
আপনার টেনসরফ্লো মডেলের পারফরম্যান্স ট্র্যাক করতে টেনসরফ্লো প্রোফাইলারের সাথে উপলব্ধ সরঞ্জামগুলি কীভাবে ব্যবহার করবেন তা এই নির্দেশিকাটি দেখায়। হোস্ট (সিপিইউ), ডিভাইস (জিপিইউ) বা হোস্ট এবং ডিভাইস(গুলি) উভয়ের সংমিশ্রণে আপনার মডেল কীভাবে পারফর্ম করে তা আপনি বুঝতে শিখবেন।
প্রোফাইলিং আপনার মডেলের বিভিন্ন টেনসরফ্লো অপারেশনের (অপস) হার্ডওয়্যার রিসোর্স খরচ (সময় এবং মেমরি) বুঝতে সাহায্য করে এবং পারফরম্যান্সের বাধাগুলি সমাধান করে এবং অবশেষে, মডেলটিকে দ্রুত কার্যকর করতে সাহায্য করে।
এই গাইডটি আপনাকে কিভাবে প্রোফাইলার ইনস্টল করতে হয়, বিভিন্ন উপলভ্য টুলস, প্রোফাইলার কিভাবে পারফরম্যান্স ডেটা সংগ্রহ করে তার বিভিন্ন মোড এবং মডেল পারফরম্যান্স অপ্টিমাইজ করার জন্য কিছু প্রস্তাবিত সেরা অনুশীলনের মাধ্যমে আপনাকে নিয়ে যাবে।
আপনি যদি ক্লাউড টিপিইউতে আপনার মডেলের পারফরম্যান্স প্রোফাইল করতে চান তবে ক্লাউড টিপিইউ নির্দেশিকা পড়ুন।
প্রোফাইলার এবং জিপিইউ পূর্বশর্ত ইনস্টল করুন
পিপ দিয়ে টেনসরবোর্ডের জন্য প্রোফাইলার প্লাগইন ইনস্টল করুন। মনে রাখবেন যে প্রোফাইলারের জন্য TensorFlow এবং TensorBoard (>=2.2) এর সর্বশেষ সংস্করণ প্রয়োজন।
pip install -U tensorboard_plugin_profile
GPU তে প্রোফাইল করতে, আপনাকে অবশ্যই:
- TensorFlow GPU সমর্থন সফ্টওয়্যার প্রয়োজনীয়তার তালিকাভুক্ত NVIDIA® GPU ড্রাইভার এবং CUDA® টুলকিট প্রয়োজনীয়তা পূরণ করুন।
নিশ্চিত করুন যে NVIDIA® CUDA® প্রোফাইলিং টুলস ইন্টারফেস (CUPTI) পথে বিদ্যমান রয়েছে:
/sbin/ldconfig -N -v $(sed 's/:/ /g' <<< $LD_LIBRARY_PATH) | \ grep libcupti
আপনার যদি পাথে CUPTI না থাকে, তাহলে চালানোর মাধ্যমে এর ইনস্টলেশন ডিরেক্টরিকে $LD_LIBRARY_PATH এনভায়রনমেন্ট ভেরিয়েবলের সাথে প্রিপেন্ড করুন:
export LD_LIBRARY_PATH=/usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
তারপরে, CUPTI লাইব্রেরি পাওয়া গেছে কিনা তা যাচাই করতে উপরের ldconfig কমান্ডটি আবার চালান।
বিশেষাধিকার সমস্যা সমাধান
আপনি যখন ডকার পরিবেশে বা লিনাক্সে CUDA® টুলকিটের সাথে প্রোফাইলিং চালান, তখন আপনি অপর্যাপ্ত CUPTI বিশেষাধিকার ( CUPTI_ERROR_INSUFFICIENT_PRIVILEGES ) সম্পর্কিত সমস্যার সম্মুখীন হতে পারেন। আপনি কীভাবে Linux-এ এই সমস্যাগুলি সমাধান করতে পারেন সে সম্পর্কে আরও জানতে NVIDIA বিকাশকারী ডক্সে যান।
একটি ডকার পরিবেশে CUPTI বিশেষাধিকার সমস্যা সমাধান করতে, চালান
docker run option '--privileged=true'
প্রোফাইলার টুল
TensorBoard-এর প্রোফাইল ট্যাব থেকে প্রোফাইলার অ্যাক্সেস করুন, যা আপনি কিছু মডেল ডেটা ক্যাপচার করার পরেই প্রদর্শিত হবে৷
পারফরম্যান্স বিশ্লেষণে সহায়তা করার জন্য প্রোফাইলারের একটি নির্বাচনী সরঞ্জাম রয়েছে:
- ওভারভিউ পৃষ্ঠা
- ইনপুট পাইপলাইন বিশ্লেষক
- টেনসরফ্লো পরিসংখ্যান
- ট্রেস ভিউয়ার
- GPU কার্নেল পরিসংখ্যান
- মেমরি প্রোফাইল টুল
- পড ভিউয়ার
ওভারভিউ পৃষ্ঠা
ওভারভিউ পৃষ্ঠাটি প্রোফাইল চালানোর সময় আপনার মডেল কীভাবে পারফর্ম করেছে তার একটি শীর্ষ স্তরের ভিউ প্রদান করে। পৃষ্ঠাটি আপনাকে আপনার হোস্ট এবং সমস্ত ডিভাইসের জন্য একটি সমষ্টিগত ওভারভিউ পৃষ্ঠা এবং আপনার মডেল প্রশিক্ষণ কর্মক্ষমতা উন্নত করার জন্য কিছু সুপারিশ দেখায়। এছাড়াও আপনি হোস্ট ড্রপডাউন থেকে পৃথক হোস্ট নির্বাচন করতে পারেন।
ওভারভিউ পৃষ্ঠাটি নিম্নরূপ ডেটা প্রদর্শন করে:
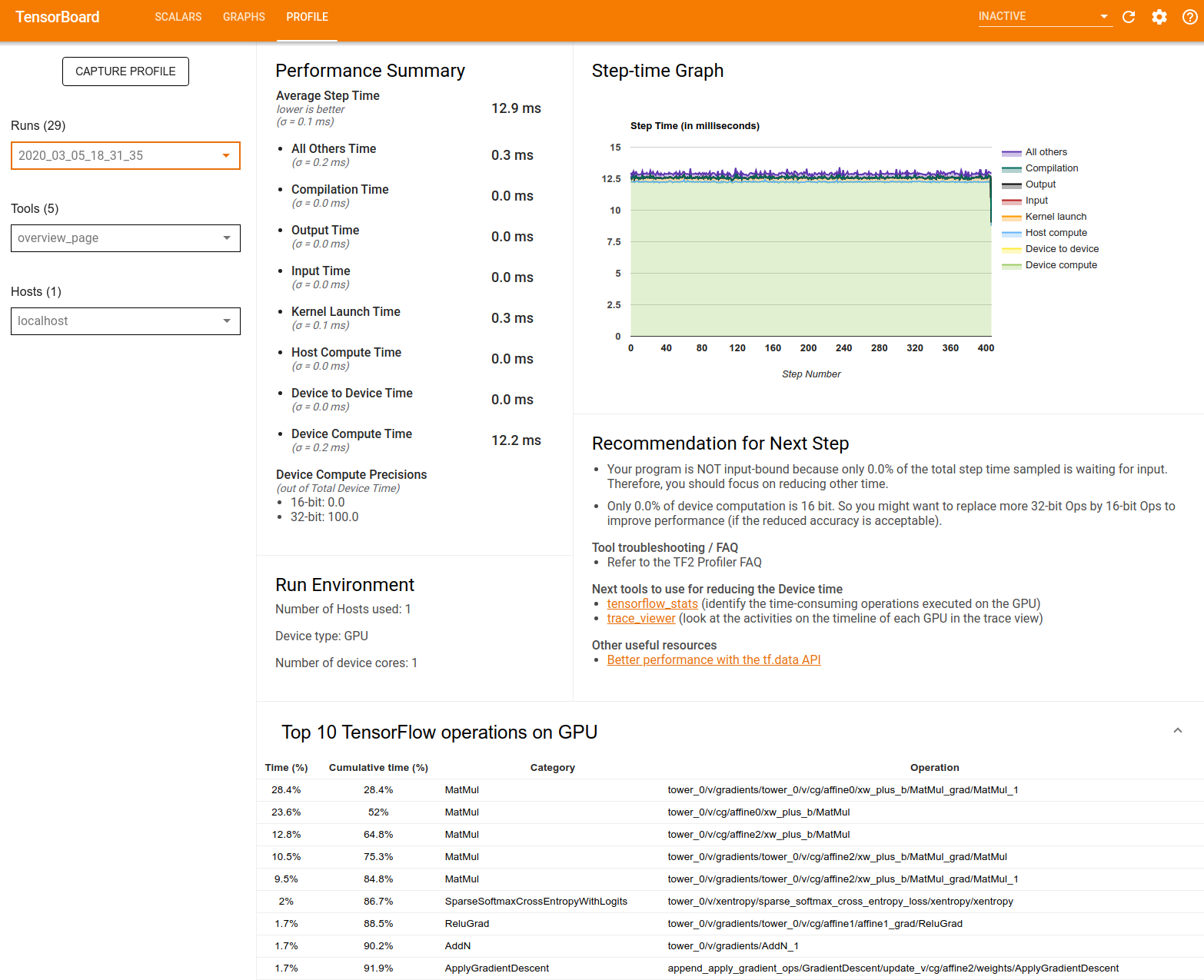
কর্মক্ষমতা সারাংশ : আপনার মডেল কর্মক্ষমতা একটি উচ্চ-স্তরের সারাংশ প্রদর্শন করে। কর্মক্ষমতা সারাংশ দুটি অংশ আছে:
স্টেপ-টাইম ব্রেকডাউন: যেখানে সময় অতিবাহিত হয় তার একাধিক বিভাগে গড় ধাপ সময়কে বিভক্ত করে:
- সংকলন: কার্নেল কম্পাইল করার সময় ব্যয় করা হয়েছে।
- ইনপুট: ইনপুট ডেটা পড়ার সময় ব্যয় করা হয়েছে।
- আউটপুট: আউটপুট ডেটা পড়ার সময় ব্যয় করা হয়।
- কার্নেল লঞ্চ: হোস্ট কার্নেল চালু করতে সময় ব্যয় করে
- আয়োজক গণনা সময়..
- ডিভাইস থেকে ডিভাইস যোগাযোগ সময়।
- অন-ডিভাইস গণনা সময়।
- পাইথন ওভারহেড সহ অন্য সকল।
ডিভাইস কম্পিউট নির্ভুলতা - 16 এবং 32-বিট কম্পিউটেশন ব্যবহার করে ডিভাইস কম্পিউট সময়ের শতাংশের রিপোর্ট করে।
স্টেপ-টাইম গ্রাফ : নমুনা করা সমস্ত ধাপে ডিভাইসের ধাপ সময়ের (মিলিসেকেন্ডে) একটি গ্রাফ প্রদর্শন করে। প্রতিটি ধাপকে একাধিক বিভাগে (বিভিন্ন রঙ সহ) বিভক্ত করা হয়েছে যেখানে সময় ব্যয় করা হয়। হোস্ট থেকে ইনপুট ডেটার জন্য ডিভাইসগুলি নিষ্ক্রিয় বসে থাকা ধাপের অংশের সাথে লাল এলাকাটি মিলে যায়। সবুজ এলাকা দেখায় যে ডিভাইসটি আসলে কতটা সময় কাজ করছিল।
ডিভাইসে শীর্ষ 10 TensorFlow অপারেশন (যেমন GPU) : অন-ডিভাইস অপ্স প্রদর্শন করে যা সবচেয়ে বেশি সময় ধরে চলে।
প্রতিটি সারি একটি অপের স্ব-সময় (সমস্ত অপের দ্বারা নেওয়া সময়ের শতাংশ হিসাবে), ক্রমবর্ধমান সময়, বিভাগ এবং নাম প্রদর্শন করে।
রান এনভায়রনমেন্ট : মডেল রান এনভায়রনমেন্টের একটি উচ্চ-স্তরের সারসংক্ষেপ প্রদর্শন করে যার মধ্যে রয়েছে:
- ব্যবহৃত হোস্ট সংখ্যা.
- ডিভাইসের ধরন (GPU/TPU)।
- ডিভাইসের কোরের সংখ্যা।
পরবর্তী ধাপের জন্য সুপারিশ : যখন একটি মডেল ইনপুট আবদ্ধ থাকে এবং মডেলের কার্যক্ষমতার বাধাগুলি সনাক্ত করতে এবং সমাধান করতে আপনি ব্যবহার করতে পারেন এমন সরঞ্জামগুলির সুপারিশ করে।
ইনপুট পাইপলাইন বিশ্লেষক
যখন একটি টেনসরফ্লো প্রোগ্রাম একটি ফাইল থেকে ডেটা পড়ে তখন এটি পাইপলাইন পদ্ধতিতে টেনসরফ্লো গ্রাফের শীর্ষে শুরু হয়। পঠন প্রক্রিয়াটি সিরিজে সংযুক্ত একাধিক ডেটা প্রক্রিয়াকরণ পর্যায়ে বিভক্ত, যেখানে একটি পর্যায়ের আউটপুট পরেরটির ইনপুট। ডেটা পড়ার এই সিস্টেমটিকে ইনপুট পাইপলাইন বলা হয়।
ফাইল থেকে রেকর্ড পড়ার জন্য একটি সাধারণ পাইপলাইনের নিম্নলিখিত ধাপ রয়েছে:
- ফাইল পড়া।
- ফাইল প্রিপ্রসেসিং (ঐচ্ছিক)।
- হোস্ট থেকে ডিভাইসে ফাইল স্থানান্তর।
একটি অদক্ষ ইনপুট পাইপলাইন গুরুতরভাবে আপনার আবেদন মন্থর করতে পারে. একটি অ্যাপ্লিকেশন ইনপুট আবদ্ধ বলে বিবেচিত হয় যখন এটি ইনপুট পাইপলাইনে সময়ের একটি উল্লেখযোগ্য অংশ ব্যয় করে। ইনপুট পাইপলাইন কোথায় অদক্ষ তা বোঝার জন্য ইনপুট পাইপলাইন বিশ্লেষক থেকে প্রাপ্ত অন্তর্দৃষ্টি ব্যবহার করুন।
ইনপুট পাইপলাইন বিশ্লেষক আপনাকে অবিলম্বে বলে যে আপনার প্রোগ্রাম ইনপুট আবদ্ধ কিনা এবং ইনপুট পাইপলাইনের যেকোনো পর্যায়ে পারফরম্যান্সের বাধাগুলি ডিবাগ করতে ডিভাইস- এবং হোস্ট-সাইড বিশ্লেষণের মাধ্যমে আপনাকে নিয়ে যায়।
আপনার ডেটা ইনপুট পাইপলাইন অপ্টিমাইজ করার জন্য প্রস্তাবিত সর্বোত্তম অনুশীলনের জন্য ইনপুট পাইপলাইন পারফরম্যান্সের নির্দেশিকা দেখুন।
ইনপুট পাইপলাইন ড্যাশবোর্ড
ইনপুট পাইপলাইন বিশ্লেষক খুলতে, প্রোফাইল নির্বাচন করুন, তারপর টুল ড্রপডাউন থেকে input_pipeline_analyzer নির্বাচন করুন।
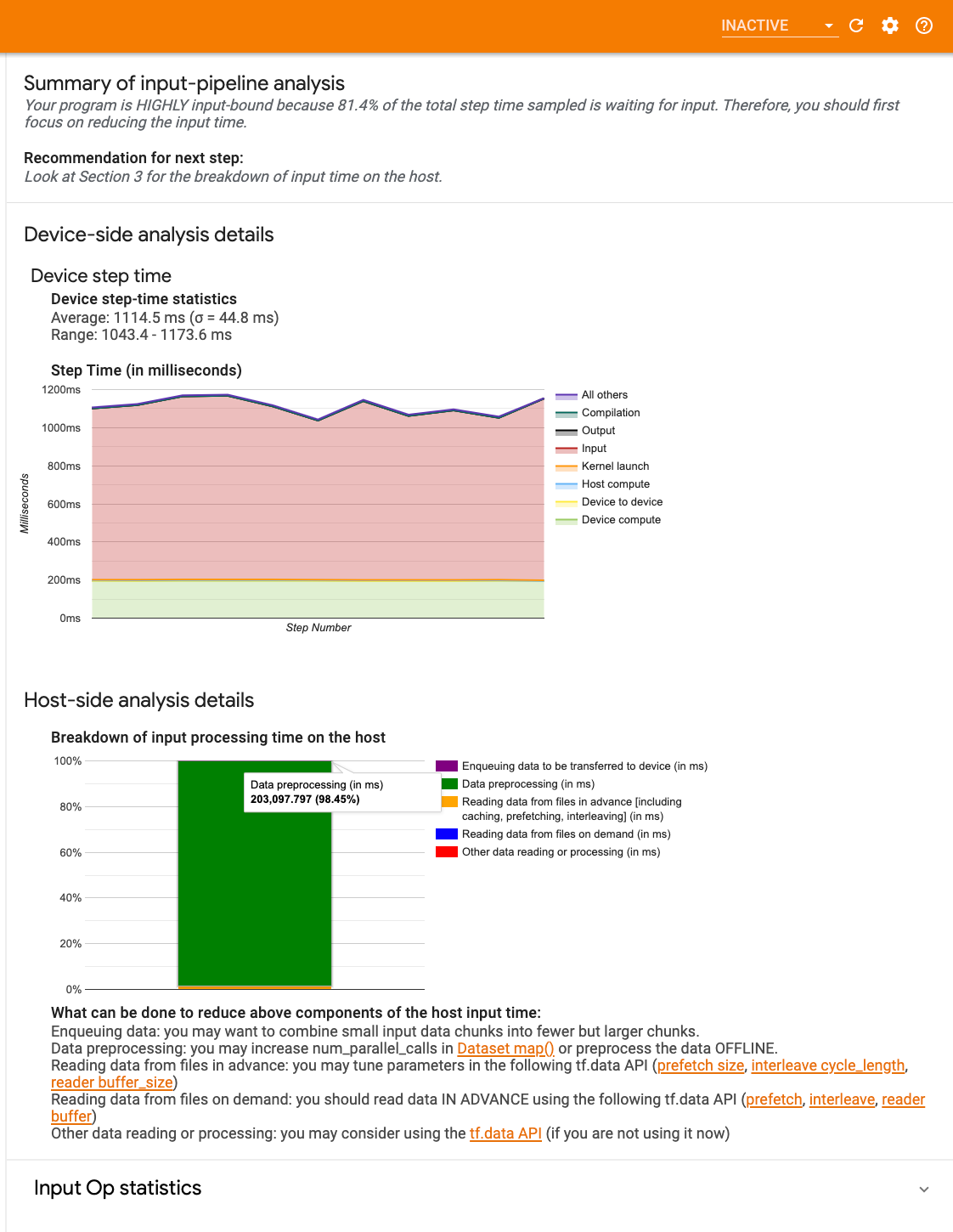
ড্যাশবোর্ডে তিনটি বিভাগ রয়েছে:
- সারাংশ : আপনার অ্যাপ্লিকেশন ইনপুট আবদ্ধ কিনা এবং যদি তাই হয়, কতটুকু তার তথ্য সহ সামগ্রিক ইনপুট পাইপলাইনকে সংক্ষিপ্ত করে।
- ডিভাইস-পার্শ্ব বিশ্লেষণ : ডিভাইসের ধাপ-সময় এবং প্রতিটি ধাপে কোর জুড়ে ইনপুট ডেটার জন্য অপেক্ষা করা ডিভাইসের সময়ের পরিসীমা সহ বিস্তারিত, ডিভাইস-সাইড বিশ্লেষণের ফলাফল প্রদর্শন করে।
- হোস্ট-সাইড বিশ্লেষণ : হোস্টের ইনপুট প্রসেসিং সময়ের ভাঙ্গন সহ হোস্টের দিকে একটি বিশদ বিশ্লেষণ দেখায়।
ইনপুট পাইপলাইন সারাংশ
হোস্টের কাছ থেকে ইনপুটের জন্য অপেক্ষা করার সময় ব্যয় করা ডিভাইসের সময়ের শতাংশ উপস্থাপন করে আপনার প্রোগ্রামটি ইনপুট আবদ্ধ হলে সারাংশ রিপোর্ট করে। আপনি যদি একটি স্ট্যান্ডার্ড ইনপুট পাইপলাইন ব্যবহার করেন যা ইনস্ট্রুমেন্ট করা হয়েছে, টুলটি রিপোর্ট করে যেখানে ইনপুট প্রক্রিয়াকরণের বেশিরভাগ সময় ব্যয় করা হয়েছে।
ডিভাইস-সাইড বিশ্লেষণ
ডিভাইস-সাইড বিশ্লেষণটি হোস্টের বিরুদ্ধে ডিভাইসে ব্যয় করা সময়ের অন্তর্দৃষ্টি প্রদান করে এবং হোস্ট থেকে ইনপুট ডেটার জন্য কতটা ডিভাইস সময় ব্যয় করা হয়েছিল।
- ধাপ নম্বরের বিপরীতে প্লট করা ধাপের সময় : নমুনা করা সমস্ত ধাপে ডিভাইসের ধাপ সময়ের (মিলিসেকেন্ডে) একটি গ্রাফ প্রদর্শন করে। প্রতিটি ধাপকে একাধিক বিভাগে (বিভিন্ন রঙ সহ) বিভক্ত করা হয়েছে যেখানে সময় ব্যয় করা হয়। হোস্ট থেকে ইনপুট ডেটার জন্য ডিভাইসগুলি নিষ্ক্রিয় বসে থাকা ধাপের অংশের সাথে লাল এলাকাটি মিলে যায়। সবুজ এলাকাটি দেখায় যে ডিভাইসটি আসলে কতটা সময় কাজ করছিল।
- ধাপের সময় পরিসংখ্যান : ডিভাইসের ধাপ সময়ের গড়, মানক বিচ্যুতি এবং পরিসর ([সর্বনিম্ন, সর্বোচ্চ]) রিপোর্ট করে।
হোস্ট-সাইড বিশ্লেষণ
হোস্ট-সাইড বিশ্লেষণ হোস্টে ইনপুট প্রক্রিয়াকরণের সময় ( tf.data API অপ্স-এ ব্যয় করা সময়)কে কয়েকটি বিভাগে বিভক্ত করে:
- চাহিদা অনুযায়ী ফাইল থেকে ডেটা পড়া : ক্যাশিং, প্রিফেচিং এবং ইন্টারলিভিং ছাড়াই ফাইল থেকে ডেটা পড়ার সময় ব্যয় করা হয়।
- ফাইলগুলি থেকে আগে থেকেই ডেটা পড়া : ক্যাশিং, প্রিফেচিং এবং ইন্টারলিভিং সহ ফাইলগুলি পড়ার সময় ব্যয় করা হয়।
- ডেটা প্রিপ্রসেসিং : প্রি-প্রসেসিং অপ্স, যেমন ইমেজ ডিকম্প্রেশনে সময় ব্যয় করা হয়।
- ডিভাইসে স্থানান্তর করার জন্য ডেটা সারিবদ্ধ করা : ডিভাইসে ডেটা স্থানান্তর করার আগে ডেটা ইনফিড সারিতে রেখে সময় ব্যয় করা হয়।
পৃথক ইনপুট অপ্সের পরিসংখ্যান পরিদর্শন করতে ইনপুট অপ পরিসংখ্যান প্রসারিত করুন এবং তাদের বিভাগগুলি সম্পাদনের সময় দ্বারা বিভক্ত।
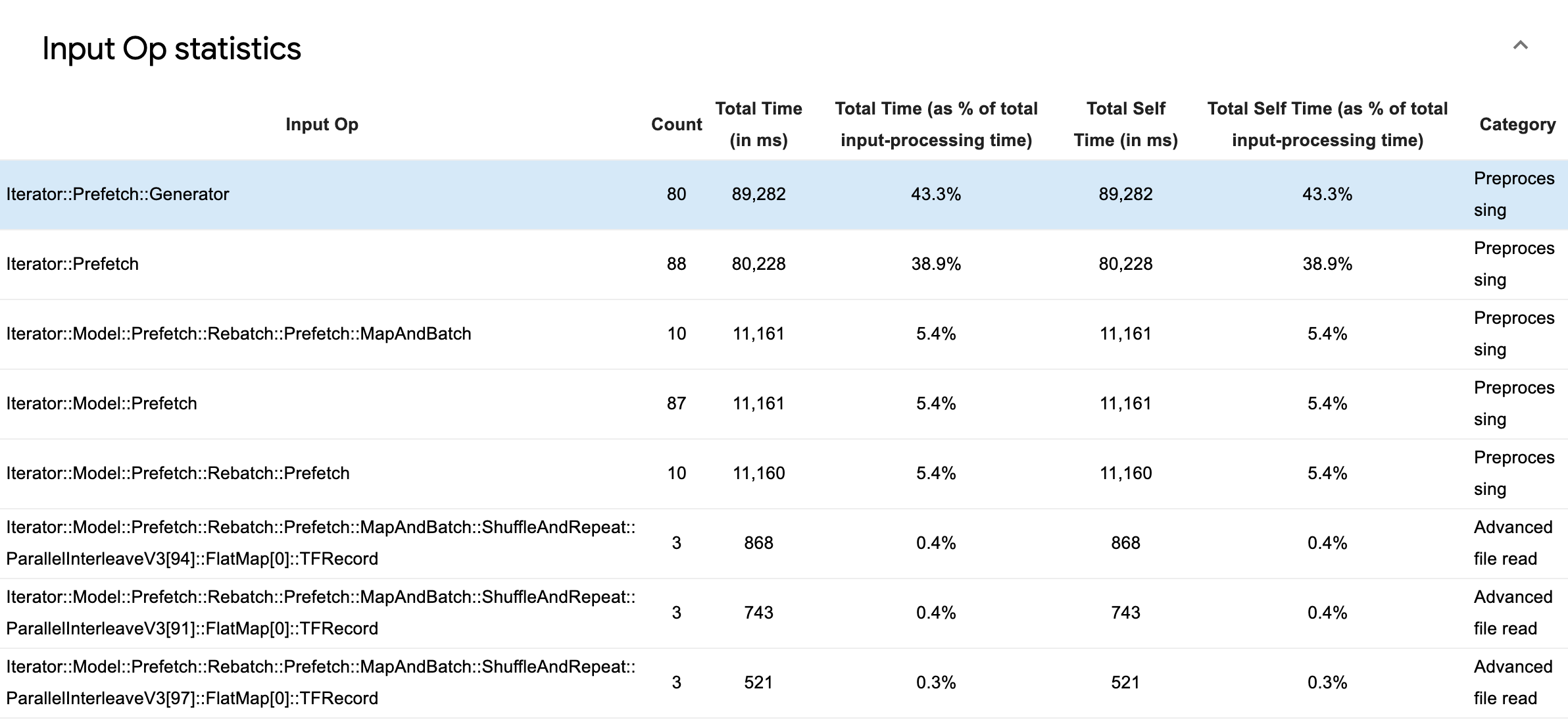
একটি উৎস তথ্য টেবিল নিম্নলিখিত তথ্য ধারণকারী প্রতিটি এন্ট্রি সঙ্গে প্রদর্শিত হবে:
- ইনপুট অপ : ইনপুট অপের TensorFlow op নাম দেখায়।
- গণনা : প্রোফাইলিং সময়কালে অপ সম্পাদনের মোট উদাহরণ দেখায়।
- মোট সময় (এমএসে) : সেই প্রতিটি দৃষ্টান্তে ব্যয় করা সময়ের ক্রমবর্ধমান যোগফল দেখায়।
- মোট সময় % : ইনপুট প্রক্রিয়াকরণে ব্যয় করা মোট সময়ের একটি ভগ্নাংশ হিসাবে একটি অপ-এ ব্যয় করা মোট সময় দেখায়।
- টোটাল সেল্ফ টাইম (মিসে) : সেই প্রতিটি দৃষ্টান্তে ব্যয় করা স্ব-সময়ের ক্রমবর্ধমান যোগফল দেখায়। এখানে সেলফ টাইম ফাংশন বডির অভ্যন্তরে কাটানো সময়কে পরিমাপ করে, এটি যে ফাংশনে ব্যয় করেছে তা বাদ দিয়ে।
- মোট স্ব-সময় % । ইনপুট প্রক্রিয়াকরণে ব্যয় করা মোট সময়ের একটি ভগ্নাংশ হিসাবে মোট স্ব-সময় দেখায়।
- বিভাগ ইনপুট অপের প্রক্রিয়াকরণ বিভাগ দেখায়।
টেনসরফ্লো পরিসংখ্যান
TensorFlow পরিসংখ্যান টুল প্রতিটি TensorFlow op (op) এর কর্মক্ষমতা প্রদর্শন করে যা একটি প্রোফাইলিং সেশনের সময় হোস্ট বা ডিভাইসে সম্পাদিত হয়।
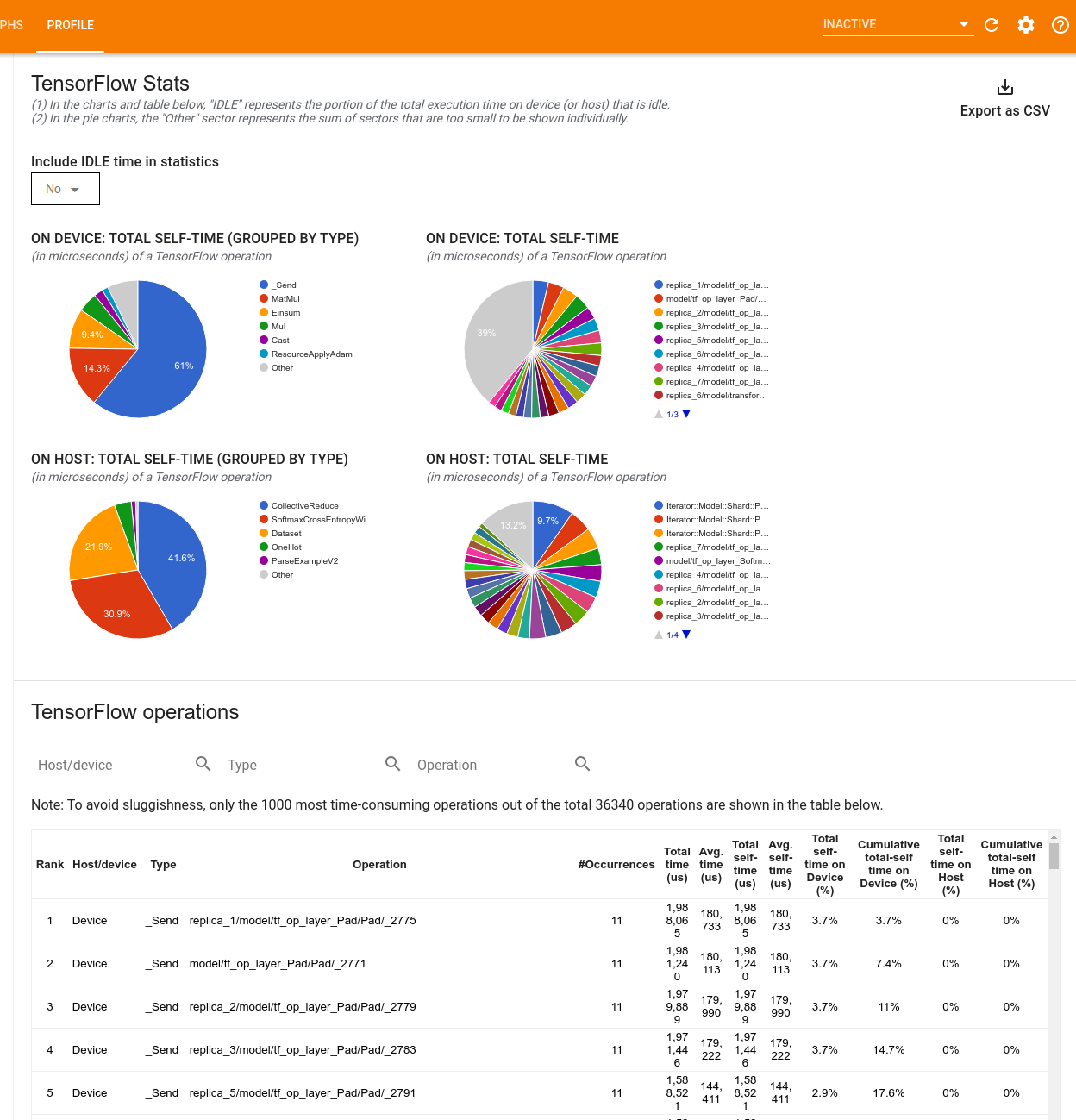
টুলটি দুটি প্যানে কর্মক্ষমতা তথ্য প্রদর্শন করে:
উপরের ফলকটি চারটি পাই চার্ট পর্যন্ত প্রদর্শন করে:
- হোস্টে প্রতিটি অপের স্ব-নির্বাহের সময় বিতরণ।
- হোস্টে প্রতিটি অপ টাইপের স্ব-নির্বাহের সময় বিতরণ।
- ডিভাইসে প্রতিটি অপের স্ব-নির্বাহের সময় বিতরণ।
- ডিভাইসে প্রতিটি অপ টাইপের স্ব-নির্বাহের সময় বিতরণ।
নীচের ফলকটি একটি টেবিল দেখায় যা প্রতিটি অপের জন্য একটি সারি এবং প্রতিটি ধরণের ডেটার জন্য একটি কলাম সহ টেনসরফ্লো অপস সম্পর্কে ডেটা রিপোর্ট করে (কলামের শিরোনাম ক্লিক করে কলামগুলি সাজান)৷ একটি CSV ফাইল হিসাবে এই টেবিল থেকে ডেটা রপ্তানি করতে উপরের ফলকের ডানদিকে CSV হিসাবে রপ্তানি করুন বোতামে ক্লিক করুন৷
উল্লেখ্য যে:
যদি কোনো অপারেশনে শিশু অপারেশন হয়:
- একটি অপারেটিং সিস্টেমের মোট "সঞ্চিত" সময়ের মধ্যে শিশু অপারেশনের ভিতরে কাটানো সময় অন্তর্ভুক্ত।
- একটি অপারেটিং সিস্টেমের মোট "স্ব" সময় শিশু অপের ভিতরে ব্যয় করা সময়কে অন্তর্ভুক্ত করে না।
যদি হোস্টে একটি অপশন চালানো হয়:
- অপ-অন-এর দ্বারা ব্যবহৃত ডিভাইসে মোট স্ব-সময়ের শতাংশ হবে 0।
- এই অপশন পর্যন্ত এবং সহ ডিভাইসে মোট স্ব-সময়ের ক্রমবর্ধমান শতাংশ 0 হবে।
যদি ডিভাইসে একটি অপশন চালানো হয়:
- এই অপশনের মাধ্যমে হোস্টে মোট স্ব-সময়ের শতাংশ হবে 0।
- এই অপশন পর্যন্ত এবং সহ হোস্টে থাকা মোট স্ব-সময়ের ক্রমবর্ধমান শতাংশ 0 হবে।
আপনি পাই চার্ট এবং টেবিলে নিষ্ক্রিয় সময় অন্তর্ভুক্ত বা বাদ দিতে বেছে নিতে পারেন।
ট্রেস ভিউয়ার
ট্রেস ভিউয়ার একটি টাইমলাইন প্রদর্শন করে যা দেখায়:
- আপনার TensorFlow মডেল দ্বারা সম্পাদিত অপারেশনগুলির সময়কাল
- সিস্টেমের কোন অংশ (হোস্ট বা ডিভাইস) একটি অপ সম্পাদন করেছে। সাধারণত, হোস্ট ইনপুট অপারেশন চালায়, প্রশিক্ষণ ডেটা প্রিপ্রসেস করে এবং ডিভাইসে স্থানান্তর করে, যখন ডিভাইসটি প্রকৃত মডেল প্রশিক্ষণ চালায়
ট্রেস ভিউয়ার আপনাকে আপনার মডেলের পারফরম্যান্স সমস্যা সনাক্ত করতে দেয়, তারপর সেগুলি সমাধানের জন্য পদক্ষেপ নিন। উদাহরণস্বরূপ, উচ্চ স্তরে, আপনি সনাক্ত করতে পারেন যে ইনপুট বা মডেল প্রশিক্ষণ বেশিরভাগ সময় নিচ্ছে কিনা। ড্রিলিং ডাউন, আপনি শনাক্ত করতে পারবেন কোন অপ্সটি চালাতে সবচেয়ে বেশি সময় লাগে। মনে রাখবেন যে ট্রেস ভিউয়ার প্রতি ডিভাইসে 1 মিলিয়ন ইভেন্টে সীমাবদ্ধ।
ট্রেস ভিউয়ার ইন্টারফেস
আপনি যখন ট্রেস ভিউয়ার খুলবেন, তখন এটি আপনার সাম্প্রতিক রান প্রদর্শন করছে:
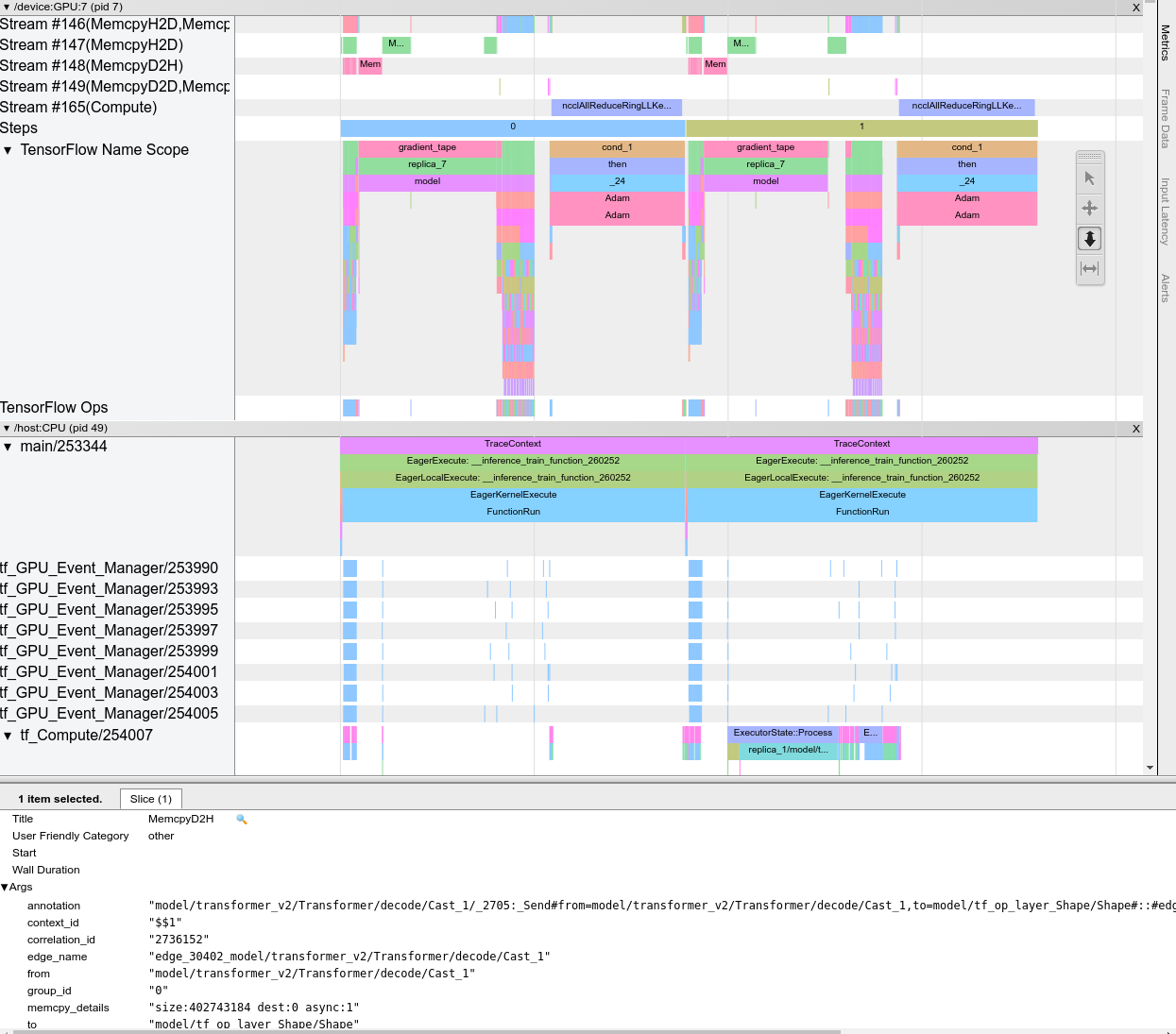
এই পর্দায় নিম্নলিখিত প্রধান উপাদান রয়েছে:
- টাইমলাইন ফলক : ডিভাইস এবং হোস্ট সময়ের সাথে সম্পাদিত অপারেশনগুলি দেখায়।
- বিস্তারিত ফলক : টাইমলাইন ফলকে নির্বাচিত অপারেশনগুলির জন্য অতিরিক্ত তথ্য দেখায়।
টাইমলাইন প্যানে নিম্নলিখিত উপাদান রয়েছে:
- শীর্ষ বার : বিভিন্ন অক্জিলিয়ারী নিয়ন্ত্রণ রয়েছে।
- সময় অক্ষ : ট্রেসের শুরুর সাপেক্ষে সময় দেখায়।
- বিভাগ এবং ট্র্যাক লেবেল : প্রতিটি বিভাগে একাধিক ট্র্যাক রয়েছে এবং বাম দিকে একটি ত্রিভুজ রয়েছে যা আপনি বিভাগটি প্রসারিত করতে এবং ভেঙে পড়তে ক্লিক করতে পারেন৷ সিস্টেমের প্রতিটি প্রক্রিয়াকরণ উপাদানের জন্য একটি বিভাগ আছে।
- টুল সিলেক্টর : ট্রেস ভিউয়ারের সাথে ইন্টারঅ্যাক্ট করার জন্য বিভিন্ন টুল রয়েছে যেমন জুম, প্যান, সিলেক্ট এবং টাইমিং। সময় ব্যবধান চিহ্নিত করতে টাইমিং টুল ব্যবহার করুন।
- ইভেন্টগুলি : এগুলি দেখায় যে সময়টিতে একটি অপারেশন চালানো হয়েছিল বা মেটা-ইভেন্টের সময়কাল, যেমন প্রশিক্ষণের পদক্ষেপগুলি।
বিভাগ এবং ট্র্যাক
ট্রেস ভিউয়ারে নিম্নলিখিত বিভাগগুলি রয়েছে:
- প্রতিটি ডিভাইস নোডের জন্য একটি বিভাগ , ডিভাইস চিপের সংখ্যা এবং চিপের মধ্যে থাকা ডিভাইস নোডের লেবেলযুক্ত (উদাহরণস্বরূপ,
/device:GPU:0 (pid 0))। প্রতিটি ডিভাইস নোড বিভাগে নিম্নলিখিত ট্র্যাক রয়েছে:- ধাপ : ডিভাইসে চলমান প্রশিক্ষণের ধাপের সময়কাল দেখায়
- TensorFlow Ops : ডিভাইসে সম্পাদিত অপ্স দেখায়
- XLA Ops : XLA ব্যবহার করা কম্পাইলার হলে ডিভাইসে চালানো XLA অপারেশন (অপস) দেখায় (প্রতিটি টেনসরফ্লো অপস এক বা একাধিক XLA অপ্সে অনুবাদ করা হয়। XLA কম্পাইলার XLA অপ্সকে ডিভাইসে চলা কোডে অনুবাদ করে)।
- হোস্ট মেশিনের CPU-তে চলমান থ্রেডগুলির জন্য একটি বিভাগ, "হোস্ট থ্রেডস" লেবেলযুক্ত। বিভাগে প্রতিটি CPU থ্রেডের জন্য একটি ট্র্যাক রয়েছে। মনে রাখবেন যে আপনি বিভাগ লেবেলগুলির পাশাপাশি প্রদর্শিত তথ্য উপেক্ষা করতে পারেন।
ঘটনা
টাইমলাইনের মধ্যে ইভেন্টগুলি বিভিন্ন রঙে প্রদর্শিত হয়; রং নিজেদের কোন নির্দিষ্ট অর্থ আছে.
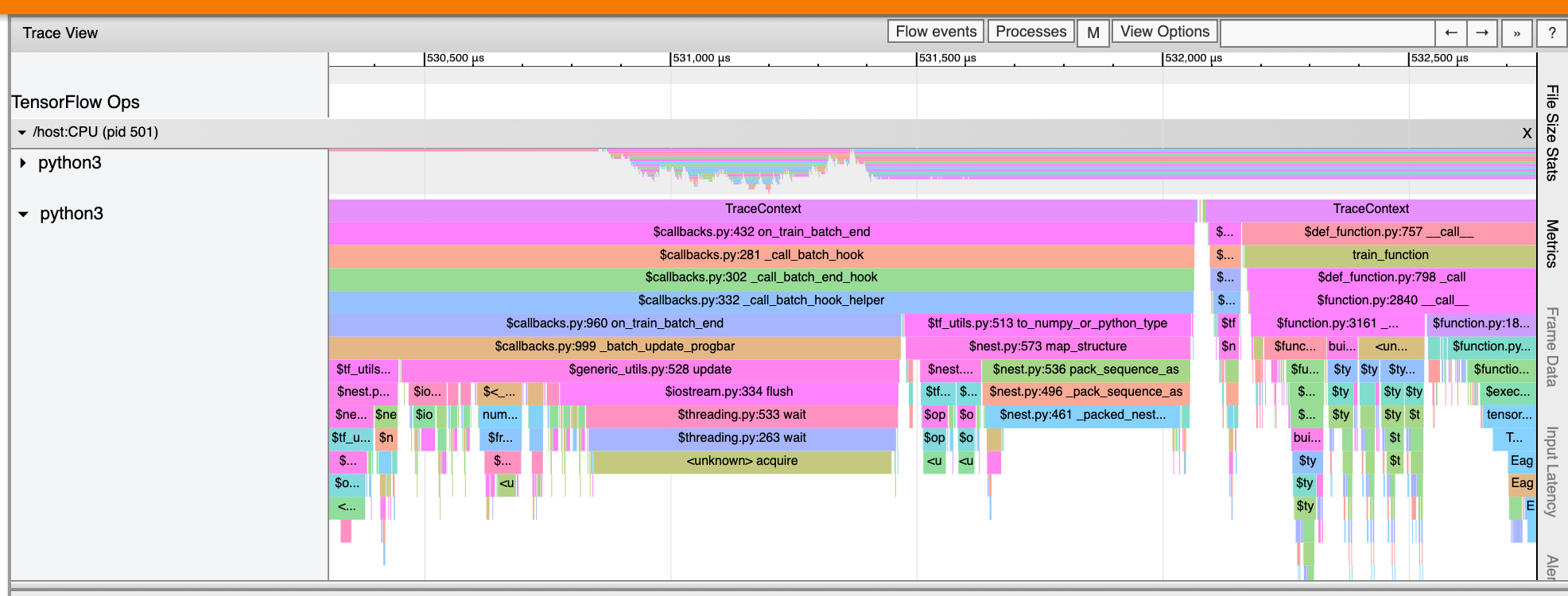
ট্রেস ভিউয়ার আপনার টেনসরফ্লো প্রোগ্রামে পাইথন ফাংশন কলের ট্রেসও প্রদর্শন করতে পারে। আপনি যদি tf.profiler.experimental.start API ব্যবহার করেন, আপনি প্রোফাইলিং শুরু করার সময় ProfilerOptions nametuple ব্যবহার করে Python ট্রেসিং সক্ষম করতে পারেন। বিকল্পভাবে, যদি আপনি প্রোফাইলিংয়ের জন্য স্যাম্পলিং মোড ব্যবহার করেন, আপনি ক্যাপচার প্রোফাইল ডায়ালগে ড্রপডাউন বিকল্পগুলি ব্যবহার করে ট্রেসিংয়ের স্তর নির্বাচন করতে পারেন।
GPU কার্নেলের পরিসংখ্যান
এই টুলটি প্রতিটি GPU ত্বরান্বিত কার্নেলের জন্য কর্মক্ষমতা পরিসংখ্যান এবং মূল অপশন দেখায়।
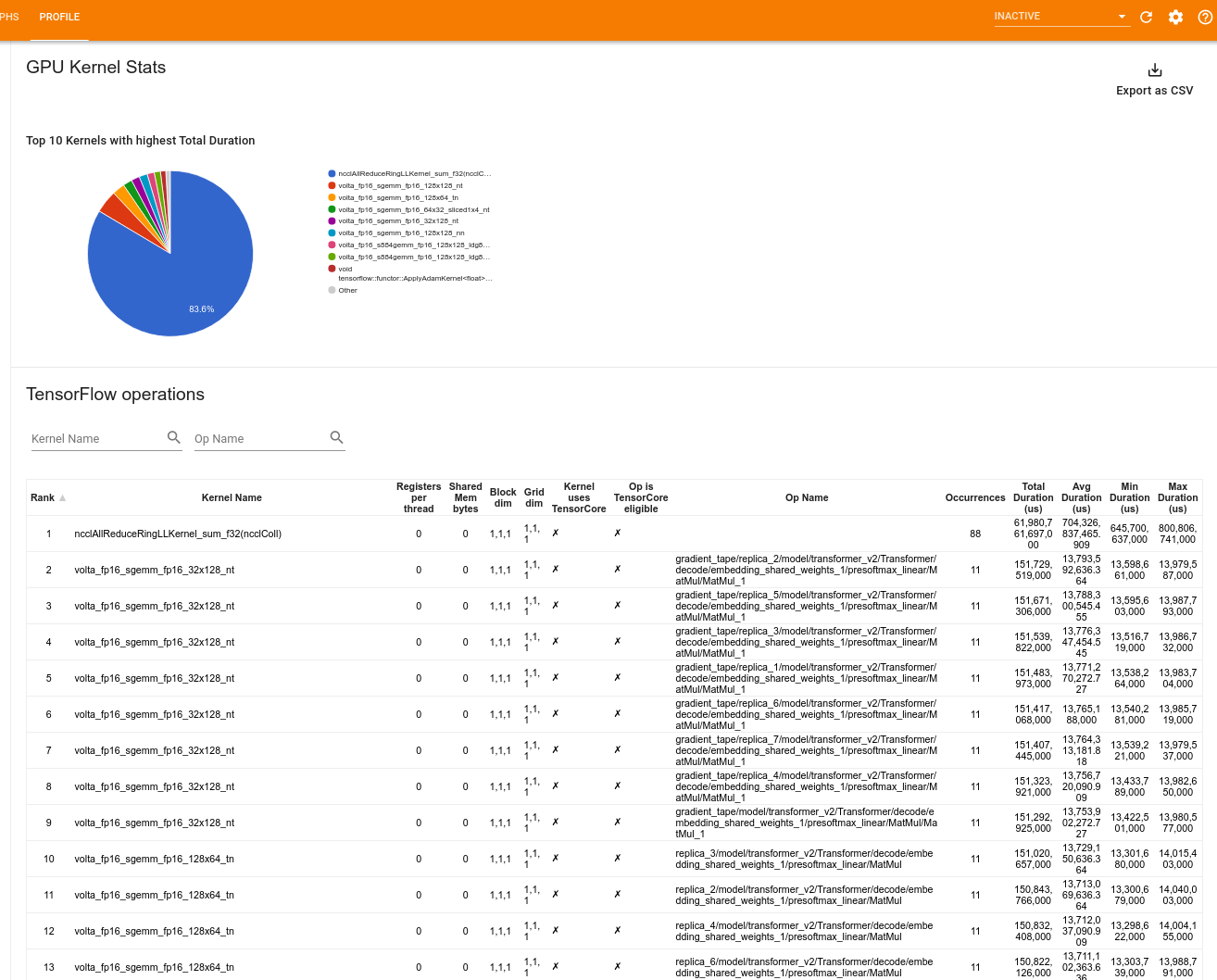
টুল দুটি প্যানে তথ্য প্রদর্শন করে:
উপরের ফলকটি একটি পাই চার্ট প্রদর্শন করে যা CUDA কার্নেলগুলি দেখায় যেগুলির সর্বাধিক মোট সময় অতিবাহিত হয়েছে।
নীচের ফলকটি প্রতিটি অনন্য কার্নেল-অপ জোড়ার জন্য নিম্নলিখিত ডেটা সহ একটি টেবিল প্রদর্শন করে:
- কার্নেল-অপ পেয়ার দ্বারা গোষ্ঠীবদ্ধ মোট অতিবাহিত GPU সময়কালের অবরোহ ক্রমে একটি র্যাঙ্ক।
- লঞ্চ করা কার্নেলের নাম।
- কার্নেল দ্বারা ব্যবহৃত GPU রেজিস্টারের সংখ্যা।
- বাইটে ব্যবহৃত শেয়ার্ড (স্ট্যাটিক + ডাইনামিক শেয়ার্ড) মেমরির মোট আকার।
- ব্লকের মাত্রা
blockDim.x, blockDim.y, blockDim.zহিসাবে প্রকাশ করা হয়েছে। - গ্রিডের মাত্রা
gridDim.x, gridDim.y, gridDim.zহিসাবে প্রকাশ করা হয়েছে। - অপটি টেনসর কোর ব্যবহার করার যোগ্য কিনা।
- কার্নেলে টেনসর কোর নির্দেশাবলী রয়েছে কিনা।
- অপের নাম যে এই কার্নেলটি চালু করেছে।
- এই কার্নেল-অপ জোড়ার সংঘটনের সংখ্যা।
- মাইক্রোসেকেন্ডে মোট অতিবাহিত GPU সময়।
- মাইক্রোসেকেন্ডে গড় অতিবাহিত GPU সময়।
- মাইক্রোসেকেন্ডে ন্যূনতম অতিবাহিত GPU সময়।
- মাইক্রোসেকেন্ডে সর্বাধিক অতিবাহিত GPU সময়।
মেমরি প্রোফাইল টুল
মেমরি প্রোফাইল টুল প্রোফাইলিং ব্যবধানের সময় আপনার ডিভাইসের মেমরি ব্যবহার নিরীক্ষণ করে। আপনি এই টুল ব্যবহার করতে পারেন:
- পিক মেমরির ব্যবহার এবং TensorFlow অপারেশনের সাথে সংশ্লিষ্ট মেমরি বরাদ্দকরণের মাধ্যমে মেমরির (OOM) সমস্যাগুলি ডিবাগ করুন। আপনি বহু-টেন্যান্সি ইনফারেন্স চালালে যে OOM সমস্যাগুলি দেখা দিতে পারে আপনি ডিবাগ করতে পারেন।
- ডিবাগ মেমরি ফ্র্যাগমেন্টেশন সমস্যা।
মেমরি প্রোফাইল টুল তিনটি বিভাগে ডেটা প্রদর্শন করে:
- মেমরি প্রোফাইল সারাংশ
- মেমরি টাইমলাইন গ্রাফ
- মেমরি ব্রেকডাউন টেবিল
মেমরি প্রোফাইল সারাংশ
এই বিভাগটি নীচে দেখানো হিসাবে আপনার TensorFlow প্রোগ্রামের মেমরি প্রোফাইলের একটি উচ্চ-স্তরের সারাংশ প্রদর্শন করে:
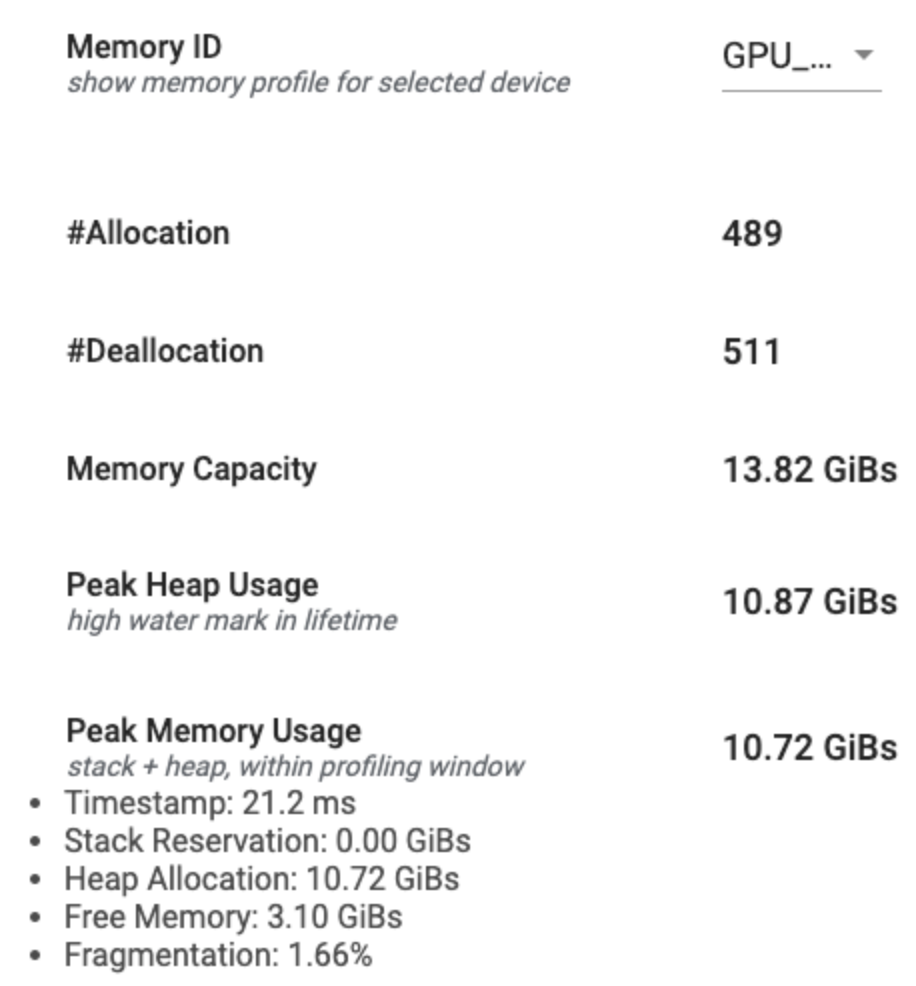
মেমরি প্রোফাইল সারাংশে ছয়টি ক্ষেত্র রয়েছে:
- মেমরি আইডি : ড্রপডাউন যা সমস্ত উপলব্ধ ডিভাইস মেমরি সিস্টেমের তালিকা করে। ড্রপডাউন থেকে আপনি যে মেমরি সিস্টেমটি দেখতে চান তা নির্বাচন করুন।
- #বরাদ্দ : প্রোফাইলিং ব্যবধানের সময় মেমরি বরাদ্দের সংখ্যা।
- #Deallocation : প্রোফাইলিং ব্যবধানে মেমরি ডিললোকেশনের সংখ্যা
- মেমরি ক্যাপাসিটি : আপনি যে মেমরি সিস্টেম নির্বাচন করেছেন তার মোট ক্ষমতা (GiBs-এ)।
- পিক হিপ ব্যবহার : মডেলটি চলা শুরু হওয়ার পর থেকে সর্বোচ্চ মেমরি ব্যবহার (GiBs-এ)।
- পিক মেমরি ব্যবহার : প্রোফাইলিং ব্যবধানে সর্বোচ্চ মেমরি ব্যবহার (GiBs-এ)। এই ক্ষেত্রটিতে নিম্নলিখিত উপ-ক্ষেত্র রয়েছে:
- টাইমস্ট্যাম্প : টাইমলাইন গ্রাফে কখন পিক মেমরি ব্যবহার হয়েছিল তার টাইমস্ট্যাম্প৷
- স্ট্যাক রিজার্ভেশন : স্ট্যাকের উপর সংরক্ষিত মেমরির পরিমাণ (GiB-তে)।
- হিপ অ্যালোকেশন : হিপে বরাদ্দকৃত মেমরির পরিমাণ (GiB-তে)।
- ফ্রি মেমরি : ফ্রি মেমরির পরিমাণ (GIB-তে)। মেমরি ক্যাপাসিটি হল স্ট্যাক রিজার্ভেশন, হিপ অ্যালোকেশন এবং ফ্রি মেমরির মোট যোগফল।
- ফ্র্যাগমেন্টেশন : ফ্র্যাগমেন্টেশনের শতাংশ (নিম্ন হলে ভালো)। এটি শতাংশ হিসাবে গণনা করা হয়
(1 - Size of the largest chunk of free memory / Total free memory)
মেমরি টাইমলাইন গ্রাফ
এই বিভাগটি মেমরি ব্যবহারের একটি প্লট (GiBs-এ) এবং খণ্ডিতকরণের শতাংশ বনাম সময় (ms-এ) প্রদর্শন করে।
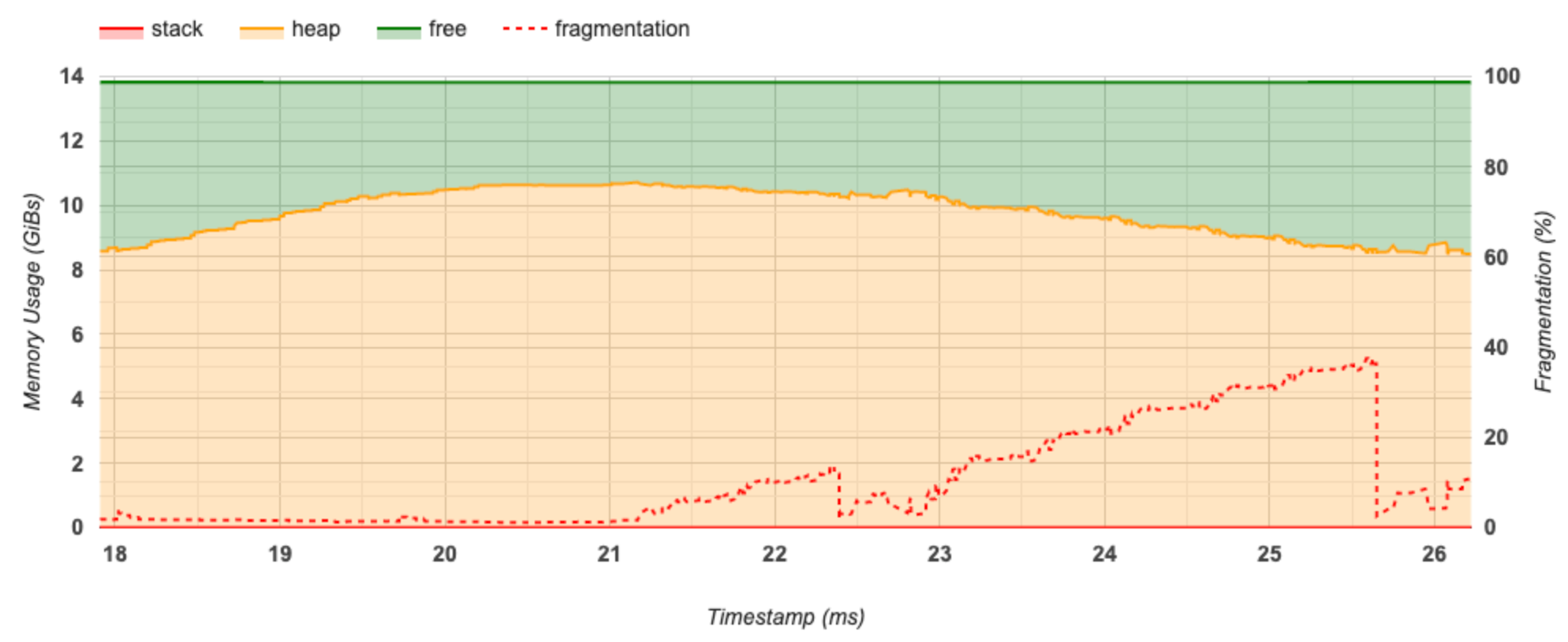
X-অক্ষ প্রোফাইলিং ব্যবধানের টাইমলাইন (এমএসে) প্রতিনিধিত্ব করে। বাম দিকের Y-অক্ষটি মেমরির ব্যবহারকে প্রতিনিধিত্ব করে (GiBs-এ) এবং ডানদিকে Y-অক্ষটি ফ্র্যাগমেন্টেশনের শতাংশকে প্রতিনিধিত্ব করে। X-অক্ষের প্রতিটি সময়ে, মোট মেমরি তিনটি বিভাগে বিভক্ত হয়: স্ট্যাক (লাল), গাদা (কমলা) এবং বিনামূল্যে (সবুজ)। নীচের মত সেই সময়ে মেমরি বরাদ্দ/বরাদ্দকরণ ইভেন্টগুলির বিশদ বিবরণ দেখতে একটি নির্দিষ্ট টাইমস্ট্যাম্পের উপর ঘোরান:
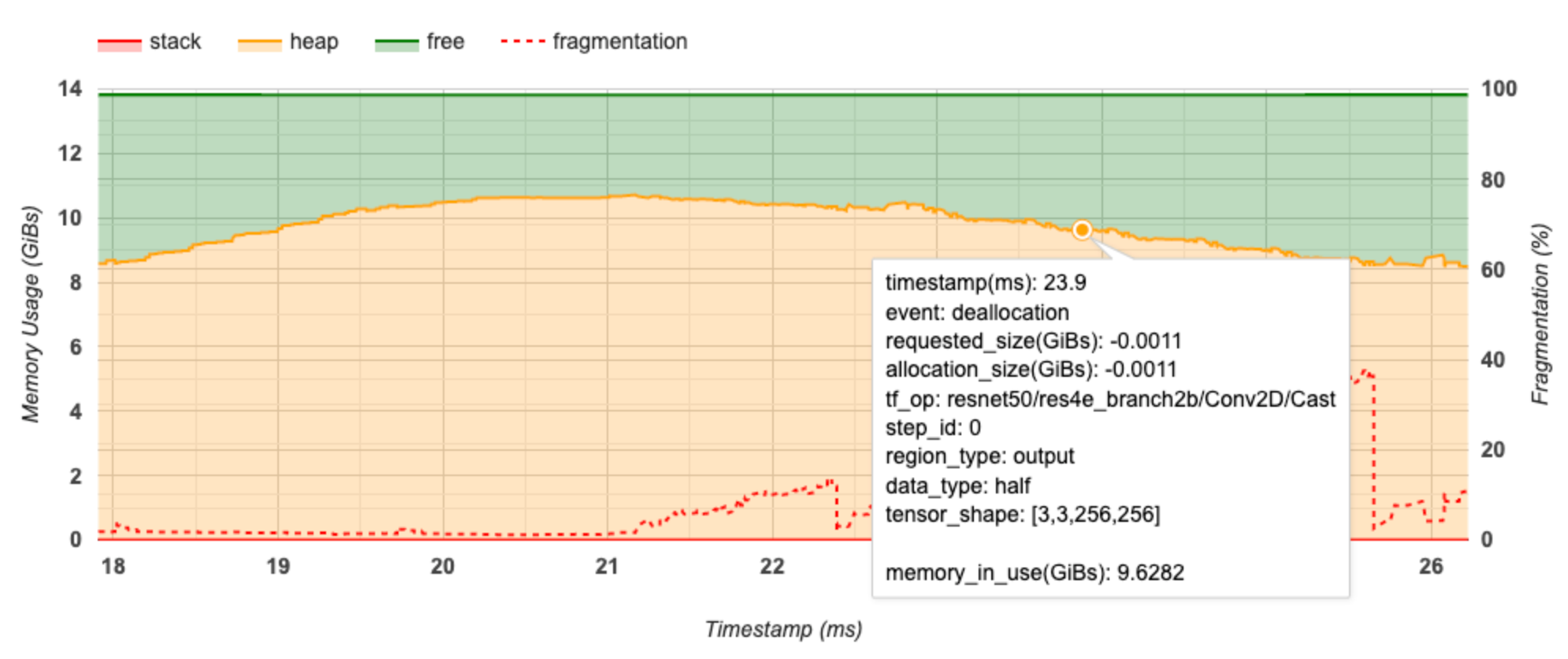
পপ-আপ উইন্ডো নিম্নলিখিত তথ্য প্রদর্শন করে:
- timestamp(ms) : টাইমলাইনে নির্বাচিত ইভেন্টের অবস্থান।
- ঘটনা : ইভেন্টের ধরন (বরাদ্দ বা ডিলোকেশন)।
- requested_size(GiBs) : অনুরোধ করা মেমরির পরিমাণ। ডিলোকেশন ইভেন্টের জন্য এটি একটি নেতিবাচক সংখ্যা হবে।
- allocation_size(GiBs) : বরাদ্দকৃত মেমরির প্রকৃত পরিমাণ। ডিলোকেশন ইভেন্টের জন্য এটি একটি নেতিবাচক সংখ্যা হবে।
- tf_op : TensorFlow op যেটি বরাদ্দ/বরাদ্দের অনুরোধ করে।
- step_id : প্রশিক্ষণের ধাপে এই ঘটনাটি ঘটেছে।
- region_type : ডেটা সত্তা টাইপ যার জন্য এই বরাদ্দ করা মেমরি। সম্ভাব্য মান হল অস্থায়ী জন্য
temp, অ্যাক্টিভেশন এবং গ্রেডিয়েন্টের জন্যoutputএবং ওজন এবং ধ্রুবকের জন্যpersist/dynamic। - data_type : টেনসর উপাদানের ধরন (যেমন, 8-বিট স্বাক্ষরবিহীন পূর্ণসংখ্যার জন্য uint8)।
- tensor_shape : টেনসরের আকৃতি বরাদ্দ/বরাদ্দ করা হচ্ছে।
- memory_in_use(GiBs) : এই সময়ে ব্যবহৃত মোট মেমরি।
মেমরি ব্রেকডাউন টেবিল
এই টেবিলটি প্রোফাইলিং ব্যবধানে পিক মেমরি ব্যবহারের পয়েন্টে সক্রিয় মেমরি বরাদ্দ দেখায়।
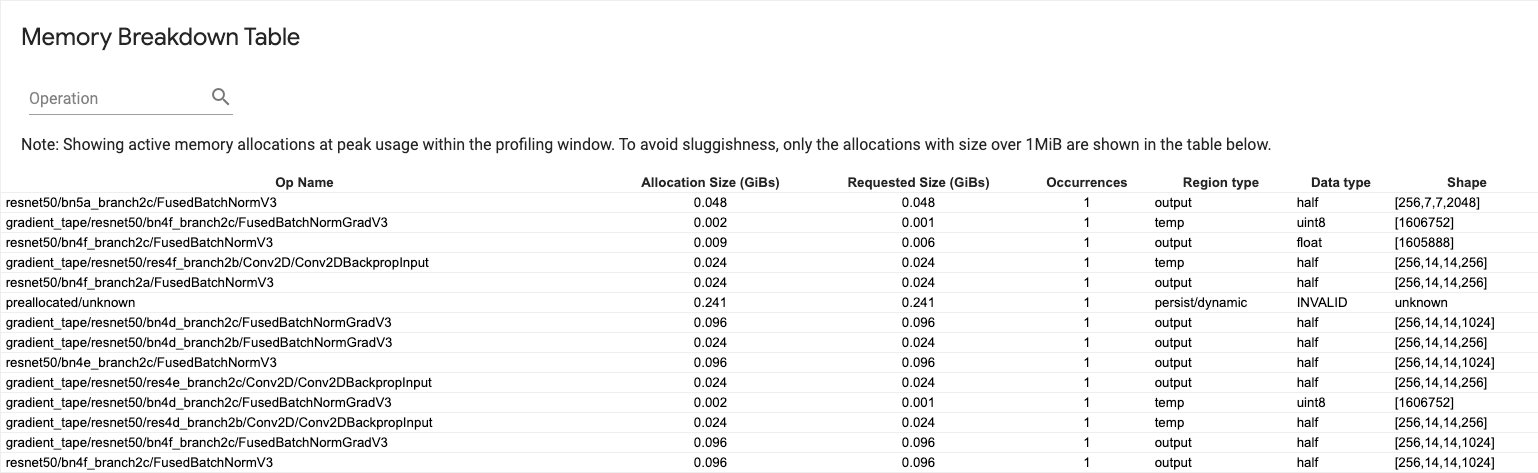
প্রতিটি টেনসরফ্লো অপের জন্য একটি সারি রয়েছে এবং প্রতিটি সারিতে নিম্নলিখিত কলাম রয়েছে:
- অপের নাম : টেনসরফ্লো অপের নাম।
- বরাদ্দের আকার (GiBs) : এই অপের জন্য বরাদ্দকৃত মেমরির মোট পরিমাণ।
- অনুরোধকৃত আকার (GiBs) : এই অপশনের জন্য অনুরোধ করা মেমরির মোট পরিমাণ।
- ঘটনা : এই অপশনের জন্য বরাদ্দের সংখ্যা।
- অঞ্চলের ধরন : এই বরাদ্দ করা মেমরির জন্য ডেটা সত্তার ধরন। সম্ভাব্য মান হল অস্থায়ী জন্য
temp, অ্যাক্টিভেশন এবং গ্রেডিয়েন্টের জন্যoutputএবং ওজন এবং ধ্রুবকের জন্যpersist/dynamic। - ডেটা টাইপ : টেনসর উপাদানের ধরন।
- আকৃতি : বরাদ্দকৃত টেনসরের আকৃতি।
পড ভিউয়ার
পড ভিউয়ার টুলটি সমস্ত কর্মীদের মধ্যে একটি প্রশিক্ষণ ধাপের ভাঙ্গন দেখায়।
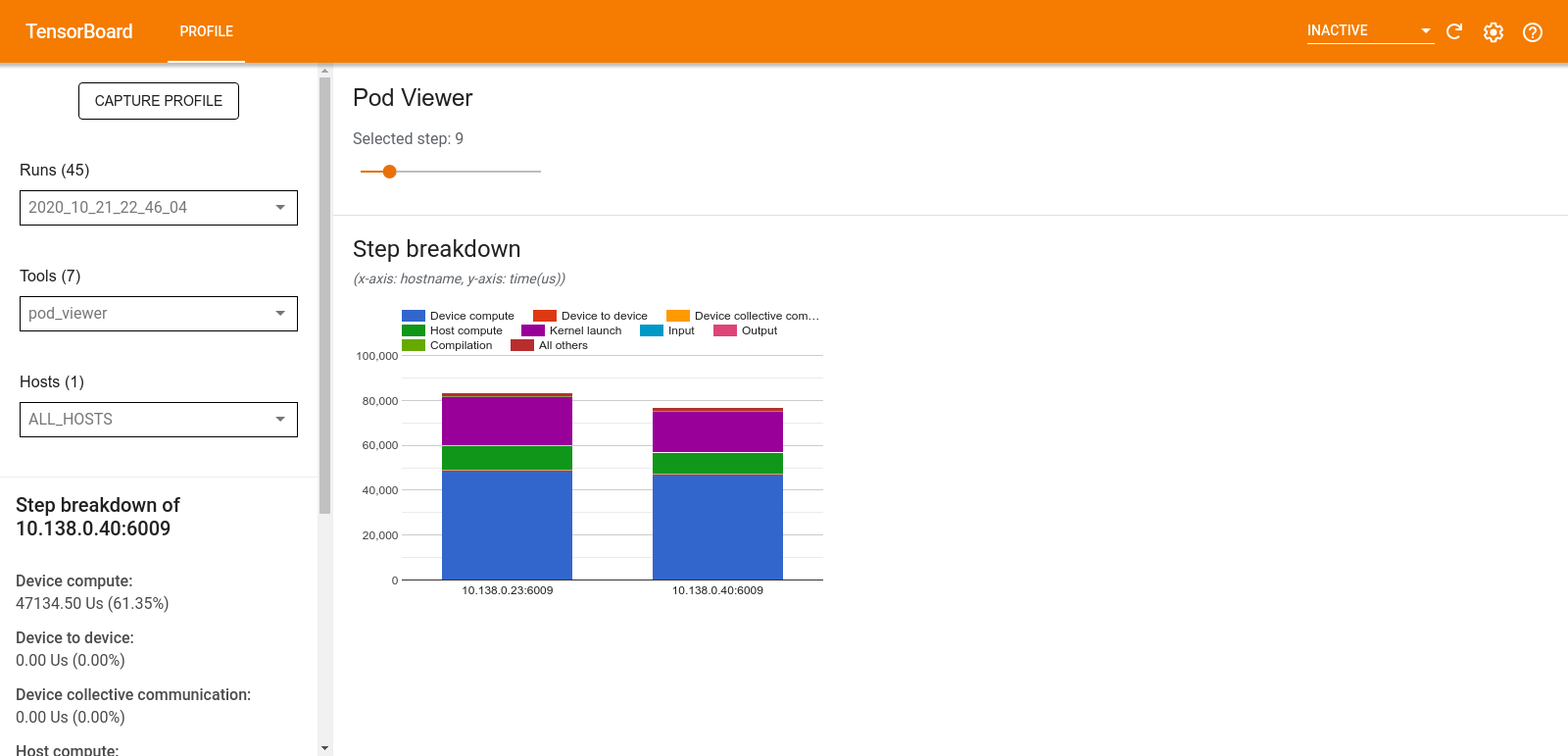
- ধাপ নম্বর নির্বাচন করার জন্য উপরের ফলকটিতে একটি স্লাইডার রয়েছে।
- নীচের ফলকটি একটি স্ট্যাক করা কলাম চার্ট প্রদর্শন করে। এটি একে অপরের উপরে স্থাপন করা ধাপে ধাপে বিভক্ত হওয়া বিভাগগুলির একটি উচ্চ স্তরের দৃশ্য। প্রতিটি স্ট্যাক করা কলাম একটি অনন্য কর্মীর প্রতিনিধিত্ব করে।
- আপনি যখন স্তুপীকৃত কলামের উপর কার্সার করেন, তখন বাম দিকের কার্ডটি ধাপের বিভাজন সম্পর্কে আরও বিশদ দেখায়।
tf.data বাধা বিশ্লেষণ
tf.data বটলনেক বিশ্লেষণ টুলটি স্বয়ংক্রিয়ভাবে আপনার প্রোগ্রামে tf.data ইনপুট পাইপলাইনে বাধা সনাক্ত করে এবং সেগুলি কীভাবে ঠিক করা যায় সে সম্পর্কে সুপারিশ প্রদান করে। এটি প্লাটফর্ম (CPU/GPU/TPU) নির্বিশেষে tf.data ব্যবহার করে যেকোনো প্রোগ্রামের সাথে কাজ করে। এর বিশ্লেষণ এবং সুপারিশ এই গাইডের উপর ভিত্তি করে।
এটি এই পদক্ষেপগুলি অনুসরণ করে একটি বাধা সনাক্ত করে:
- সবচেয়ে ইনপুট আবদ্ধ হোস্ট খুঁজুন.
- একটি
tf.dataইনপুট পাইপলাইনের ধীরতম সঞ্চালন খুঁজুন। - প্রোফাইলার ট্রেস থেকে ইনপুট পাইপলাইন গ্রাফ পুনর্গঠন করুন।
- ইনপুট পাইপলাইন গ্রাফে গুরুত্বপূর্ণ পথটি খুঁজুন।
- একটি বাধা হিসাবে সমালোচনামূলক পথে ধীর রূপান্তর চিহ্নিত করুন।
UI তিনটি বিভাগে বিভক্ত: কর্মক্ষমতা বিশ্লেষণ সারাংশ , সমস্ত ইনপুট পাইপলাইনের সারাংশ এবং ইনপুট পাইপলাইন গ্রাফ ।
কর্মক্ষমতা বিশ্লেষণ সারসংক্ষেপ

এই বিভাগটি বিশ্লেষণের সারাংশ প্রদান করে। এটি প্রোফাইলে সনাক্ত করা ধীর tf.data ইনপুট পাইপলাইনগুলির উপর রিপোর্ট করে৷ এই বিভাগটি সর্বাধিক ইনপুট আবদ্ধ হোস্ট এবং সর্বাধিক লেটেন্সি সহ এর ধীরতম ইনপুট পাইপলাইনও দেখায়। সবচেয়ে গুরুত্বপূর্ণ, এটি সনাক্ত করে যে ইনপুট পাইপলাইনের কোন অংশটি বাধা এবং কীভাবে এটি ঠিক করা যায়। ইটারেটর টাইপ এবং এর দীর্ঘ নামের সাথে বটলনেক তথ্য প্রদান করা হয়।
কিভাবে tf.data iterator এর দীর্ঘ নাম পড়তে হয়
একটি দীর্ঘ নাম Iterator::<Dataset_1>::...::<Dataset_n> । দীর্ঘ নামের মধ্যে, <Dataset_n> পুনরাবৃত্তিকারীর প্রকারের সাথে মেলে এবং দীর্ঘ নামের অন্যান্য ডেটাসেটগুলি নিম্নধারার রূপান্তরগুলিকে উপস্থাপন করে।
উদাহরণস্বরূপ, নিম্নলিখিত ইনপুট পাইপলাইন ডেটাসেট বিবেচনা করুন:
dataset = tf.data.Dataset.range(10).map(lambda x: x).repeat(2).batch(5)
উপরের ডেটাসেট থেকে পুনরাবৃত্তিকারীদের দীর্ঘ নাম হবে:
| পুনরাবৃত্তিকারী প্রকার | দীর্ঘ নাম |
|---|---|
| পরিসর | পুনরাবৃত্তিকারী::ব্যাচ::পুনরাবৃত্তি::মানচিত্র::পরিসীমা |
| মানচিত্র | পুনরাবৃত্তিকারী::ব্যাচ::পুনরাবৃত্তি::মানচিত্র |
| পুনরাবৃত্তি করুন | পুনরাবৃত্তিকারী::ব্যাচ::পুনরাবৃত্তি |
| ব্যাচ | পুনরাবৃত্তিকারী::ব্যাচ |
সমস্ত ইনপুট পাইপলাইনের সারাংশ
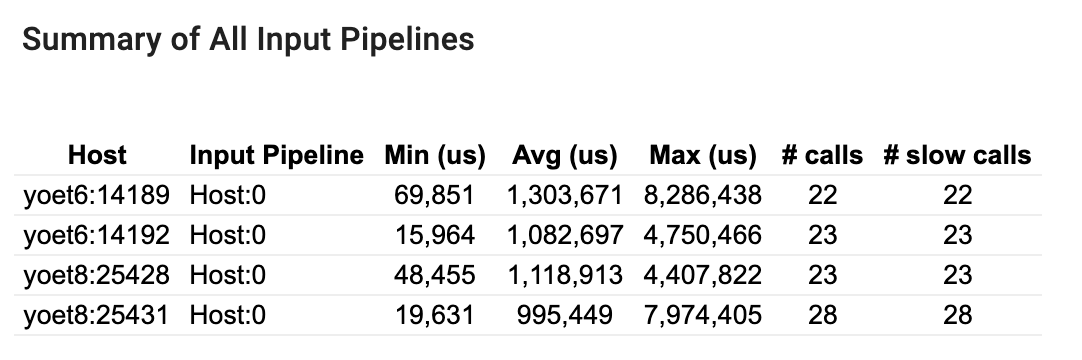
এই বিভাগটি সমস্ত হোস্ট জুড়ে সমস্ত ইনপুট পাইপলাইনের সারাংশ প্রদান করে। সাধারণত একটি ইনপুট পাইপলাইন আছে। বিতরণ কৌশল ব্যবহার করার সময়, একটি হোস্ট ইনপুট পাইপলাইন প্রোগ্রামের tf.data কোড চালায় এবং একাধিক ডিভাইস ইনপুট পাইপলাইন হোস্ট ইনপুট পাইপলাইন থেকে ডেটা পুনরুদ্ধার করে এবং ডিভাইসগুলিতে স্থানান্তর করে।
প্রতিটি ইনপুট পাইপলাইনের জন্য, এটি তার সম্পাদনের সময়ের পরিসংখ্যান দেখায়। একটি কল 50 μs-এর বেশি সময় নিলে ধীর হিসাবে গণনা করা হয়৷
ইনপুট পাইপলাইন গ্রাফ

এই বিভাগটি কার্যকর করার সময় তথ্য সহ ইনপুট পাইপলাইন গ্রাফ দেখায়। কোন হোস্ট এবং ইনপুট পাইপলাইন দেখতে হবে তা চয়ন করতে আপনি "হোস্ট" এবং "ইনপুট পাইপলাইন" ব্যবহার করতে পারেন৷ ইনপুট পাইপলাইনের এক্সিকিউশনগুলি সঞ্চালনের সময় অনুসারে সাজানো হয় নিচের ক্রমে যা আপনি র্যাঙ্ক ড্রপডাউন ব্যবহার করে বেছে নিতে পারেন।
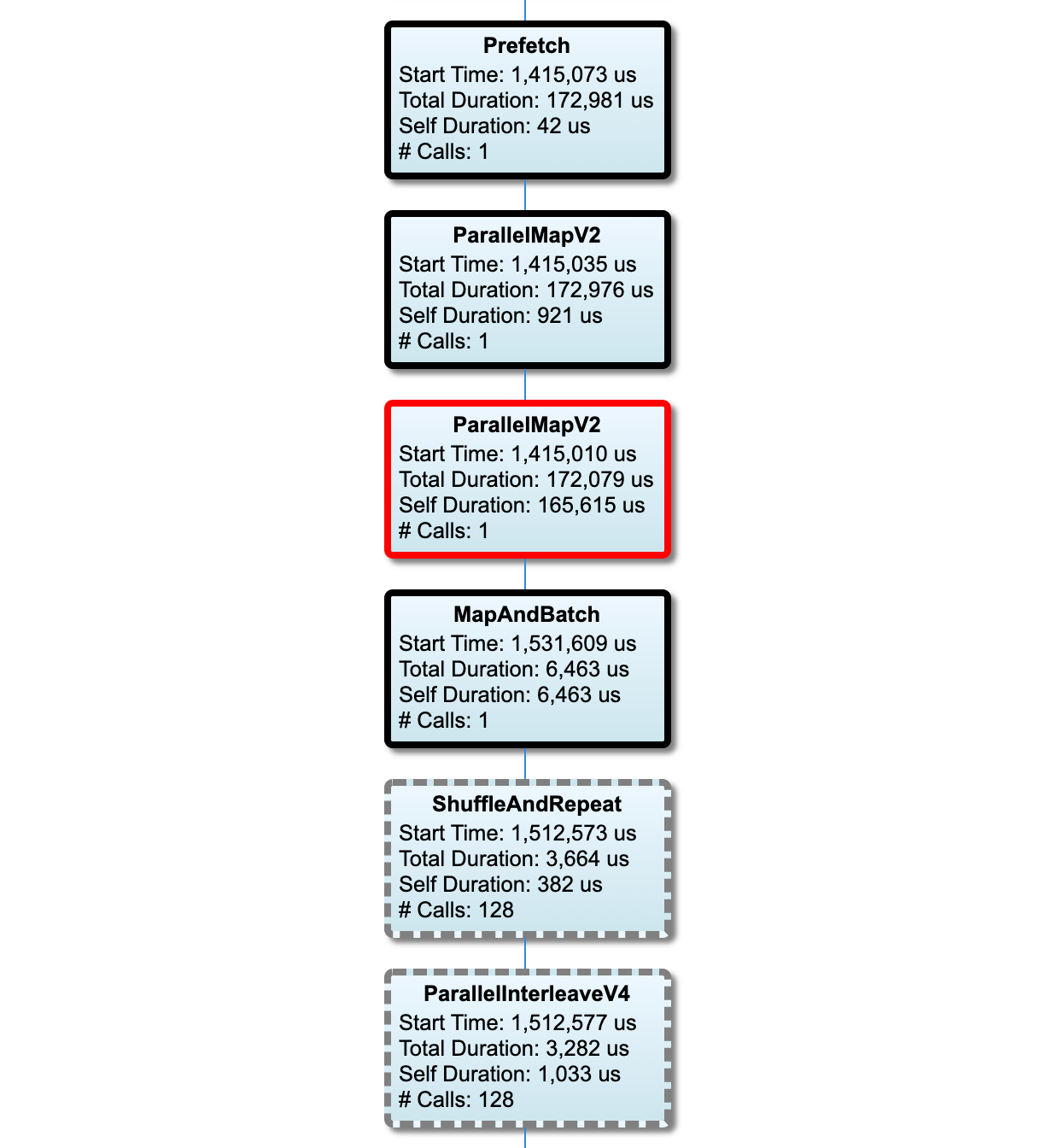
সমালোচনামূলক পথের নোডগুলির গাঢ় রূপরেখা রয়েছে। বটলনেক নোড, যেটি ক্রিটিক্যাল পাথে সবচেয়ে বেশি সময় কাটানো নোড, এর একটি লাল রূপরেখা রয়েছে। অন্যান্য অ-সমালোচনামূলক নোডগুলিতে ধূসর ড্যাশযুক্ত রূপরেখা রয়েছে।
প্রতিটি নোডে, স্টার্ট টাইম এক্সিকিউশনের শুরুর সময় নির্দেশ করে। একই নোড একাধিকবার চালানো হতে পারে, উদাহরণস্বরূপ, যদি ইনপুট পাইপলাইনে একটি Batch অপ থাকে। এটি একাধিকবার কার্যকর করা হলে, এটি প্রথম মৃত্যুদন্ডের শুরুর সময়।
মোট সময়কাল হল মৃত্যুদন্ড কার্যকরের প্রাচীর সময়। যদি এটি একাধিকবার কার্যকর করা হয় তবে এটি সমস্ত মৃত্যুদণ্ডের প্রাচীর সময়ের সমষ্টি।
সেল্ফ টাইম হল মোট সময় যার তাত্ক্ষণিক চাইল্ড নোডগুলির সাথে ওভারল্যাপ করা সময় ছাড়াই।
"# কল" হল ইনপুট পাইপলাইন চালানোর সংখ্যা।
কর্মক্ষমতা তথ্য সংগ্রহ করুন
TensorFlow প্রোফাইলার হোস্ট কার্যকলাপ এবং আপনার TensorFlow মডেলের GPU ট্রেস সংগ্রহ করে। আপনি প্রোগ্রাম্যাটিক মোড বা স্যাম্পলিং মোডের মাধ্যমে কর্মক্ষমতা ডেটা সংগ্রহ করতে প্রোফাইলারকে কনফিগার করতে পারেন।
প্রোফাইলিং API
প্রোফাইলিং সঞ্চালনের জন্য আপনি নিম্নলিখিত API ব্যবহার করতে পারেন।
টেনসরবোর্ড কেরাস কলব্যাক (
tf.keras.callbacks.TensorBoard) ব্যবহার করে প্রোগ্রাম্যাটিক মোড# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])tf.profilerফাংশন API ব্যবহার করে প্রোগ্রাম্যাটিক মোডtf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()প্রসঙ্গ ম্যানেজার ব্যবহার করে প্রোগ্রাম্যাটিক মোড
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
স্যাম্পলিং মোড: আপনার টেনসরফ্লো মডেল চালানোর সাথে একটি gRPC সার্ভার শুরু করতে
tf.profiler.experimental.server.startব্যবহার করে অন-ডিমান্ড প্রোফাইলিং সম্পাদন করুন। gRPC সার্ভার শুরু করার পরে এবং আপনার মডেল চালানোর পরে, আপনি TensorBoard প্রোফাইল প্লাগইনে ক্যাপচার প্রোফাইল বোতামের মাধ্যমে একটি প্রোফাইল ক্যাপচার করতে পারেন। একটি TensorBoard ইনস্ট্যান্স চালু করতে উপরে প্রোফাইলার ইনস্টল করুন বিভাগে স্ক্রিপ্টটি ব্যবহার করুন যদি এটি ইতিমধ্যে চালু না হয়।উদাহরণ হিসেবে,
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)একাধিক কর্মীদের প্রোফাইলিংয়ের জন্য একটি উদাহরণ:
# E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)
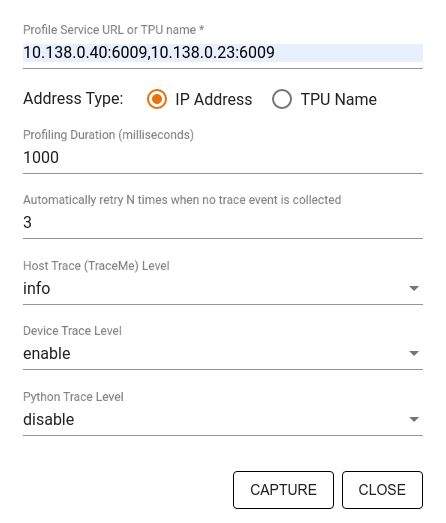
উল্লেখ করতে ক্যাপচার প্রোফাইল ডায়ালগ ব্যবহার করুন:
- প্রোফাইল পরিষেবা URL বা TPU নামের একটি কমা দ্বারা সীমাবদ্ধ তালিকা৷
- একটি প্রোফাইলিং সময়কাল.
- ডিভাইসের স্তর, হোস্ট এবং পাইথন ফাংশন কল ট্রেসিং।
- প্রথমে ব্যর্থ হলে প্রোফাইল ক্যাপচার করার জন্য আপনি কতবার প্রোফাইলারকে আবার চেষ্টা করতে চান৷
কাস্টম প্রশিক্ষণ loops প্রোফাইলিং
আপনার TensorFlow কোডে কাস্টম ট্রেনিং লুপ প্রোফাইল করতে, প্রোফাইলারের ধাপের সীমানা চিহ্নিত করতে tf.profiler.experimental.Trace API দিয়ে ট্রেনিং লুপকে ইনস্ট্রুমেন্ট করুন।
name যুক্তিটি ধাপের নামের জন্য একটি উপসর্গ হিসাবে ব্যবহৃত হয়, ধাপের নামগুলিতে step_num কীওয়ার্ড আর্গুমেন্ট যুক্ত করা হয়, এবং _r কীওয়ার্ড আর্গুমেন্ট এই ট্রেস ইভেন্টটিকে প্রোফাইলারের দ্বারা একটি ধাপ ইভেন্ট হিসাবে প্রক্রিয়া করা হয়।
উদাহরণ হিসেবে,
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
এটি প্রোফাইলারের ধাপ-ভিত্তিক কর্মক্ষমতা বিশ্লেষণকে সক্ষম করবে এবং ধাপ ইভেন্টগুলি ট্রেস ভিউয়ারে দেখানোর কারণ হবে।
নিশ্চিত করুন যে আপনি ইনপুট পাইপলাইনের সঠিক বিশ্লেষণের জন্য tf.profiler.experimental.Trace প্রসঙ্গ-এর মধ্যে ডেটাসেট পুনরাবৃত্তিকারী অন্তর্ভুক্ত করেছেন।
নীচের কোড স্নিপেট একটি বিরোধী প্যাটার্ন:
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
প্রোফাইলিং ব্যবহার ক্ষেত্রে
প্রোফাইলারটি চারটি ভিন্ন অক্ষ বরাবর বেশ কয়েকটি ব্যবহারের ক্ষেত্রে কভার করে। কিছু সংমিশ্রণ বর্তমানে সমর্থিত এবং অন্যগুলি ভবিষ্যতে যোগ করা হবে৷ কিছু ব্যবহারের ক্ষেত্রে হল:
- স্থানীয় বনাম দূরবর্তী প্রোফাইলিং : আপনার প্রোফাইলিং পরিবেশ সেট আপ করার এই দুটি সাধারণ উপায়। স্থানীয় প্রোফাইলিং-এ, আপনার মডেল যে মেশিনে এক্সিকিউট করছে সেই মেশিনে প্রোফাইলিং API বলা হয়, উদাহরণস্বরূপ, GPU সহ একটি স্থানীয় ওয়ার্কস্টেশন। দূরবর্তী প্রোফাইলিং-এ, প্রোফাইলিং এপিআই একটি ভিন্ন মেশিনে কল করা হয় যেখান থেকে আপনার মডেলটি কার্যকর করা হচ্ছে, উদাহরণস্বরূপ, একটি ক্লাউড TPU-তে।
- একাধিক কর্মীদের প্রোফাইলিং : TensorFlow এর বিতরণকৃত প্রশিক্ষণ ক্ষমতা ব্যবহার করার সময় আপনি একাধিক মেশিন প্রোফাইল করতে পারেন।
- হার্ডওয়্যার প্ল্যাটফর্ম : প্রোফাইল সিপিইউ, জিপিইউ এবং টিপিইউ।
নীচের টেবিলটি উপরে উল্লিখিত TensorFlow-সমর্থিত ব্যবহারের ক্ষেত্রে একটি দ্রুত ওভারভিউ প্রদান করে:
| প্রোফাইলিং API | স্থানীয় | দূরবর্তী | একাধিক কর্মী | হার্ডওয়্যার প্ল্যাটফর্ম |
|---|---|---|---|---|
| টেনসরবোর্ড কেরাস কলব্যাক | সমর্থিত | সমর্থিত নয় | সমর্থিত নয় | সিপিইউ, জিপিইউ |
tf.profiler.experimental start/stop API | সমর্থিত | সমর্থিত নয় | সমর্থিত নয় | সিপিইউ, জিপিইউ |
tf.profiler.experimental client.trace API | সমর্থিত | সমর্থিত | সমর্থিত | সিপিইউ, জিপিইউ, টিপিইউ |
| প্রসঙ্গ ম্যানেজার API | সমর্থিত | সমর্থিত নয় | সমর্থিত নয় | সিপিইউ, জিপিইউ |
সর্বোত্তম মডেল পারফরম্যান্সের জন্য সর্বোত্তম অনুশীলন
সর্বোত্তম কর্মক্ষমতা অর্জন করতে আপনার টেনসরফ্লো মডেলগুলির জন্য প্রযোজ্য হিসাবে নিম্নলিখিত সুপারিশগুলি ব্যবহার করুন৷
সাধারণভাবে, ডিভাইসে সমস্ত রূপান্তর সম্পাদন করুন এবং নিশ্চিত করুন যে আপনি আপনার প্ল্যাটফর্মের জন্য cuDNN এবং Intel MKL-এর মতো লাইব্রেরির সর্বশেষ সামঞ্জস্যপূর্ণ সংস্করণ ব্যবহার করছেন।
ইনপুট ডেটা পাইপলাইন অপ্টিমাইজ করুন
আপনার ডেটা ইনপুট পাইপলাইন অপ্টিমাইজ করতে [#input_pipeline_analyzer] থেকে ডেটা ব্যবহার করুন। একটি দক্ষ ডেটা ইনপুট পাইপলাইন ডিভাইসের অলস সময় কমিয়ে আপনার মডেল এক্সিকিউশনের গতিকে ব্যাপকভাবে উন্নত করতে পারে। আপনার ডেটা ইনপুট পাইপলাইনকে আরও দক্ষ করতে tf.data API নির্দেশিকা এবং নীচের সাথে আরও ভাল পারফরম্যান্সে বিশদ সেরা অনুশীলনগুলি অন্তর্ভুক্ত করার চেষ্টা করুন।
সাধারণভাবে, যেকোনও অপ্সের সমান্তরালকরণ যা ক্রমানুসারে চালানোর প্রয়োজন নেই তা উল্লেখযোগ্যভাবে ডেটা ইনপুট পাইপলাইনকে অপ্টিমাইজ করতে পারে।
অনেক ক্ষেত্রে, এটি কিছু কলের ক্রম পরিবর্তন করতে বা আর্গুমেন্ট টিউন করতে সাহায্য করে যাতে এটি আপনার মডেলের জন্য সবচেয়ে ভালো কাজ করে। ইনপুট ডেটা পাইপলাইন অপ্টিমাইজ করার সময়, অপ্টিমাইজেশনের প্রভাব স্বাধীনভাবে পরিমাপ করার জন্য প্রশিক্ষণ এবং ব্যাকপ্রোপগেশন পদক্ষেপ ছাড়াই শুধুমাত্র ডেটা লোডারকে বেঞ্চমার্ক করুন।
ইনপুট পাইপলাইন একটি কর্মক্ষমতা বাধা কিনা তা পরীক্ষা করতে সিন্থেটিক ডেটা দিয়ে আপনার মডেল চালানোর চেষ্টা করুন।
মাল্টি-জিপিইউ প্রশিক্ষণের জন্য
tf.data.Dataset.shardব্যবহার করুন। থ্রুপুট হ্রাস রোধ করতে ইনপুট লুপে খুব তাড়াতাড়ি শার্ড করা নিশ্চিত করুন। TFRecords-এর সাথে কাজ করার সময়, নিশ্চিত করুন যে আপনি TFRecords-এর তালিকাটি সংক্ষিপ্ত করেছেন এবং TFRecords-এর বিষয়বস্তু নয়।tf.data.AUTOTUNEব্যবহার করেnum_parallel_callsএর মান গতিশীলভাবে সেট করে বেশ কয়েকটি অপারেশনকে সমান্তরাল করুন।tf.data.Dataset.from_generatorএর ব্যবহার সীমিত করার কথা বিবেচনা করুন কারণ এটি বিশুদ্ধ TensorFlow অপারেশনের তুলনায় ধীর।tf.py_functionএর ব্যবহার সীমিত করার কথা বিবেচনা করুন কারণ এটি সিরিয়াল করা যায় না এবং বিতরণ করা TensorFlow-এ চালানোর জন্য সমর্থিত নয়।ইনপুট পাইপলাইনে স্ট্যাটিক অপ্টিমাইজেশন নিয়ন্ত্রণ করতে
tf.data.Optionsব্যবহার করুন।
এছাড়াও আপনার ইনপুট পাইপলাইন অপ্টিমাইজ করার বিষয়ে আরও নির্দেশনার জন্য tf.data কর্মক্ষমতা বিশ্লেষণ নির্দেশিকা পড়ুন।
তথ্য বৃদ্ধি অপ্টিমাইজ করুন
ইমেজ ডেটা নিয়ে কাজ করার সময়, স্থানিক রূপান্তর, যেমন ফ্লিপিং, ক্রপিং, ঘোরানো ইত্যাদি প্রয়োগ করার পরে বিভিন্ন ডেটা প্রকারে কাস্ট করে আপনার ডেটা বৃদ্ধিকে আরও দক্ষ করে তুলুন।
NVIDIA® DALI ব্যবহার করুন
কিছু ক্ষেত্রে, যেমন আপনার যখন উচ্চ GPU থেকে CPU অনুপাত সহ একটি সিস্টেম থাকে, উপরের সমস্ত অপ্টিমাইজেশানগুলি CPU চক্রের সীমাবদ্ধতার কারণে ডেটা লোডারে বাধাগুলি দূর করার জন্য যথেষ্ট নাও হতে পারে।
আপনি যদি কম্পিউটার ভিশন এবং অডিও ডিপ লার্নিং অ্যাপ্লিকেশানের জন্য NVIDIA® GPU ব্যবহার করেন, তাহলে ডেটা পাইপলাইনকে ত্বরান্বিত করতে ডেটা লোডিং লাইব্রেরি ( DALI ) ব্যবহার করার কথা বিবেচনা করুন৷
NVIDIA® DALI: সমর্থিত DALI অপ্সের তালিকার জন্য অপারেশন ডকুমেন্টেশন দেখুন।
থ্রেডিং এবং সমান্তরাল এক্সিকিউশন ব্যবহার করুন
tf.config.threading API-এর সাথে একাধিক CPU থ্রেডে অপ্স চালান যাতে দ্রুত কার্যকর হয়।
TensorFlow স্বয়ংক্রিয়ভাবে ডিফল্টরূপে সমান্তরাল থ্রেডের সংখ্যা সেট করে। TensorFlow ops চালানোর জন্য উপলব্ধ থ্রেড পুল উপলব্ধ CPU থ্রেডের সংখ্যার উপর নির্ভর করে।
tf.config.threading.set_intra_op_parallelism_threads ব্যবহার করে একটি একক অপের জন্য সর্বাধিক সমান্তরাল গতি নিয়ন্ত্রণ করুন। মনে রাখবেন যে আপনি যদি সমান্তরালে একাধিক অপ্স চালান, তবে তারা সকলেই উপলব্ধ থ্রেড পুল ভাগ করবে।
আপনার যদি স্বাধীন নন-ব্লকিং অপ্স থাকে (গ্রাফে তাদের মধ্যে কোনো নির্দেশিত পথ ছাড়া অপ্স), উপলব্ধ থ্রেড পুল ব্যবহার করে একই সাথে চালানোর জন্য tf.config.threading.set_inter_op_parallelism_threads ব্যবহার করুন।
বিবিধ
NVIDIA® GPU-তে ছোট মডেলগুলির সাথে কাজ করার সময়, আপনি মডেলের কর্মক্ষমতাকে একটি উল্লেখযোগ্য বৃদ্ধি দিতে CUDA পিনড মেমরির সাথে সমস্ত CPU টেনসর বরাদ্দ করতে বাধ্য করতে tf.compat.v1.ConfigProto.force_gpu_compatible=True সেট করতে পারেন। যাইহোক, অজানা/খুব বড় মডেলের জন্য এই বিকল্পটি ব্যবহার করার সময় সতর্কতা অবলম্বন করুন কারণ এটি হোস্ট (CPU) কর্মক্ষমতাকে নেতিবাচকভাবে প্রভাবিত করতে পারে।
ডিভাইসের কর্মক্ষমতা উন্নত করুন
অন-ডিভাইস টেনসরফ্লো মডেল পারফরম্যান্স অপ্টিমাইজ করতে এখানে এবং GPU পারফরম্যান্স অপ্টিমাইজেশান গাইডে বিস্তারিত সেরা অনুশীলনগুলি অনুসরণ করুন।
আপনি যদি NVIDIA GPU ব্যবহার করে থাকেন, তাহলে GPU এবং মেমরির ব্যবহার একটি CSV ফাইলে চালিয়ে লগ করুন:
nvidia-smi
--query-gpu=utilization.gpu,utilization.memory,memory.total,
memory.free,memory.used --format=csv
ডেটা লেআউট কনফিগার করুন
চ্যানেলের তথ্য (যেমন ছবি) ধারণ করে এমন ডেটা নিয়ে কাজ করার সময়, চ্যানেলগুলিকে পছন্দ করতে ডেটা লেআউট বিন্যাসটি অপ্টিমাইজ করুন (NCHW এর উপর NHWC)।
চ্যানেল-লাস্ট ডেটা ফরম্যাটগুলি টেনসর কোর ব্যবহার উন্নত করে এবং বিশেষত এএমপি-এর সাথে মিলিত হলে কনভোল্যুশনাল মডেলগুলিতে উল্লেখযোগ্য কর্মক্ষমতা উন্নত করে। NCHW ডেটা লেআউটগুলি এখনও টেনসর কোর দ্বারা পরিচালিত হতে পারে, তবে স্বয়ংক্রিয় ট্রান্সপোজ অপ্সের কারণে অতিরিক্ত ওভারহেড চালু করে।
আপনি tf.keras.layers.Conv2D , tf.keras.layers.Conv3D , এবং tf.keras.layers.RandomRotation এর মতো স্তরগুলির জন্য data_format="channels_last" সেট করে NHWC লেআউটগুলিকে পছন্দ করতে ডেটা লেআউটটিকে অপ্টিমাইজ করতে পারেন।
Keras ব্যাকএন্ড API-এর জন্য ডিফল্ট ডেটা লেআউট বিন্যাস সেট করতে tf.keras.backend.set_image_data_format ব্যবহার করুন।
সর্বোচ্চ L2 ক্যাশে আউট
NVIDIA® GPU-এর সাথে কাজ করার সময়, প্রশিক্ষণ লুপের আগে নীচের কোড স্নিপেটটি চালান যাতে L2 128 বাইটে গ্রানুলারিটি নিয়ে আসে।
import ctypes
_libcudart = ctypes.CDLL('libcudart.so')
# Set device limit on the current device
# cudaLimitMaxL2FetchGranularity = 0x05
pValue = ctypes.cast((ctypes.c_int*1)(), ctypes.POINTER(ctypes.c_int))
_libcudart.cudaDeviceSetLimit(ctypes.c_int(0x05), ctypes.c_int(128))
_libcudart.cudaDeviceGetLimit(pValue, ctypes.c_int(0x05))
assert pValue.contents.value == 128
GPU থ্রেড ব্যবহার কনফিগার করুন
GPU থ্রেড মোড সিদ্ধান্ত নেয় কিভাবে GPU থ্রেড ব্যবহার করা হয়।
প্রিপ্রসেসিং সমস্ত GPU থ্রেড চুরি না করে তা নিশ্চিত করতে থ্রেড মোডটিকে gpu_private এ সেট করুন। এটি প্রশিক্ষণের সময় কার্নেল লঞ্চ বিলম্ব হ্রাস করবে। আপনি GPU প্রতি থ্রেডের সংখ্যাও সেট করতে পারেন। পরিবেশ ভেরিয়েবল ব্যবহার করে এই মানগুলি সেট করুন।
import os
os.environ['TF_GPU_THREAD_MODE']='gpu_private'
os.environ['TF_GPU_THREAD_COUNT']='1'
জিপিইউ মেমরি বিকল্পগুলি কনফিগার করুন
সাধারণভাবে, ব্যাচের আকার বাড়ান এবং জিপিইউগুলি আরও ভালভাবে ব্যবহার করতে এবং উচ্চতর থ্রুপুট পেতে মডেলটি স্কেল করুন। নোট করুন যে ব্যাচের আকার বাড়ানো মডেলের যথার্থতা পরিবর্তন করবে তাই লক্ষ্য নির্ভুলতা পূরণের জন্য শেখার হারের মতো হাইপারপ্যারামিটারগুলি টিউন করে মডেলটিকে ছোট করা দরকার।
এছাড়াও, tf.config.experimental.set_memory_growth ব্যবহার করুন জিপিইউ মেমরিটি বাড়ার জন্য সমস্ত উপলব্ধ মেমরিটিকে সম্পূর্ণরূপে ওপিএসে বরাদ্দ করা থেকে রোধ করতে বাড়াতে অনুমতি দেয় যাতে কেবলমাত্র মেমরির একটি ভগ্নাংশের প্রয়োজন হয়। এটি অন্যান্য প্রক্রিয়াগুলির অনুমতি দেয় যা জিপিইউ মেমরিটি একই ডিভাইসে চালানোর জন্য ব্যবহার করে।
আরও জানতে, আরও জানার জন্য জিপিইউ গাইডে সীমাবদ্ধ জিপিইউ মেমরি বৃদ্ধির গাইডেন্সটি দেখুন।
বিবিধ
প্রশিক্ষণ লুপের একটি পুনরাবৃত্তিতে ডিভাইসে ব্যবহৃত প্রশিক্ষণের নমুনাগুলির সংখ্যা) জিপিইউতে মেমরি (ওওএম) ত্রুটি ছাড়াই ফিট করে এমন সর্বাধিক পরিমাণে প্রশিক্ষণ মিনি-ব্যাচের আকার (প্রশিক্ষণের লুপের প্রতি ব্যবহৃত প্রশিক্ষণের নমুনাগুলির সংখ্যা) বাড়ান। ব্যাচের আকার বাড়ানো মডেলের যথার্থতাটিকে প্রভাবিত করে - তাই নিশ্চিত করুন যে আপনি লক্ষ্য নির্ভুলতা মেটাতে হাইপারপ্যারামিটারগুলি টিউন করে মডেলটি স্কেল করেছেন।
উত্পাদন কোডে টেনসর বরাদ্দের সময় ওওএম ত্রুটিগুলি রিপোর্টিং অক্ষম করুন।
report_tensor_allocations_upon_oom=Falsetf.compat.v1.RunOptionsরুনোপশনগুলিতে মিথ্যা সেট করুন।কনভোলিউশন স্তরযুক্ত মডেলগুলির জন্য, ব্যাচের নরমালাইজেশন ব্যবহার করে যদি পক্ষপাত সংযোজন সরান। ব্যাচ নরমালাইজেশন তাদের গড় দ্বারা মানগুলি স্থানান্তরিত করে এবং এটি একটি ধ্রুবক পক্ষপাতের শব্দটির প্রয়োজনীয়তা সরিয়ে দেয়।
অন-ডিভাইস ওপিএস কতটা দক্ষতার সাথে চালিত হয় তা জানতে টিএফ পরিসংখ্যান ব্যবহার করুন।
গণনা সম্পাদন করতে
tf.functionব্যবহার করুন এবং ally চ্ছিকভাবে,jit_compile=Trueপতাকা সক্ষম করুন (tf.function(jit_compile=True)। আরও জানতে, xla tf.function ব্যবহার করতে যান।পদক্ষেপের মধ্যে হোস্ট পাইথন অপারেশনগুলি হ্রাস করুন এবং কলব্যাকগুলি হ্রাস করুন। প্রতিটি পদক্ষেপের পরিবর্তে প্রতি কয়েক ধাপে মেট্রিকগুলি গণনা করুন।
ডিভাইস গণনা ইউনিটগুলিকে ব্যস্ত রাখুন।
সমান্তরালভাবে একাধিক ডিভাইসে ডেটা প্রেরণ করুন।
16-বিট সংখ্যাসূচক উপস্থাপনা যেমন
fp16-আইইইই দ্বারা নির্দিষ্ট করা অর্ধেক-নির্ভুলতা ভাসমান পয়েন্ট ফর্ম্যাট-বা মস্তিষ্কের ভাসমান-পয়েন্ট বিফ্লোয়েট 16 ফর্ম্যাট দ্বারা নির্দিষ্ট করা বিবেচনা করুন।
অতিরিক্ত সম্পদ
- টেনসরফ্লো প্রোফাইলার: কেরাস এবং টেনসরবোর্ডের সাথে প্রোফাইল মডেল পারফরম্যান্স টিউটোরিয়াল যেখানে আপনি এই গাইডে পরামর্শটি প্রয়োগ করতে পারেন।
- টেনসরফ্লো 2 তে পারফরম্যান্স প্রোফাইলিং টেনসরফ্লো ডেভ সামিট 2020 থেকে আলাপ।
- টেনসরফ্লো ডেভ সামিট 2020 থেকে টেনসরফ্লো প্রোফাইলার ডেমো ।
পরিচিত সীমাবদ্ধতা
টেনসরফ্লো ২.২ এবং টেনসরফ্লো ২.৩ এ একাধিক জিপিইউ প্রোফাইলিং
টেনসরফ্লো 2.2 এবং 2.3 কেবলমাত্র একক হোস্ট সিস্টেমের জন্য একাধিক জিপিইউ প্রোফাইলিং সমর্থন করে; মাল্টি-হোস্ট সিস্টেমগুলির জন্য একাধিক জিপিইউ প্রোফাইলিং সমর্থিত নয়। মাল্টি-ওয়ার্কার জিপিইউ কনফিগারেশনগুলি প্রোফাইল করতে, প্রতিটি কর্মীকে স্বাধীনভাবে প্রোফাইল করতে হবে। টেনসরফ্লো থেকে ২.৪ থেকে একাধিক কর্মী tf.profiler.experimental.client.trace এপিআই ব্যবহার করে প্রোফাইল করা যেতে পারে।
একাধিক জিপিইউ প্রোফাইল করার জন্য CUDA® টুলকিট 10.2 বা তার পরে প্রয়োজন। টেনসরফ্লো 2.2 এবং 2.3 হিসাবে কেবল 10.1 অবধি সিউডিএ® টুলকিট সংস্করণ সমর্থন করে, আপনাকে libcudart.so.10.1 এবং libcupti.so.10.1 : এর প্রতীকী লিঙ্ক তৈরি করতে হবে:
sudo ln -s /usr/local/cuda/lib64/libcudart.so.10.2 /usr/local/cuda/lib64/libcudart.so.10.1
sudo ln -s /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.2 /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.1