
W tym przewodniku pokazano, jak używać narzędzi dostępnych w programie TensorFlow Profiler do śledzenia wydajności modeli TensorFlow. Dowiesz się, jak zrozumieć, jak Twój model działa na hoście (CPU), urządzeniu (GPU) lub na kombinacji hosta i urządzeń.
Profilowanie pomaga zrozumieć zużycie zasobów sprzętowych (czasu i pamięci) różnych operacji TensorFlow w modelu i rozwiązać wąskie gardła wydajności, a ostatecznie sprawić, że model będzie działał szybciej.
Ten przewodnik przeprowadzi Cię przez proces instalowania Profilera, różne dostępne narzędzia, różne tryby gromadzenia danych dotyczących wydajności przez Profiler oraz niektóre zalecane najlepsze praktyki w celu optymalizacji wydajności modelu.
Jeśli chcesz sprofilować wydajność swojego modelu na Cloud TPU, zapoznaj się z przewodnikiem Cloud TPU .
Zainstaluj wymagania wstępne Profilera i procesora graficznego
Zainstaluj wtyczkę Profiler dla TensorBoard za pomocą pip. Należy pamiętać, że Profiler wymaga najnowszych wersji TensorFlow i TensorBoard (>= 2,2).
pip install -U tensorboard_plugin_profile
Aby profilować na GPU, musisz:
- Spełnij wymagania sterowników GPU NVIDIA® i zestawu narzędzi CUDA® Toolkit wymienione w wymaganiach oprogramowania obsługującego procesor graficzny TensorFlow .
Upewnij się, że interfejs narzędzi profilowania NVIDIA® CUDA® (CUPTI) istnieje na ścieżce:
/sbin/ldconfig -N -v $(sed 's/:/ /g' <<< $LD_LIBRARY_PATH) | \ grep libcupti
Jeśli na ścieżce nie ma CUPTI, dodaj jego katalog instalacyjny do zmiennej środowiskowej $LD_LIBRARY_PATH uruchamiając:
export LD_LIBRARY_PATH=/usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
Następnie ponownie uruchom powyższą komendę ldconfig aby sprawdzić, czy znaleziono bibliotekę CUPTI.
Rozwiąż problemy z uprawnieniami
Kiedy uruchamiasz profilowanie za pomocą CUDA® Toolkit w środowisku Docker lub w systemie Linux, możesz napotkać problemy związane z niewystarczającymi uprawnieniami CUPTI ( CUPTI_ERROR_INSUFFICIENT_PRIVILEGES ). Przejdź do dokumentacji programistycznej NVIDIA, aby dowiedzieć się więcej o tym, jak rozwiązać te problemy w systemie Linux.
Aby rozwiązać problemy z uprawnieniami CUPTI w środowisku Docker, uruchom
docker run option '--privileged=true'
Narzędzia profilera
Uzyskaj dostęp do Profilera z karty Profil w TensorBoard, która pojawia się dopiero po przechwyceniu niektórych danych modelu.
Profiler posiada wybór narzędzi pomagających w analizie wydajności:
- Strona przeglądu
- Analizator potoku wejściowego
- Statystyki TensorFlow
- Przeglądarka śladów
- Statystyki jądra GPU
- Narzędzie profilu pamięci
- Przeglądarka podów
Strona przeglądu
Strona przeglądu zapewnia widok najwyższego poziomu działania modelu podczas przebiegu profilu. Na tej stronie znajduje się zagregowany przegląd hosta i wszystkich urządzeń oraz zalecenia dotyczące poprawy wydajności uczenia modeli. Możesz także wybrać poszczególne hosty z listy rozwijanej Host.
Strona przeglądu wyświetla dane w następujący sposób:
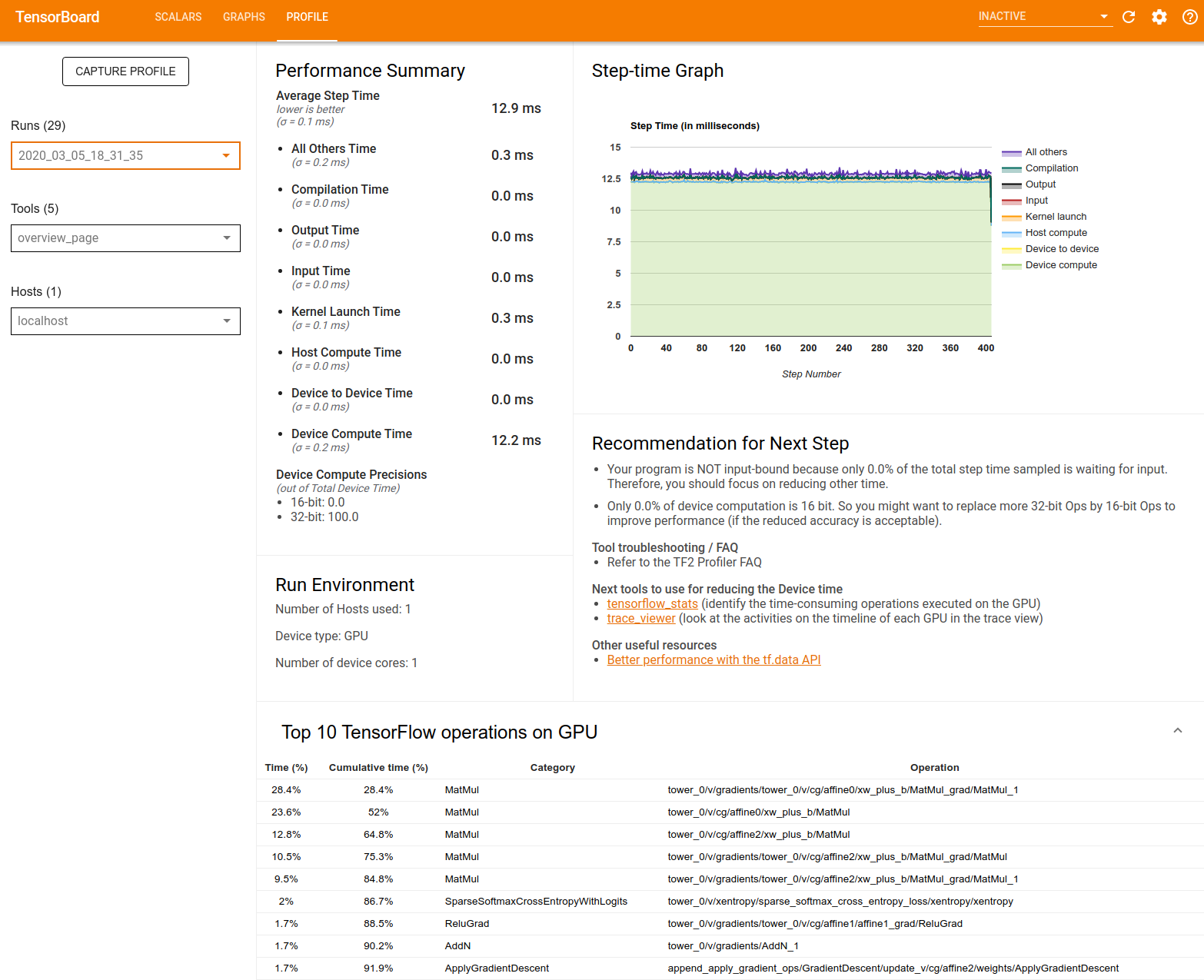
Podsumowanie wydajności : wyświetla ogólne podsumowanie wydajności modelu. Podsumowanie wyników składa się z dwóch części:
Podział czasu kroku: dzieli średni czas kroku na wiele kategorii czasu spędzanego:
- Kompilacja: Czas spędzony na kompilacji jąder.
- Wejście: Czas spędzony na czytaniu danych wejściowych.
- Dane wyjściowe: Czas spędzony na czytaniu danych wyjściowych.
- Uruchomienie jądra: Czas spędzony przez hosta na uruchomieniu jądra
- Czas obliczeń hosta..
- Czas komunikacji między urządzeniami.
- Czas obliczeń na urządzeniu.
- Wszystkie inne, łącznie z narzutem Pythona.
Precyzja obliczeń urządzenia — raportuje procent czasu obliczeń urządzenia przy użyciu obliczeń 16 i 32-bitowych.
Wykres czasu kroku : Wyświetla wykres czasu kroku urządzenia (w milisekundach) dla wszystkich próbkowanych kroków. Każdy krok jest podzielony na wiele kategorii (w różnych kolorach), na których spędzany jest czas. Czerwony obszar odpowiada części czasu, przez który urządzenia pozostawały bezczynne w oczekiwaniu na dane wejściowe od hosta. Zielony obszar pokazuje, ile czasu urządzenie faktycznie pracowało.
10 najważniejszych operacji TensorFlow na urządzeniu (np. GPU) : Wyświetla operacje na urządzeniu, które trwały najdłużej.
Każdy wiersz wyświetla czas własny operacji (jako procent czasu zajmowanego przez wszystkie operacje), czas skumulowany, kategorię i nazwę.
Środowisko uruchamiania : wyświetla ogólne podsumowanie środowiska uruchamiania modelu, w tym:
- Liczba używanych hostów.
- Typ urządzenia (GPU/TPU).
- Liczba rdzeni urządzenia.
Zalecenie dotyczące następnego kroku : raportuje, kiedy model jest powiązany z danymi wejściowymi i zaleca narzędzia, których można użyć do zlokalizowania i rozwiązania wąskich gardeł wydajności modelu.
Analizator rurociągu wejściowego
Kiedy program TensorFlow odczytuje dane z pliku, zaczyna się od góry wykresu TensorFlow w sposób potokowy. Proces odczytu jest podzielony na wiele etapów przetwarzania danych połączonych szeregowo, gdzie wynik jednego etapu jest wejściem do następnego. Ten system odczytu danych nazywany jest potokiem wejściowym .
Typowy potok odczytywania rekordów z plików składa się z następujących etapów:
- Odczyt plików.
- Wstępne przetwarzanie plików (opcjonalnie).
- Przesyłanie plików z hosta na urządzenie.
Nieefektywny potok wejściowy może poważnie spowolnić aplikację. Aplikacja jest uważana za powiązaną z danymi wejściowymi, jeśli spędza znaczną część czasu w potoku wejściowym. Skorzystaj z wniosków uzyskanych z analizatora potoku wejściowego, aby zrozumieć, gdzie potok wejściowy jest nieefektywny.
Analizator potoku wejściowego natychmiast poinformuje Cię, czy Twój program jest powiązany z danymi wejściowymi, i przeprowadzi Cię przez analizę po stronie urządzenia i hosta w celu usunięcia wąskich gardeł wydajności na dowolnym etapie potoku wejściowego.
Zapoznaj się ze wskazówkami dotyczącymi wydajności potoku wejściowego, aby zapoznać się z zalecanymi najlepszymi praktykami w celu optymalizacji potoków wejściowych danych.
Panel potoku wejściowego
Aby otworzyć analizator potoku wejściowego, wybierz opcję Profil , a następnie wybierz pozycję input_pipeline_analyzer z listy rozwijanej Narzędzia .
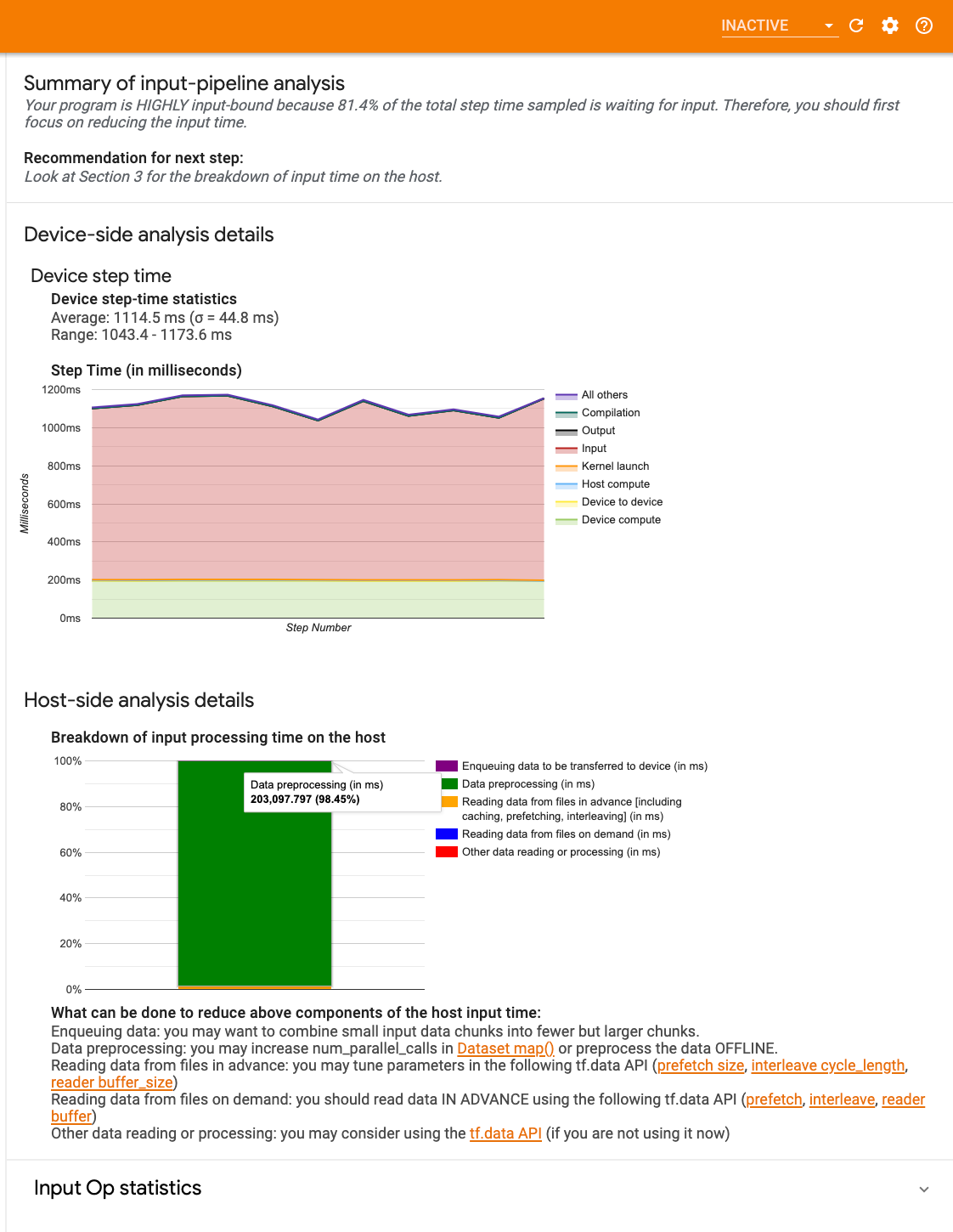
Pulpit nawigacyjny składa się z trzech sekcji:
- Podsumowanie : podsumowuje ogólny potok wejściowy z informacjami o tym, czy aplikacja jest powiązana z danymi wejściowymi, a jeśli tak, to w jakim stopniu.
- Analiza po stronie urządzenia : wyświetla szczegółowe wyniki analizy po stronie urządzenia, w tym czas kroku urządzenia i zakres czasu, jaki urządzenie spędziło na oczekiwaniu na dane wejściowe pomiędzy rdzeniami na każdym kroku.
- Analiza po stronie hosta : pokazuje szczegółową analizę po stronie hosta, w tym zestawienie czasu przetwarzania danych wejściowych na hoście.
Podsumowanie potoku wejściowego
Podsumowanie informuje, czy Twój program jest ograniczony danymi wejściowymi, prezentując procent czasu, jaki urządzenie spędziło na oczekiwaniu na dane wejściowe od hosta. Jeśli używasz standardowego potoku wejściowego, który został oprzyrządowany, narzędzie raportuje, gdzie spędzana jest większość czasu przetwarzania danych wejściowych.
Analiza po stronie urządzenia
Analiza po stronie urządzenia zapewnia wgląd w czas spędzony na urządzeniu w porównaniu z czasem spędzonym na hoście oraz ile czasu urządzenie spędziło na oczekiwaniu na dane wejściowe od hosta.
- Czas kroku wykreślony w funkcji numeru kroku : Wyświetla wykres czasu kroku urządzenia (w milisekundach) dla wszystkich próbkowanych kroków. Każdy krok jest podzielony na wiele kategorii (w różnych kolorach), na których spędzany jest czas. Czerwony obszar odpowiada części czasu, przez który urządzenia pozostawały bezczynne w oczekiwaniu na dane wejściowe od hosta. Zielony obszar pokazuje, przez ile czasu urządzenie faktycznie działało.
- Statystyka czasu kroku : Podaje średnią, odchylenie standardowe i zakres ([minimum, maksimum]) czasu kroku urządzenia.
Analiza po stronie gospodarza
Analiza po stronie hosta raportuje podział czasu przetwarzania danych wejściowych (czasu spędzonego na operacjach API tf.data ) na hoście na kilka kategorii:
- Odczyt danych z plików na żądanie : czas spędzony na czytaniu danych z plików bez buforowania, pobierania wstępnego i przeplatania.
- Odczytywanie danych z plików z wyprzedzeniem : czas spędzony na czytaniu plików, łącznie z buforowaniem, pobieraniem wstępnym i przeplataniem.
- Wstępne przetwarzanie danych : czas spędzony na operacjach wstępnego przetwarzania, takich jak dekompresja obrazu.
- Kolejkowanie danych do przesłania do urządzenia : czas spędzony na umieszczaniu danych w kolejce wejściowej przed przesłaniem danych do urządzenia.
Rozwiń opcję Statystyka operacji wejściowych , aby sprawdzić statystyki poszczególnych operacji wejściowych i ich kategorie w podziale na czas wykonania.

Przy każdym wpisie pojawi się tabela danych źródłowych zawierająca następujące informacje:
- Operacja wejściowa : pokazuje nazwę operacji TensorFlow dla operacji wejściowej.
- Liczba : Pokazuje całkowitą liczbę wystąpień wykonania operacji w okresie profilowania.
- Czas całkowity (w ms) : Pokazuje skumulowaną sumę czasu spędzonego w każdym z tych przypadków.
- Całkowity czas % : Pokazuje całkowity czas spędzony na operacji jako ułamek całkowitego czasu spędzonego na przetwarzaniu danych wejściowych.
- Całkowity czas własny (w ms) : Pokazuje skumulowaną sumę czasu własnego spędzonego w każdym z tych przypadków. Czas własny mierzy tutaj czas spędzony w ciele funkcji, z wyłączeniem czasu spędzonego w funkcji, którą wywołuje.
- Całkowity czas własny % . Pokazuje całkowity czas własny jako ułamek całkowitego czasu spędzonego na przetwarzaniu danych wejściowych.
- Kategoria . Pokazuje kategorię przetwarzania operacji wejściowej.
Statystyki TensorFlow
Narzędzie TensorFlow Stats wyświetla wydajność każdej operacji TensorFlow wykonywanej na hoście lub urządzeniu podczas sesji profilowania.
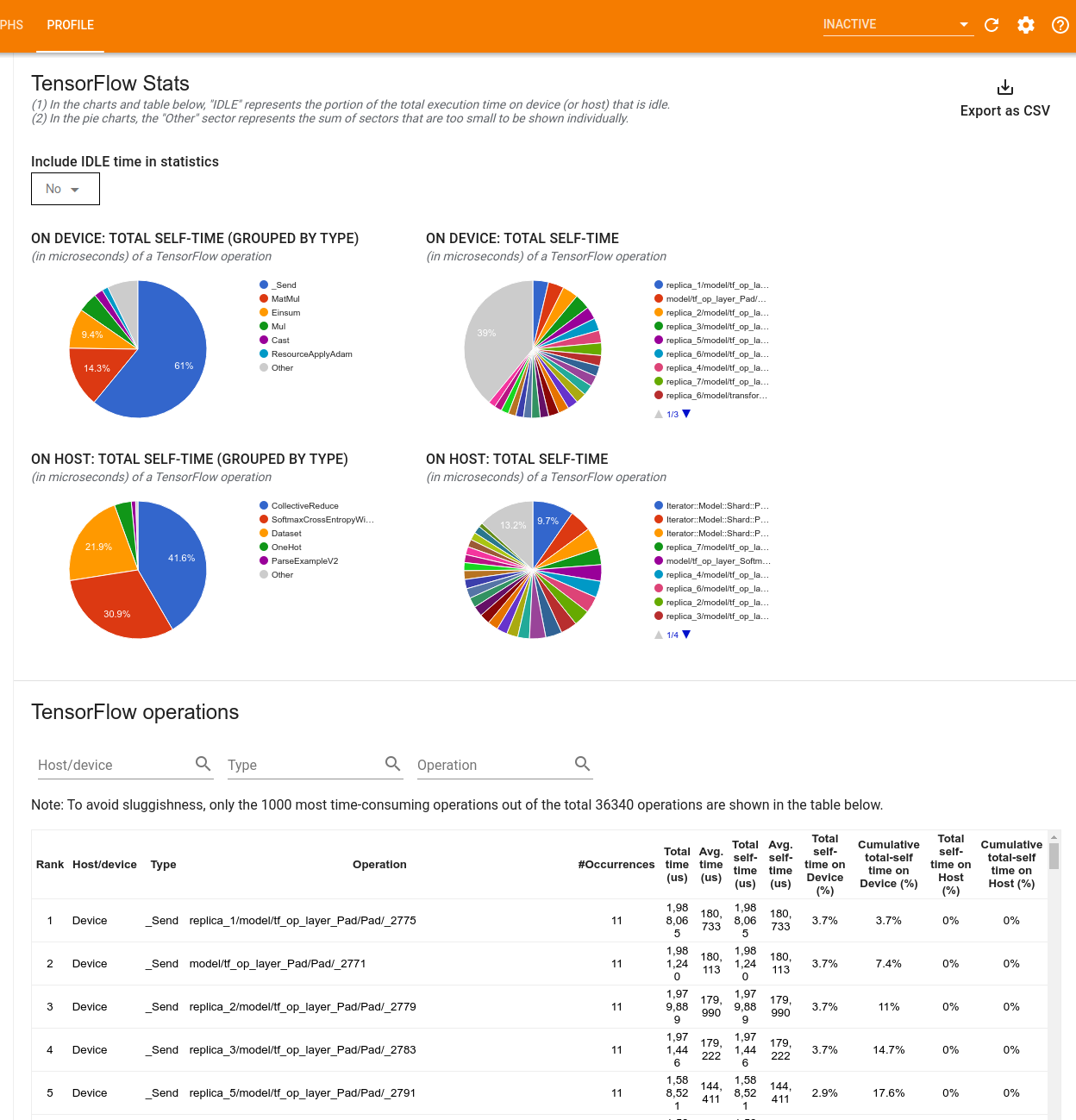
Narzędzie wyświetla informacje o wydajności w dwóch panelach:
W górnym panelu wyświetlane są maksymalnie cztery wykresy kołowe:
- Rozkład czasu samowykonania każdej operacji na hoście.
- Rozkład czasu samowykonania każdego typu operacji na hoście.
- Rozkład czasu samowykonania każdej operacji na urządzeniu.
- Rozkład czasu samowykonania każdego typu operacji na urządzeniu.
Dolny panel przedstawia tabelę, która raportuje dane dotyczące operacji TensorFlow z jednym wierszem dla każdej operacji i jedną kolumną dla każdego typu danych (sortuj kolumny, klikając nagłówek kolumny). Kliknij przycisk Eksportuj jako CSV po prawej stronie górnego panelu, aby wyeksportować dane z tej tabeli jako plik CSV.
Pamiętaj, że:
Jeśli jakiekolwiek operacje mają operacje podrzędne:
- Całkowity „skumulowany” czas operacji obejmuje czas spędzony w operacjach podrzędnych.
- Całkowity czas „własny” operacji nie obejmuje czasu spędzonego w operacjach podrzędnych.
Jeśli operacja jest wykonywana na hoście:
- Procent całkowitego czasu spędzonego na urządzeniu poniesiony przez tę opcję wyniesie 0.
- Skumulowany procent całkowitego czasu spędzonego na urządzeniu do tej operacji włącznie wyniesie 0.
Jeśli na urządzeniu wykonywana jest operacja:
- Procent całkowitego czasu poświęconego na hosta poniesionego przez tę operację będzie wynosić 0.
- Skumulowany procent całkowitego czasu spędzonego na hoście do tej operacji włącznie będzie wynosić 0.
Możesz uwzględnić lub wykluczyć czas bezczynności na wykresach kołowych i w tabeli.
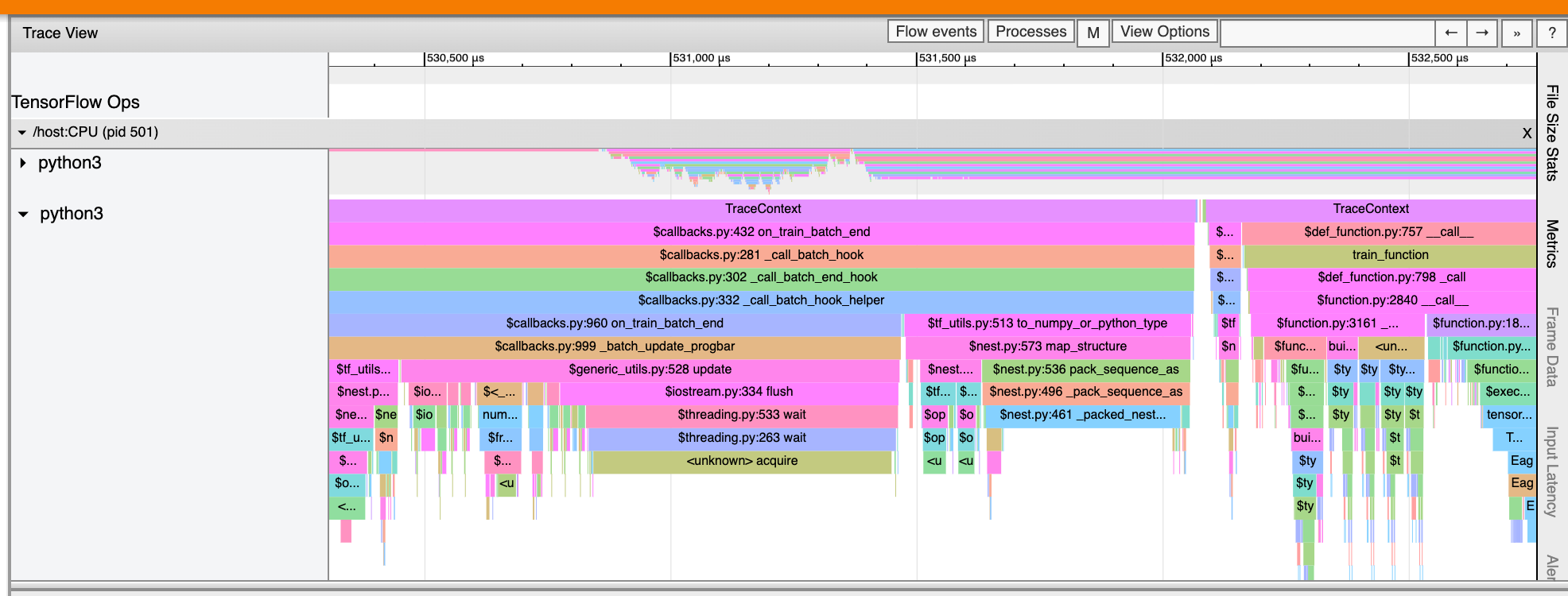
Przeglądarka śladów
Przeglądarka śledzenia wyświetla oś czasu, która pokazuje:
- Czas trwania operacji wykonanych przez Twój model TensorFlow
- Która część systemu (host lub urządzenie) wykonała op. Zazwyczaj host wykonuje operacje wejściowe, wstępnie przetwarza dane szkoleniowe i przesyła je do urządzenia, podczas gdy urządzenie wykonuje faktyczne szkolenie modelu
Przeglądarka śledzenia pozwala zidentyfikować problemy z wydajnością modelu, a następnie podjąć kroki w celu ich rozwiązania. Na przykład na wysokim poziomie można określić, czy szkolenie danych wejściowych czy modelowych zajmuje większość czasu. Analizując szczegółowo, możesz określić, które operacje trwają najdłużej. Należy pamiętać, że przeglądarka śledzenia jest ograniczona do 1 miliona zdarzeń na urządzenie.
Interfejs przeglądarki śledzenia
Po otwarciu przeglądarki śledzenia wyświetli się ostatni przebieg:
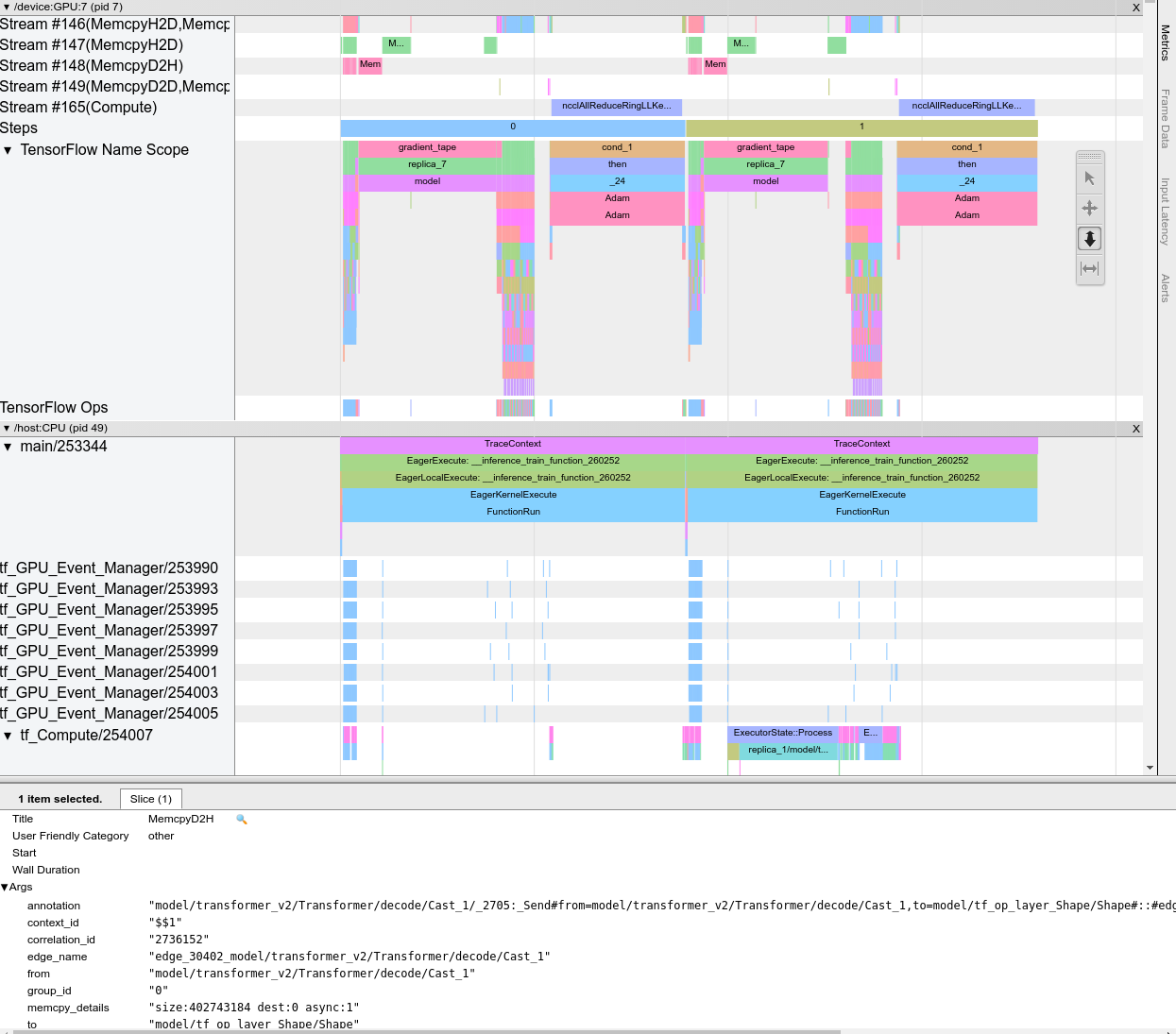
Ten ekran zawiera następujące główne elementy:
- Okienko osi czasu : pokazuje operacje, które urządzenie i host wykonywały w określonym czasie.
- Panel szczegółów : wyświetla dodatkowe informacje dotyczące operacji wybranych w panelu Oś czasu.
Panel Oś czasu zawiera następujące elementy:
- Górny pasek : zawiera różne dodatkowe elementy sterujące.
- Oś czasu : Pokazuje czas względem początku śladu.
- Etykiety sekcji i ścieżek : każda sekcja zawiera wiele ścieżek i po lewej stronie znajduje się trójkąt, który można kliknąć, aby rozwinąć lub zwinąć sekcję. Na każdy element przetwarzający w systemie przypada jedna sekcja.
- Selektor narzędzi : zawiera różne narzędzia do interakcji z przeglądarką śladów, takie jak Zoom, Panoramowanie, Zaznaczanie i Timing. Użyj narzędzia Timing, aby oznaczyć przedział czasu.
- Zdarzenia : pokazują czas wykonania operacji lub czas trwania meta-zdarzeń, takich jak kroki szkoleniowe.
Sekcje i ścieżki
Przeglądarka śledzenia zawiera następujące sekcje:
- Jedna sekcja dla każdego węzła urządzenia , oznaczona numerem chipa urządzenia i węzła urządzenia w chipie (na przykład
/device:GPU:0 (pid 0)). Każda sekcja węzła urządzenia zawiera następujące ścieżki:- Krok : Pokazuje czas trwania etapów treningu uruchomionych na urządzeniu
- TensorFlow Ops : Pokazuje operacje wykonane na urządzeniu
- Operacje XLA : Pokazuje operacje XLA , które zostały uruchomione na urządzeniu, jeśli używanym kompilatorem jest XLA (każda operacja TensorFlow jest tłumaczona na jedną lub kilka operacji XLA. Kompilator XLA tłumaczy operacje XLA na kod, który działa na urządzeniu).
- Jedna sekcja poświęcona wątkom działającym na procesorze hosta, oznaczona jako „Wątki hosta” . Sekcja zawiera jedną ścieżkę dla każdego wątku procesora. Pamiętaj, że możesz zignorować informacje wyświetlane obok etykiet sekcji.
Wydarzenia
Wydarzenia na osi czasu są wyświetlane w różnych kolorach; same kolory nie mają określonego znaczenia.
Przeglądarka śledzenia może także wyświetlać ślady wywołań funkcji Pythona w programie TensorFlow. Jeśli korzystasz z interfejsu API tf.profiler.experimental.start , możesz włączyć śledzenie języka Python, używając opcji ProfilerOptions Nametuple podczas rozpoczynania profilowania. Alternatywnie, jeśli używasz trybu próbkowania do profilowania, możesz wybrać poziom śledzenia, korzystając z opcji rozwijanych w oknie dialogowym Przechwyć profil .
Statystyki jądra GPU
To narzędzie pokazuje statystyki wydajności i początkową operację dla każdego jądra akcelerowanego przez GPU.
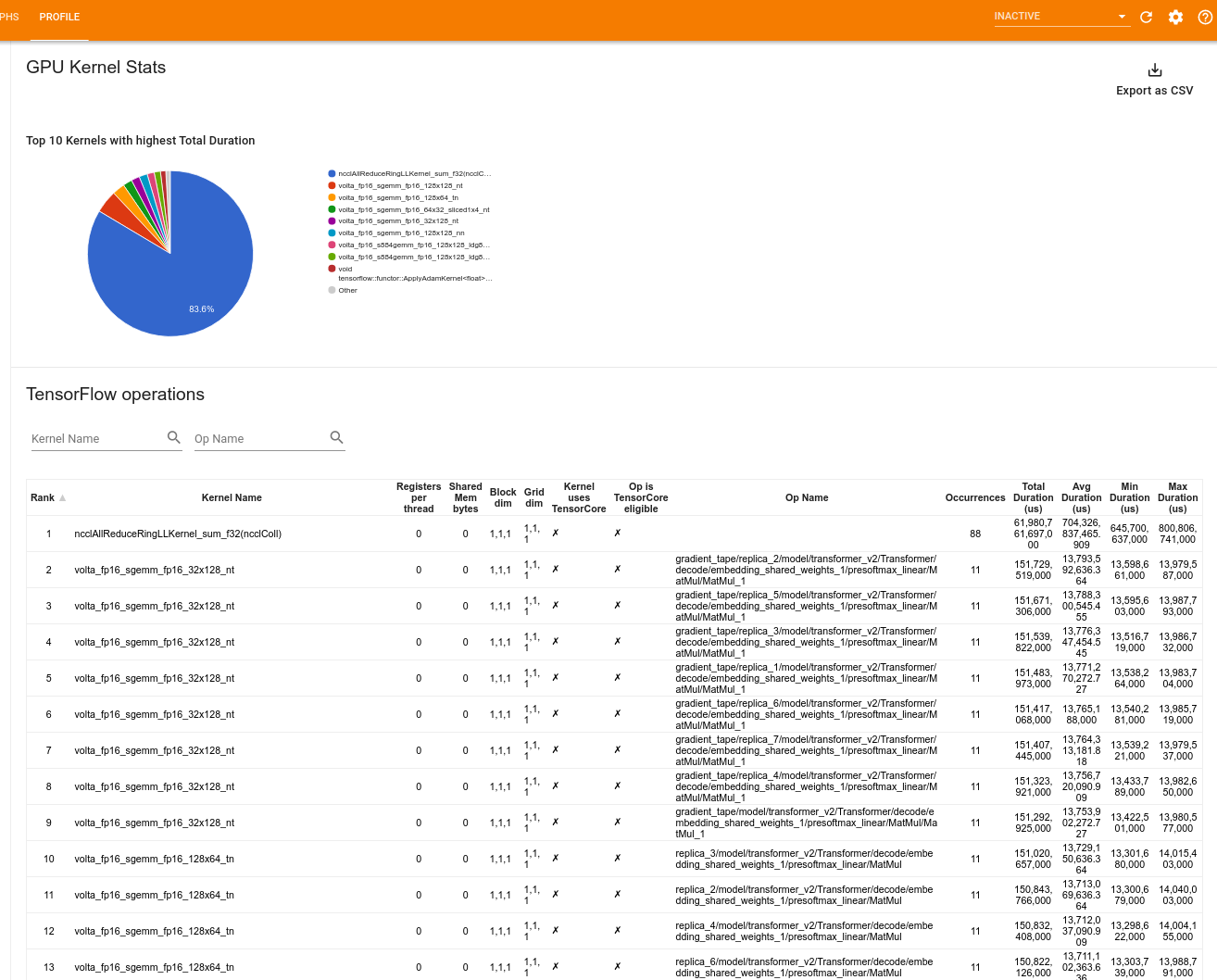
Narzędzie wyświetla informacje w dwóch panelach:
Górny panel wyświetla wykres kołowy przedstawiający jądra CUDA, które mają najwyższy łączny czas, jaki upłynął.
Dolny panel wyświetla tabelę z następującymi danymi dla każdej unikalnej pary operacji jądra:
- Ranga w kolejności malejącej całkowitego czasu trwania procesora graficznego, jaki upłynął, pogrupowana według pary operacji jądra.
- Nazwa uruchomionego jądra.
- Liczba rejestrów GPU używanych przez jądro.
- Całkowity rozmiar pamięci współdzielonej (statycznej + dynamicznej współdzielonej) używanej w bajtach.
- Wymiar bloku wyrażony jako
blockDim.x, blockDim.y, blockDim.z. - Wymiary siatki wyrażone jako
gridDim.x, gridDim.y, gridDim.z. - Określa, czy operacja kwalifikuje się do korzystania z rdzeni Tensor .
- Czy jądro zawiera instrukcje Tensor Core.
- Nazwa operacji, która uruchomiła to jądro.
- Liczba wystąpień tej pary operacji jądra.
- Całkowity czas GPU, który upłynął, w mikrosekundach.
- Średni czas pracy procesora graficznego w mikrosekundach.
- Minimalny czas GPU, który upłynął, w mikrosekundach.
- Maksymalny czas GPU w mikrosekundach, który upłynął.
Narzędzie profilu pamięci
Narzędzie Profil pamięci monitoruje wykorzystanie pamięci urządzenia w okresie profilowania. Możesz użyć tego narzędzia, aby:
- Debuguj problemy związane z brakiem pamięci (OOM), wskazując szczytowe wykorzystanie pamięci i odpowiednią alokację pamięci do operacji TensorFlow. Można także debugować problemy OOM, które mogą wystąpić po uruchomieniu wnioskowania dotyczącego wielu dzierżawców .
- Debugowanie problemów z fragmentacją pamięci.
Narzędzie profilu pamięci wyświetla dane w trzech sekcjach:
- Podsumowanie profilu pamięci
- Wykres osi czasu pamięci
- Tabela podziału pamięci
Podsumowanie profilu pamięci
W tej sekcji wyświetlane jest ogólne podsumowanie profilu pamięci programu TensorFlow, jak pokazano poniżej:
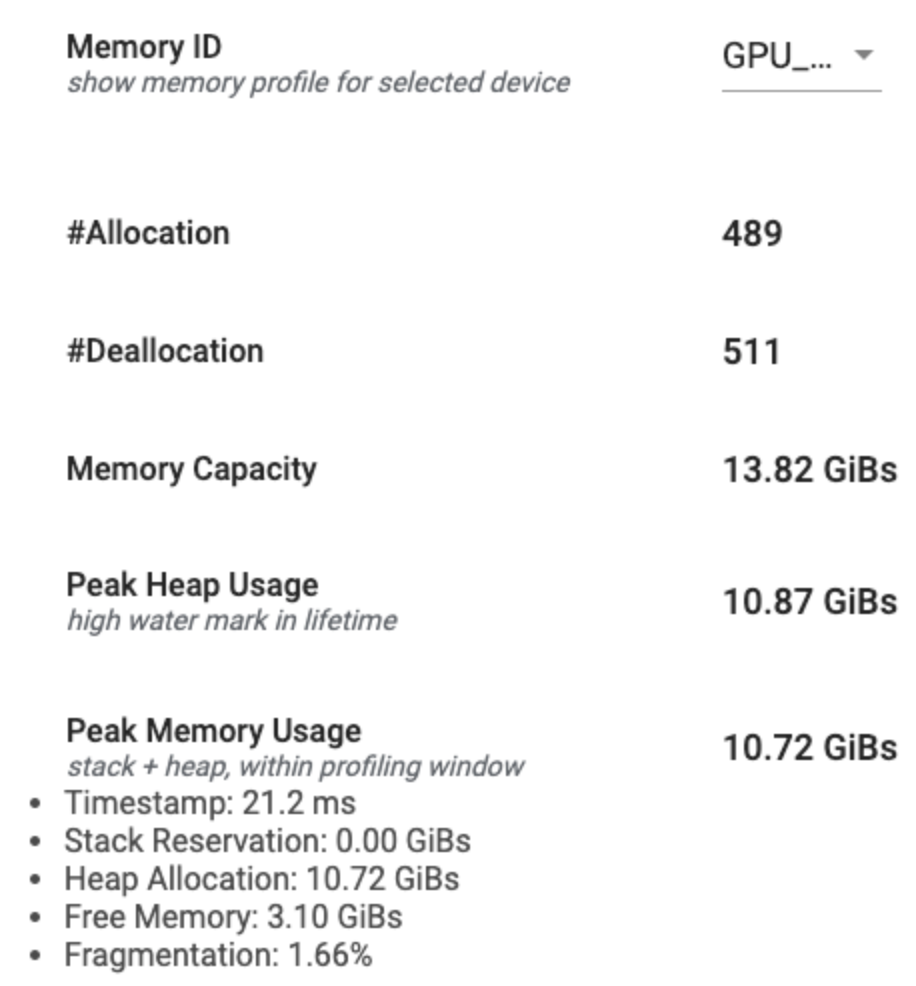
Podsumowanie profilu pamięci składa się z sześciu pól:
- Identyfikator pamięci : menu rozwijane zawierające listę wszystkich dostępnych systemów pamięci urządzenia. Z listy rozwijanej wybierz system pamięci, który chcesz wyświetlić.
- #Allocation : liczba alokacji pamięci dokonanych w interwale profilowania.
- #Deallocation : Liczba zwolnień pamięci w przedziale profilowania
- Pojemność pamięci : Całkowita pojemność (w GiB) wybranego systemu pamięci.
- Szczytowe użycie sterty : szczytowe użycie pamięci (w GiB) od momentu uruchomienia modelu.
- Szczytowe użycie pamięci : szczytowe użycie pamięci (w GiB) w interwale profilowania. To pole zawiera następujące podpola:
- Znacznik czasu : Znacznik czasu wystąpienia szczytowego użycia pamięci na wykresie osi czasu.
- Rezerwacja stosu : Ilość pamięci zarezerwowanej na stosie (w GiB).
- Alokacja sterty : Ilość pamięci przydzielonej na stercie (w GiB).
- Wolna pamięć : Ilość wolnej pamięci (w GiB). Pojemność pamięci to suma rezerwacji stosu, alokacji sterty i wolnej pamięci.
- Fragmentacja : Procent fragmentacji (im niższy, tym lepszy). Jest obliczany jako procent
(1 - Size of the largest chunk of free memory / Total free memory).
Wykres osi czasu pamięci
W tej sekcji wyświetlany jest wykres użycia pamięci (w GiB) i procent fragmentacji w funkcji czasu (w ms).
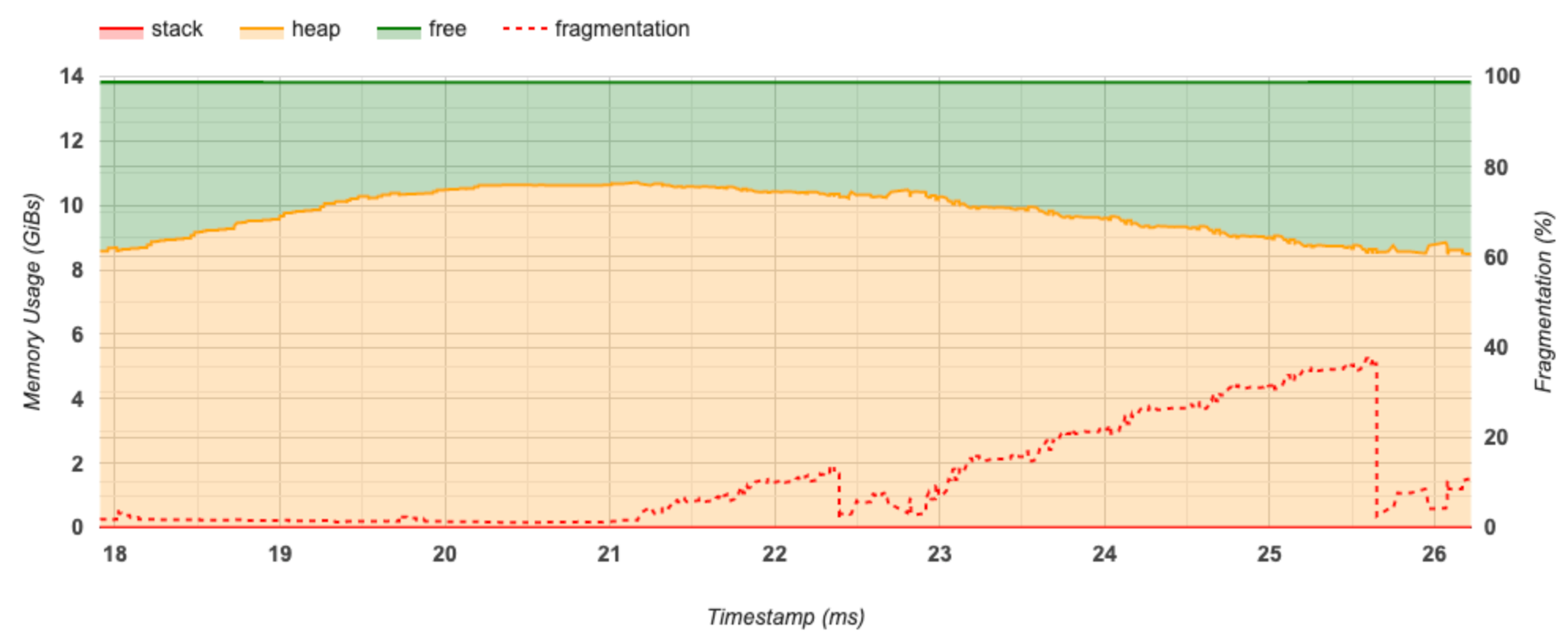
Oś X przedstawia oś czasu (w ms) interwału profilowania. Oś Y po lewej stronie przedstawia użycie pamięci (w GiB), a oś Y po prawej stronie przedstawia procent fragmentacji. W każdym momencie na osi X całkowita pamięć jest podzielona na trzy kategorie: stos (na czerwono), sterta (na pomarańczowo) i wolna (na zielono). Najedź kursorem na konkretny znacznik czasu, aby wyświetlić szczegóły dotyczące zdarzeń alokacji/delokacji pamięci w tym momencie, jak poniżej:
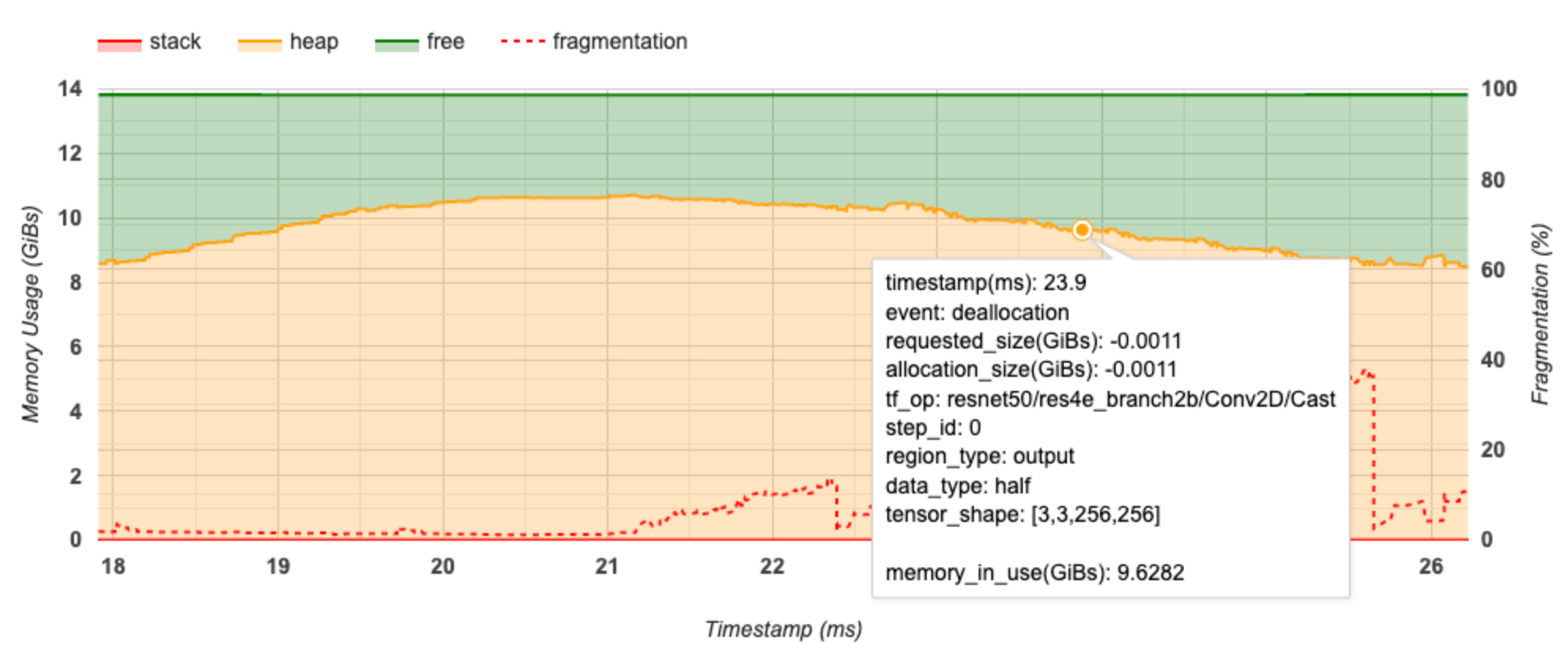
W wyskakującym oknie wyświetlane są następujące informacje:
- timestamp(ms) : Lokalizacja wybranego zdarzenia na osi czasu.
- event : Typ zdarzenia (alokacja lub dezalokacja).
- request_size(GiBs) : Żądana ilość pamięci. Będzie to liczba ujemna w przypadku zdarzeń dezalokacji.
- alokacja_size(GiBs) : Rzeczywista ilość przydzielonej pamięci. Będzie to liczba ujemna w przypadku zdarzeń dezalokacji.
- tf_op : Operacja TensorFlow, która żąda alokacji/dealokacji.
- step_id : Krok uczenia, w którym wystąpiło to zdarzenie.
- region_type : Typ jednostki danych, dla której jest przeznaczona ta przydzielona pamięć. Możliwe wartości to
tempdla elementów tymczasowych,outputdla aktywacji i gradientów orazpersist/dynamicdla wag i stałych. - data_type : Typ elementu tensora (np. uint8 dla 8-bitowej liczby całkowitej bez znaku).
- tensor_shape : Kształt alokowanego/cofywanego tensora.
- memory_in_use(GiBs) : Całkowita pamięć używana w tym momencie.
Tabela podziału pamięci
W tej tabeli przedstawiono aktywne alokacje pamięci w momencie szczytowego użycia pamięci w interwale profilowania.
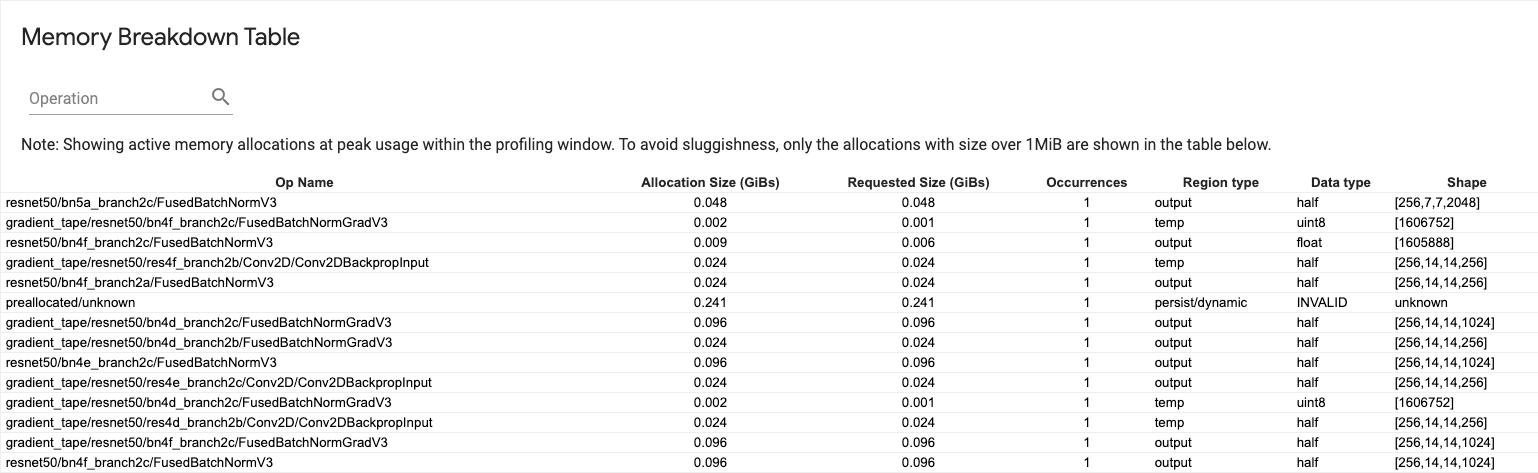
Dla każdej operacji TensorFlow istnieje jeden wiersz, a każdy wiersz zawiera następujące kolumny:
- Nazwa operacji : nazwa operacji TensorFlow.
- Rozmiar alokacji (GiB) : Całkowita ilość pamięci przydzielonej do tej operacji.
- Żądany rozmiar (GiB) : całkowita ilość pamięci żądana dla tej operacji.
- Zdarzenia : liczba alokacji dla tego op.
- Typ regionu : typ jednostki danych, dla której jest przeznaczona ta przydzielona pamięć. Możliwe wartości to
tempdla elementów tymczasowych,outputdla aktywacji i gradientów orazpersist/dynamicdla wag i stałych. - Typ danych : typ elementu tensorowego.
- Kształt : Kształt przydzielonych tensorów.
Przeglądarka podów
Narzędzie Pod Viewer pokazuje podział etapu szkolenia na wszystkich pracowników.
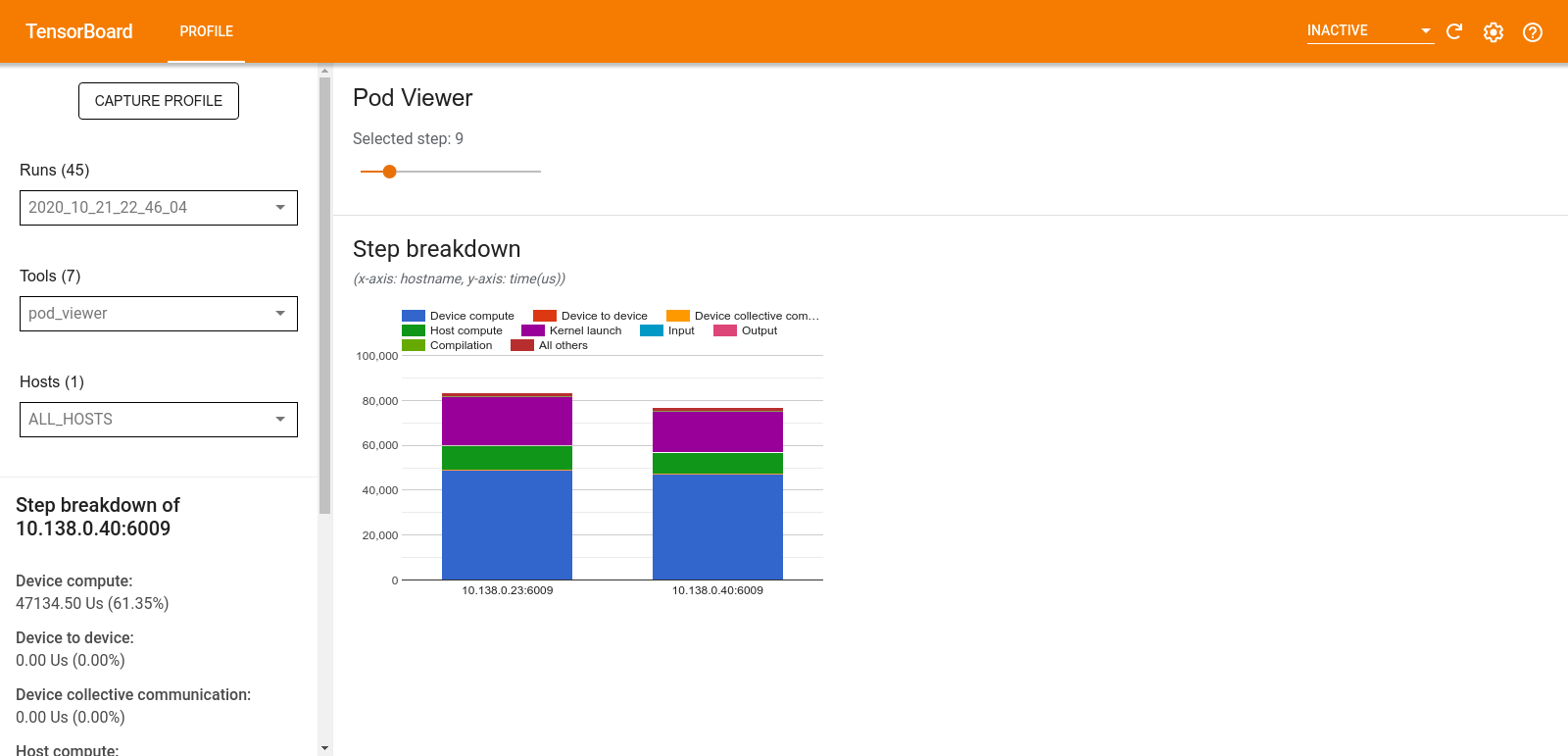
- W górnym panelu znajduje się suwak umożliwiający wybór numeru kroku.
- W dolnym okienku wyświetlany jest skumulowany wykres kolumnowy. Jest to ogólny widok podzielonych kategorii czasu kroku, umieszczonych jedna na drugiej. Każda ułożona kolumna reprezentuje unikalnego pracownika.
- Po najechaniu kursorem na skumulowaną kolumnę karta po lewej stronie pokazuje więcej szczegółów na temat podziału kroków.
analiza wąskiego gardła tf.data
Narzędzie do analizy wąskich gardeł tf.data automatycznie wykrywa wąskie gardła w potokach wejściowych tf.data w Twoim programie i dostarcza rekomendacje, jak je naprawić. Działa z każdym programem korzystającym z tf.data niezależnie od platformy (CPU/GPU/TPU). Na podstawie tego przewodnika opierają się jego analizy i zalecenia.
Wykrywa wąskie gardło, wykonując następujące kroki:
- Znajdź hosta z największymi ograniczeniami wejściowymi.
- Znajdź najwolniejsze wykonanie potoku wejściowego
tf.data. - Zrekonstruuj wykres potoku wejściowego na podstawie śledzenia profilera.
- Znajdź ścieżkę krytyczną na wykresie potoku wejściowego.
- Zidentyfikuj najwolniejszą transformację na ścieżce krytycznej jako wąskie gardło.
Interfejs użytkownika jest podzielony na trzy sekcje: Podsumowanie analizy wydajności , Podsumowanie wszystkich potoków wejściowych i Wykres potoków wejściowych .
Podsumowanie analizy wydajności

W tej części znajduje się podsumowanie analizy. Raportuje o wolnych potokach wejściowych tf.data wykrytych w profilu. W tej sekcji przedstawiono także hosta z największymi ograniczeniami wejściowymi i jego najwolniejszy potok wejściowy z maksymalnym opóźnieniem. Co najważniejsze, identyfikuje, która część rurociągu wejściowego stanowi wąskie gardło i jak to naprawić. Informacje o wąskim gardle są dostarczane wraz z typem iteratora i jego długą nazwą.
Jak odczytać długą nazwę iteratora tf.data
Długa nazwa jest formatowana jako Iterator::<Dataset_1>::...::<Dataset_n> . W długiej nazwie <Dataset_n> odpowiada typowi iteratora, a pozostałe zestawy danych w długiej nazwie reprezentują dalsze transformacje.
Rozważmy na przykład następujący zestaw danych potoku wejściowego:
dataset = tf.data.Dataset.range(10).map(lambda x: x).repeat(2).batch(5)
Długie nazwy iteratorów z powyższego zbioru danych będą następujące:
| Typ iteratora | Długie imię |
|---|---|
| Zakres | Iterator::Batch::Repeat::Map::Zakres |
| Mapa | Iterator::Batch::Repeat::Map |
| Powtarzać | Iterator::Batch::Powtórz |
| Seria | Iterator::Wsad |
Podsumowanie wszystkich potoków wejściowych
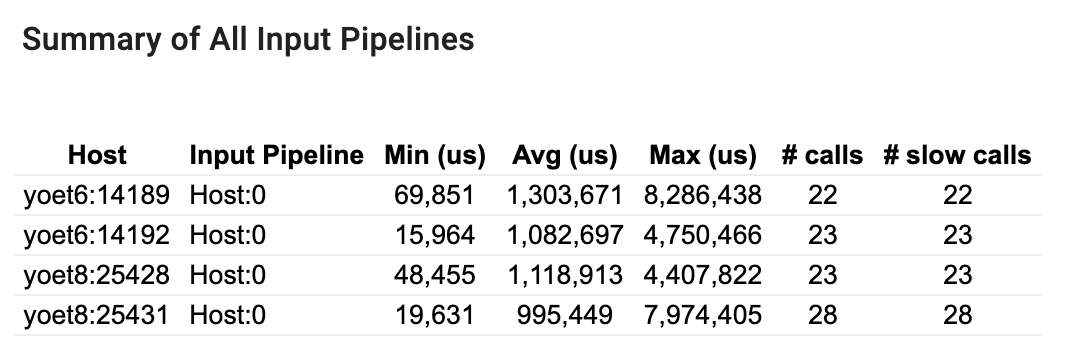
Ta sekcja zawiera podsumowanie wszystkich potoków wejściowych na wszystkich hostach. Zazwyczaj istnieje jeden potok wejściowy. W przypadku stosowania strategii dystrybucji jeden potok wejściowy hosta uruchamia kod tf.data programu oraz wiele potoków wejściowych urządzeń pobierających dane z potoku wejściowego hosta i przesyłających je do urządzeń.
Dla każdego potoku wejściowego pokazuje statystyki czasu jego wykonania. Połączenie jest liczone jako wolne, jeśli trwa dłużej niż 50 μs.
Wykres potoku wejściowego

W tej sekcji przedstawiono wykres potoku wejściowego z informacjami o czasie wykonania. Możesz użyć „Host” i „Potok wejściowy”, aby wybrać, który host i potok wejściowy mają być widoczne. Wykonania potoku wejściowego są sortowane według czasu wykonania w kolejności malejącej, którą można wybrać za pomocą listy rozwijanej Ranga .
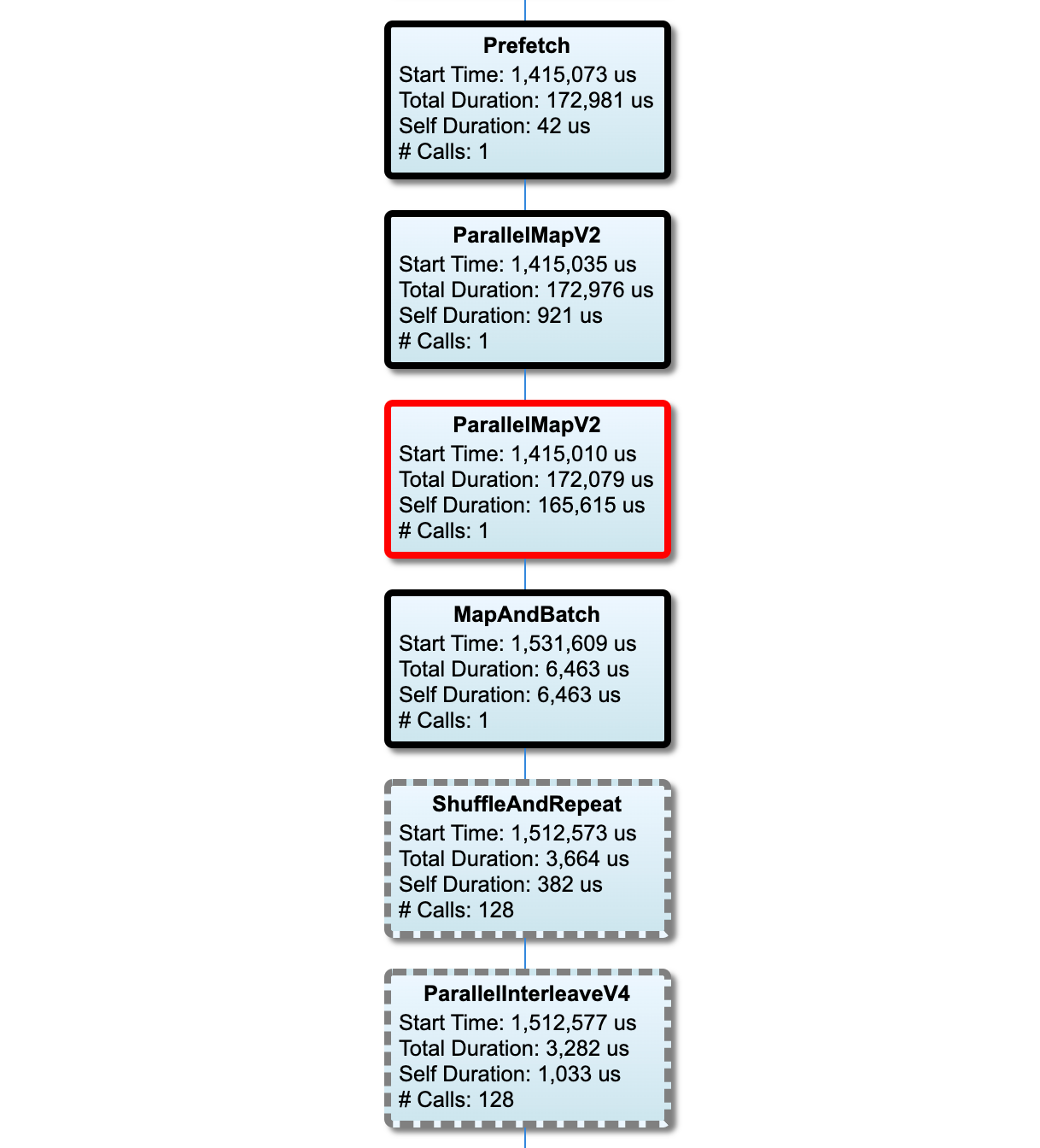
Węzły na ścieżce krytycznej mają pogrubione kontury. Węzeł wąskiego gardła, czyli węzeł o najdłuższym czasie trwania na ścieżce krytycznej, jest oznaczony czerwonym konturem. Pozostałe niekrytyczne węzły mają szare, przerywane kontury.
W każdym węźle Czas rozpoczęcia wskazuje czas rozpoczęcia wykonania. Ten sam węzeł może zostać wykonany wiele razy, na przykład, jeśli w potoku wejściowym znajduje się Batch . Jeśli jest wykonywane wielokrotnie, jest to czas rozpoczęcia pierwszego wykonania.
Całkowity czas trwania to czas ściany wykonania. Jeśli jest wykonywany wielokrotnie, jest to suma czasów ścian wszystkich wykonań.
Czas własny to czas całkowity bez nakładającego się czasu z jego bezpośrednimi węzłami podrzędnymi.
„# wywołań” to liczba wykonań potoku wejściowego.
Zbieraj dane dotyczące wydajności
TensorFlow Profiler zbiera działania hosta i ślady GPU Twojego modelu TensorFlow. Profiler można skonfigurować tak, aby zbierał dane dotyczące wydajności w trybie programistycznym lub w trybie próbkowania.
Profilowanie interfejsów API
Do profilowania można używać następujących interfejsów API.
Tryb programowy wykorzystujący wywołanie zwrotne Keras TensorBoard (
tf.keras.callbacks.TensorBoard)# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])Tryb programowy przy użyciu interfejsu API funkcji
tf.profilertf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()Tryb programowy z wykorzystaniem menedżera kontekstu
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
Tryb próbkowania: wykonaj profilowanie na żądanie, używając
tf.profiler.experimental.server.startdo uruchomienia serwera gRPC z uruchomionym modelem TensorFlow. Po uruchomieniu serwera gRPC i uruchomieniu modelu możesz przechwycić profil za pomocą przycisku Przechwyć profil we wtyczce profilu TensorBoard. Użyj skryptu w powyższej sekcji Instalowanie profilera, aby uruchomić instancję TensorBoard, jeśli nie jest ona jeszcze uruchomiona.Jako przykład,
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)Przykład profilowania wielu pracowników:
# E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)
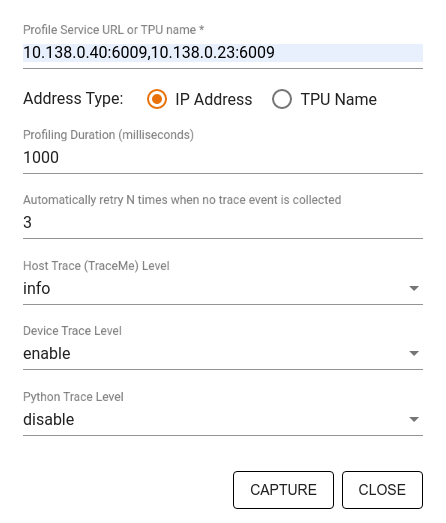
Użyj okna dialogowego Przechwyć profil, aby określić:
- Rozdzielana przecinkami lista adresów URL usług profili lub nazw TPU.
- Czas trwania profilowania.
- Poziom śledzenia wywołań urządzeń, hostów i funkcji języka Python.
- Ile razy chcesz, aby Profiler ponawiał próby przechwytywania profili, jeśli początkowo nie powiodło się.
Profilowanie niestandardowych pętli treningowych
Aby profilować niestandardowe pętle szkoleniowe w kodzie TensorFlow, oprzyrząduj pętlę treningową za pomocą interfejsu API tf.profiler.experimental.Trace , aby oznaczyć granice kroków dla Profilera.
Argument name jest używany jako przedrostek nazw kroków, argument słowa kluczowego step_num jest dołączany do nazw kroków, a argument słowa kluczowego _r powoduje, że to zdarzenie śledzenia jest przetwarzane jako zdarzenie kroku przez Profiler.
Jako przykład,
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
Umożliwi to analizę wydajności opartą na krokach przez Profiler i spowoduje wyświetlenie zdarzeń kroków w przeglądarce śledzenia.
Upewnij się, że iterator zestawu danych został uwzględniony w kontekście tf.profiler.experimental.Trace w celu dokładnej analizy potoku wejściowego.
Poniższy fragment kodu jest antywzorem:
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
Profilowanie przypadków użycia
Profiler obejmuje wiele przypadków użycia na czterech różnych osiach. Niektóre kombinacje są obecnie obsługiwane, inne zostaną dodane w przyszłości. Oto niektóre przypadki użycia:
- Profilowanie lokalne a profilowanie zdalne : są to dwa popularne sposoby konfigurowania środowiska profilowania. W przypadku profilowania lokalnego interfejs API profilowania jest wywoływany na tej samej maszynie, na której wykonuje Twój model, na przykład na lokalnej stacji roboczej z procesorami graficznymi. W przypadku zdalnego profilowania interfejs API profilowania jest wywoływany na innej maszynie, na której działa Twój model, na przykład na Cloud TPU.
- Profilowanie wielu pracowników : możesz profilować wiele maszyn, korzystając z możliwości rozproszonego szkolenia TensorFlow.
- Platforma sprzętowa : procesory profilowe, procesory graficzne i TPU.
Poniższa tabela zawiera krótki przegląd wspomnianych powyżej przypadków użycia obsługiwanych przez TensorFlow:
| Profilowanie API | Lokalny | Zdalny | Wielu pracowników | Platformy sprzętowe |
|---|---|---|---|---|
| Wywołanie zwrotne TensorBoard Keras | Utrzymany | Nieobsługiwane | Nieobsługiwane | Procesor, karta graficzna |
tf.profiler.experimental API uruchamiania/zatrzymywania | Utrzymany | Nieobsługiwane | Nieobsługiwane | Procesor, karta graficzna |
tf.profiler.experimental interfejs API klienta.trace | Utrzymany | Utrzymany | Utrzymany | Procesor, karta graficzna, TPU |
| API menedżera kontekstu | Utrzymany | Nieobsługiwane | Nieobsługiwane | Procesor, karta graficzna |
Najlepsze praktyki dotyczące optymalnej wydajności modelu
Aby osiągnąć optymalną wydajność, skorzystaj z poniższych zaleceń mających zastosowanie do modeli TensorFlow.
Ogólnie rzecz biorąc, wykonaj wszystkie transformacje na urządzeniu i upewnij się, że korzystasz z najnowszej kompatybilnej wersji bibliotek, takich jak cuDNN i Intel MKL dla swojej platformy.
Zoptymalizuj potok danych wejściowych
Użyj danych z [#input_pipeline_analyzer], aby zoptymalizować potok wprowadzania danych. Wydajny potok wprowadzania danych może radykalnie poprawić szybkość wykonywania modelu, skracając czas bezczynności urządzenia. Spróbuj zastosować najlepsze praktyki opisane w przewodniku Lepsza wydajność dzięki przewodnikowi po interfejsie API tf.data i poniżej, aby zwiększyć wydajność potoku wprowadzania danych.
Ogólnie rzecz biorąc, równoległe wykonywanie wszelkich operacji, które nie muszą być wykonywane sekwencyjnie, może znacznie zoptymalizować potok wprowadzania danych.
W wielu przypadkach pomaga zmiana kolejności niektórych wywołań lub dostrojenie argumentów w taki sposób, aby działało najlepiej dla Twojego modelu. Optymalizując potok danych wejściowych, przeprowadź test porównawczy tylko modułu ładującego dane bez etapów uczenia i propagacji wstecznej, aby niezależnie ocenić ilościowo wpływ optymalizacji.
Spróbuj uruchomić model z danymi syntetycznymi, aby sprawdzić, czy potok wejściowy nie stanowi wąskiego gardła wydajności.
Użyj
tf.data.Dataset.sharddo szkolenia z wieloma procesorami graficznymi. Upewnij się, że fragmentujesz bardzo wcześnie w pętli wejściowej, aby zapobiec zmniejszeniu przepustowości. Podczas pracy z TFRecords upewnij się, że podzieliłeś listę TFRecords, a nie zawartość TFRecords.Zrównoleglanie kilku operacji poprzez dynamiczne ustawienie wartości
num_parallel_callsza pomocątf.data.AUTOTUNE.Rozważ ograniczenie użycia
tf.data.Dataset.from_generator, ponieważ jest on wolniejszy w porównaniu do czystych operacji TensorFlow.Rozważ ograniczenie użycia funkcji
tf.py_function, ponieważ nie można jej serializować i nie można jej uruchamiać w rozproszonym TensorFlow.Użyj
tf.data.Options, aby kontrolować optymalizacje statyczne potoku wejściowego.
Przeczytaj także przewodnik dotyczący analizy wydajności tf.data , aby uzyskać więcej wskazówek na temat optymalizacji potoku wejściowego.
Zoptymalizuj powiększanie danych
Pracując z danymi obrazu, zwiększ efektywność powiększania danych , rzutując na różne typy danych po zastosowaniu przekształceń przestrzennych, takich jak odwracanie, kadrowanie, obracanie itp.
Użyj NVIDIA® DALI
W niektórych przypadkach, na przykład gdy masz system z wysokim stosunkiem GPU do procesora, wszystkie powyższe optymalizacje mogą nie wystarczyć, aby wyeliminować wąskie gardła w ładowaczu danych spowodowane ograniczeniami cykli procesora.
Jeśli używasz procesorów graficznych NVIDIA® do zastosowań związanych z wizją komputerową i głębokim uczeniem się dźwięku, rozważ użycie biblioteki ładowania danych ( DALI ) w celu przyspieszenia potoku danych.
Sprawdź dokumentację NVIDIA® DALI: Operations, aby uzyskać listę obsługiwanych operacji DALI.
Użyj wątków i wykonywania równoległego
Uruchamiaj operacje na wielu wątkach procesora za pomocą interfejsu API tf.config.threading aby wykonywać je szybciej.
TensorFlow automatycznie ustawia domyślnie liczbę wątków równoległości. Pula wątków dostępna do uruchamiania operacji TensorFlow zależy od liczby dostępnych wątków procesora.
Kontroluj maksymalne przyspieszenie równoległe dla pojedynczej operacji, używając tf.config.threading.set_intra_op_parallelism_threads . Pamiętaj, że jeśli uruchomisz wiele operacji równolegle, wszystkie będą dzielić dostępną pulę wątków.
Jeśli masz niezależne, nieblokujące operacje (operacje bez skierowanej ścieżki między nimi na wykresie), użyj tf.config.threading.set_inter_op_parallelism_threads aby uruchomić je jednocześnie, korzystając z dostępnej puli wątków.
Różnorodny
Pracując z mniejszymi modelami na procesorach graficznych NVIDIA®, możesz ustawić tf.compat.v1.ConfigProto.force_gpu_compatible=True aby wymusić alokację wszystkich tensorów procesora z pamięcią przypiętą CUDA, co znacznie zwiększy wydajność modelu. Należy jednak zachować ostrożność podczas korzystania z tej opcji w przypadku nieznanych/bardzo dużych modeli, ponieważ może to mieć negatywny wpływ na wydajność hosta (CPU).
Popraw wydajność urządzenia
Postępuj zgodnie z najlepszymi praktykami opisanymi tutaj oraz w przewodniku optymalizacji wydajności GPU, aby zoptymalizować wydajność modelu TensorFlow na urządzeniu.
Jeśli używasz procesorów graficznych NVIDIA, zarejestruj wykorzystanie procesora graficznego i pamięci w pliku CSV, uruchamiając:
nvidia-smi
--query-gpu=utilization.gpu,utilization.memory,memory.total,
memory.free,memory.used --format=csv
Skonfiguruj układ danych
Podczas pracy z danymi zawierającymi informacje o kanałach (np. obrazami) zoptymalizuj format układu danych, aby preferować kanały na końcu (NHWC zamiast NCHW).
Formaty danych ostatniego kanału poprawiają wykorzystanie Tensor Core i zapewniają znaczną poprawę wydajności, szczególnie w modelach splotowych w połączeniu z AMP. Układy danych NCHW mogą być nadal obsługiwane przez rdzenie Tensor, ale powodują dodatkowe obciążenie ze względu na operacje automatycznej transpozycji.
Możesz zoptymalizować układ danych, aby preferować układy NHWC, ustawiając data_format="channels_last" dla warstw takich jak tf.keras.layers.Conv2D , tf.keras.layers.Conv3D i tf.keras.layers.RandomRotation .
Użyj tf.keras.backend.set_image_data_format , aby ustawić domyślny format układu danych dla interfejsu API zaplecza Keras.
Maksymalnie wykorzystaj pamięć podręczną L2
Podczas pracy z procesorami graficznymi NVIDIA® wykonaj poniższy fragment kodu przed pętlą treningową, aby zwiększyć szczegółowość pobierania L2 do 128 bajtów.
import ctypes
_libcudart = ctypes.CDLL('libcudart.so')
# Set device limit on the current device
# cudaLimitMaxL2FetchGranularity = 0x05
pValue = ctypes.cast((ctypes.c_int*1)(), ctypes.POINTER(ctypes.c_int))
_libcudart.cudaDeviceSetLimit(ctypes.c_int(0x05), ctypes.c_int(128))
_libcudart.cudaDeviceGetLimit(pValue, ctypes.c_int(0x05))
assert pValue.contents.value == 128
Skonfiguruj użycie wątku GPU
Tryb wątku GPU decyduje o sposobie wykorzystania wątków GPU.
Ustaw tryb wątku na gpu_private , aby upewnić się, że wstępne przetwarzanie nie kradnie wszystkich wątków GPU. Spowoduje to zmniejszenie opóźnienia premiery jądra podczas szkolenia. Możesz także ustawić liczbę wątków na GPU. Ustaw te wartości za pomocą zmiennych środowiskowych.
import os
os.environ['TF_GPU_THREAD_MODE']='gpu_private'
os.environ['TF_GPU_THREAD_COUNT']='1'
Skonfiguruj opcje pamięci GPU
Zasadniczo zwiększ rozmiar partii i skaluj model, aby lepiej wykorzystać GPU i uzyskać wyższą przepustowość. Należy zauważyć, że zwiększenie wielkości partii zmieni dokładność modelu, więc model musi zostać skalowany poprzez strojenie hiperparametrów, takich jak wskaźnik uczenia się, aby osiągnąć dokładność docelową.
Użyj również tf.config.experimental.set_memory_growth , aby umożliwić rozwój pamięci GPU, aby zapobiec pełnemu przydzieleniu całej pamięci dostępnej do operacji wymagających jedynie ułamka pamięci. Umożliwia to inne procesy, które zużywają pamięć GPU uruchamiać się na tym samym urządzeniu.
Aby dowiedzieć się więcej, sprawdź ograniczające wytyczne dotyczące wzrostu pamięci GPU w przewodniku GPU, aby dowiedzieć się więcej.
Różnorodny
Zwiększ trening mini wielkości partii (liczba próbek treningowych używanych na urządzenie w jednej iteracji pętli treningowej) do maksymalnej ilości, która pasuje bez błędu poza pamięcią (OOM) na GPU. Zwiększenie wielkości partii wpływa na dokładność modelu - więc upewnij się, że skalujesz model, dostrajając hiperparametry w celu osiągnięcia dokładności docelowej.
Wyłącz błędy raportowania OOM podczas alokacji tensorów w kodzie produkcyjnym. Ustaw
report_tensor_allocations_upon_oom=Falsewtf.compat.v1.RunOptions.W przypadku modeli z warstwami splotu usuń dodawanie uprzedzeń, jeśli przy użyciu normalizacji partii. Normalizacja partii przesuwa wartości ze względu na ich średnią, co usuwa potrzebę ciągłego terminu odchylenia.
Użyj statystyk TF, aby dowiedzieć się, jak skutecznie działają OPS na urządzeniu.
Użyj
tf.functiondo wykonywania obliczeń i opcjonalnie, włącz flagęjit_compile=True(tf.function(jit_compile=True). Aby dowiedzieć się więcej, idź używać xla tf.function .Minimalizuj operacje hosta Pythona między krokami i zmniejsz zwrot zwrotny. Oblicz wskaźniki co kilka kroków zamiast na każdym kroku.
Utrzymuj jednostki obliczeniowe urządzenia.
Wysyłaj dane do wielu urządzeń równolegle.
Rozważ stosowanie 16-bitowych reprezentacji numerycznych , takich jak
fp16-format zmiennoprzecinkowy w połowie precyzyjny określony przez IEEE-lub format pływającego mózgu BFLOAT16 .
Dodatkowe zasoby
- TENSORFLOW PROFILER: Samouczek wydajności modelu profilu z rogami i Tensorboard, w którym można zastosować porady w tym przewodniku.
- Profilowanie wydajności w Tensorflow 2 rozmawiają z Tensorflow Dev Summit 2020.
- Demo Profilera Tensorflow z szczytu Tensorflow Dev 2020.
Znane ograniczenia
Profilowanie wielu GPU na tensorflow 2.2 i Tensorflow 2.3
Tensorflow 2.2 i 2.3 obsługują wiele profilowania GPU tylko dla systemów pojedynczych hostów; Nie jest obsługiwane wiele profilowania GPU dla systemów wielu osób. Aby profilować konfiguracje GPU z wieloma pracownikami, każdy pracownik musi być profilowany niezależnie. Z Tensorflow 2.4 Wielu pracowników można profilować za pomocą tf.profiler.experimental.client.trace API.
Toolkit CUDA® 10.2 lub nowszy jest wymagany do profilowania wielu GPU. Jako wersje TensorFlow 2.2 i 2.3 Obsługują wersje narzędzi CUDA® tylko do 10.1, musisz utworzyć symboliczne linki do libcudart.so.10.1 i libcupti.so.10.1 :
sudo ln -s /usr/local/cuda/lib64/libcudart.so.10.2 /usr/local/cuda/lib64/libcudart.so.10.1
sudo ln -s /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.2 /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.1