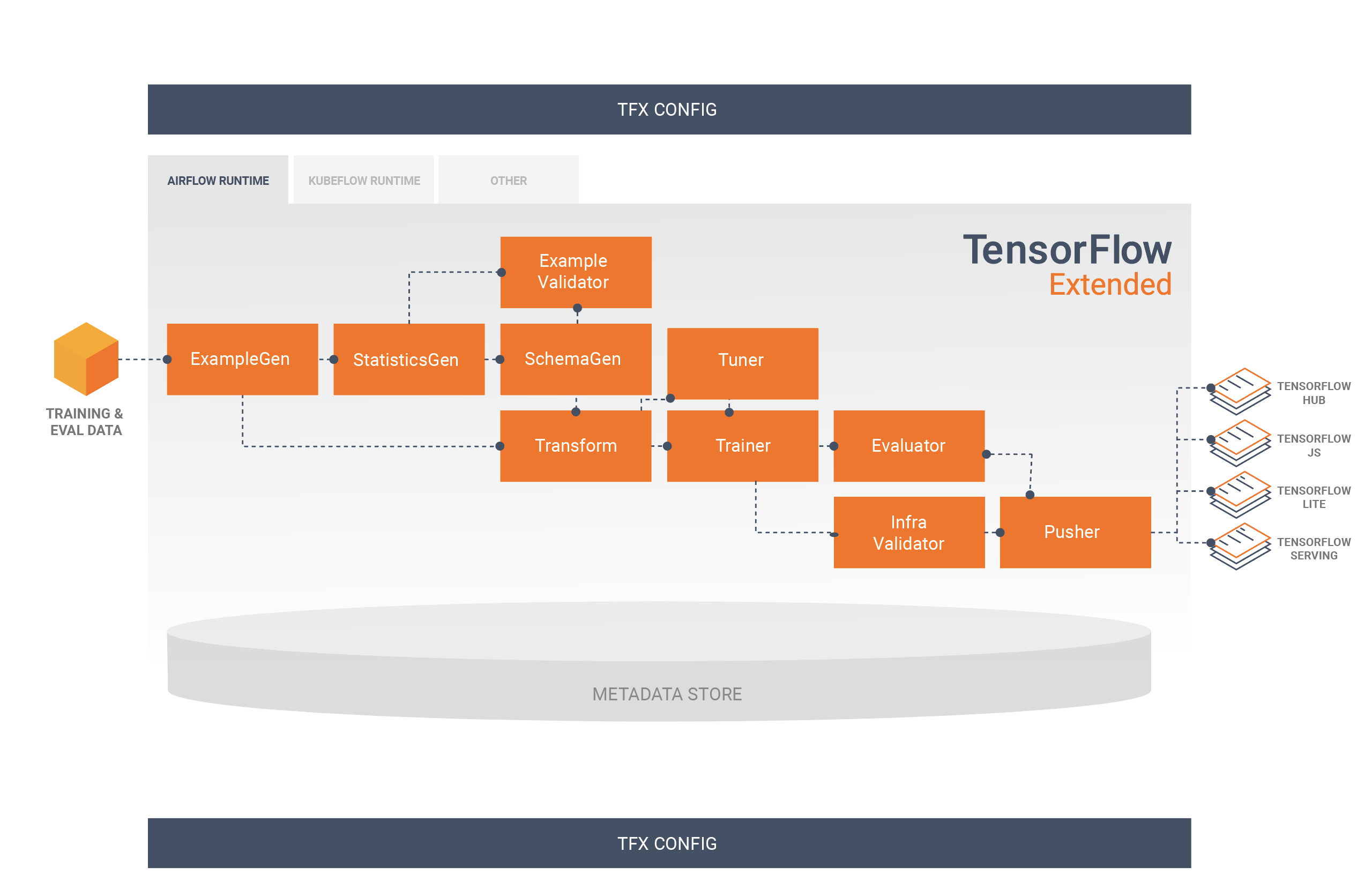
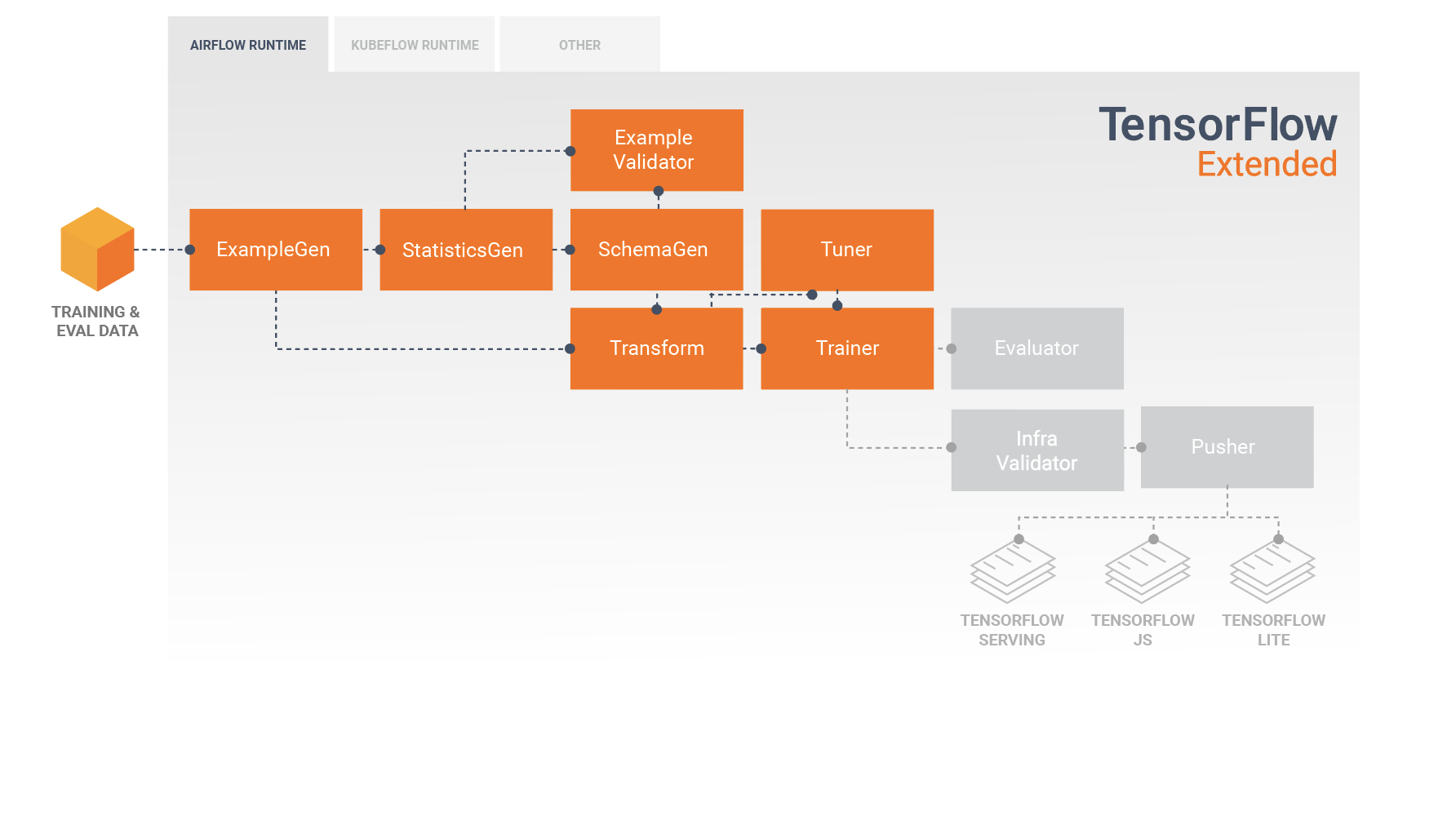
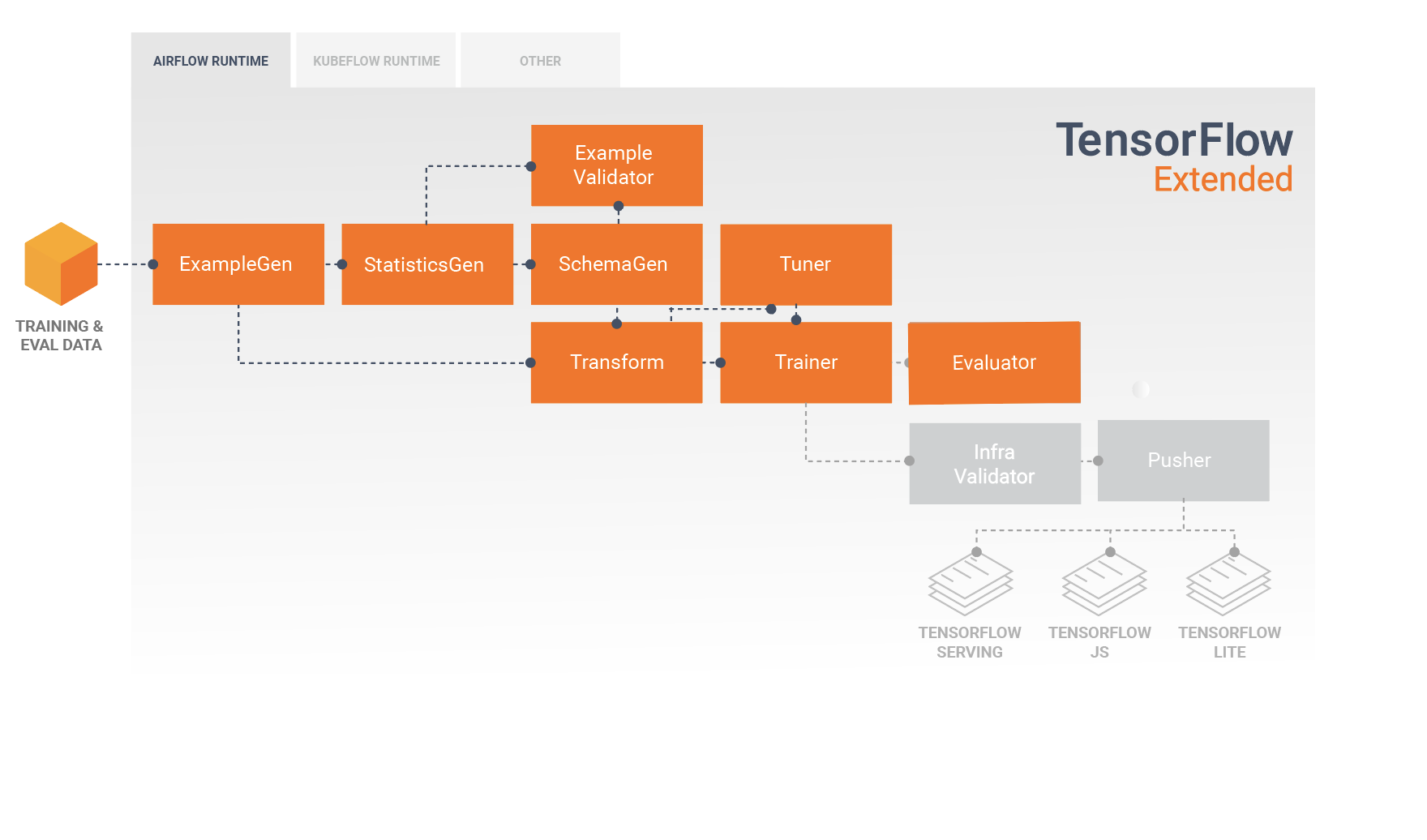
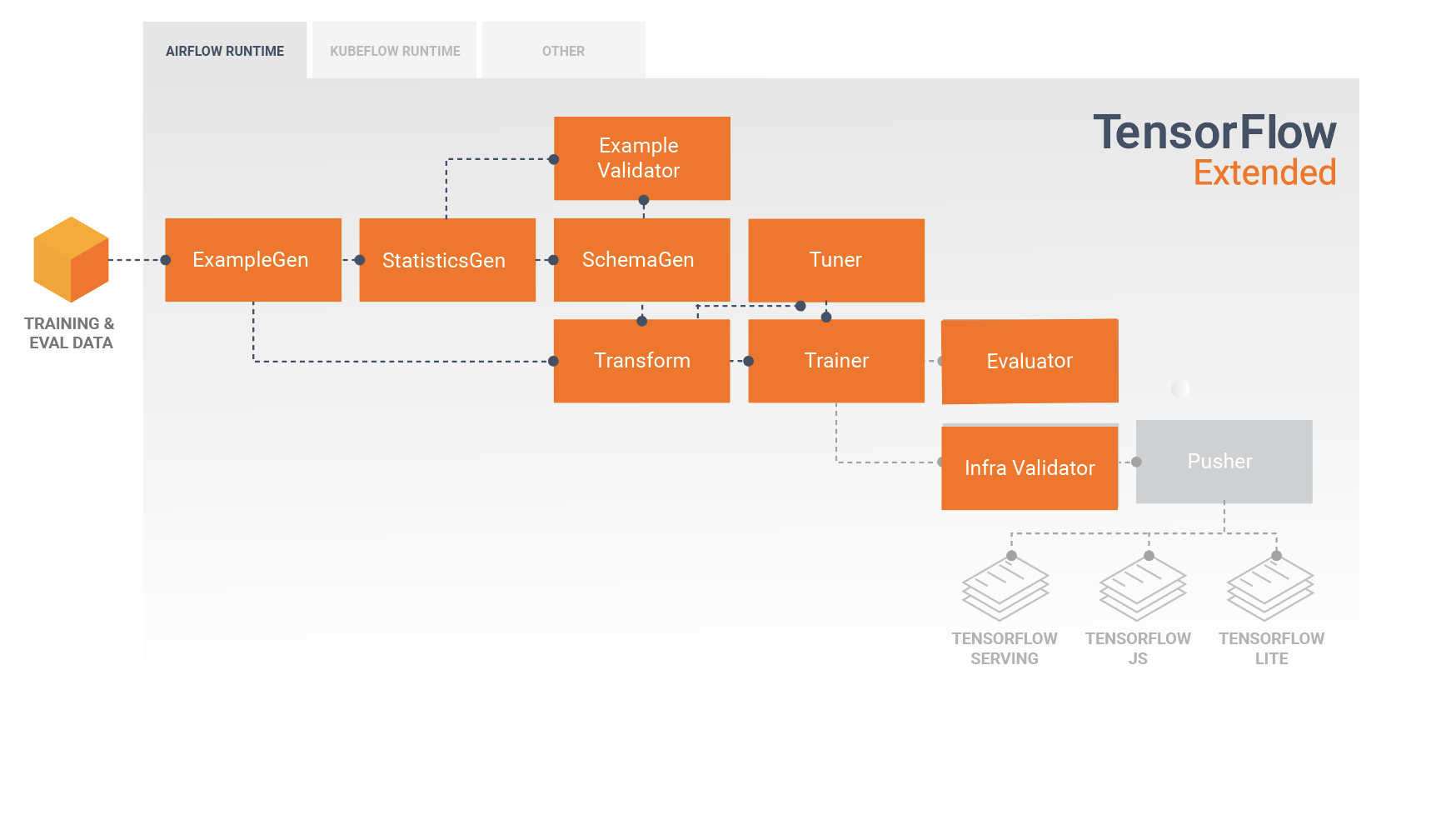
टीएफएक्स पाइपलाइन घटकों का एक क्रम है जो एमएल पाइपलाइन को लागू करता है जो विशेष रूप से स्केलेबल, उच्च-प्रदर्शन मशीन सीखने के कार्यों के लिए डिज़ाइन किया गया है। इसमें मॉडलिंग, प्रशिक्षण, अनुमान प्रस्तुत करना और ऑनलाइन, देशी मोबाइल और जावास्क्रिप्ट लक्ष्यों के लिए तैनाती का प्रबंधन करना शामिल है।
टीएफएक्स पाइपलाइन में आम तौर पर निम्नलिखित घटक शामिल होते हैं:
उदाहरणजेन एक पाइपलाइन का प्रारंभिक इनपुट घटक है जो इनपुट डेटासेट को ग्रहण करता है और वैकल्पिक रूप से विभाजित करता है।
स्टैटिस्टिक्सजेन डेटासेट के लिए आंकड़ों की गणना करता है।
SchemaGen आँकड़ों की जाँच करता है और एक डेटा स्कीमा बनाता है।
उदाहरण सत्यापनकर्ता डेटासेट में विसंगतियों और गुम मानों की तलाश करता है।
ट्रांसफ़ॉर्म डेटासेट पर फ़ीचर इंजीनियरिंग निष्पादित करता है।
प्रशिक्षक मॉडल को प्रशिक्षित करता है।
ट्यूनर मॉडल के हाइपरपैरामीटर को ट्यून करता है।
मूल्यांकनकर्ता प्रशिक्षण परिणामों का गहन विश्लेषण करता है और आपके निर्यातित मॉडलों को मान्य करने में आपकी सहायता करता है, यह सुनिश्चित करते हुए कि वे उत्पादन में धकेलने के लिए "काफी अच्छे" हैं।
इन्फ्रावैलिडेटर यह जांचता है कि मॉडल वास्तव में बुनियादी ढांचे से सेवा योग्य है, और खराब मॉडल को आगे बढ़ने से रोकता है।
पुशर मॉडल को एक सेवारत बुनियादी ढांचे पर तैनात करता है।
बल्कइन्फररर बिना लेबल वाले अनुमान अनुरोधों वाले मॉडल पर बैच प्रोसेसिंग करता है।
यह आरेख इन घटकों के बीच डेटा के प्रवाह को दर्शाता है:
टीएफएक्स पुस्तकालय
टीएफएक्स में लाइब्रेरी और पाइपलाइन घटक दोनों शामिल हैं। यह चित्र TFX लाइब्रेरीज़ और पाइपलाइन घटकों के बीच संबंधों को दर्शाता है:
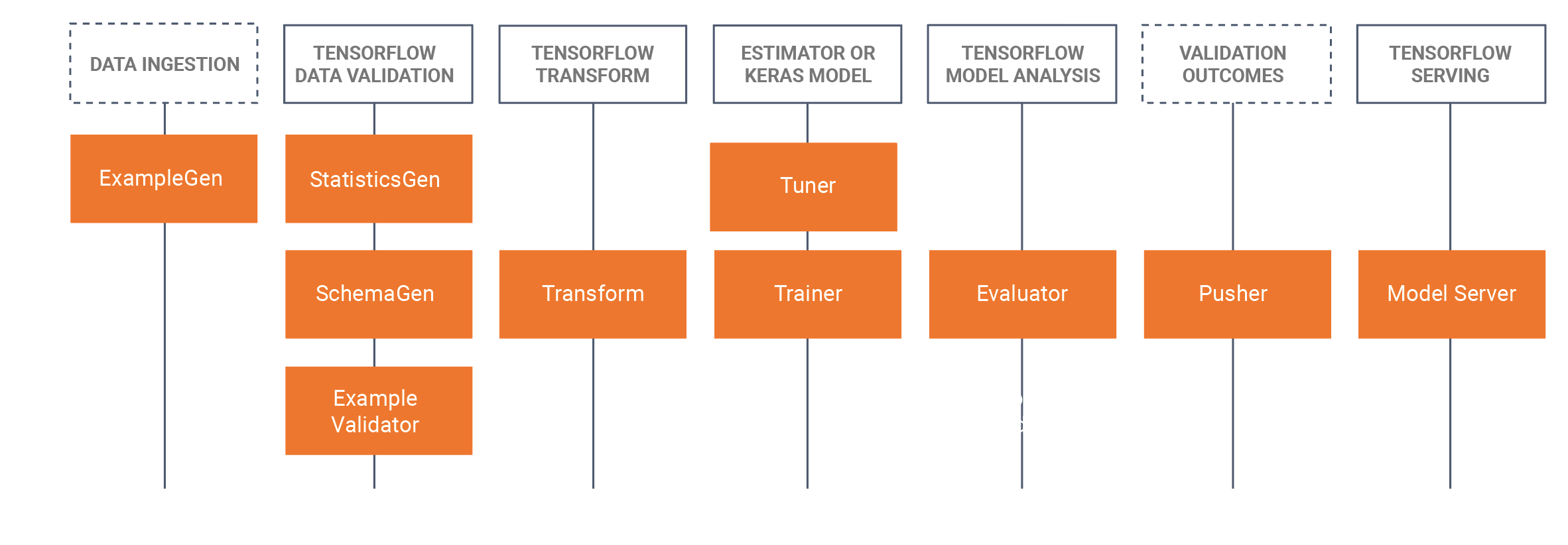
टीएफएक्स कई पायथन पैकेज प्रदान करता है जो कि लाइब्रेरी हैं जिनका उपयोग पाइपलाइन घटकों को बनाने के लिए किया जाता है। आप अपनी पाइपलाइनों के घटकों को बनाने के लिए इन पुस्तकालयों का उपयोग करेंगे ताकि आपका कोड आपकी पाइपलाइन के अद्वितीय पहलुओं पर ध्यान केंद्रित कर सके।
TFX पुस्तकालयों में शामिल हैं:
TensorFlow डेटा वैलिडेशन (TFDV) मशीन लर्निंग डेटा का विश्लेषण और सत्यापन करने के लिए एक लाइब्रेरी है। इसे अत्यधिक स्केलेबल होने और TensorFlow और TFX के साथ अच्छी तरह से काम करने के लिए डिज़ाइन किया गया है। टीएफडीवी में शामिल हैं:
- प्रशिक्षण और परीक्षण डेटा के सारांश आंकड़ों की स्केलेबल गणना।
- डेटा वितरण और आंकड़ों के लिए एक दर्शक के साथ एकीकरण, साथ ही डेटासेट (पहलुओं) के जोड़े की पहलू तुलना।
- आवश्यक मानों, श्रेणियों और शब्दावलियों जैसी डेटा के बारे में अपेक्षाओं का वर्णन करने के लिए स्वचालित डेटा-स्कीमा पीढ़ी।
- स्कीमा का निरीक्षण करने में आपकी सहायता के लिए एक स्कीमा व्यूअर।
- विसंगति का पता लगाने के लिए विसंगतियों की पहचान की जाती है, जैसे कि गायब सुविधाएँ, सीमा से बाहर मान, या गलत फ़ीचर प्रकार, कुछ नाम।
- एक विसंगति दर्शक ताकि आप देख सकें कि किन विशेषताओं में विसंगतियाँ हैं और उन्हें ठीक करने के लिए और अधिक जानें।
TensorFlow Transform (TFT) TensorFlow के साथ डेटा प्रीप्रोसेसिंग के लिए एक लाइब्रेरी है। TensorFlow ट्रांसफ़ॉर्म उस डेटा के लिए उपयोगी है जिसके लिए पूर्ण-पास की आवश्यकता होती है, जैसे:
- माध्य और मानक विचलन द्वारा इनपुट मान को सामान्यीकृत करें।
- सभी इनपुट मानों पर एक शब्दावली उत्पन्न करके स्ट्रिंग्स को पूर्णांकों में बदलें।
- देखे गए डेटा वितरण के आधार पर फ़्लोट को बकेट में निर्दिष्ट करके पूर्णांकों में परिवर्तित करें।
TensorFlow का उपयोग TFX वाले मॉडलों के प्रशिक्षण के लिए किया जाता है। यह प्रशिक्षण डेटा और मॉडलिंग कोड को ग्रहण करता है और एक SaveModel परिणाम बनाता है। यह प्रीप्रोसेसिंग इनपुट डेटा के लिए टेन्सरफ्लो ट्रांसफॉर्म द्वारा बनाई गई एक फीचर इंजीनियरिंग पाइपलाइन को भी एकीकृत करता है।
KerasTuner का उपयोग मॉडल के लिए हाइपरपैरामीटर ट्यूनिंग के लिए किया जाता है।
TensorFlow मॉडल विश्लेषण (TFMA) TensorFlow मॉडल के मूल्यांकन के लिए एक पुस्तकालय है। इसका उपयोग TensorFlow के साथ EvalSavenModel बनाने के लिए किया जाता है, जो इसके विश्लेषण का आधार बन जाता है। यह उपयोगकर्ताओं को उनके ट्रेनर में परिभाषित समान मेट्रिक्स का उपयोग करके वितरित तरीके से बड़ी मात्रा में डेटा पर अपने मॉडल का मूल्यांकन करने की अनुमति देता है। इन मेट्रिक्स की गणना डेटा के विभिन्न स्लाइस पर की जा सकती है और ज्यूपिटर नोटबुक में देखी जा सकती है।
TensorFlow मेटाडेटा (TFMD) मेटाडेटा के लिए मानक प्रतिनिधित्व प्रदान करता है जो TensorFlow के साथ मशीन लर्निंग मॉडल को प्रशिक्षित करते समय उपयोगी होते हैं। इनपुट डेटा विश्लेषण के दौरान मेटाडेटा हाथ से या स्वचालित रूप से तैयार किया जा सकता है, और डेटा सत्यापन, अन्वेषण और परिवर्तन के लिए इसका उपयोग किया जा सकता है। मेटाडेटा क्रमांकन प्रारूपों में शामिल हैं:
- सारणीबद्ध डेटा का वर्णन करने वाली एक स्कीमा (जैसे, tf.Examples)।
- ऐसे डेटासेट पर सारांश आँकड़ों का संग्रह।
एमएल मेटाडेटा (एमएलएमडी) एमएल डेवलपर और डेटा वैज्ञानिक वर्कफ़्लो से जुड़े मेटाडेटा को रिकॉर्ड करने और पुनर्प्राप्त करने के लिए एक लाइब्रेरी है। अक्सर मेटाडेटा टीएफएमडी अभ्यावेदन का उपयोग करता है। MLMD SQL-Lite , MySQL और अन्य समान डेटा स्टोर का उपयोग करके दृढ़ता का प्रबंधन करता है।
सहायक प्रौद्योगिकियाँ
आवश्यक
- अपाचे बीम बैच और स्ट्रीमिंग डेटा-समानांतर प्रसंस्करण पाइपलाइनों को परिभाषित करने के लिए एक खुला स्रोत, एकीकृत मॉडल है। टीएफएक्स डेटा-समानांतर पाइपलाइनों को लागू करने के लिए अपाचे बीम का उपयोग करता है। फिर पाइपलाइन को बीम के समर्थित वितरित प्रोसेसिंग बैक-एंड में से एक द्वारा निष्पादित किया जाता है, जिसमें अपाचे फ्लिंक, अपाचे स्पार्क, Google क्लाउड डेटाफ्लो और अन्य शामिल हैं।
वैकल्पिक
अपाचे एयरफ्लो और क्यूबफ्लो जैसे ऑर्केस्ट्रेटर एमएल पाइपलाइन को कॉन्फ़िगर करना, संचालन, निगरानी और रखरखाव करना आसान बनाते हैं।
अपाचे एयरफ़्लो वर्कफ़्लो को प्रोग्रामेटिक रूप से लिखने, शेड्यूल करने और मॉनिटर करने का एक प्लेटफ़ॉर्म है। टीएफएक्स कार्यों के निर्देशित एसाइक्लिक ग्राफ़ (डीएजी) के रूप में वर्कफ़्लो लिखने के लिए एयरफ्लो का उपयोग करता है। एयरफ़्लो शेड्यूलर निर्दिष्ट निर्भरताओं का पालन करते हुए श्रमिकों की एक श्रृंखला पर कार्य निष्पादित करता है। समृद्ध कमांड लाइन उपयोगिताएँ DAGs पर जटिल सर्जरी करना आसान बनाती हैं। समृद्ध उपयोगकर्ता इंटरफ़ेस उत्पादन में चल रही पाइपलाइनों की कल्पना करना, प्रगति की निगरानी करना और ज़रूरत पड़ने पर समस्याओं का निवारण करना आसान बनाता है। जब वर्कफ़्लो को कोड के रूप में परिभाषित किया जाता है, तो वे अधिक रखरखाव योग्य, संस्करण योग्य, परीक्षण योग्य और सहयोगी बन जाते हैं।
क्यूबफ़्लो, कुबेरनेट्स पर मशीन लर्निंग (एमएल) वर्कफ़्लो की तैनाती को सरल, पोर्टेबल और स्केलेबल बनाने के लिए समर्पित है। क्यूबफ्लो का लक्ष्य अन्य सेवाओं को फिर से बनाना नहीं है, बल्कि एमएल के लिए विविध बुनियादी ढांचे के लिए सर्वोत्तम नस्ल के ओपन-सोर्स सिस्टम को तैनात करने का एक सीधा तरीका प्रदान करना है। क्यूबफ्लो पाइपलाइन प्रयोग और नोटबुक आधारित अनुभवों के साथ एकीकृत, क्यूबफ्लो पर प्रतिलिपि प्रस्तुत करने योग्य वर्कफ़्लो की संरचना और निष्पादन को सक्षम बनाती है। Kubernetes पर Kubeflow पाइपलाइन सेवाओं में उपयोगकर्ताओं को बड़े पैमाने पर जटिल ML पाइपलाइनों को विकसित करने, चलाने और प्रबंधित करने में मदद करने के लिए होस्ट किए गए मेटाडेटा स्टोर, कंटेनर आधारित ऑर्केस्ट्रेशन इंजन, नोटबुक सर्वर और UI शामिल हैं। क्यूबफ़्लो पाइपलाइन एसडीके प्रोग्रामेटिक रूप से पाइपलाइनों के घटकों और संरचना को बनाने और साझा करने की अनुमति देता है।
पोर्टेबिलिटी और इंटरऑपरेबिलिटी
टीएफएक्स को अपाचे एयरफ्लो , अपाचे बीम और क्यूबफ्लो सहित कई वातावरणों और ऑर्केस्ट्रेशन फ्रेमवर्क के लिए पोर्टेबल होने के लिए डिज़ाइन किया गया है। यह ऑन-प्रिमाइसेस और Google क्लाउड प्लेटफ़ॉर्म (GCP) जैसे क्लाउड प्लेटफ़ॉर्म सहित विभिन्न कंप्यूटिंग प्लेटफ़ॉर्म के लिए भी पोर्टेबल है। विशेष रूप से, टीएफएक्स सर्वरल प्रबंधित जीसीपी सेवाओं के साथ इंटरऑपरेट करता है, जैसे प्रशिक्षण और भविष्यवाणी के लिए क्लाउड एआई प्लेटफॉर्म , और एमएल जीवनचक्र के कई अन्य पहलुओं के लिए वितरित डेटा प्रोसेसिंग के लिए क्लाउड डेटाफ्लो ।
मॉडल बनाम सेव्डमॉडल
नमूना
एक मॉडल प्रशिक्षण प्रक्रिया का आउटपुट है। यह प्रशिक्षण प्रक्रिया के दौरान सीखे गए वज़न का क्रमबद्ध रिकॉर्ड है। इन भारों का उपयोग बाद में नए इनपुट उदाहरणों के लिए पूर्वानुमानों की गणना करने के लिए किया जा सकता है। टीएफएक्स और टेन्सरफ्लो के लिए, 'मॉडल' उन चौकियों को संदर्भित करता है जिनमें उस बिंदु तक सीखे गए वजन शामिल हैं।
ध्यान दें कि 'मॉडल' टेन्सरफ्लो गणना ग्राफ (यानी एक पायथन फ़ाइल) की परिभाषा को भी संदर्भित कर सकता है जो बताता है कि भविष्यवाणी की गणना कैसे की जाएगी। संदर्भ के आधार पर दोनों इंद्रियों का परस्पर उपयोग किया जा सकता है।
सहेजा गया मॉडल
- सेव्डमॉडल क्या है : टेन्सरफ्लो मॉडल का एक सार्वभौमिक, भाषा-तटस्थ, सुव्यवस्थित, पुनर्प्राप्ति योग्य क्रमबद्धता।
- यह महत्वपूर्ण क्यों है : यह उच्च-स्तरीय प्रणालियों को एकल अमूर्त का उपयोग करके TensorFlow मॉडल का उत्पादन, परिवर्तन और उपभोग करने में सक्षम बनाता है।
सेव्डमॉडल उत्पादन में टेन्सरफ्लो मॉडल की सेवा के लिए, या देशी मोबाइल या जावास्क्रिप्ट एप्लिकेशन के लिए प्रशिक्षित मॉडल को निर्यात करने के लिए अनुशंसित क्रमांकन प्रारूप है। उदाहरण के लिए, पूर्वानुमान लगाने के लिए किसी मॉडल को REST सेवा में बदलने के लिए, आप मॉडल को SavedModel के रूप में क्रमबद्ध कर सकते हैं और TensorFlow सर्विंग का उपयोग करके इसे परोस सकते हैं। अधिक जानकारी के लिए TensorFlow मॉडल परोसना देखें।
योजना
कुछ TFX घटक आपके इनपुट डेटा के विवरण का उपयोग करते हैं जिसे स्कीमा कहा जाता है। स्कीमा schema.proto का एक उदाहरण है। स्कीमा एक प्रकार का प्रोटोकॉल बफ़र है, जिसे आम तौर पर "प्रोटोबफ़" के रूप में जाना जाता है। स्कीमा फ़ीचर मानों के लिए डेटा प्रकार निर्दिष्ट कर सकती है, चाहे कोई फ़ीचर सभी उदाहरणों, अनुमत मान श्रेणियों और अन्य गुणों में मौजूद हो। TensorFlow डेटा वैलिडेशन (TFDV) का उपयोग करने का एक लाभ यह है कि यह प्रशिक्षण डेटा से प्रकारों, श्रेणियों और श्रेणियों का अनुमान लगाकर स्वचालित रूप से एक स्कीमा उत्पन्न करेगा।
यहां स्कीमा प्रोटोबफ़ का एक अंश दिया गया है:
...
feature {
name: "age"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
feature {
name: "capital-gain"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
...
निम्नलिखित घटक स्कीमा का उपयोग करते हैं:
- टेंसरफ़्लो डेटा सत्यापन
- टेंसरफ़्लो ट्रांसफ़ॉर्म
एक विशिष्ट TFX पाइपलाइन में TensorFlow डेटा वैलिडेशन एक स्कीमा उत्पन्न करता है, जिसका उपभोग अन्य घटकों द्वारा किया जाता है।
टीएफएक्स के साथ विकास करना
टीएफएक्स तैनाती के माध्यम से आपकी स्थानीय मशीन पर अनुसंधान, प्रयोग और विकास से लेकर मशीन लर्निंग प्रोजेक्ट के हर चरण के लिए एक शक्तिशाली मंच प्रदान करता है। कोड दोहराव से बचने और प्रशिक्षण/सर्विंग तिरछा की संभावना को खत्म करने के लिए मॉडल प्रशिक्षण और प्रशिक्षित मॉडलों की तैनाती दोनों के लिए अपनी टीएफएक्स पाइपलाइन को लागू करने और ट्रांसफॉर्म घटकों का उपयोग करने की दृढ़ता से अनुशंसा की जाती है जो प्रशिक्षण और अनुमान दोनों के लिए टेन्सरफ्लो ट्रांसफॉर्म लाइब्रेरी का लाभ उठाते हैं। ऐसा करने से आप समान प्रीप्रोसेसिंग और विश्लेषण कोड का लगातार उपयोग करेंगे, और प्रशिक्षण के लिए उपयोग किए गए डेटा और उत्पादन में आपके प्रशिक्षित मॉडलों को खिलाए गए डेटा के बीच अंतर से बचेंगे, साथ ही उस कोड को एक बार लिखने से भी लाभ होगा।
डेटा अन्वेषण, विज़ुअलाइज़ेशन और सफ़ाई
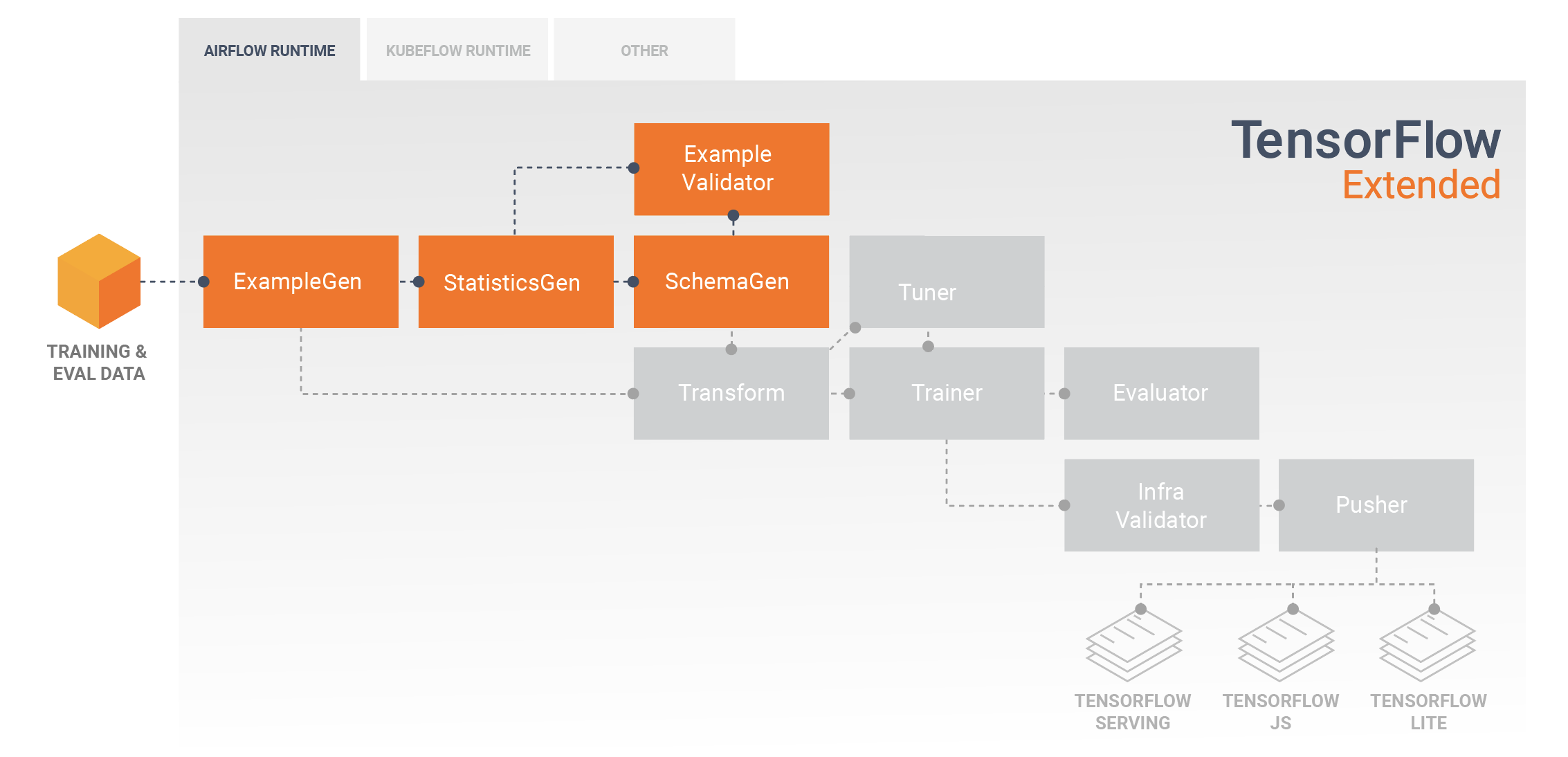
टीएफएक्स पाइपलाइन आम तौर पर एक उदाहरणजेन घटक से शुरू होती है, जो इनपुट डेटा स्वीकार करती है और इसे tf.Examples के रूप में प्रारूपित करती है। अक्सर यह डेटा को प्रशिक्षण और मूल्यांकन डेटासेट में विभाजित करने के बाद किया जाता है ताकि वास्तव में उदाहरणजेन घटकों की दो प्रतियां हों, प्रत्येक प्रशिक्षण और मूल्यांकन के लिए। इसके बाद आम तौर पर एक स्टैटिस्टिक्सजेन घटक और एक स्कीमजेन घटक होता है, जो आपके डेटा की जांच करेगा और एक डेटा स्कीमा और आंकड़ों का अनुमान लगाएगा। स्कीमा और आँकड़े एक exampleValidator घटक द्वारा उपभोग किए जाएंगे, जो आपके डेटा में विसंगतियों, लापता मानों और गलत डेटा प्रकारों की तलाश करेगा। ये सभी घटक TensorFlow डेटा सत्यापन लाइब्रेरी की क्षमताओं का लाभ उठाते हैं।
आपके डेटासेट की प्रारंभिक खोज, विज़ुअलाइज़ेशन और सफाई करते समय TensorFlow डेटा वैलिडेशन (TFDV) एक मूल्यवान उपकरण है। टीएफडीवी आपके डेटा की जांच करता है और डेटा प्रकार, श्रेणियों और श्रेणियों का अनुमान लगाता है, और फिर स्वचालित रूप से विसंगतियों और लापता मूल्यों की पहचान करने में मदद करता है। यह विज़ुअलाइज़ेशन टूल भी प्रदान करता है जो आपके डेटासेट की जांच और समझने में आपकी सहायता कर सकता है। आपकी पाइपलाइन पूरी होने के बाद आप एमएलएमडी से मेटाडेटा पढ़ सकते हैं और अपने डेटा का विश्लेषण करने के लिए ज्यूपिटर नोटबुक में टीएफडीवी के विज़ुअलाइज़ेशन टूल का उपयोग कर सकते हैं।
आपके प्रारंभिक मॉडल प्रशिक्षण और तैनाती के बाद, टीएफडीवी का उपयोग आपके तैनात मॉडलों के अनुमान अनुरोधों से नए डेटा की निगरानी करने और विसंगतियों और/या बहाव को देखने के लिए किया जा सकता है। यह समय श्रृंखला डेटा के लिए विशेष रूप से उपयोगी है जो प्रवृत्ति या मौसमी के परिणामस्वरूप समय के साथ बदलता है, और यह सूचित करने में मदद कर सकता है कि डेटा समस्याएं कब होती हैं या मॉडल को नए डेटा पर फिर से प्रशिक्षित करने की आवश्यकता होती है।
डेटा विज़ुअलाइज़ेशन
अपने पाइपलाइन के उस अनुभाग के माध्यम से अपने डेटा का पहला रन पूरा करने के बाद जो TFDV (आमतौर पर स्टैटिस्टिक्सजेन, स्कीमजेन, और उदाहरण वैलिडेटर) का उपयोग करता है, आप ज्यूपिटर स्टाइल नोटबुक में परिणामों की कल्पना कर सकते हैं। अतिरिक्त रन के लिए आप समायोजन करते समय इन परिणामों की तुलना कर सकते हैं, जब तक कि आपका डेटा आपके मॉडल और एप्लिकेशन के लिए इष्टतम न हो जाए।
आप इन घटकों के निष्पादन के परिणामों का पता लगाने के लिए पहले एमएल मेटाडेटा (एमएलएमडी) से पूछताछ करेंगे, और फिर अपनी नोटबुक में विज़ुअलाइज़ेशन बनाने के लिए टीएफडीवी में विज़ुअलाइज़ेशन समर्थन एपीआई का उपयोग करेंगे। इसमें tfdv.load_statistics() और tfdv.visualize_statistics() शामिल हैं। इस विज़ुअलाइज़ेशन का उपयोग करके आप अपने डेटासेट की विशेषताओं को बेहतर ढंग से समझ सकते हैं, और यदि आवश्यक हो तो आवश्यकतानुसार संशोधित कर सकते हैं।
मॉडल का विकास और प्रशिक्षण
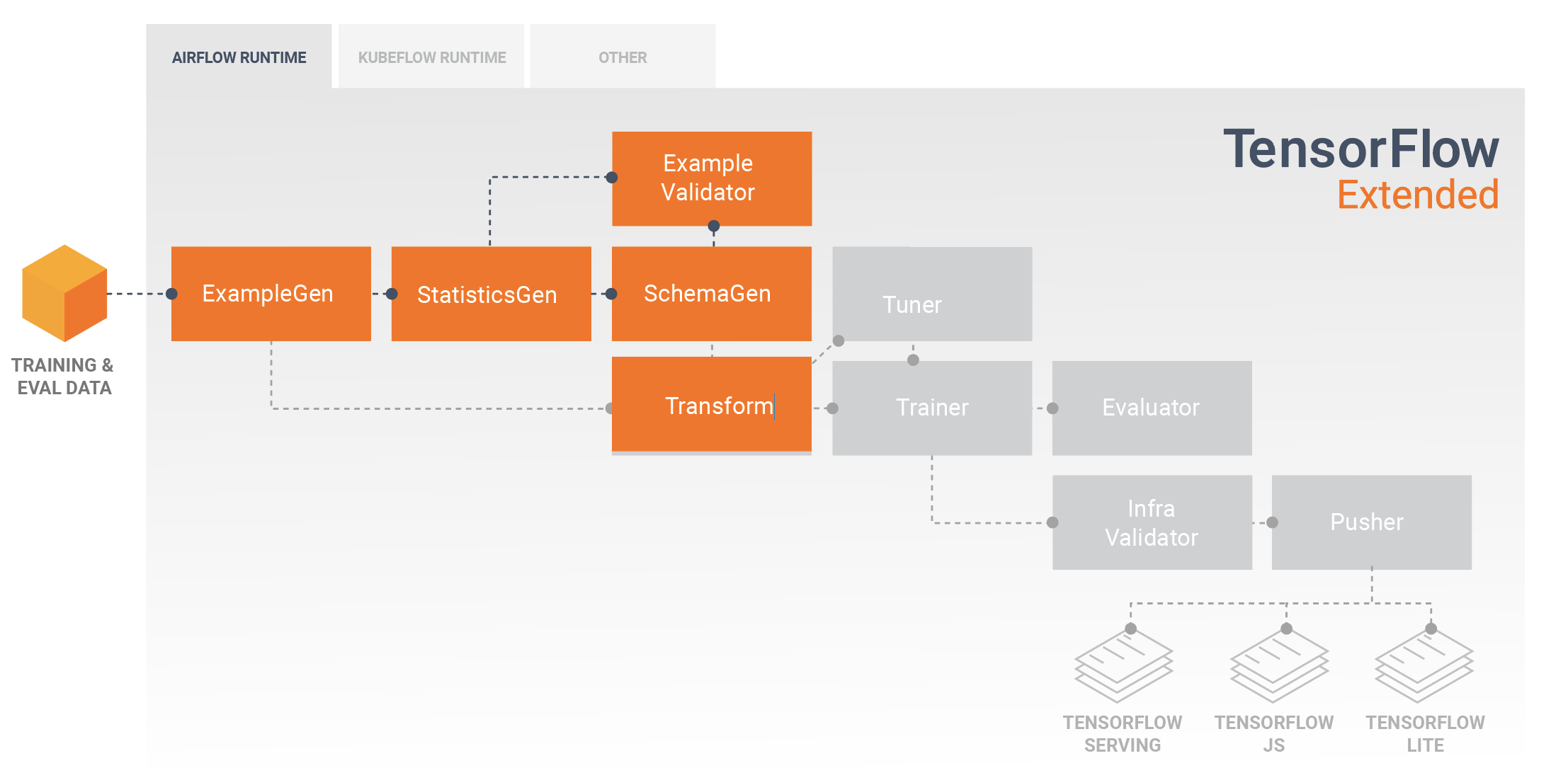
एक विशिष्ट टीएफएक्स पाइपलाइन में एक ट्रांसफॉर्म घटक शामिल होगा, जो टेन्सरफ्लो ट्रांसफॉर्म (टीएफटी) लाइब्रेरी की क्षमताओं का लाभ उठाकर फीचर इंजीनियरिंग करेगा। एक ट्रांसफ़ॉर्म घटक स्कीमजेन घटक द्वारा बनाई गई स्कीमा का उपभोग करता है, और उन सुविधाओं को बनाने, संयोजित करने और बदलने के लिए डेटा परिवर्तनों को लागू करता है जिनका उपयोग आपके मॉडल को प्रशिक्षित करने के लिए किया जाएगा। अनुपलब्ध मानों की सफाई और प्रकारों का रूपांतरण भी ट्रांसफॉर्म घटक में किया जाना चाहिए यदि कभी संभावना हो कि ये अनुमान अनुरोधों के लिए भेजे गए डेटा में भी मौजूद होंगे। टीएफएक्स में प्रशिक्षण के लिए टेन्सरफ्लो कोड डिजाइन करते समय कुछ महत्वपूर्ण विचार हैं ।
ट्रांसफॉर्म घटक का परिणाम एक सेव्डमॉडल है जिसे ट्रेनर घटक के दौरान टेन्सरफ्लो में आपके मॉडलिंग कोड में आयात और उपयोग किया जाएगा। इस सेव्डमॉडल में ट्रांसफ़ॉर्म घटक में बनाए गए सभी डेटा इंजीनियरिंग परिवर्तन शामिल हैं, ताकि प्रशिक्षण और अनुमान दोनों के दौरान समान कोड का उपयोग करके समान परिवर्तन किए जा सकें। ट्रांसफ़ॉर्म घटक से सेव्डमॉडल सहित मॉडलिंग कोड का उपयोग करके, आप अपने प्रशिक्षण और मूल्यांकन डेटा का उपभोग कर सकते हैं और अपने मॉडल को प्रशिक्षित कर सकते हैं।
एस्टीमेटर आधारित मॉडल के साथ काम करते समय, आपके मॉडलिंग कोड के अंतिम भाग को आपके मॉडल को सेव्डमॉडल और इवलसेव्डमॉडल दोनों के रूप में सहेजना चाहिए। EvalSavenModel के रूप में सहेजने से यह सुनिश्चित होता है कि प्रशिक्षण के समय उपयोग किए गए मेट्रिक्स मूल्यांकन के दौरान भी उपलब्ध हैं (ध्यान दें कि केरस आधारित मॉडल के लिए यह आवश्यक नहीं है)। EvalSavenModel को सहेजने के लिए आवश्यक है कि आप अपने ट्रेनर घटक में TensorFlow मॉडल विश्लेषण (TFMA) लाइब्रेरी को आयात करें।
import tensorflow_model_analysis as tfma
...
tfma.export.export_eval_savedmodel(
estimator=estimator,
export_dir_base=eval_model_dir,
eval_input_receiver_fn=receiver_fn)
मॉडल के लिए हाइपरपैरामीटर (उदाहरण के लिए, परतों की संख्या) को ट्यून करने के लिए ट्रेनर से पहले एक वैकल्पिक ट्यूनर घटक जोड़ा जा सकता है। दिए गए मॉडल और हाइपरपैरामीटर के खोज स्थान के साथ, ट्यूनिंग एल्गोरिदम उद्देश्य के आधार पर सर्वोत्तम हाइपरपैरामीटर ढूंढेगा।
मॉडल प्रदर्शन का विश्लेषण और समझना
प्रारंभिक मॉडल विकास और प्रशिक्षण के बाद अपने मॉडल के प्रदर्शन का विश्लेषण करना और उसे वास्तव में समझना महत्वपूर्ण है। एक विशिष्ट टीएफएक्स पाइपलाइन में एक मूल्यांकनकर्ता घटक शामिल होगा, जो टेन्सरफ्लो मॉडल विश्लेषण (टीएफएमए) लाइब्रेरी की क्षमताओं का लाभ उठाता है, जो विकास के इस चरण के लिए एक पावर टूलसेट प्रदान करता है। एक मूल्यांकनकर्ता घटक उस मॉडल का उपभोग करता है जिसे आपने ऊपर निर्यात किया है, और आपको tfma.SlicingSpec की एक सूची निर्दिष्ट करने की अनुमति देता है जिसका उपयोग आप अपने मॉडल के प्रदर्शन की कल्पना और विश्लेषण करते समय कर सकते हैं। प्रत्येक SlicingSpec आपके प्रशिक्षण डेटा का एक टुकड़ा परिभाषित करता है जिसे आप जांचना चाहते हैं, जैसे श्रेणीबद्ध सुविधाओं के लिए विशेष श्रेणियां, या संख्यात्मक सुविधाओं के लिए विशेष श्रेणियां।
उदाहरण के लिए, यह आपके ग्राहकों के विभिन्न वर्गों के लिए आपके मॉडल के प्रदर्शन को समझने की कोशिश करने के लिए महत्वपूर्ण होगा, जिसे वार्षिक खरीदारी, भौगोलिक डेटा, आयु समूह या लिंग के आधार पर विभाजित किया जा सकता है। यह लंबी पूंछ वाले डेटासेट के लिए विशेष रूप से महत्वपूर्ण हो सकता है, जहां एक प्रमुख समूह का प्रदर्शन महत्वपूर्ण, फिर भी छोटे समूहों के लिए अस्वीकार्य प्रदर्शन को छुपा सकता है। उदाहरण के लिए, आपका मॉडल औसत कर्मचारियों के लिए अच्छा प्रदर्शन कर सकता है लेकिन कार्यकारी कर्मचारियों के लिए बुरी तरह विफल हो सकता है, और आपके लिए यह जानना महत्वपूर्ण हो सकता है।
मॉडल विश्लेषण और विज़ुअलाइज़ेशन
अपने मॉडल को प्रशिक्षित करने और प्रशिक्षण परिणामों पर मूल्यांकनकर्ता घटक (जो टीएफएमए का लाभ उठाता है) चलाने के माध्यम से अपने डेटा का पहला रन पूरा करने के बाद, आप ज्यूपिटर शैली नोटबुक में परिणामों की कल्पना कर सकते हैं। अतिरिक्त रन के लिए आप समायोजन करते समय इन परिणामों की तुलना कर सकते हैं, जब तक कि आपके परिणाम आपके मॉडल और एप्लिकेशन के लिए इष्टतम न हों।
आप इन घटकों के निष्पादन के परिणामों का पता लगाने के लिए पहले एमएल मेटाडेटा (एमएलएमडी) से पूछताछ करेंगे, और फिर अपनी नोटबुक में विज़ुअलाइज़ेशन बनाने के लिए टीएफएमए में विज़ुअलाइज़ेशन समर्थन एपीआई का उपयोग करेंगे। इसमें tfma.load_eval_results और tfma.view.render_slicing_metrics शामिल हैं। इस विज़ुअलाइज़ेशन का उपयोग करके आप अपने मॉडल की विशेषताओं को बेहतर ढंग से समझ सकते हैं, और यदि आवश्यक हो तो आवश्यकतानुसार संशोधित कर सकते हैं।
मॉडल प्रदर्शन को मान्य करना
किसी मॉडल के प्रदर्शन का विश्लेषण करने के भाग के रूप में आप एक आधार रेखा (जैसे वर्तमान में सेवारत मॉडल) के आधार पर प्रदर्शन को सत्यापित करना चाह सकते हैं। मॉडल सत्यापन एक उम्मीदवार और बेसलाइन मॉडल दोनों को मूल्यांकनकर्ता घटक में पास करके किया जाता है। मूल्यांकनकर्ता अलग-अलग मेट्रिक्स के संबंधित सेट के साथ उम्मीदवार और बेसलाइन दोनों के लिए मेट्रिक्स (जैसे एयूसी, हानि) की गणना करता है। फिर थ्रेसहोल्ड लागू किए जा सकते हैं और आपके मॉडल को उत्पादन की ओर धकेलने के लिए गेट का उपयोग किया जा सकता है।
यह सत्यापित करना कि एक मॉडल प्रस्तुत किया जा सकता है
प्रशिक्षित मॉडल को तैनात करने से पहले, आप यह सत्यापित करना चाहेंगे कि मॉडल वास्तव में सेवारत बुनियादी ढांचे में सेवा योग्य है या नहीं। उत्पादन परिवेश में यह विशेष रूप से महत्वपूर्ण है ताकि यह सुनिश्चित किया जा सके कि नया प्रकाशित मॉडल सिस्टम को पूर्वानुमान प्रस्तुत करने से नहीं रोकता है। इन्फ्रावैलिडेटर घटक सैंडबॉक्स वाले वातावरण में आपके मॉडल की कैनरी तैनाती करेगा, और वैकल्पिक रूप से यह जांचने के लिए वास्तविक अनुरोध भेजेगा कि आपका मॉडल सही ढंग से काम करता है।
परिनियोजन लक्ष्य
एक बार जब आप एक मॉडल विकसित और प्रशिक्षित कर लेते हैं जिससे आप खुश हैं, तो अब इसे एक या अधिक परिनियोजन लक्ष्य (लक्ष्यों) पर तैनात करने का समय है जहां इसे अनुमान अनुरोध प्राप्त होंगे। TFX परिनियोजन लक्ष्यों के तीन वर्गों में परिनियोजन का समर्थन करता है। प्रशिक्षित मॉडल जिन्हें सेव्डमॉडल के रूप में निर्यात किया गया है, उन्हें इनमें से किसी एक या सभी तैनाती लक्ष्यों पर तैनात किया जा सकता है।
अनुमान: टेंसरफ़्लो सर्विंग
टेन्सरफ्लो सर्विंग (टीएफएस) मशीन लर्निंग मॉडल के लिए एक लचीली, उच्च प्रदर्शन वाली सर्विंग प्रणाली है, जिसे उत्पादन वातावरण के लिए डिज़ाइन किया गया है। यह एक सेव्डमॉडल का उपभोग करता है और REST या gRPC इंटरफेस पर अनुमान अनुरोध स्वीकार करेगा। यह सिंक्रनाइज़ेशन और वितरित गणना को संभालने के लिए कई उन्नत आर्किटेक्चर में से एक का उपयोग करते हुए, एक या अधिक नेटवर्क सर्वर पर प्रक्रियाओं के एक सेट के रूप में चलता है। टीएफएस समाधानों को विकसित करने और तैनात करने के बारे में अधिक जानकारी के लिए टीएफएस दस्तावेज़ देखें।
एक विशिष्ट पाइपलाइन में, एक सेव्डमॉडल जिसे ट्रेनर घटक में प्रशिक्षित किया गया है, उसे पहले एक इन्फ्रावैलिडेटर घटक में इन्फ्रा-मान्य किया जाएगा। इन्फ्रावैलिडेटर ने वास्तव में सेव्डमॉडल की सेवा के लिए एक कैनरी टीएफएस मॉडल सर्वर लॉन्च किया है। यदि सत्यापन पारित हो गया है, तो एक पुशर घटक अंततः सेव्डमॉडल को आपके टीएफएस बुनियादी ढांचे में तैनात करेगा। इसमें कई संस्करणों और मॉडल अपडेट को संभालना शामिल है।
नेटिव मोबाइल और IoT अनुप्रयोगों में अनुमान: TensorFlow Lite
TensorFlow Lite उपकरणों का एक सूट है जो डेवलपर्स को देशी मोबाइल और IoT अनुप्रयोगों में अपने प्रशिक्षित TensorFlow मॉडल का उपयोग करने में मदद करने के लिए समर्पित है। यह TensorFlow सर्विंग के समान SavedModels का उपभोग करता है, और मोबाइल और IoT उपकरणों पर चलने की चुनौतियों के लिए परिणामी मॉडल के आकार और प्रदर्शन को अनुकूलित करने के लिए परिमाणीकरण और छंटाई जैसे अनुकूलन लागू करता है। TensorFlow Lite के उपयोग के बारे में अधिक जानकारी के लिए TensorFlow Lite दस्तावेज़ देखें।
जावास्क्रिप्ट में अनुमान: TensorFlow JS
TensorFlow JS ब्राउज़र और Node.js पर एमएल मॉडल के प्रशिक्षण और तैनाती के लिए एक जावास्क्रिप्ट लाइब्रेरी है। यह TensorFlow सर्विंग और TensorFlow Lite के समान SaveModels का उपभोग करता है, और उन्हें TensorFlow.js वेब प्रारूप में परिवर्तित करता है। TensorFlow JS के उपयोग के बारे में अधिक जानकारी के लिए TensorFlow JS दस्तावेज़ देखें।
एयरफ्लो के साथ एक टीएफएक्स पाइपलाइन बनाना
विवरण के लिए एयरफ़्लो कार्यशाला की जाँच करें
क्यूबफ्लो के साथ एक टीएफएक्स पाइपलाइन बनाना
स्थापित करना
क्यूबफ़्लो को पाइपलाइनों को बड़े पैमाने पर चलाने के लिए कुबेरनेट्स क्लस्टर की आवश्यकता होती है। क्यूबफ़्लो परिनियोजन दिशानिर्देश देखें जो क्यूबफ़्लो क्लस्टर को तैनात करने के विकल्पों के माध्यम से मार्गदर्शन करता है।
टीएफएक्स पाइपलाइन को कॉन्फ़िगर करें और चलाएं
क्यूबफ्लो पर टीएफएक्स उदाहरण पाइपलाइन चलाने के लिए कृपया टीएफएक्स ऑन क्लाउड एआई प्लेटफॉर्म पाइपलाइन ट्यूटोरियल का पालन करें। टीएफएक्स घटकों को क्यूबफ्लो पाइपलाइन बनाने के लिए कंटेनरीकृत किया गया है और नमूना बड़े सार्वजनिक डेटासेट को पढ़ने और क्लाउड में बड़े पैमाने पर प्रशिक्षण और डेटा प्रोसेसिंग चरणों को निष्पादित करने के लिए पाइपलाइन को कॉन्फ़िगर करने की क्षमता को दर्शाता है।
पाइपलाइन क्रियाओं के लिए कमांड लाइन इंटरफ़ेस
टीएफएक्स एक एकीकृत सीएलआई प्रदान करता है जो अपाचे एयरफ्लो, अपाचे बीम और क्यूबफ्लो सहित विभिन्न ऑर्केस्ट्रेटर्स पर पाइपलाइन बनाने, अपडेट करने, चलाने, सूचीबद्ध करने और हटाने जैसी पाइपलाइन क्रियाओं की पूरी श्रृंखला करने में मदद करता है। विवरण के लिए, कृपया इन निर्देशों का पालन करें।