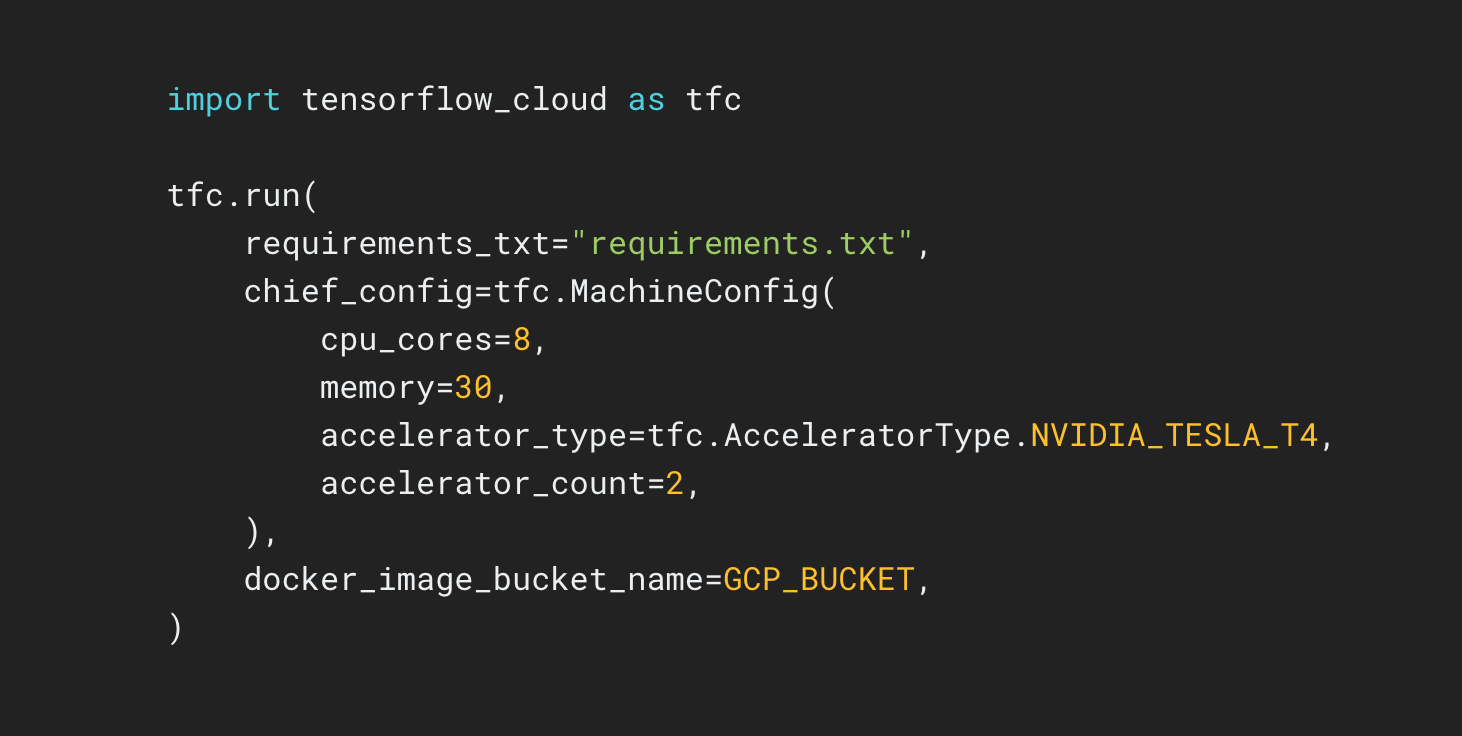
TensorFlow Cloud는 로컬 환경을 Google Cloud에 연결해 주는 라이브러리입니다.
import tensorflow_cloud as tfc TF_GPU_IMAGE= "tensorflow/tensorflow:latest-gpu" run_parameters = [ distribution_strategy='auto', requirements_txt='requirements.txt', docker_config=tfc.DockerConfig( parent_image=TF_GPU_IMAGE, image_build_bucket=GCS_BUCKET ), chief_config=tfc.COMMON_MACHINE_CONFIGS['K80_1X'], worker_config=tfc.COMMON_MACHINE_CONFIGS['K80_1X'], worker_count=3, job_labels={'job': "my_job"} ] run(**run_parameters) # Runs your training on Google Cloud!
TensorFlow Cloud Repository는 로컬 모델 빌드 및 디버깅에서 Google Cloud의 분산형 학습 및 초매개변수 조정으로 쉽게 전환할 수 있는 API를 제공합니다. Cloud Console을 사용하지 않고 Colab, Kaggle Notebook 또는 로컬 스크립트 파일 내에서 Cloud를 직접 미세 조정 또는 학습을 위한 모델을 전송할 수 있습니다.