
این راهنما نحوه استفاده از ابزارهای موجود با TensorFlow Profiler را برای ردیابی عملکرد مدلهای TensorFlow نشان میدهد. شما یاد خواهید گرفت که چگونه عملکرد مدل خود را در هاست (CPU)، دستگاه (GPU) یا ترکیبی از هر دو میزبان و دستگاه(ها) درک کنید.
نمایه سازی به درک مصرف منابع سخت افزاری (زمان و حافظه) عملیات (ops) مختلف TensorFlow در مدل شما و رفع تنگناهای عملکرد کمک می کند و در نهایت باعث می شود مدل سریعتر اجرا شود.
این راهنما نحوه نصب Profiler، ابزارهای مختلف موجود، حالتهای مختلف نحوه جمعآوری دادههای عملکرد توسط Profiler و برخی از بهترین روشهای توصیهشده برای بهینهسازی عملکرد مدل را به شما آموزش میدهد.
اگر میخواهید عملکرد مدل خود را در Cloud TPU نمایه کنید، به راهنمای Cloud TPU مراجعه کنید.
پیش نیازهای Profiler و GPU را نصب کنید
افزونه Profiler را برای TensorBoard با پیپ نصب کنید. توجه داشته باشید که Profiler به آخرین نسخه های TensorFlow و TensorBoard (>=2.2) نیاز دارد.
pip install -U tensorboard_plugin_profile
برای نمایه در GPU، باید:
- درایورهای NVIDIA® GPU و الزامات CUDA® Toolkit فهرست شده در الزامات نرم افزار پشتیبانی GPU TensorFlow را برآورده کنید.
اطمینان حاصل کنید که رابط NVIDIA® CUDA® Profileng Tools (CUPTI) در مسیر وجود دارد:
/sbin/ldconfig -N -v $(sed 's/:/ /g' <<< $LD_LIBRARY_PATH) | \ grep libcupti
اگر CUPTI را در مسیر ندارید، دایرکتوری نصب آن را به متغیر محیطی $LD_LIBRARY_PATH با اجرای:
export LD_LIBRARY_PATH=/usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
سپس، دوباره دستور ldconfig را در بالا اجرا کنید تا بررسی کنید که کتابخانه CUPTI پیدا شده است.
مسائل مربوط به امتیازات را حل کنید
هنگامی که نمایه سازی را با CUDA® Toolkit در یک محیط Docker یا در لینوکس اجرا می کنید، ممکن است با مشکلات مربوط به امتیازات ناکافی CUPTI ( CUPTI_ERROR_INSUFFICIENT_PRIVILEGES ) مواجه شوید. برای کسب اطلاعات بیشتر در مورد نحوه حل این مشکلات در لینوکس، به سندنگار توسعه دهنده NVIDIA بروید.
برای حل مسائل مربوط به امتیازات CUPTI در محیط Docker، اجرا کنید
docker run option '--privileged=true'
ابزارهای پروفایل
از تب Profile در TensorBoard به Profiler دسترسی پیدا کنید، که فقط پس از گرفتن برخی از داده های مدل ظاهر می شود.
Profiler دارای مجموعه ای از ابزارها برای کمک به تجزیه و تحلیل عملکرد است:
- صفحه نمای کلی
- آنالایزر خط لوله ورودی
- آمار TensorFlow
- نمایشگر ردیابی
- آمار هسته GPU
- ابزار نمایه حافظه
- نمایشگر پاد
صفحه نمای کلی
صفحه نمای کلی نمای سطح بالایی از عملکرد مدل شما در طول اجرای نمایه ارائه می دهد. این صفحه یک صفحه نمای کلی برای هاست و همه دستگاهها و توصیههایی برای بهبود عملکرد آموزش مدل به شما نشان میدهد. همچنین می توانید هاست های جداگانه را در منوی کشویی Host انتخاب کنید.
صفحه نمای کلی داده ها را به صورت زیر نمایش می دهد:
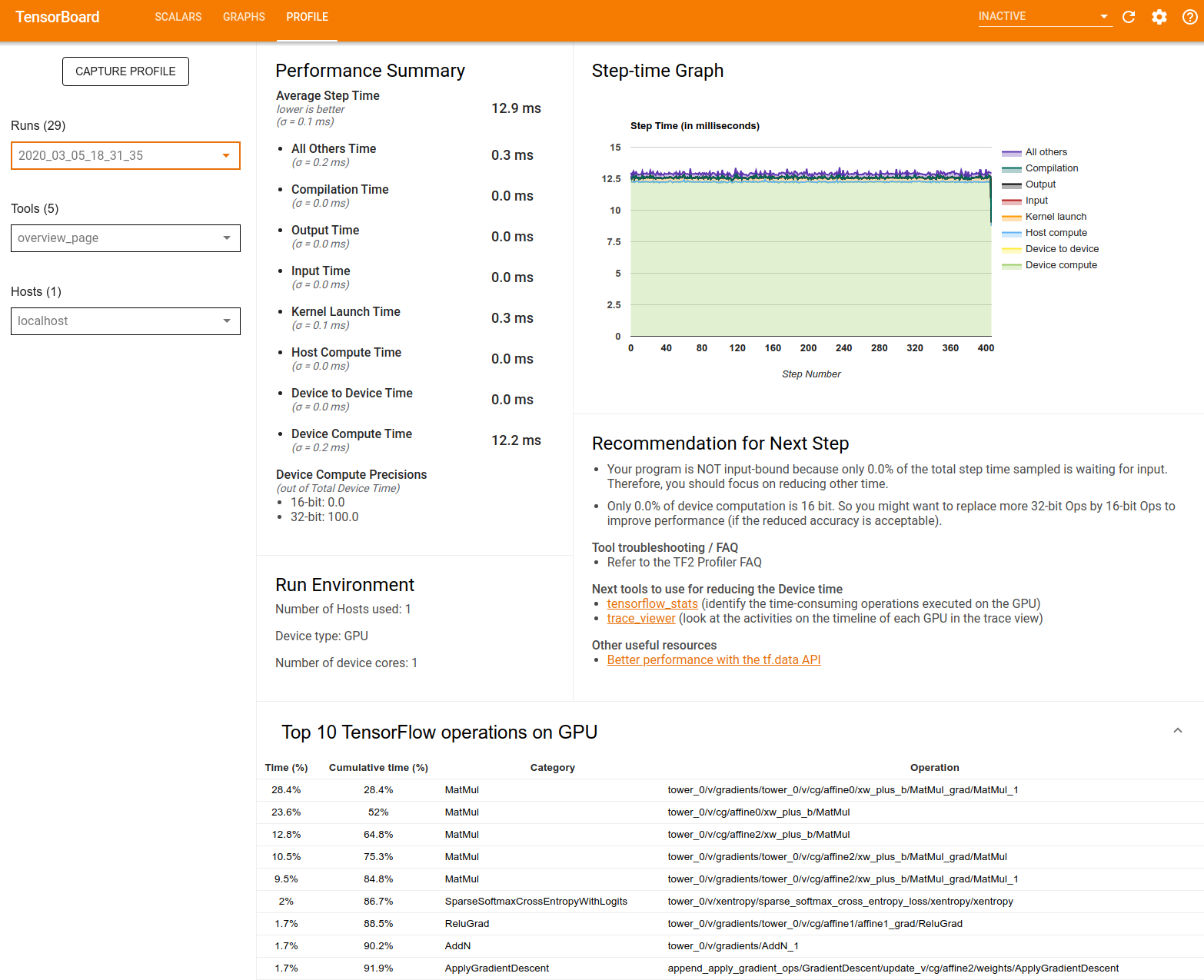
خلاصه عملکرد : خلاصه سطح بالایی از عملکرد مدل شما را نمایش می دهد. خلاصه عملکرد دو بخش دارد:
تفکیک مرحله-زمان: میانگین زمان گام را به چند دسته تقسیم می کند که زمان صرف شده است:
- کامپایل: زمان صرف شده برای کامپایل کردن کرنل ها.
- ورودی: زمان صرف شده برای خواندن داده های ورودی.
- خروجی: زمان صرف شده برای خواندن داده های خروجی.
- راهاندازی هسته: زمان صرف شده توسط میزبان برای راهاندازی هستهها
- زمان محاسبه میزبان..
- زمان ارتباط دستگاه به دستگاه
- زمان محاسبه روی دستگاه
- بقیه، از جمله سربار پایتون.
Device compute precisions - درصد زمان محاسبه دستگاه را گزارش می دهد که از محاسبات 16 و 32 بیتی استفاده می کند.
نمودار مرحلهای : نموداری از زمان گام دستگاه (بر حسب میلیثانیه) در تمام مراحل نمونهبرداری شده را نشان میدهد. هر مرحله به دسته بندی های متعدد (با رنگ های مختلف) که در آن زمان صرف می شود، تقسیم می شود. ناحیه قرمز مربوط به قسمتی از مرحله زمانی است که دستگاهها در حالت بیکار در انتظار دریافت دادههای ورودی از میزبان بودند. منطقه سبز نشان می دهد که دستگاه واقعاً چه مدت زمان کار کرده است.
10 عملیات برتر TensorFlow در دستگاه (مثلاً GPU) : عملیات روی دستگاه را که طولانی ترین زمان را اجرا کرده اند نشان می دهد.
هر ردیف زمان خود عملیات (به عنوان درصد زمان صرف شده توسط همه عملیات ها)، زمان تجمعی، دسته بندی و نام را نشان می دهد.
Run Environment : خلاصه سطح بالایی از محیط اجرای مدل را نشان می دهد که شامل:
- تعداد هاست های استفاده شده
- نوع دستگاه (GPU/TPU).
- تعداد هسته های دستگاه
توصیه برای مرحله بعدی : زمانی را گزارش میکند که یک مدل محدود به ورودی است و ابزارهایی را توصیه میکند که میتوانید برای پیدا کردن و رفع تنگناهای عملکرد مدل استفاده کنید.
تحلیلگر خط لوله ورودی
هنگامی که یک برنامه TensorFlow داده ها را از یک فایل می خواند، از بالای نمودار TensorFlow به صورت خط لوله شروع می شود. فرآیند خواندن به چند مرحله پردازش داده تقسیم می شود که به صورت سری به هم متصل شده اند، که در آن خروجی یک مرحله ورودی مرحله بعدی است. این سیستم خواندن داده ها را خط لوله ورودی می نامند.
یک خط لوله معمولی برای خواندن رکوردها از پرونده ها دارای مراحل زیر است:
- خواندن فایل.
- پیش پردازش فایل (اختیاری).
- انتقال فایل از هاست به دستگاه
یک خط لوله ورودی ناکارآمد می تواند برنامه شما را به شدت کند کند. یک برنامه زمانی محدود به ورودی در نظر گرفته می شود که بخش قابل توجهی از زمان را در خط لوله ورودی صرف کند. از بینش بهدستآمده از تحلیلگر خط لوله ورودی برای درک اینکه خط لوله ورودی کجا ناکارآمد است، استفاده کنید.
تحلیلگر خط لوله ورودی فوراً به شما می گوید که آیا برنامه شما محدود به ورودی است یا خیر و شما را در تجزیه و تحلیل سمت دستگاه و میزبان راهنمایی می کند تا گلوگاه های عملکرد را در هر مرحله از خط لوله ورودی رفع اشکال کنید.
راهنمای عملکرد خط لوله ورودی را برای بهترین شیوه های توصیه شده برای بهینه سازی خطوط لوله ورودی داده خود بررسی کنید.
داشبورد خط لوله ورودی
برای باز کردن تحلیلگر خط لوله ورودی، Profile را انتخاب کنید، سپس input_pipeline_analyzer را از منوی کشویی Tools انتخاب کنید.
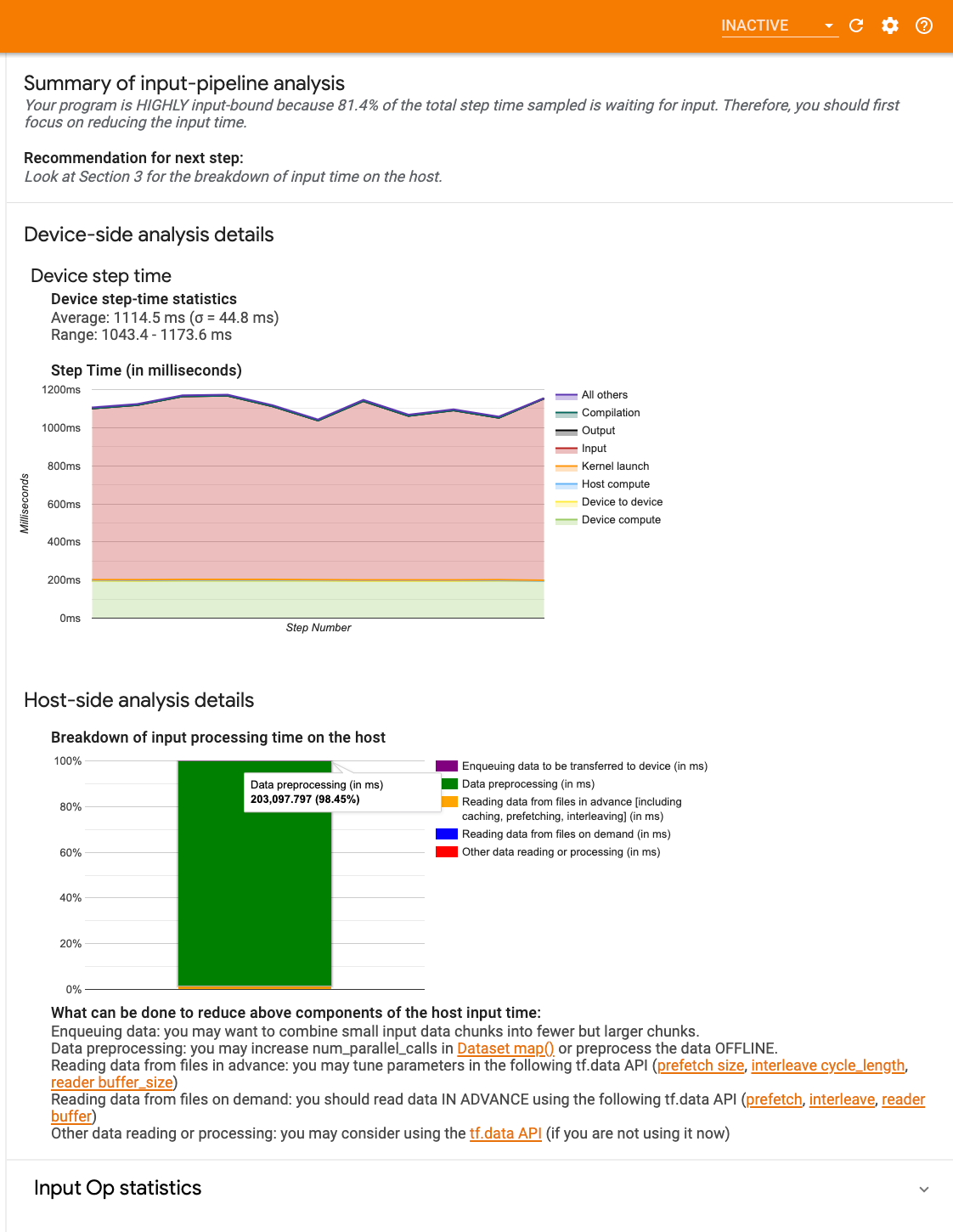
داشبورد شامل سه بخش است:
- خلاصه : خط لوله ورودی کلی را با اطلاعاتی در مورد اینکه آیا برنامه شما محدود به ورودی است و اگر چنین است، به چه میزان خلاصه می کند.
- تجزیه و تحلیل سمت دستگاه : نتایج تجزیه و تحلیل دقیق و در سمت دستگاه را نشان می دهد، از جمله زمان گام دستگاه و محدوده زمانی که دستگاه صرف انتظار برای داده های ورودی در هسته ها در هر مرحله می شود.
- تجزیه و تحلیل سمت میزبان : تجزیه و تحلیل دقیق در سمت میزبان، از جمله تجزیه و تحلیل زمان پردازش ورودی در میزبان را نشان می دهد.
خلاصه خط لوله ورودی
خلاصه گزارش می دهد که آیا برنامه شما محدود به ورودی است، با ارائه درصدی از زمان صرف شده دستگاه برای انتظار برای ورودی از میزبان. اگر از یک خط لوله ورودی استاندارد استفاده می کنید که ابزار دقیقی دارد، ابزار گزارش می دهد که بیشتر زمان پردازش ورودی در کجا سپری شده است.
تجزیه و تحلیل سمت دستگاه
تجزیه و تحلیل سمت دستگاه، بینش هایی را در مورد زمان صرف شده در دستگاه در مقابل میزبان و مدت زمان صرف شده دستگاه در انتظار داده های ورودی از میزبان ارائه می دهد.
- نمودار زمان گام در برابر شماره مرحله : نموداری از زمان گام دستگاه (بر حسب میلی ثانیه) را در تمام مراحل نمونه نشان می دهد. هر مرحله به دسته بندی های متعدد (با رنگ های مختلف) که در آن زمان صرف می شود، تقسیم می شود. ناحیه قرمز مربوط به قسمتی از مرحله زمانی است که دستگاهها در حالت بیکار در انتظار دریافت دادههای ورودی از میزبان بودند. ناحیه سبز نشان می دهد که دستگاه واقعاً چه مقدار از زمان کار می کرد.
- آمار زمان مرحله : میانگین، انحراف استاندارد، و محدوده ([حداقل، حداکثر]) زمان گام دستگاه را گزارش می کند.
تجزیه و تحلیل سمت میزبان
تجزیه و تحلیل سمت میزبان، زمان پردازش ورودی (زمان صرف شده برای عملیات API tf.data ) در میزبان را به چند دسته گزارش میکند:
- خواندن دادهها از فایلهای درخواستی : زمان صرف شده برای خواندن دادهها از فایلها بدون ذخیرهسازی، واکشی اولیه، و interleaving.
- خواندن پیشاپیش دادهها از فایلها : زمان صرف شده برای خواندن فایلها، از جمله ذخیرهسازی، واکشی پیشفرض و interleaving.
- پیش پردازش داده ها : زمان صرف شده برای عملیات پیش پردازش، مانند رفع فشرده سازی تصویر.
- در صف قرار دادن داده ها برای انتقال به دستگاه : زمان صرف شده برای قرار دادن داده ها در صف ورودی قبل از انتقال داده ها به دستگاه.
Input Op Statistics را گسترش دهید تا آمار عملیات ورودی منفرد و دسته بندی آنها را بر اساس زمان اجرا بررسی کنید.
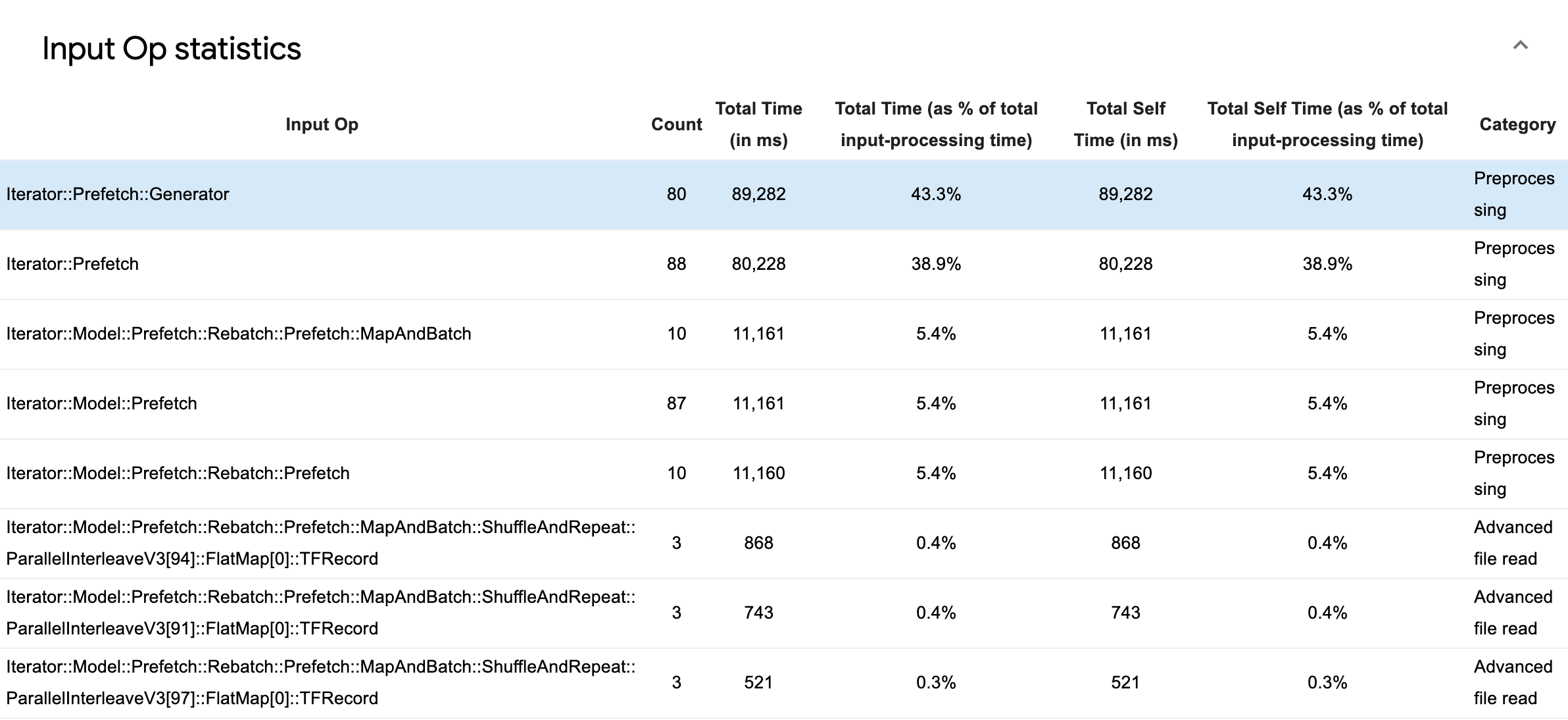
یک جدول داده منبع با هر ورودی حاوی اطلاعات زیر ظاهر می شود:
- Input Op : نام عملیات TensorFlow عملیات ورودی را نشان می دهد.
- تعداد : تعداد کل نمونه های اجرای عملیات را در طول دوره نمایه سازی نشان می دهد.
- مجموع زمان (بر حسب میلیثانیه) : مجموع زمان صرف شده برای هر یک از آن نمونهها را نشان میدهد.
- % زمان کل : کل زمان صرف شده در یک عملیات را به عنوان کسری از کل زمان صرف شده در پردازش ورودی نشان می دهد.
- مجموع زمان شخصی (بر حسب میلیثانیه) : مجموع زمان خود صرف شده برای هر یک از آن نمونهها را نشان میدهد. زمان خود در اینجا زمان صرف شده در داخل بدنه تابع را اندازه گیری می کند، به استثنای زمان صرف شده در تابعی که فراخوانی می کند.
- کل زمان خود ٪ . کل زمان خود را به عنوان کسری از کل زمان صرف شده برای پردازش ورودی نشان می دهد.
- دسته بندی . دسته پردازشی عملیات ورودی را نشان می دهد.
آمار TensorFlow
ابزار TensorFlow Stats عملکرد هر عملیات TensorFlow (op) که در هاست یا دستگاه در طول یک جلسه پروفایل اجرا می شود را نمایش می دهد.
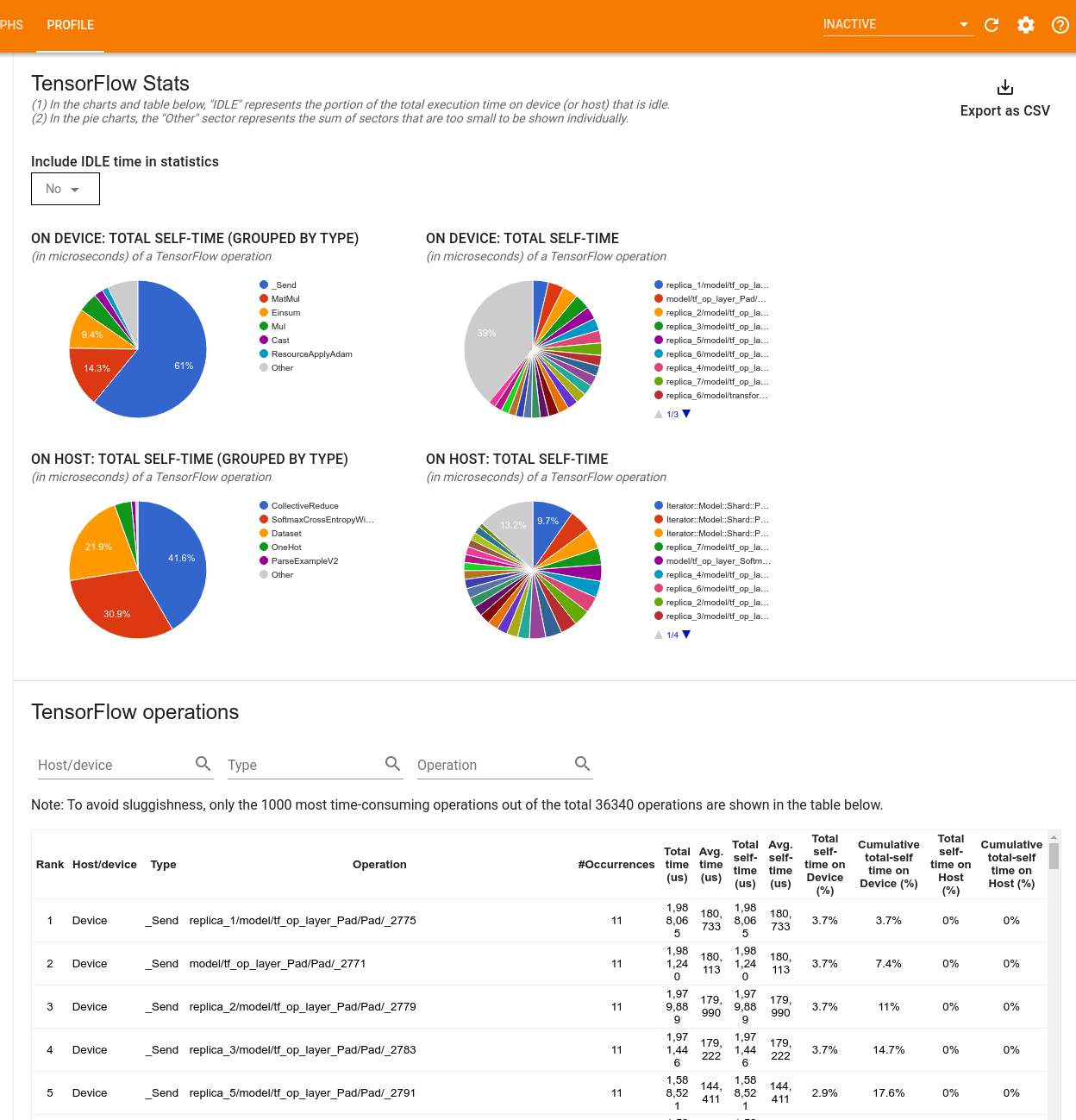
این ابزار اطلاعات عملکرد را در دو صفحه نمایش می دهد:
پنجره بالایی حداکثر چهار نمودار دایره ای را نمایش می دهد:
- توزیع زمان خوداجرای هر عملیات روی هاست.
- توزیع زمان خوداجرای هر نوع عملیات روی هاست.
- توزیع زمان خوداجرای هر عملیات بر روی دستگاه.
- توزیع زمان خوداجرای هر نوع عملیات بر روی دستگاه.
پنجره پایین جدولی را نشان می دهد که داده های مربوط به عملیات TensorFlow را با یک ردیف برای هر عملیات و یک ستون برای هر نوع داده گزارش می دهد (مرتب سازی ستون ها با کلیک بر روی عنوان ستون). روی دکمه Export as CSV در سمت راست پنجره بالایی کلیک کنید تا داده ها از این جدول به عنوان یک فایل CSV صادر شود.
توجه داشته باشید که:
اگر هر عملیاتی دارای عملیات کودک است:
- کل زمان "انباشته" یک عملیات شامل زمان صرف شده در داخل عملیات کودک می شود.
- کل زمان "خود" یک عملیات شامل زمان صرف شده در داخل عملیات کودک نمی شود.
اگر یک عملیات روی هاست اجرا شود:
- درصد کل زمان خودگردانی که در دستگاه متحمل شده است، 0 خواهد بود.
- درصد تجمعی کل زمان خودکار روی دستگاه تا و از جمله این عملیات 0 خواهد بود.
اگر یک عملیات روی دستگاه اجرا شود:
- درصد کل زمان خودگردانی که در میزبان متحمل شده توسط این عملیات 0 خواهد بود.
- درصد تجمعی کل زمان خود در میزبان تا و از جمله این عملیات 0 خواهد بود.
شما می توانید انتخاب کنید که زمان بیکاری را در نمودارها و جدول دایره ای گنجانده یا حذف کنید.
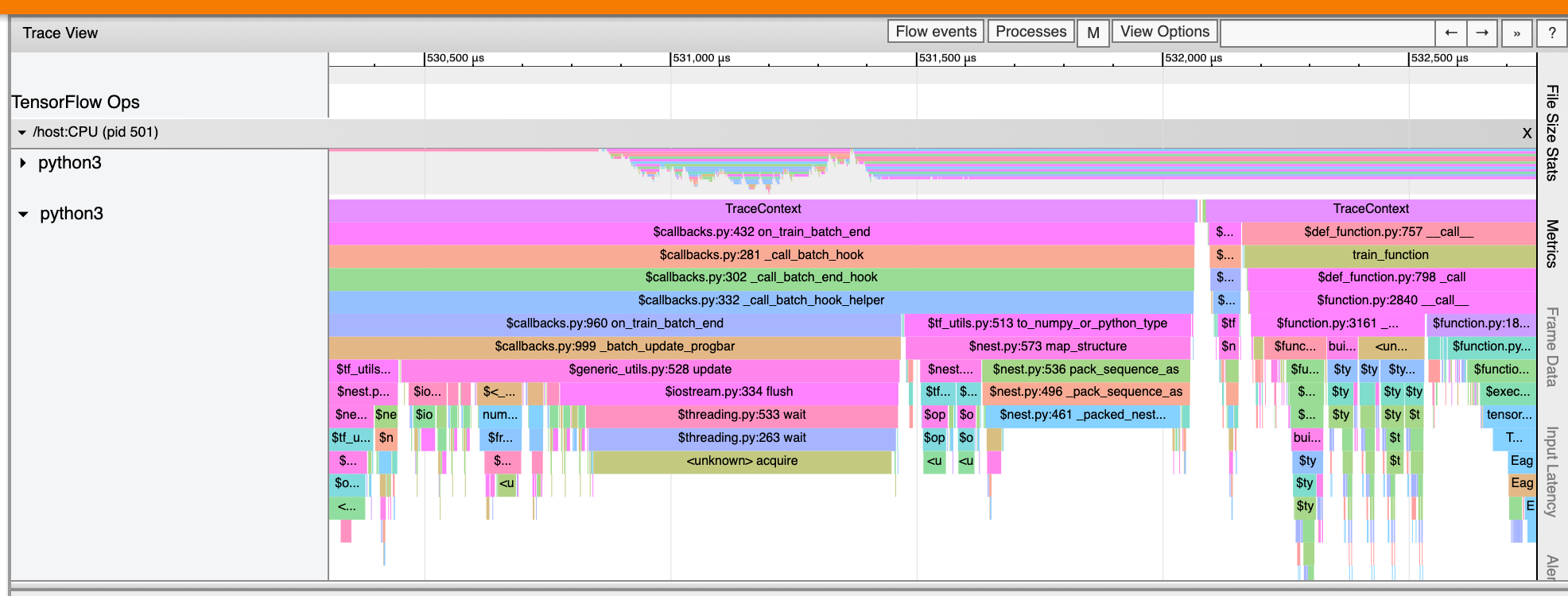
ردیابی بیننده
نمایشگر ردیابی یک جدول زمانی نمایش می دهد که نشان می دهد:
- مدت زمان عملیاتی که توسط مدل TensorFlow شما اجرا شده است
- کدام قسمت از سیستم (میزبان یا دستگاه) یک عملیات را اجرا می کند. به طور معمول، میزبان عملیات ورودی را اجرا می کند، داده های آموزشی را پیش پردازش می کند و آنها را به دستگاه منتقل می کند، در حالی که دستگاه آموزش مدل واقعی را اجرا می کند.
نمایشگر ردیابی به شما این امکان را می دهد تا مشکلات عملکرد مدل خود را شناسایی کنید، سپس برای حل آنها قدم بردارید. به عنوان مثال، در یک سطح بالا، می توانید تشخیص دهید که آیا آموزش ورودی یا مدل اکثر زمان را می گیرد. با حفاری، می توانید تشخیص دهید که اجرای کدام عملیات طولانی ترین زمان را می برد. توجه داشته باشید که نمایشگر ردیابی به 1 میلیون رویداد در هر دستگاه محدود شده است.
ردیابی رابط بیننده
هنگامی که نمایشگر ردیابی را باز می کنید، ظاهر می شود که آخرین اجرای شما را نشان می دهد:
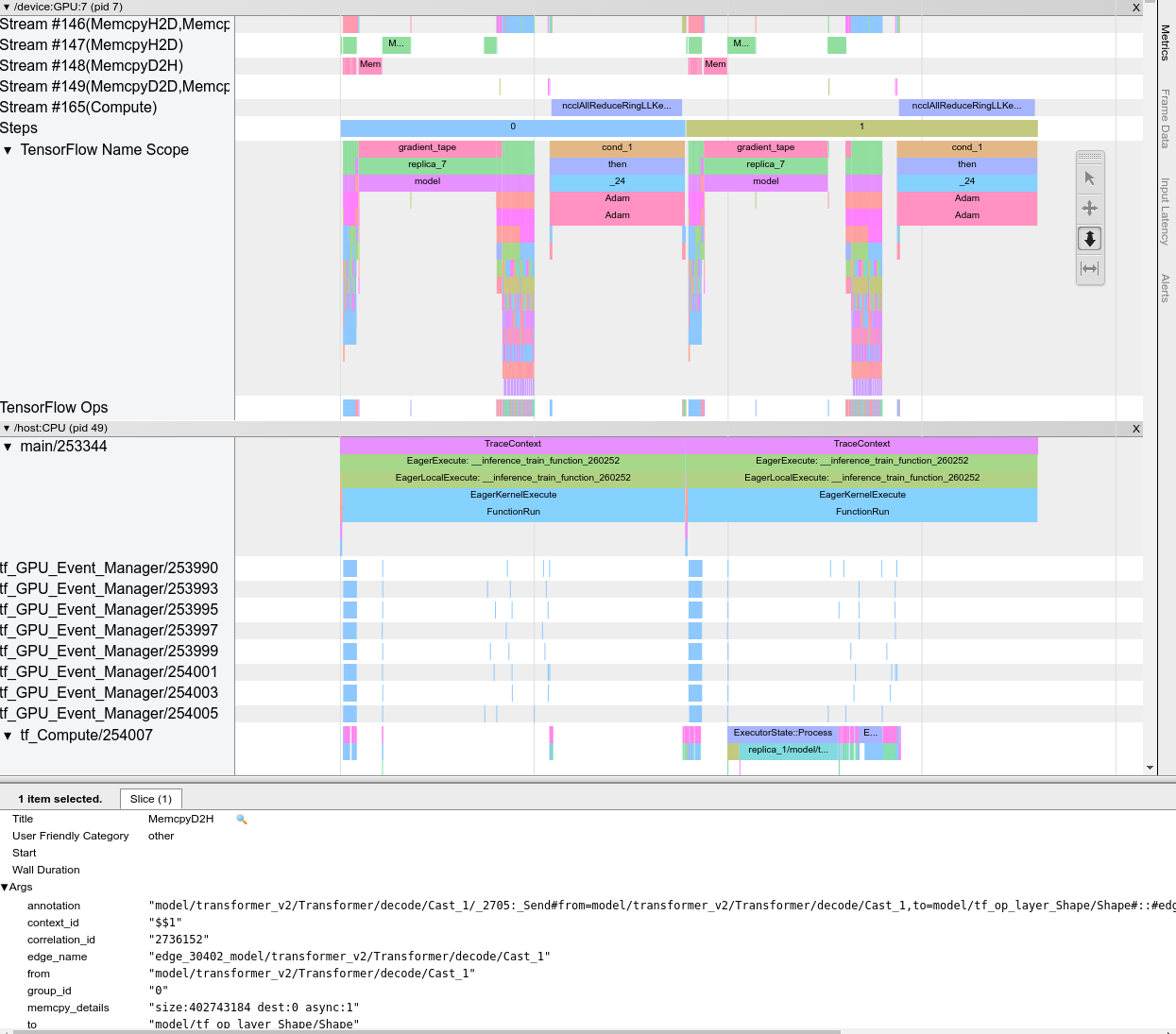
این صفحه شامل عناصر اصلی زیر است:
- صفحه زمان : عملیاتی را که دستگاه و میزبان در طول زمان اجرا کرده اند را نشان می دهد.
- صفحه جزئیات : اطلاعات اضافی را برای عملیات انتخاب شده در بخش Timeline نشان می دهد.
پنجره Timeline شامل عناصر زیر است:
- نوار بالا : شامل کنترل های مختلف کمکی است.
- محور زمان : زمان را نسبت به ابتدای ردیابی نشان می دهد.
- برچسبهای بخش و آهنگ : هر بخش شامل چندین آهنگ است و یک مثلث در سمت چپ دارد که میتوانید روی آن کلیک کنید تا بخش را بزرگ و کوچک کنید. برای هر عنصر پردازشی در سیستم یک بخش وجود دارد.
- انتخابگر ابزار : شامل ابزارهای مختلفی برای تعامل با نمایشگر ردیابی مانند زوم، پان، انتخاب و زمان بندی است. از ابزار Timeming برای علامت گذاری یک بازه زمانی استفاده کنید.
- رویدادها : اینها زمان اجرای عملیات یا مدت زمان متا رویدادها، مانند مراحل آموزشی را نشان میدهند.
بخش ها و آهنگ ها
نمایشگر ردیابی شامل بخش های زیر است:
- یک بخش برای هر گره دستگاه که با شماره تراشه دستگاه و گره دستگاه در تراشه برچسب گذاری شده است (به عنوان مثال
/device:GPU:0 (pid 0)). هر بخش گره دستگاه شامل آهنگ های زیر است:- مرحله : مدت زمان مراحل آموزشی که روی دستگاه اجرا می شد را نشان می دهد
- TensorFlow Ops : عملیات اجرا شده در دستگاه را نشان می دهد
- XLA Ops : اگر XLA کامپایلر مورد استفاده باشد، عملیات XLA (ops) را نشان می دهد که روی دستگاه اجرا می شود (هر عملیات TensorFlow به یک یا چند عملیات XLA ترجمه می شود. کامپایلر XLA عملیات XLA را به کدی که روی دستگاه اجرا می شود ترجمه می کند).
- یک بخش برای رشته های در حال اجرا بر روی CPU ماشین میزبان، با برچسب "Host Threads" . این بخش شامل یک آهنگ برای هر رشته CPU است. توجه داشته باشید که می توانید اطلاعات نمایش داده شده در کنار برچسب های بخش را نادیده بگیرید.
رویدادها
رویدادهای درون جدول زمانی در رنگ های مختلف نمایش داده می شوند. خود رنگ ها معنای خاصی ندارند.
نمایشگر ردیابی همچنین میتواند آثار فراخوانی تابع پایتون را در برنامه TensorFlow شما نمایش دهد. اگر از tf.profiler.experimental.start API استفاده می کنید، می توانید ردیابی Python را با استفاده از ProfilerOptions namedtuple هنگام شروع نمایه سازی فعال کنید. همچنین، اگر از حالت نمونهگیری برای نمایهسازی استفاده میکنید، میتوانید سطح ردیابی را با استفاده از گزینههای کشویی در گفتگوی Capture Profile انتخاب کنید.
آمار هسته GPU
این ابزار آمار عملکرد و عملیات اولیه را برای هر هسته شتابدهنده GPU نشان میدهد.
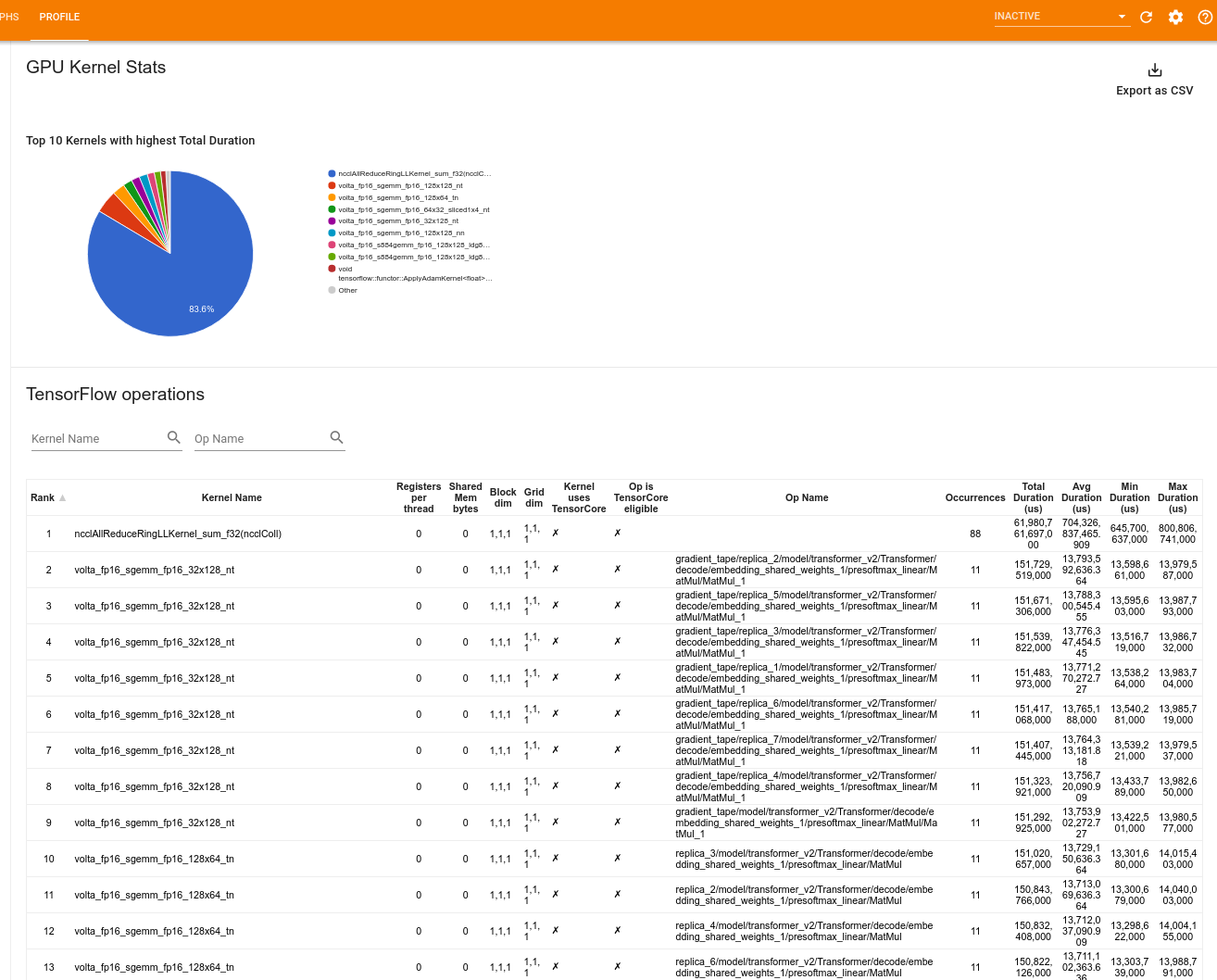
این ابزار اطلاعات را در دو صفحه نمایش می دهد:
پنجره بالایی نمودار دایره ای را نشان می دهد که هسته های CUDA را نشان می دهد که بیشترین زمان کل سپری شده را دارند.
در پنجره پایین جدولی با داده های زیر برای هر جفت هسته عملیات منحصر به فرد نمایش داده می شود:
- رتبه ای به ترتیب نزولی کل مدت زمان GPU سپری شده که بر اساس جفت هسته عملیات گروه بندی شده است.
- نام هسته راه اندازی شده.
- تعداد رجیسترهای GPU استفاده شده توسط هسته.
- اندازه کل حافظه مشترک (استاتیک + پویا مشترک) استفاده شده در بایت.
- بعد بلوک به صورت
blockDim.x, blockDim.y, blockDim.zبیان میشود. - ابعاد شبکه به صورت
gridDim.x, gridDim.y, gridDim.zبیان شده است. - اینکه آیا عملیات واجد شرایط استفاده از Tensor Cores است یا خیر.
- آیا هسته حاوی دستورالعمل های Tensor Core است یا خیر.
- نام عملیاتی که این هسته را راه اندازی کرد.
- تعداد وقوع این جفت kernel-op.
- کل زمان GPU سپری شده بر حسب میکروثانیه.
- میانگین زمان GPU سپری شده بر حسب میکروثانیه.
- حداقل زمان GPU سپری شده بر حسب میکروثانیه.
- حداکثر زمان GPU سپری شده بر حسب میکروثانیه.
ابزار نمایه حافظه
ابزار Memory Profile میزان استفاده از حافظه دستگاه شما را در بازه زمانی نمایه سازی کنترل می کند. شما می توانید از این ابزار برای موارد زیر استفاده کنید:
- با مشخص کردن حداکثر میزان مصرف حافظه و تخصیص حافظه مربوطه به عملیات TensorFlow، مشکلات مربوط به حافظه (OOM) را رفع اشکال کنید. همچنین میتوانید مشکلات OOM را که ممکن است هنگام اجرای استنتاج چند اجارهای ایجاد شود، اشکالزدایی کنید.
- اشکال زدایی مشکلات تکه تکه شدن حافظه
ابزار نمایه حافظه داده ها را در سه بخش نمایش می دهد:
- خلاصه مشخصات حافظه
- نمودار جدول زمانی حافظه
- جدول شکست حافظه
خلاصه مشخصات حافظه
این بخش خلاصه سطح بالایی از مشخصات حافظه برنامه TensorFlow شما را مطابق شکل زیر نمایش می دهد:
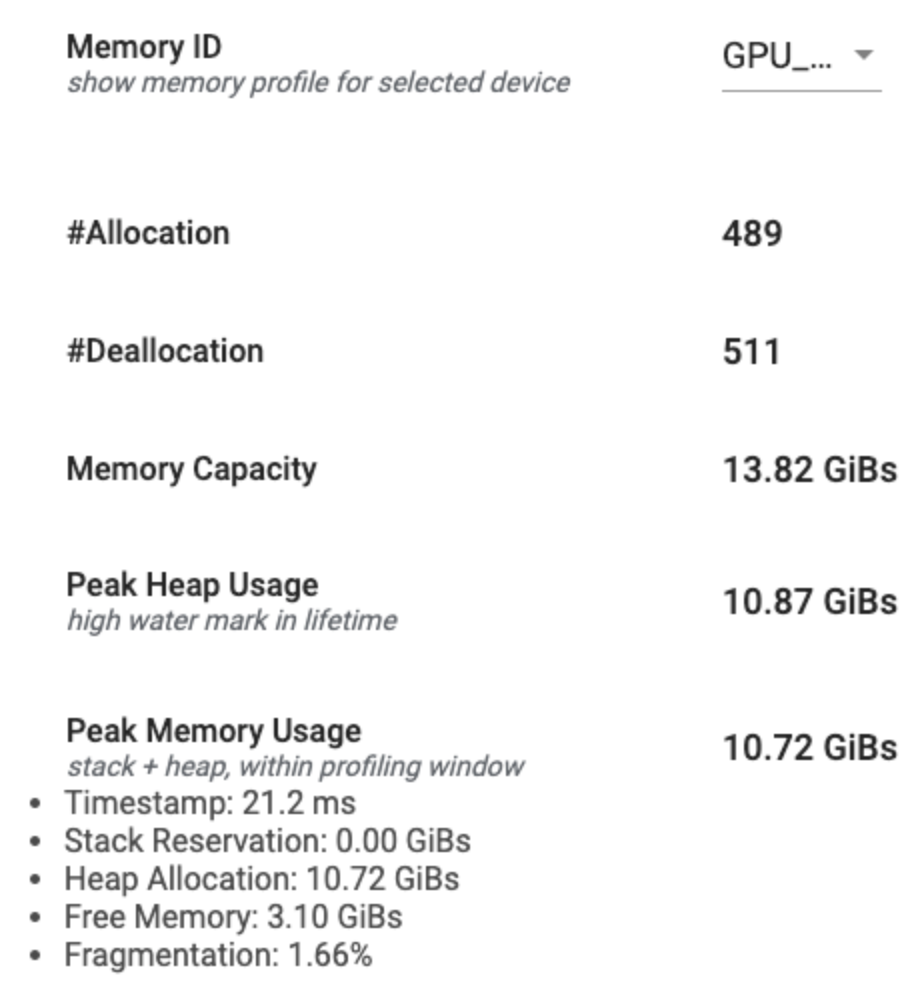
خلاصه مشخصات حافظه دارای شش قسمت است:
- شناسه حافظه : کشویی که تمام سیستم های حافظه دستگاه موجود را فهرست می کند. سیستم حافظه ای را که می خواهید مشاهده کنید از منوی کشویی انتخاب کنید.
- #تخصیص : تعداد تخصیص حافظه انجام شده در بازه نمایه سازی.
- #Deallocation : تعداد تخصیص حافظه در بازه پروفایل
- ظرفیت حافظه : ظرفیت کل (بر حسب گیگابایت) سیستم حافظه ای که انتخاب می کنید.
- حداکثر استفاده از پشته : بیشترین میزان استفاده از حافظه (در گیگابایت) از زمانی که مدل شروع به کار کرد.
- حداکثر استفاده از حافظه : حداکثر استفاده از حافظه (بر حسب گیگابایت) در فاصله پروفایل. این فیلد شامل فیلدهای فرعی زیر است:
- مهر زمانی : مُهر زمانی زمانی که بیشترین استفاده از حافظه در نمودار خط زمانی رخ داده است.
- رزرو پشته : مقدار حافظه ذخیره شده روی پشته (بر حسب گیگابایت).
- Heap Allocation : مقدار حافظه تخصیص داده شده بر روی پشته (به گیگابایت).
- حافظه آزاد : مقدار حافظه آزاد (به گیگابایت). ظرفیت حافظه جمع کل رزرو پشته، تخصیص پشته و حافظه رایگان است.
- تکه تکه شدن : درصد تکه تکه شدن (کمتر بهتر است). به عنوان درصد
(1 - Size of the largest chunk of free memory / Total free memory)محاسبه می شود.
نمودار جدول زمانی حافظه
این بخش نموداری از میزان استفاده از حافظه (در گیگابایت) و درصد تکه تکه شدن در مقابل زمان (بر حسب میلی ثانیه) را نشان می دهد.
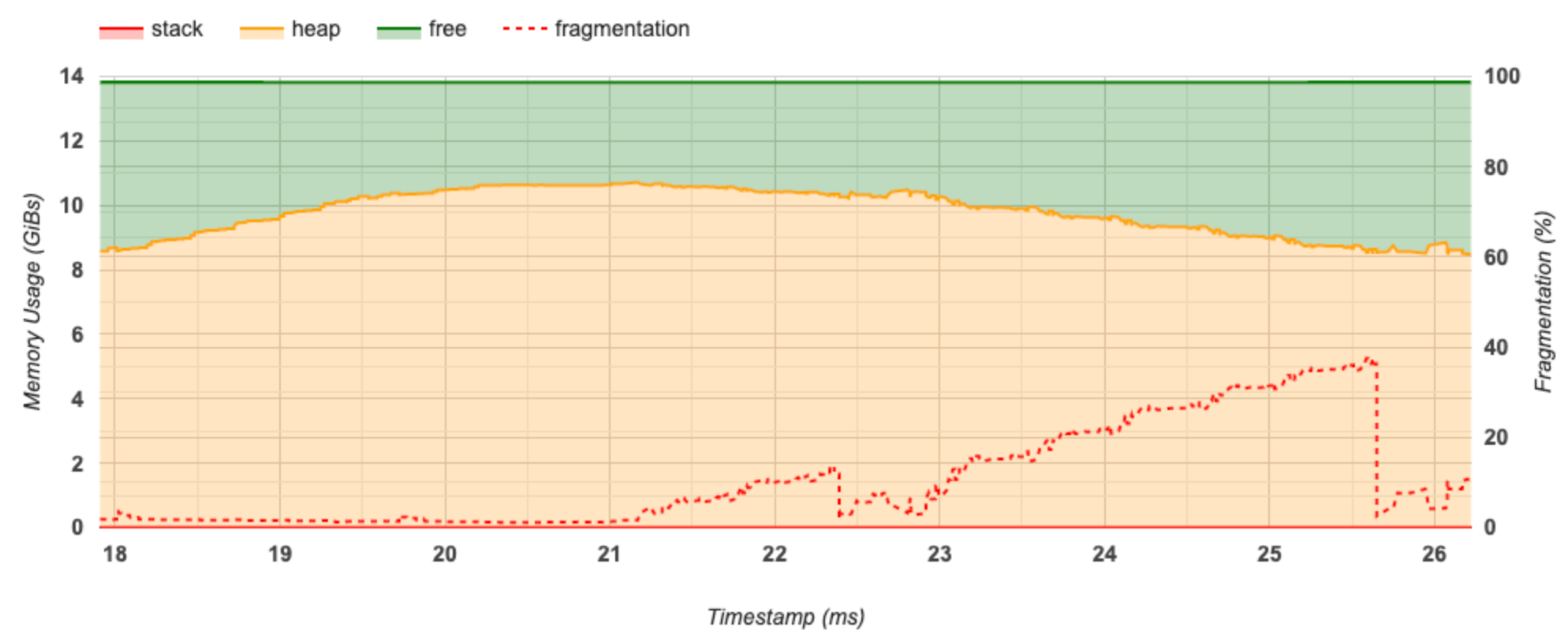
محور X نشاندهنده جدول زمانی (بر حسب میلیثانیه) بازه نمایهسازی است. محور Y در سمت چپ نشان دهنده میزان استفاده از حافظه (در GiBs) و محور Y در سمت راست نشان دهنده درصد تکه تکه شدن است. در هر نقطه از زمان در محور X، کل حافظه به سه دسته تقسیم می شود: پشته (قرمز)، پشته (به رنگ نارنجی)، و آزاد (به رنگ سبز). برای مشاهده جزئیات مربوط به رویدادهای تخصیص/تخصیص حافظه در آن نقطه مانند زیر، ماوس را روی یک مهر زمانی خاص نگه دارید:
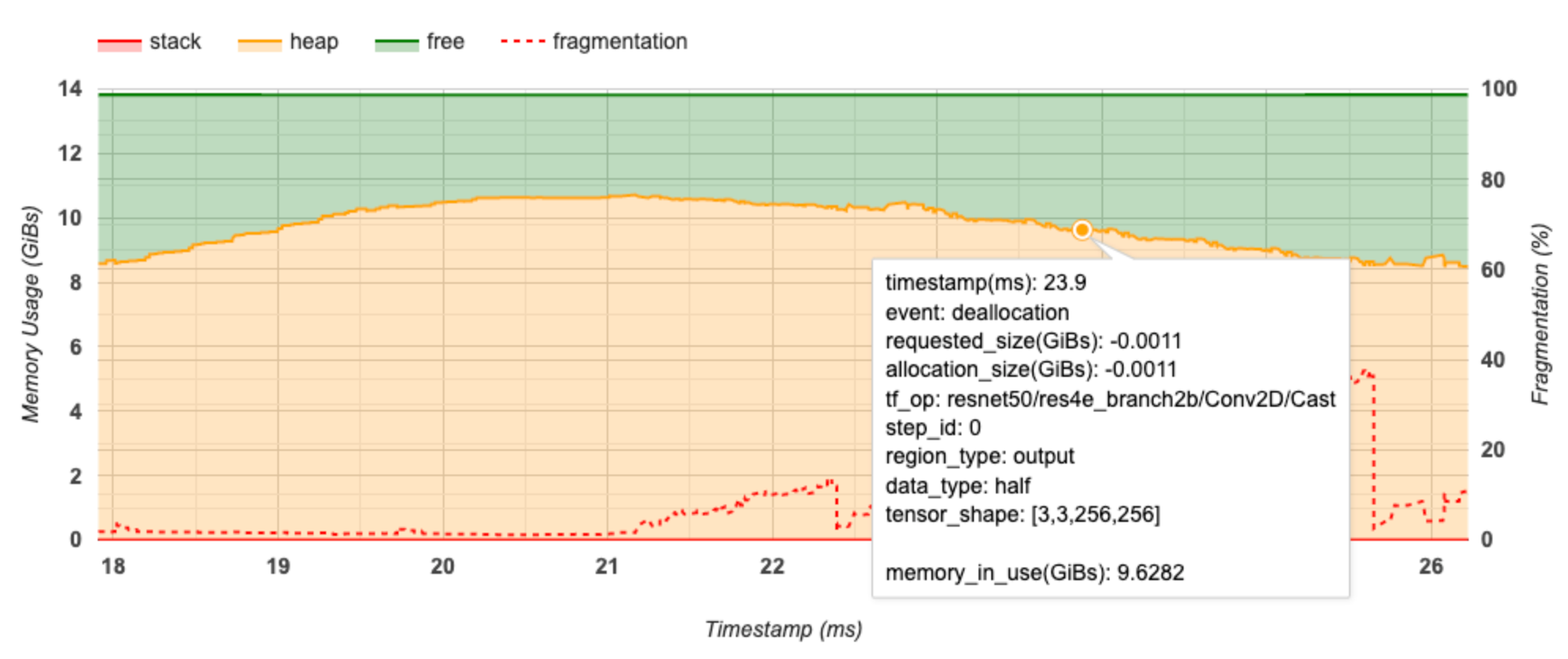
پنجره پاپ آپ اطلاعات زیر را نمایش می دهد:
- timestamp(ms) : مکان رویداد انتخاب شده در جدول زمانی.
- رویداد : نوع رویداد (تخصیص یا واگذاری).
- requested_size(GiBs) : مقدار حافظه درخواستی. این یک عدد منفی برای رویدادهای واگذاری خواهد بود.
- allocation_size(GiBs) : مقدار واقعی حافظه اختصاص داده شده. این یک عدد منفی برای رویدادهای واگذاری خواهد بود.
- tf_op : عملیات TensorFlow که تخصیص/تخصیص را درخواست می کند.
- step_id : مرحله آموزشی که این رویداد در آن رخ داده است.
- region_type : نوع داده ای که این حافظه اختصاص داده شده برای آن است. مقادیر ممکن عبارتند از
tempبرای موقت،outputبرای فعال سازی و گرادیان، وpersist/dynamicبرای وزن ها و ثابت ها. - data_type : نوع عنصر تانسور (به عنوان مثال، uint8 برای عدد صحیح بدون علامت 8 بیتی).
- tensor_shape : شکل تانسور در حال تخصیص/تخصیص.
- memory_in_use(GiBs) : کل حافظه ای که در این نقطه از زمان در حال استفاده است.
جدول خرابی حافظه
این جدول تخصیص حافظه فعال را در نقطه اوج استفاده از حافظه در بازه پروفایل نشان می دهد.
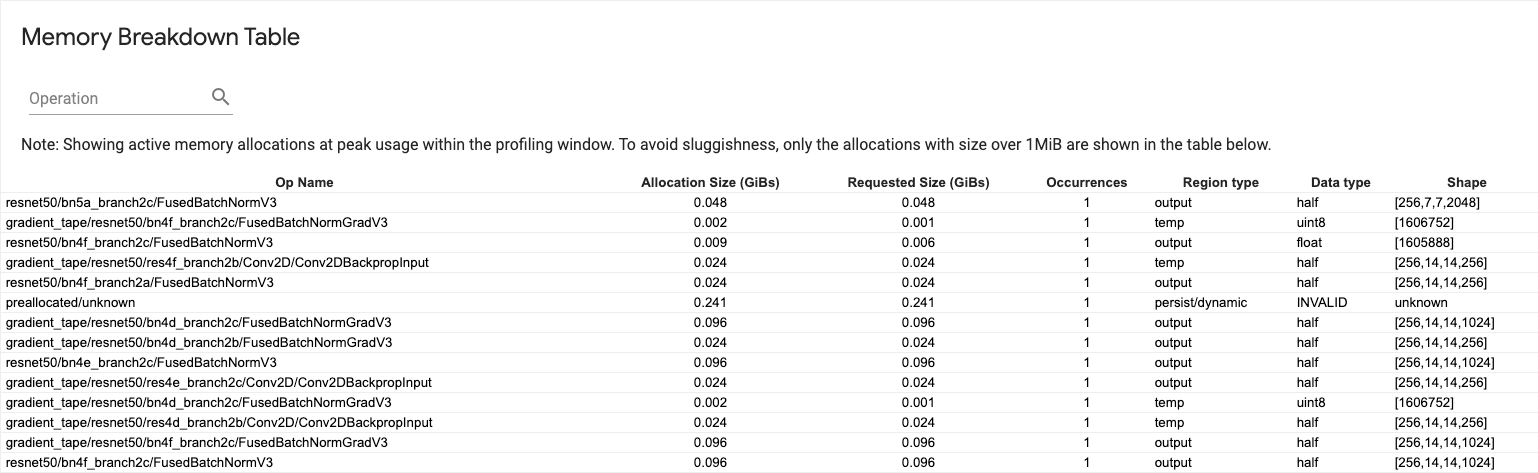
برای هر TensorFlow Op یک ردیف وجود دارد و هر سطر دارای ستون های زیر است:
- Op Name : نام عملیات TensorFlow.
- اندازه تخصیص (GiBs) : مقدار کل حافظه اختصاص داده شده به این عملیات.
- اندازه درخواستی (گیگابایت) : کل مقدار حافظه درخواستی برای این عملیات.
- رویدادها : تعداد تخصیص برای این عملیات.
- نوع منطقه : نوع موجودیت داده ای که این حافظه اختصاص داده شده برای آن است. مقادیر ممکن عبارتند از
tempبرای موقت،outputبرای فعال سازی و گرادیان، وpersist/dynamicبرای وزن ها و ثابت ها. - نوع داده : نوع عنصر تانسور.
- شکل : شکل تانسورهای اختصاص داده شده.
نمایشگر پاد
ابزار Pod Viewer تفکیک یک مرحله آموزشی را در همه کارگران نشان می دهد.
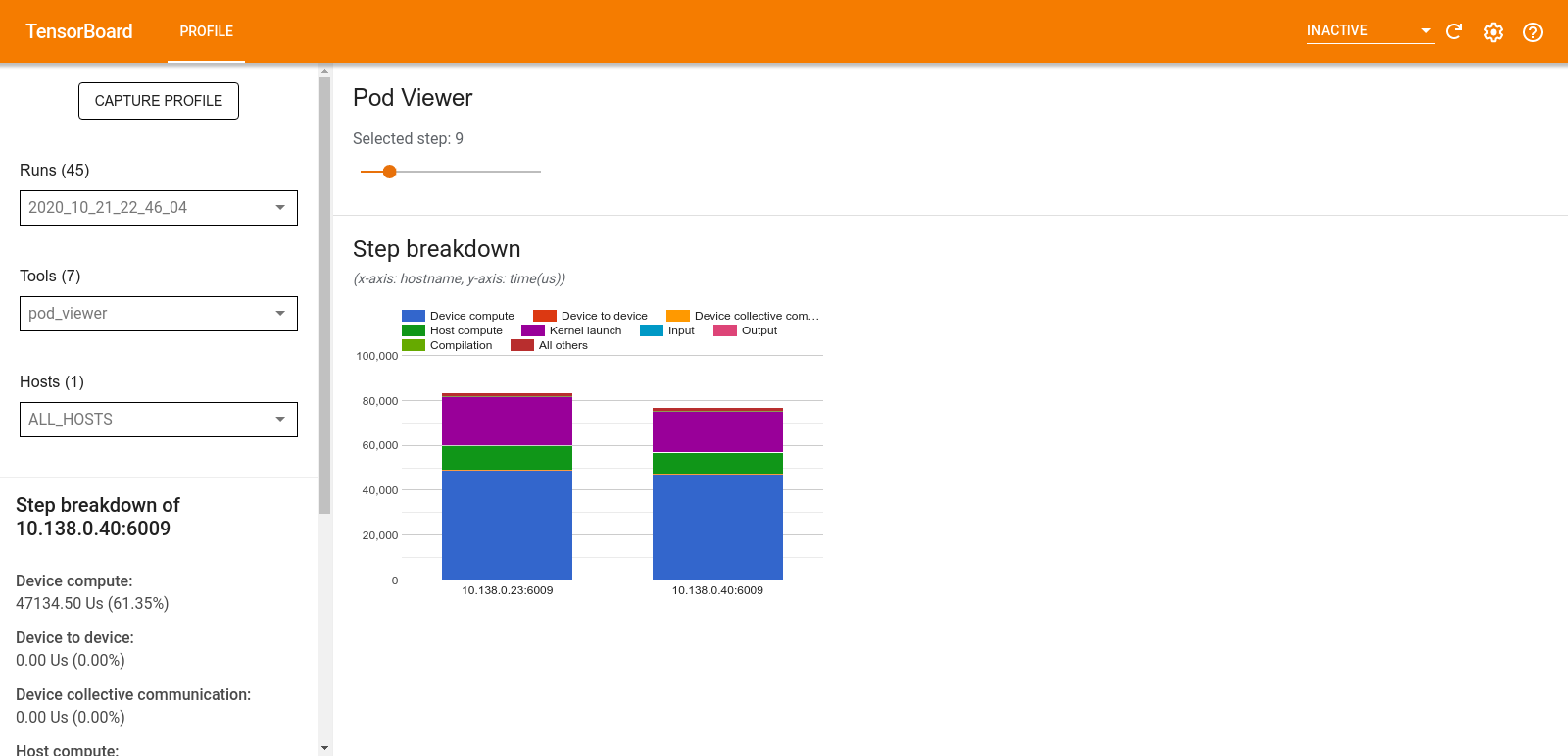
- پنجره بالایی دارای یک نوار لغزنده برای انتخاب شماره مرحله است.
- پنجره پایین یک نمودار ستونی انباشته را نشان می دهد. این نمای سطح بالایی از دسته بندی های مرحله-زمان شکسته شده است که بر روی یکدیگر قرار گرفته اند. هر ستون انباشته نشان دهنده یک کارگر منحصر به فرد است.
- وقتی ماوس را روی یک ستون انباشته نگه میدارید، کارت سمت چپ جزئیات بیشتری در مورد تفکیک مرحله نشان میدهد.
تجزیه و تحلیل تنگنای داده tf
ابزار تجزیه و تحلیل تنگنا tf.data به طور خودکار تنگناها را در خطوط لوله ورودی tf.data در برنامه شما شناسایی می کند و توصیه هایی در مورد نحوه رفع آنها ارائه می دهد. بدون در نظر گرفتن پلتفرم (CPU/GPU/TPU) با هر برنامه ای با استفاده از tf.data کار می کند. تجزیه و تحلیل و توصیه های آن بر اساس این راهنما است.
با دنبال کردن مراحل زیر یک گلوگاه را تشخیص می دهد:
- بیشترین ورودی باند میزبان را پیدا کنید.
- کندترین اجرای خط لوله ورودی
tf.dataرا پیدا کنید. - گراف خط لوله ورودی را از ردیابی پروفایلر بازسازی کنید.
- مسیر بحرانی را در نمودار خط لوله ورودی پیدا کنید.
- کندترین تحول در مسیر بحرانی را به عنوان یک گلوگاه شناسایی کنید.
رابط کاربری به سه بخش تقسیم می شود: خلاصه تجزیه و تحلیل عملکرد ، خلاصه همه خطوط لوله ورودی و نمودار خط لوله ورودی .
خلاصه تحلیل عملکرد

این بخش خلاصه ای از تحلیل را ارائه می دهد. این خط لوله های ورودی آهسته tf.data شناسایی شده در نمایه را گزارش می دهد. این بخش همچنین بیشترین میزبان محدود ورودی و کندترین خط لوله ورودی آن را با حداکثر تأخیر نشان می دهد. مهمتر از همه، مشخص می کند که کدام قسمت از خط لوله ورودی گلوگاه است و چگونه آن را تعمیر کند. اطلاعات گلوگاه با نوع تکرار کننده و نام طولانی آن ارائه می شود.
نحوه خواندن نام طولانی tf.data iterator
یک نام طولانی به صورت Iterator::<Dataset_1>::...::<Dataset_n> . در نام طولانی، <Dataset_n> با نوع تکرار کننده مطابقت دارد و مجموعه داده های دیگر در نام طولانی، تبدیل های پایین دست را نشان می دهند.
به عنوان مثال، مجموعه داده خط لوله ورودی زیر را در نظر بگیرید:
dataset = tf.data.Dataset.range(10).map(lambda x: x).repeat(2).batch(5)
نام های طولانی برای تکرار کننده ها از مجموعه داده فوق به صورت زیر خواهد بود:
| نوع تکرار کننده | نام طولانی |
|---|---|
| محدوده | تکرار کننده:: دسته:: تکرار:: نقشه:: محدوده |
| نقشه | تکرار کننده:: دسته:: تکرار:: نقشه |
| تکرار کنید | Iterator::Batch::Repeat |
| دسته ای | تکرار کننده:: دسته ای |
خلاصه تمام خطوط لوله ورودی
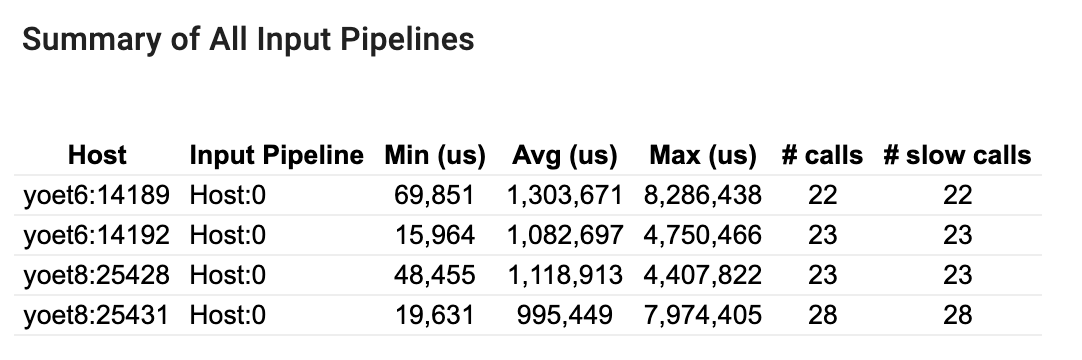
این بخش خلاصه ای از تمام خطوط لوله ورودی در همه میزبان ها را ارائه می دهد. به طور معمول یک خط لوله ورودی وجود دارد. هنگام استفاده از استراتژی توزیع، یک خط لوله ورودی میزبان وجود دارد که کد tf.data برنامه را اجرا می کند و خطوط لوله ورودی دستگاه متعددی وجود دارد که داده ها را از خط لوله ورودی میزبان بازیابی و به دستگاه ها منتقل می کند.
برای هر خط لوله ورودی، آمار زمان اجرای خود را نشان می دهد. اگر بیش از 50 میکروثانیه طول بکشد، یک تماس کند حساب می شود.
نمودار خط لوله ورودی

این بخش نمودار خط لوله ورودی را با اطلاعات زمان اجرا نشان می دهد. میتوانید از «Host» و «Input Pipeline» برای انتخاب میزبان و خط لوله ورودی استفاده کنید. اجرای خط لوله ورودی بر اساس زمان اجرا به ترتیب نزولی طبقه بندی می شود که می توانید با استفاده از منوی کرکره ای Rank انتخاب کنید.
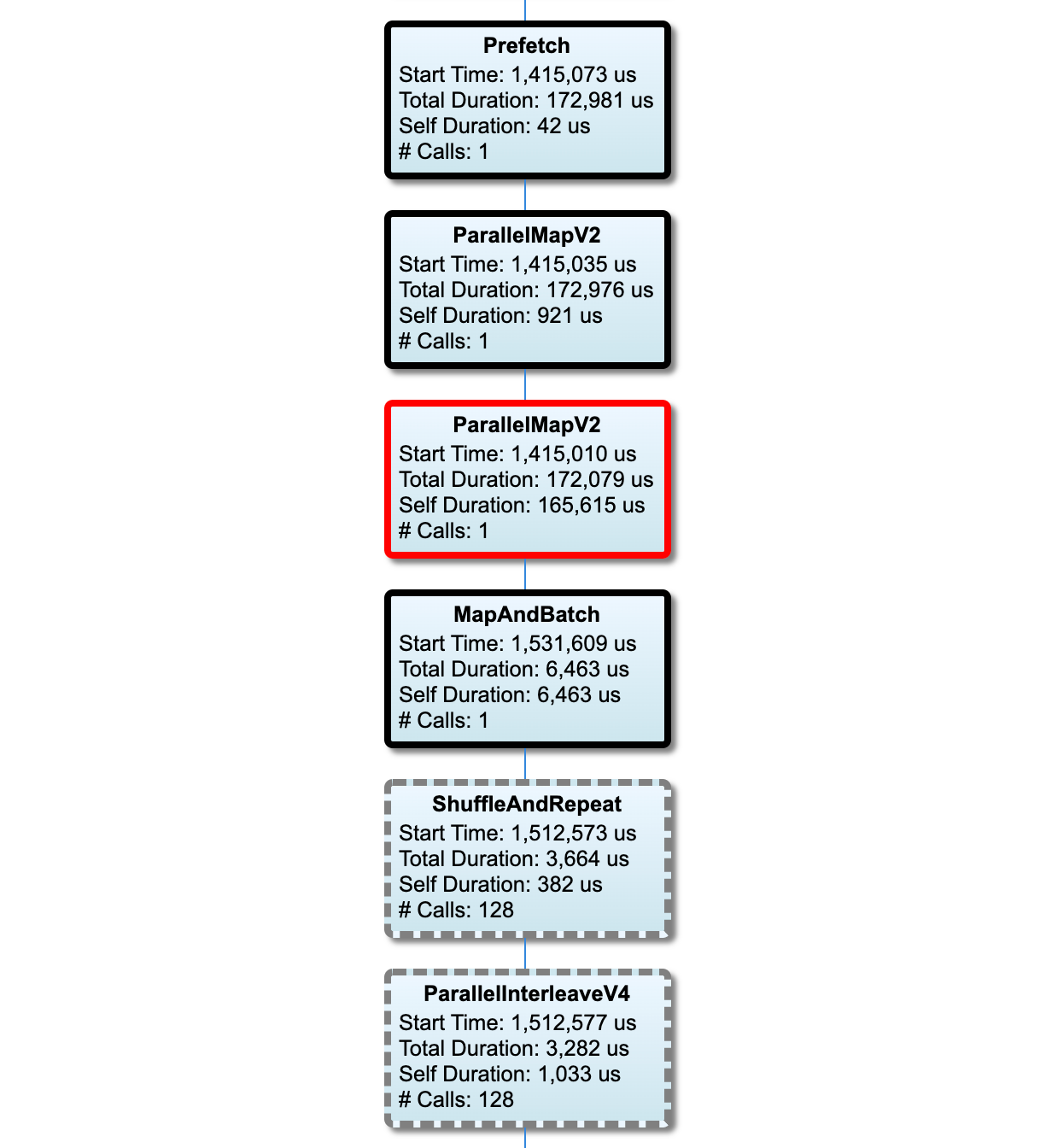
گره های موجود در مسیر بحرانی دارای خطوط برجسته هستند. گره گلوگاه، که گرهی با طولانی ترین زمان خود در مسیر بحرانی است، دارای یک طرح کلی قرمز است. سایر گره های غیر بحرانی دارای خطوط خاکستری خط چین هستند.
در هر گره، Start Time زمان شروع اجرا را نشان می دهد. یک گره ممکن است چندین بار اجرا شود، برای مثال، اگر یک عملیات Batch در خط لوله ورودی وجود داشته باشد. اگر چندین بار اجرا شود، زمان شروع اولین اجرا است.
مجموع مدت زمان دیوار اجرا است. اگر چندین بار اجرا شود، مجموع دفعات دیوار تمام اجراها است.
زمان خود، زمان کل بدون زمان همپوشانی با گره های فرزند فوری آن است.
"# تماس" تعداد دفعاتی است که خط لوله ورودی اجرا می شود.
داده های عملکرد را جمع آوری کنید
TensorFlow Profiler فعالیت های میزبان و ردپای GPU مدل TensorFlow شما را جمع آوری می کند. میتوانید Profiler را برای جمعآوری دادههای عملکرد از طریق حالت برنامهنویسی یا حالت نمونهبرداری پیکربندی کنید.
پروفایل API ها
برای انجام پروفایل می توانید از API های زیر استفاده کنید.
حالت برنامه نویسی با استفاده از TensorBoard Keras Callback (
tf.keras.callbacks.TensorBoard)# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])حالت برنامه نویسی با استفاده از
tf.profilerFunction APItf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()حالت برنامه نویسی با استفاده از مدیر زمینه
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
حالت نمونه برداری: با استفاده از
tf.profiler.experimental.server.startبرای راه اندازی یک سرور gRPC با اجرای مدل TensorFlow، پروفایل بر اساس تقاضا را انجام دهید. پس از راه اندازی سرور gRPC و اجرای مدل خود، می توانید از طریق دکمه Capture Profile در افزونه پروفایل TensorBoard یک نمایه بگیرید. از اسکریپت در بخش Install profiler در بالا برای راهاندازی یک نمونه TensorBoard در صورتی که قبلاً اجرا نشده است استفاده کنید.به عنوان نمونه،
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)مثالی برای پروفایل چندین کارگر:
# E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)
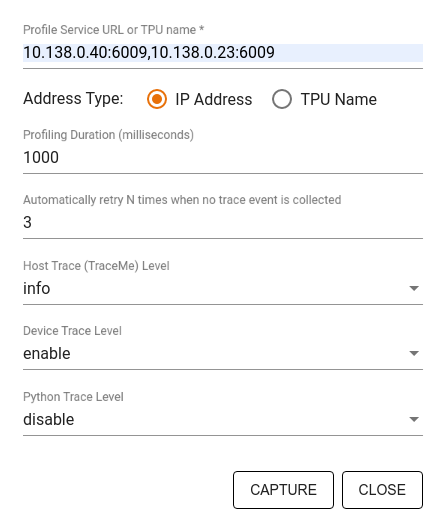
از کادر گفتگوی Capture Profile برای تعیین موارد زیر استفاده کنید:
- فهرستی از نشانیهای اینترنتی خدمات نمایه یا نامهای TPU که با کاما محدود شدهاند.
- مدت زمان پروفایل
- سطح ردیابی فراخوانی دستگاه، میزبان و تابع پایتون.
- چند بار میخواهید که در صورت عدم موفقیت، نمایهگر دوباره سعی کند نمایهها را بگیرد.
پروفایل کردن حلقه های آموزشی سفارشی
برای نمایه کردن حلقههای آموزشی سفارشی در کد TensorFlow، حلقه آموزشی را با tf.profiler.experimental.Trace API تنظیم کنید تا مرزهای مرحله را برای Profiler مشخص کنید.
آرگومان name به عنوان پیشوند برای نام گام ها استفاده می شود، آرگومان کلمه کلیدی step_num به نام گام ها اضافه می شود، و آرگومان کلمه کلیدی _r باعث می شود این رویداد ردیابی به عنوان یک رویداد مرحله ای توسط Profiler پردازش شود.
به عنوان نمونه،
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
این کار تجزیه و تحلیل عملکرد مبتنی بر مرحله Profiler را فعال می کند و باعث می شود که رویدادهای مرحله در نمایشگر ردیابی نشان داده شوند.
اطمینان حاصل کنید که تکرارکننده مجموعه داده را در زمینه tf.profiler.experimental.Trace برای تجزیه و تحلیل دقیق خط لوله ورودی قرار داده اید.
قطعه کد زیر یک ضد الگو است:
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
موارد استفاده پروفایل
پروفایلر تعدادی از موارد استفاده را در چهار محور مختلف پوشش می دهد. برخی از ترکیب ها در حال حاضر پشتیبانی می شوند و برخی دیگر در آینده اضافه خواهند شد. برخی از موارد استفاده عبارتند از:
- نمایه سازی محلی در مقابل از راه دور : این دو روش متداول برای تنظیم محیط پروفایل شما هستند. در نمایه سازی محلی، API پروفایل در همان ماشینی که مدل شما در حال اجرای آن است فراخوانی می شود، به عنوان مثال، یک ایستگاه کاری محلی با GPU. در نمایه سازی از راه دور، API پروفایل در ماشینی متفاوت از جایی که مدل شما در حال اجرا است فراخوانی می شود، به عنوان مثال، در یک Cloud TPU.
- پروفایل چندین کارگر : هنگام استفاده از قابلیت های آموزشی توزیع شده TensorFlow می توانید چندین ماشین را نمایه کنید.
- پلتفرم سخت افزاری : مشخصات CPU، GPU و TPU.
جدول زیر یک نمای کلی از موارد استفاده با پشتیبانی از TensorFlow ذکر شده در بالا ارائه می دهد:
| پروفایل API | محلی | از راه دور | چند کارگر | پلتفرم های سخت افزاری |
|---|---|---|---|---|
| TensorBoard Keras Callback | پشتیبانی می شود | پشتیبانی نمی شود | پشتیبانی نمی شود | CPU، GPU |
tf.profiler.experimental start/stop API | پشتیبانی می شود | پشتیبانی نمی شود | پشتیبانی نمی شود | CPU، GPU |
tf.profiler.experimental client.trace API | پشتیبانی می شود | پشتیبانی می شود | پشتیبانی می شود | CPU، GPU، TPU |
| API مدیر زمینه | پشتیبانی می شود | پشتیبانی نمی شود | پشتیبانی نمی شود | CPU، GPU |
بهترین روش ها برای عملکرد بهینه مدل
برای دستیابی به عملکرد مطلوب، از توصیه های زیر برای مدل های TensorFlow خود استفاده کنید.
به طور کلی، تمام تغییرات را روی دستگاه انجام دهید و اطمینان حاصل کنید که از آخرین نسخه سازگار کتابخانههایی مانند cuDNN و Intel MKL برای پلتفرم خود استفاده میکنید.
بهینه سازی خط لوله داده های ورودی
از داده های [#input_pipeline_analyzer] برای بهینه سازی خط لوله ورودی داده خود استفاده کنید. یک خط لوله ورودی داده کارآمد می تواند سرعت اجرای مدل شما را با کاهش زمان بیکاری دستگاه به شدت بهبود بخشد. سعی کنید بهترین روشها را که در بخش عملکرد بهتر با راهنمای tf.data API و زیر توضیح داده شده است، بگنجانید تا خط لوله ورودی دادههای خود را کارآمدتر کنید.
به طور کلی، موازی کردن هر عملیاتی که نیازی به اجرای متوالی ندارد، می تواند خط لوله ورودی داده را به طور قابل توجهی بهینه کند.
در بسیاری از موارد، به تغییر ترتیب برخی تماس ها یا تنظیم آرگومان ها به گونه ای کمک می کند که برای مدل شما بهترین کار را داشته باشد. در حین بهینهسازی خط لوله دادههای ورودی، تنها بارگذار داده را بدون مراحل آموزش و انتشار پسانداز، معیار قرار دهید تا تأثیر بهینهسازیها به طور مستقل کمیت شود.
سعی کنید مدل خود را با داده های مصنوعی اجرا کنید تا بررسی کنید که آیا خط لوله ورودی یک گلوگاه عملکرد است یا خیر.
برای آموزش چند GPU از
tf.data.Dataset.shardاستفاده کنید. اطمینان حاصل کنید که خیلی زود در حلقه ورودی خرد می کنید تا از کاهش توان جلوگیری شود. هنگام کار با TFRecords، مطمئن شوید که لیست TFRecords را به اشتراک می گذارید و نه محتوای TFRecords.با تنظیم پویا مقدار
num_parallel_callsبا استفاده ازtf.data.AUTOTUNEچندین عملیات را موازی کنید.محدود کردن استفاده از
tf.data.Dataset.from_generatorرا در نظر بگیرید زیرا در مقایسه با عملیات خالص TensorFlow کندتر است.محدود کردن استفاده از
tf.py_functionرا در نظر بگیرید زیرا نمی توان آن را سریال کرد و برای اجرا در TensorFlow توزیع شده پشتیبانی نمی شود.از
tf.data.Optionsبرای کنترل بهینهسازی استاتیک در خط لوله ورودی استفاده کنید.
همچنین راهنمای تحلیل عملکرد tf.data را برای راهنمایی بیشتر در مورد بهینه سازی خط لوله ورودی خود بخوانید.
بهینه سازی افزایش داده ها
هنگام کار با دادههای تصویر، با ارسال به انواع دادههای مختلف پس از اعمال تبدیلهای فضایی، مانند چرخش، برش، چرخش و غیره ، افزایش دادههای خود را کارآمدتر کنید.
از NVIDIA® DALI استفاده کنید
در برخی موارد، مانند زمانی که سیستمی با نسبت GPU به CPU بالا دارید، همه بهینهسازیهای بالا ممکن است برای از بین بردن تنگناهای بارگذار دادهای که به دلیل محدودیتهای چرخههای CPU ایجاد میشود، کافی نباشند.
اگر از پردازندههای گرافیکی NVIDIA® برای برنامههای یادگیری عمیق بینایی رایانه و صوتی استفاده میکنید، از کتابخانه بارگیری داده ( DALI ) برای تسریع در خط لوله داده استفاده کنید.
اسناد NVIDIA® DALI: Operations را برای لیستی از عملیات DALI پشتیبانی شده بررسی کنید.
از threading و اجرای موازی استفاده کنید
با tf.config.threading API عملیات را روی چندین رشته CPU اجرا کنید تا آنها را سریعتر اجرا کنید.
TensorFlow به طور خودکار تعداد رشته های موازی را به طور پیش فرض تنظیم می کند. Thread Pool موجود برای اجرای عملیات TensorFlow به تعداد رشتههای CPU موجود بستگی دارد.
با استفاده از tf.config.threading.set_intra_op_parallelism_threads ، حداکثر سرعت موازی را برای یک عملیات واحد کنترل کنید. توجه داشته باشید که اگر چندین عملیات را به صورت موازی اجرا کنید، همه آنها از thread pool موجود به اشتراک خواهند گذاشت.
اگر عملیات غیر مسدود کننده مستقل دارید (عملیات بدون مسیر مستقیم بین آنها در نمودار)، از tf.config.threading.set_inter_op_parallelism_threads استفاده کنید تا آنها را همزمان با استفاده از thread pool موجود اجرا کنید.
متفرقه
هنگام کار با مدلهای کوچکتر روی پردازندههای گرافیکی NVIDIA®، میتوانید tf.compat.v1.ConfigProto.force_gpu_compatible=True را تنظیم کنید تا همه تانسورهای CPU با حافظه پینشده CUDA تخصیص داده شوند تا عملکرد مدل را افزایش دهد. با این حال، هنگام استفاده از این گزینه برای مدلهای ناشناخته/بسیار بزرگ احتیاط کنید زیرا ممکن است بر عملکرد میزبان (CPU) تأثیر منفی بگذارد.
بهبود عملکرد دستگاه
برای بهینهسازی عملکرد مدل TensorFlow روی دستگاه، بهترین روشهای شرح داده شده در اینجا و راهنمای بهینهسازی عملکرد GPU را دنبال کنید.
اگر از پردازندههای گرافیکی NVIDIA استفاده میکنید، GPU و استفاده از حافظه را با اجرای:
nvidia-smi
--query-gpu=utilization.gpu,utilization.memory,memory.total,
memory.free,memory.used --format=csv
پیکربندی طرح بندی داده ها
هنگام کار با دادههایی که حاوی اطلاعات کانال هستند (مانند تصاویر)، قالب طرحبندی دادهها را بهینه کنید تا کانالهای آخر را ترجیح دهید (NHWC بر NCHW).
فرمتهای داده آخرین کانال، استفاده از Tensor Core را بهبود میبخشد و بهبود عملکرد قابل توجهی را به خصوص در مدلهای کانولوشنال در صورت همراه شدن با AMP ارائه میکند. طرحبندی دادههای NCHW هنوز میتواند توسط Tensor Cores اجرا شود، اما به دلیل عملیات انتقال خودکار، سربار اضافی را معرفی میکند.
با تنظیم data_format="channels_last" برای لایههایی مانند tf.keras.layers.Conv2D ، tf.keras.layers.Conv3D ، و tf.keras.layers.RandomRotation ، میتوانید طرحبندی دادهها را برای ترجیح طرحبندیهای NHWC بهینه کنید.
از tf.keras.backend.set_image_data_format برای تنظیم قالب پیشفرض طرحبندی داده برای API باطن Keras استفاده کنید.
حافظه نهان L2 را حداکثر کنید
هنگام کار با پردازندههای گرافیکی NVIDIA®، قطعه کد زیر را قبل از حلقه آموزشی اجرا کنید تا دانهبندی واکشی L2 را به 128 بایت برسانید.
import ctypes
_libcudart = ctypes.CDLL('libcudart.so')
# Set device limit on the current device
# cudaLimitMaxL2FetchGranularity = 0x05
pValue = ctypes.cast((ctypes.c_int*1)(), ctypes.POINTER(ctypes.c_int))
_libcudart.cudaDeviceSetLimit(ctypes.c_int(0x05), ctypes.c_int(128))
_libcudart.cudaDeviceGetLimit(pValue, ctypes.c_int(0x05))
assert pValue.contents.value == 128
پیکربندی استفاده از رشته GPU
حالت رشته GPU نحوه استفاده از رشته های GPU را تعیین می کند.
حالت رشته را روی gpu_private تنظیم کنید تا مطمئن شوید که پیش پردازش تمام رشتههای GPU را نمیدزدد. این باعث کاهش تاخیر راه اندازی هسته در طول آموزش می شود. همچنین می توانید تعداد موضوعات در هر GPU را تنظیم کنید. این مقادیر را با استفاده از متغیرهای محیط تنظیم کنید.
import os
os.environ['TF_GPU_THREAD_MODE']='gpu_private'
os.environ['TF_GPU_THREAD_COUNT']='1'
گزینه های حافظه GPU را پیکربندی کنید
به طور کلی ، اندازه دسته ای را افزایش داده و مدل را برای استفاده بهتر از GPU ها و دستیابی به توان بالاتر افزایش دهید. توجه داشته باشید که افزایش اندازه دسته ، دقت مدل را تغییر می دهد ، بنابراین مدل با تنظیم فشار بیش از حد مانند نرخ یادگیری برای برآورده کردن دقت هدف باید مقیاس شود.
همچنین از tf.config.experimental.set_memory_growth استفاده کنید تا حافظه GPU رشد کند تا تمام حافظه موجود به طور کامل به OPS اختصاص یابد که فقط به بخشی از حافظه نیاز دارند. این اجازه می دهد تا فرآیندهای دیگری که حافظه GPU را مصرف می کنند در همان دستگاه اجرا شوند.
برای کسب اطلاعات بیشتر ، برای کسب اطلاعات بیشتر ، راهنمای رشد حافظه GPU را در راهنمای GPU محدود کنید.
متفرقه
اندازه مینی دسته آموزش (تعداد نمونه های آموزش مورد استفاده در هر دستگاه در یک تکرار حلقه آموزش) را به حداکثر مقدار متناسب با خطای خارج از حافظه (OOM) در GPU افزایش دهید. افزایش اندازه دسته ای بر دقت مدل تأثیر می گذارد - بنابراین با تنظیم HyperParameters برای دستیابی به دقت هدف ، اطمینان حاصل کنید که مدل را مقیاس می کنید.
گزارش خطاهای OOM گزارش در هنگام تخصیص تانسور در کد تولید.
report_tensor_allocations_upon_oom=Falseintf.compat.v1.RunOptionsرا تنظیم کنید.برای مدلهای دارای لایه های حلقوی ، در صورت استفاده از عادی سازی دسته ای ، علاوه بر این تعصب را حذف کنید. عادی سازی مقادیر با میانگین خود را تغییر می دهد و این نیاز به داشتن یک اصطلاح تعصب ثابت را برطرف می کند.
از آمار TF استفاده کنید تا دریابید که OPS در دستگاه چگونه کارآمد است.
برای انجام محاسبات و به صورت اختیاری از
tf.functionاستفاده کنید ،jit_compile=Trueرا فعال کنید (tf.function(jit_compile=True). برای کسب اطلاعات بیشتر ، به استفاده از xla tf.function بروید.عملیات پایتون میزبان را بین مراحل به حداقل برسانید و پاسخ به تماس را کاهش دهید. به جای هر مرحله ، هر چند مرحله را محاسبه کنید.
واحدهای محاسبه دستگاه را مشغول نگه دارید.
داده ها را به صورت موازی به چندین دستگاه ارسال کنید.
با استفاده از بازنمایی های عددی 16 بیتی ، مانند
fp16قالب نقطه شناور نیمه دقیق مشخص شده توسط IEEE-یا فرمت BFLOAT16 با نقطه شناور مغز.
منابع اضافی
- The TensorFlow Profiler: آموزش عملکرد مدل پروفایل با Keras و Tensorboard که می توانید توصیه های موجود در این راهنما را اعمال کنید.
- پروفایل عملکرد در TensorFlow 2 از TensorFlow Dev Summit 2020 صحبت می کند.
- نسخه ی نمایشی Profiler TensorFlow از TensorFlow Dev Summit 2020.
محدودیت های شناخته شده
پروفایل چندین GPU در Tensorflow 2.2 و Tensorflow 2.3
Tensorflow 2.2 و 2.3 از پروفایل چندین GPU فقط برای سیستم های میزبان منفرد پشتیبانی می کنند. پروفایل چند گرافیکی برای سیستم های چند میزبان پشتیبانی نمی شود. برای مشخصات تنظیمات GPU چند کارگر ، هر کارگر باید به طور مستقل پروفایل شود. از TensorFlow 2.4 چندین کارگر را می توان با استفاده از tf.profiler.experimental.client.trace API پروفایل کرد.
CUDA® Toolkit 10.2 یا بالاتر برای پروفایل چندین GPU لازم است. از آنجا که TensorFlow 2.2 و 2.3 از نسخه های ابزار CUDA® فقط تا 10.1 پشتیبانی می کنند ، باید پیوندهای نمادین به libcudart.so.10.1 و libcupti.so.10.1 ایجاد کنید:
sudo ln -s /usr/local/cuda/lib64/libcudart.so.10.2 /usr/local/cuda/lib64/libcudart.so.10.1
sudo ln -s /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.2 /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.1