
このガイドでは、TensorFlow Profiler で提供されているツールを使用して、TensorFlow モデルのパフォーマンスを追跡する方法を説明します。また、ホスト(CPU)、デバイス(GPU)、またはホストとデバイスの両方の組み合わせでモデルがどのように機能するかを確認します。
プロファイリングは、モデル内のさまざまな TensorFlow 演算(op)によるハードウェアリソース消費(時間とメモリ)を把握し、パフォーマンスのボトルネックを解消して最終的にモデルの実行を高速化するのに役立ちます。
このガイドでは、プロファイラのインストール方法、利用可能なさまざまなツール、プロファイラのさまざまなパフォーマンスデータ収集モード、およびモデルのパフォーマンスを最適化するために推奨されるベストプラクティスについて説明します。
Cloud TPU 上でモデルのパフォーマンスをプロファイリングする場合は、 Cloud TPU のガイドをご覧ください。
プロファイラのインストールと GPU の要件
TensorBoard 用の Profiler プラグインを pip でインストールします。プロファイラには、最新バージョンの TensorFlow と TensorBoard(2.2 以上)が必要です。
pip install -U tensorboard_plugin_profile
GPU 上でプロファイリングを実行するには、次の手順を行う必要があります。
TensorFlow GPU サポートソフトウェアの要件に記載されている NVIDIA® GPU ドライバーと CUDA® Toolkit の要件を満たします。
パスに NVIDIA® CUDA® Profiling Tools Interface(CUPTI)が存在することを確認します。
/sbin/ldconfig -N -v $(sed 's/:/ /g' <<< $LD_LIBRARY_PATH) | \ grep libcupti
パスに CUPTI が存在しない場合は、次のコマンドを実行してインストールディレクトリを $LD_LIBRARY_PATH 環境変数の前に追加します。
export LD_LIBRARY_PATH=/usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
次に、上記の ldconfig コマンドを再度実行し、CUPTI ライブラリが検出されたことを確認してください。
特権の問題を解消する
Docker 環境または Linux で CUDA® Toolkit を使用してプロファイリングを実行する場合、CUPTI 権限の不足に関する問題(CUPTI_ERROR_INSUFFICIENT_PRIVILEGES)が発生する場合があります。Linux でこの問題を解消する方法については、NVIDIA 開発者ドキュメント をご覧ください。
Docker 環境で CUPTI 特権の問題を解消するには、以下を実行してください。
docker run option '--privileged=true'
プロファイラツール
プロファイラには、一部のモデルデータをキャプチャした後にのみ表示される TensorBoard の Profile タブからアクセスできます。
注意: プロファイラは Google Chart ライブラリを読み込むため、インターネットアクセスを要求します。TensorBoard をローカルマシン上、企業内ファイアウォールの背後、またはデータセンターで完全にオフラインで実行する場合、一部のチャートやテーブルが表示されない場合があります。
プロファイラには、次のようなパフォーマンス分析に役立つツールが含まれています。
- 概要ページ
- 入力パイプライン分析ツール
- TensorFlow 統計
- トレースビューア
- GPU カーネル統計
- メモリプロファイルツール
- Pod ビューア
概要ページ
概要ページでは、プロファイリングを実行中にモデルがどのように動作したかが一番上に表示されます。このページには、ホストとすべてのデバイスの概要を集約したページと、モデルのトレーニングパフォーマンスを改善するためのいくつかの推奨事項が表示されます。Host ドロップダウンで個々のホストを選択することもできます。
概要ページには、次のようにデータが表示されます。
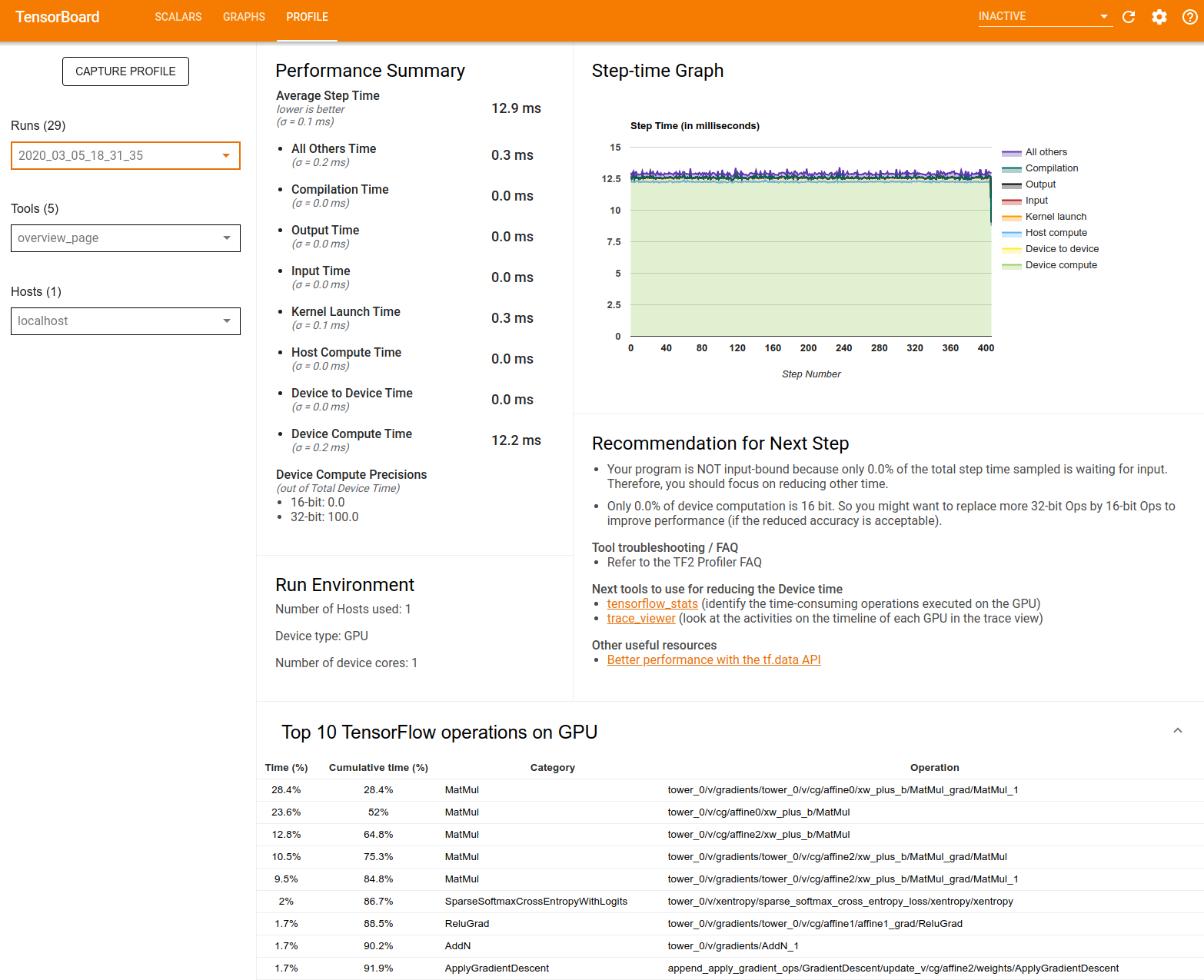
パフォーマンスの概要: モデルのパフォーマンスの概要が表示されます。パフォーマンスの概要は、次の 2 つの部分に分かれています。
ステップ時間の内訳: 平均ステップ時間を、時間を消費した場所に応じて複数のカテゴリに分類しています。
- Compilation: カーネルのコンパイルに費やされた時間
- Input: 入力データの読み取りに費やされた時間
- Output: 出力データの読み取りに費やされた時間
- Kernel launch: ホストがカーネルを起動するのに費やした時間
- Host Compute Time: ホストの計算時間
- Device to Device Time: デバイス間の通信時間
- Device Compute Time: オンデバイスの計算時間
- Python のオーバーヘッドを含むその他すべての時間
デバイスの計算精度 - 16 ビットおよび 32 ビット計算を使用するデバイス演算時間の割合を報告します。
ステップ時間グラフ: サンプリングされたすべてのステップのデバイスステップ時間(ミリ秒単位)のグラフを表示します。各ステップは、時間を費やしている箇所によって複数のカテゴリに(別々の色で)分かれています。赤い領域は、デバイスがホストからの入力データを待機してアイドル状態であったステップ時間の部分に対応しています。緑の領域は、デバイスが実際に動作していた時間の長さを示しています。
デバイスでの上位 10 個の TensorFlow 演算(例 GPU): 最も多くの時間が費やされたオンデバイスの演算が表示されます。
各行には、演算に費やされた自己時間(すべての演算にかかった時間に占める割合)、累積時間、カテゴリ、名前が表示されます。
実行環境: 以下を含むモデルの実行環境の高度な概要が表示されます。
- 使用されたホストの数。
- デバイスタイプ(GPU/TPU)
- デバイスコアの数。
次の推奨ステップ: モデルが入力限界にある場合に報告され、モデルのパフォーマンス ボトルネックを特定して解消するのに使用できるツールが提案されます。
入力パイプライン分析ツール
TensorFlow プログラムがファイルからデータを読み込むと、TensorFlow グラフにパイプライン方式でデータが表示されます。読み取りプロセスは連続した複数のデータ処理ステージに分割され、1 つのステージの出力が次のステージの入力となります。この読み込み方式を入力パイプラインといいます。
ファイルからレコードを読み取るための一般的なパイプラインには、次のステージがあります。
- ファイルの読み取り
- ファイルの前処理(オプション)
- ホストからデバイスへのファイル転送
入力パイプラインの効率が悪い場合、アプリケーションの速度が大幅に低下する可能性があります。アプリケーションが入力パイプラインに多くの時間を費やしている場合、このアプリケーションは入力限界であるとみなされます。入力パイプライン分析ツールを使用すると、効率の悪い入力パイプラインを特定できます。
入力パイプライン分析ツールは、プログラムで入力処理の負荷が高くなっているかどうかを即座に通知し、入力パイプラインの任意のステージでパフォーマンスボトルネックをデバッグするために、デバイス側とホスト側の分析を案内します。
データ入力パイプラインを最適化するための推奨ベストプラクティスについては、入力パイプラインのパフォーマンスに関するガイダンスをご覧ください。
入力パイプライン ダッシュボード
入力パイプライン分析ツールを開くには、Profile を選択し、Tools プルダウンから input_pipeline_analyzer を選択します。

ダッシュボードには次の 3 つのセクションがあります。
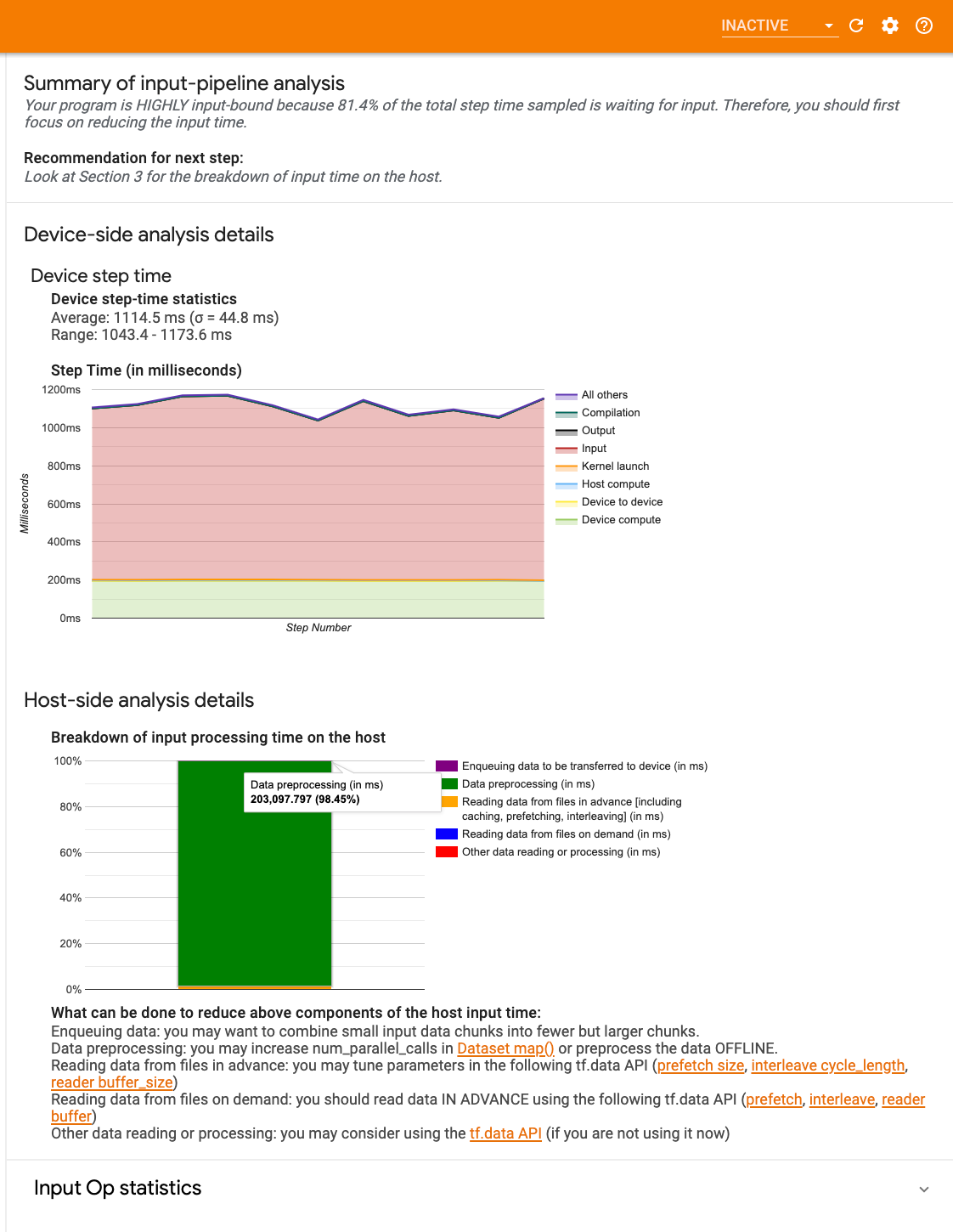
- サマリー: 入力パイプライン全体のサマリーが表示され、アプリケーションが入力限界になっているかどうかの情報が表示されます。入力限界になっている場合はその程度も表示されます。
- デバイス側の分析: デバイスのステップ時間、各ステップのコアで入力データの待機に費やしたデバイス時間など、デバイス側の詳細な分析結果が表示されます。
- ホスト側の分析: ホスト上での入力処理時間の内訳など、ホスト側の詳細な分析結果が表示されます。
入力パイプラインのサマリー
サマリーは、ホストからの入力待ちに費やされたデバイス時間の割合が表示されます。これにより、プログラムで入力処理の負荷が高くなっているかどうかを確認できます。インストゥルメント化された標準の入力パイプラインを使用している場合は、ツールによって多くの入力処理時間が費やされている部分が報告されます。
デバイス側の分析
デバイス側の分析では、デバイスとホストの間で費やされた時間と、ホストからの入力データの待機に費やされたデバイス時間が表示されます。
- ステップ数に対してプロットされたステップ時間: サンプリングされたすべてのステップのデバイスステップ時間(ミリ秒単位)のグラフを表示します。各ステップは、時間を費やしている箇所によって複数のカテゴリに(別々の色で)分かれています。赤い領域は、デバイスがホストからの入力データを待機してアイドル状態であったステップ時間の部分に対応しています。緑の領域は、デバイスが実際に動作していた時間の長さを示しています。
- ステップ時間の統計: デバイスステップ時間の平均、標準偏差、範囲([最小、最大])が報告されます。
ホスト側の分析
ホスト側の分析には、ホスト上での入力処理時間(tf.data API 演算に費やされた時間)の内訳が次のいくつかのカテゴリに分類されて表示されます。
- ファイルからのオンデマンドのデータ読み取り: キャッシュ、プリフェッチ、インターリーブなしで、ファイルからデータを読み取る際に費やされた時間。
- ファイルからのデータの事前読み取り: キャッシュ、プリフェッチ、インターリーブなど、ファイルの読み取りに費やされる時間。
- データの前処理: 画像の圧縮など、前処理の演算に費やされた時間。
- デバイスに転送されるデータのエンキュー: デバイスにデータを転送する前に、データがインフィード キューに追加される際に費やされた時間。
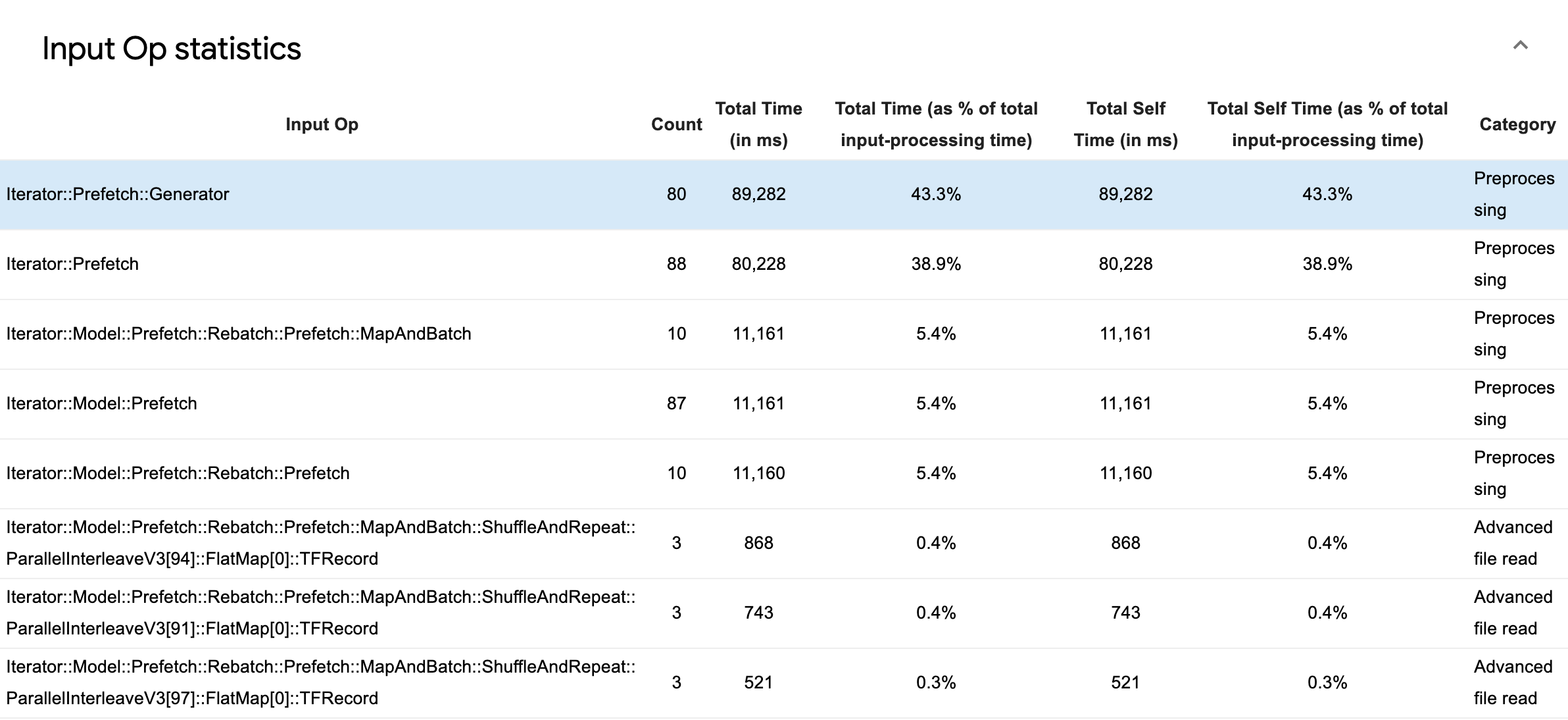
個々の入力演算の統計とそのカテゴリの内訳を実行時間別に表示するには、Input Op Statistics を展開します。
ソース データテーブルには、次の情報を含む各エントリが表示されます。
- 入力演算: 入力演算の TensorFlow 演算名が表示されます。
- 件数: プロファイリング期間中に実行された演算のインスタンスの合計数が表示されます。
- 合計時間(ミリ秒): 各インスタンスに費やされた時間の累積合計が表示されます。
- 合計時間(%): 演算に費やされた合計時間が、入力処理に費やされた合計時間との割合で表示されます。
- 合計自己時間(ミリ秒) - 各インスタンスに費やされた自己時間の累積合計が表示されます。この自己時間は、関数の本文内で費やされた時間を測定したもので、関数の本文から呼び出される関数で費やされた時間は含まれません。
- 合計自己時間(%) - 合計自己時間が、入力処理に費やされた合計時間との割合で表示されます。
- カテゴリ: 入力演算の処理カテゴリが表示されます。
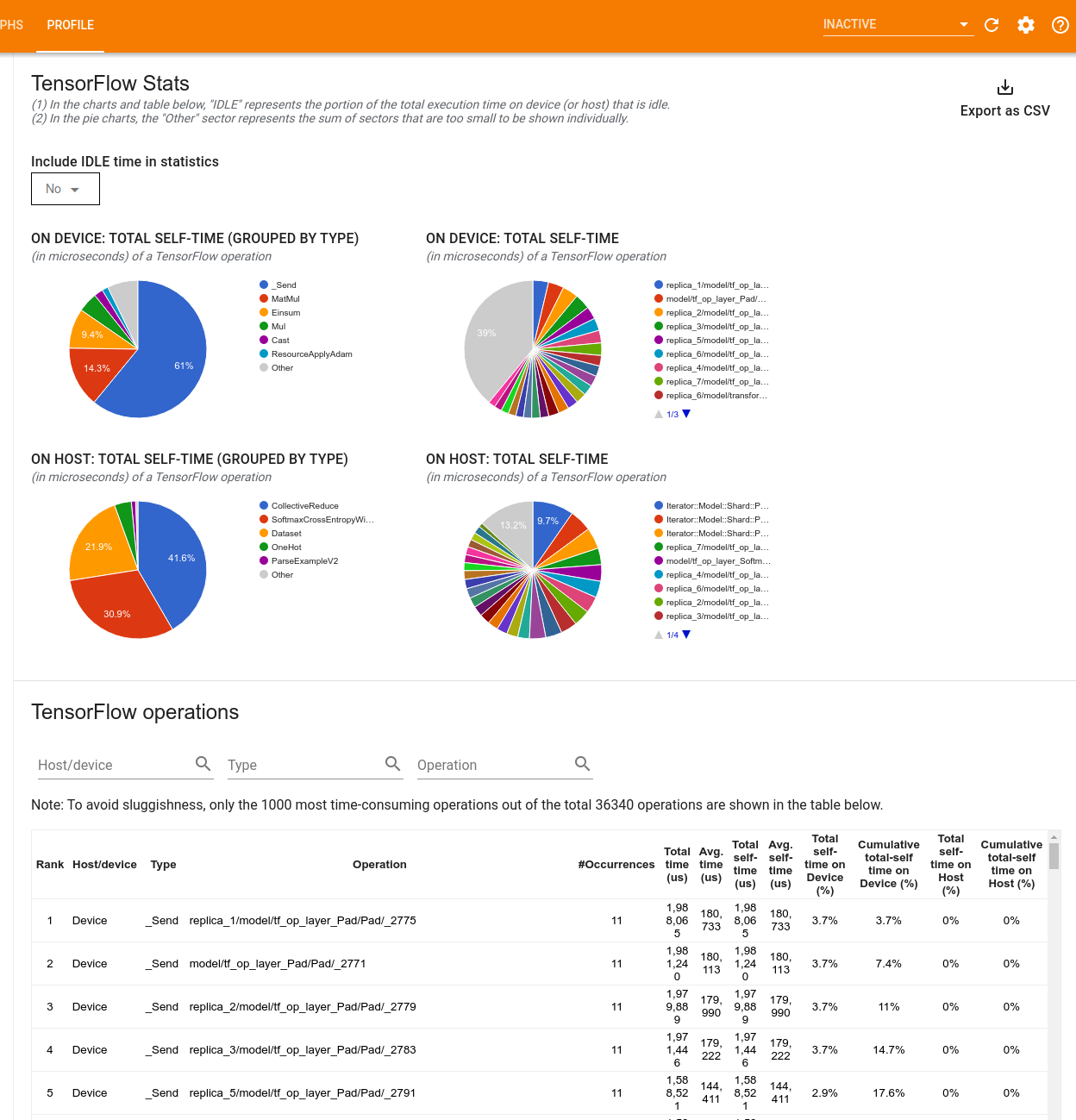
TensorFlow 統計
TensorFlow Stats ツールには、プロファイリングセッション中にホストまたはデバイスで実行されるすべての TensorFlow演算(op)のパフォーマンスが表示されます。
このツールでは 2 つのペインでパフォーマンス情報が表示されます。
上のペインには、最大 4 つの円グラフが表示されます。
- ホスト上の各演算の自己実行時間の分布。
- ホスト上の各演算タイプの自己実行時間の分布。
- デバイス上の各演算の自己実行時間の分布。
- デバイス上の各演算タイプの自己実行時間の分布。
下のペインには、TensorFlow 演算に関するデータを報告するテーブルが表示されており、各演算に 1 行、各タイプのデータに 1 列(列の見出しをクリックして列をソート)が割り当てられています。上のペインの右側にある Export as CSV ボタンをクリックすると、このテーブルのデータが CSV ファイルとしてエクスポートされます。
注意点:
子の演算を持つ演算がある場合:
- 演算の合計「累積」時間には、子の演算内で費やされた時間が含まれます。
- 演算の合計「自己」時間には、子の演算内で費やされた時間が含まれています。
演算がホスト上で実行される場合:
- 演算によって発生するデバイスの合計自己時間のパーセンテージは 0 になります。
- この演算までを含むデバイスの合計自己時間の累積パーセンテージは 0 になります。
演算がデバイス上で実行される場合:
- この演算で発生するホストの合計自己時間の割合は 0 になります。
- この演算までを含むホストの合計自己時間の累積的な割合は 0 になります。
円グラフとテーブルにアイドル時間を含めるか除外するかを選択できます。
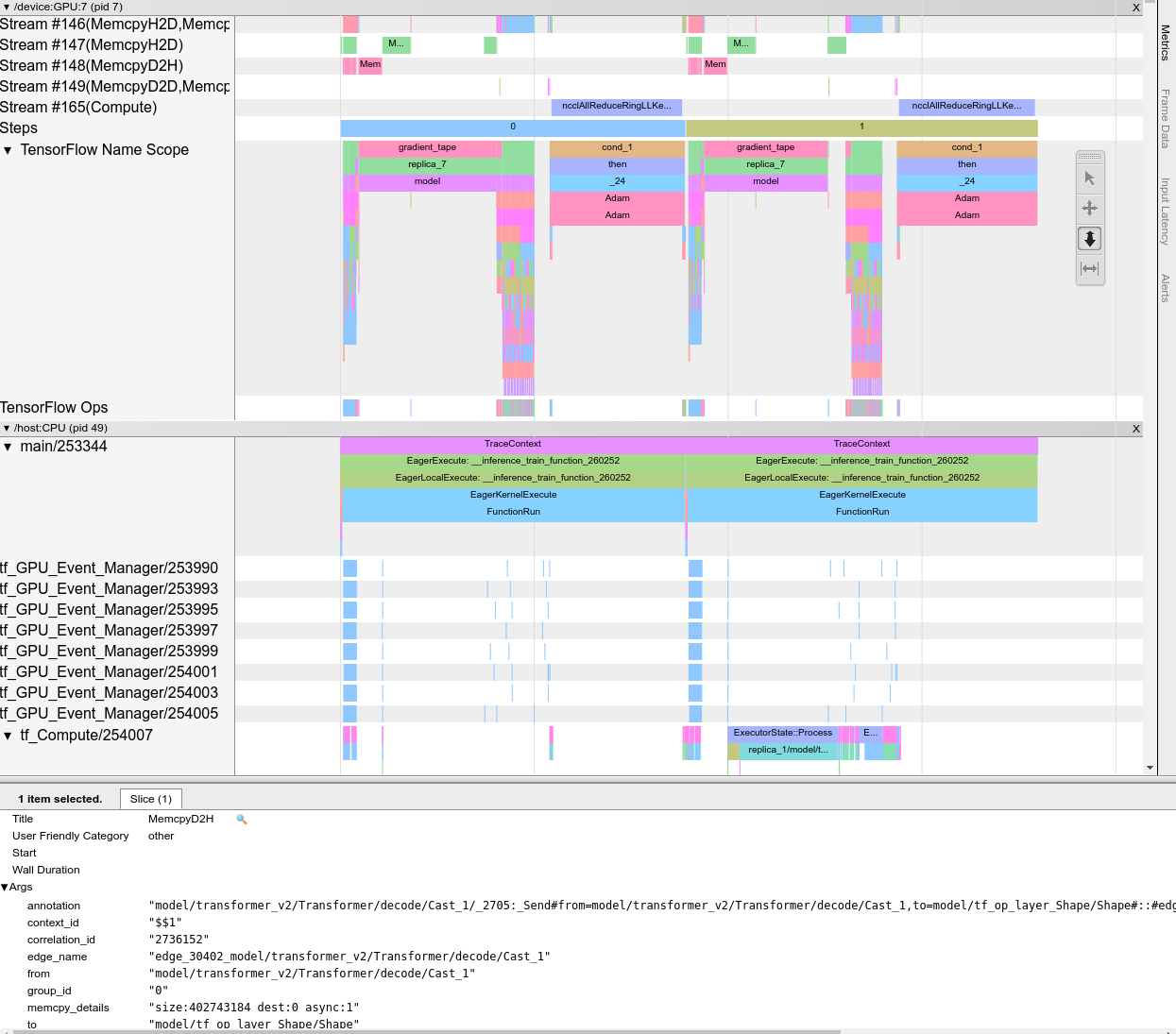
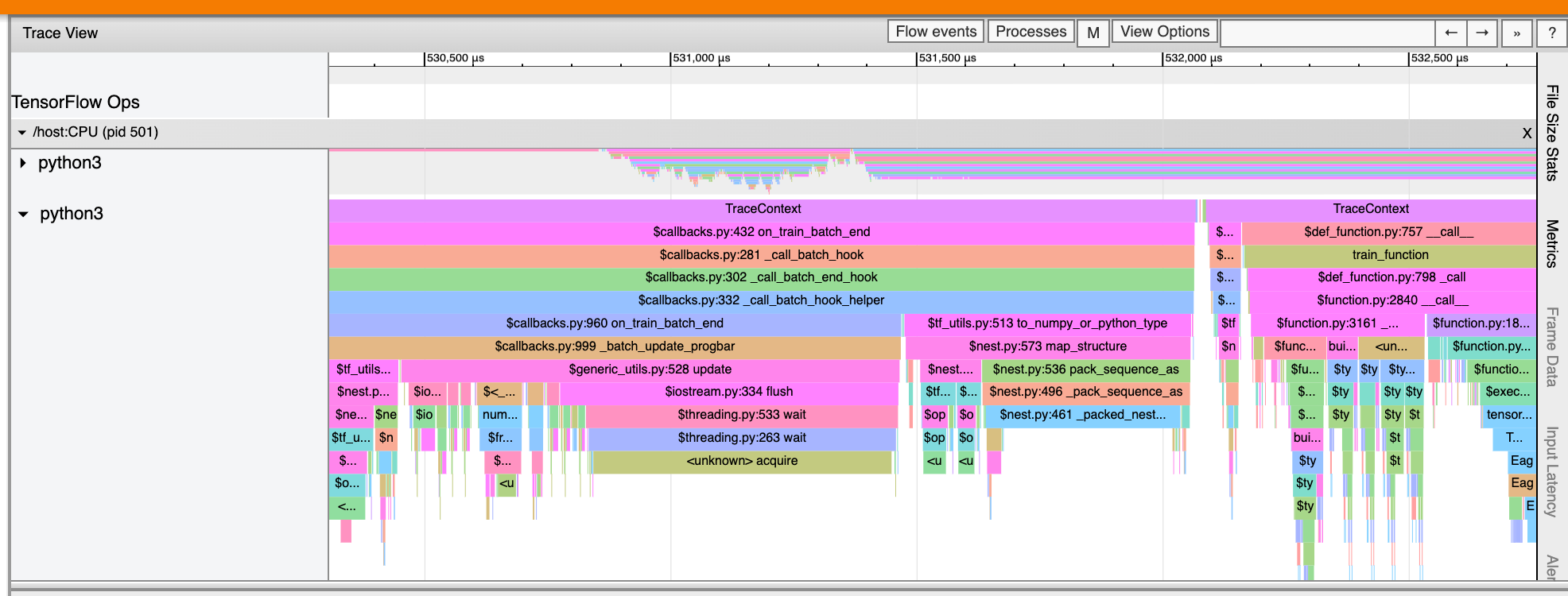
トレースビューア
トレースビューアには次のタイムラインが表示されます。
- TensorFlow モデルによって実行された演算の実行期間。
- 演算を実行したシステムの部分(ホストまたはデバイス)。通常、ホストが入力演算を実行し、トレーニングデータを前処理してデバイスに転送し、デバイスは実際のモデルトレーニングを行います。
トレースビューアを使用して、モデル内のパフォーマンスの問題を特定し、この問題を解決する対策を講じることができます。たとえば、入力とモデルトレーニングのどちらに大部分の時間を費やしているかどうかを大まかに識別できます。さらに詳しく見ると、どの演算の実行に最も時間がかかっているかも識別できます。トレースビューアで表示できるのはデバイスごとに 100 万イベントまでです。
トレースビューアのインターフェース
トレースビューアを開くと、最新の実行結果が表示されます。
この画面には、次の主要な要素が表示されます。
- Timeline ペイン: デバイスとホストで実行された演算が時系列で表示されます。
- Details ペイン: Timeline ペインで選択した演算の詳細情報が表示されます。
Timeline ペインには、次の要素が含まれます。
- 上部バー: さまざまな補助コントロールが表示されます。
- 時間軸:トレースの開始位置を基準にした時間が表示されます。
- セクションとトラックのラベル: 各セクションには複数のトラックが含まれており、左側の三角形をクリックすると、セクションの展開や折りたたみを行うことができます。システムで処理中の要素ごとに 1 つのセクションがあります。
- ツールセレクタ: Zoom、Pan、Select、Timing などのトレースビューアを操作するさまざまなツールが用意されています。
- イベント: これらのイベントは、演算が実行されていた時間やトレーニングステップなどのメタイベントの期間を示します。
セクションとトラック
トレースビューアには、次のセクションがあります。
- デバイスノードごとに 1 つのセクション。ラベルとしてデバイスチップの数とチップ内のデバイスノードの数が使用されます(例:
/device:GPU:0 (pid 0))。デバイスノードのセクションには、次のトラックが含まれます。- Step: デバイスで実行されていたレーニングステップの期間が表示されます。
- TensorFlow Ops: デバイス上で実行された演算が表示されます。
- XLA Ops: XLA が使用されているコンパイラである場合にデバイス上で実行された XLA 演算が表示されます。各 TensorFlow 演算が 1 つ以上の XLA 演算に変換されます。XLA コンパイラにより、XLA 演算がデバイス上で実行されるコードに変換されます。
- ホストマシンの CPU 上で実行されるスレッドのセクション - 「Host Threads」というラベルが付いています。このセクションには、CPU スレッドごとに 1 つのトラックが含まれます。セクションラベルと一緒に表示される情報は無視してもかまいません。
イベント
タイムライン内のイベントは異なる色で表示されます。色自体には特別な意味はありません。
トレースビューアは TensorFlow プログラム内の Python 関数呼び出しのトレースも表示できます。tf.profiler.experimental.start() API を使用する場合は、プロファイリングを開始する際に ProfilerOptions 名前付きタプルを使用して Python のトレースを有効化できます。または、プロファイリングにサンプリングモードを使用する場合は、[Capture Profile] ダイアログのドロップダウンオプションを使用してトレースのレベルを選択することができます。
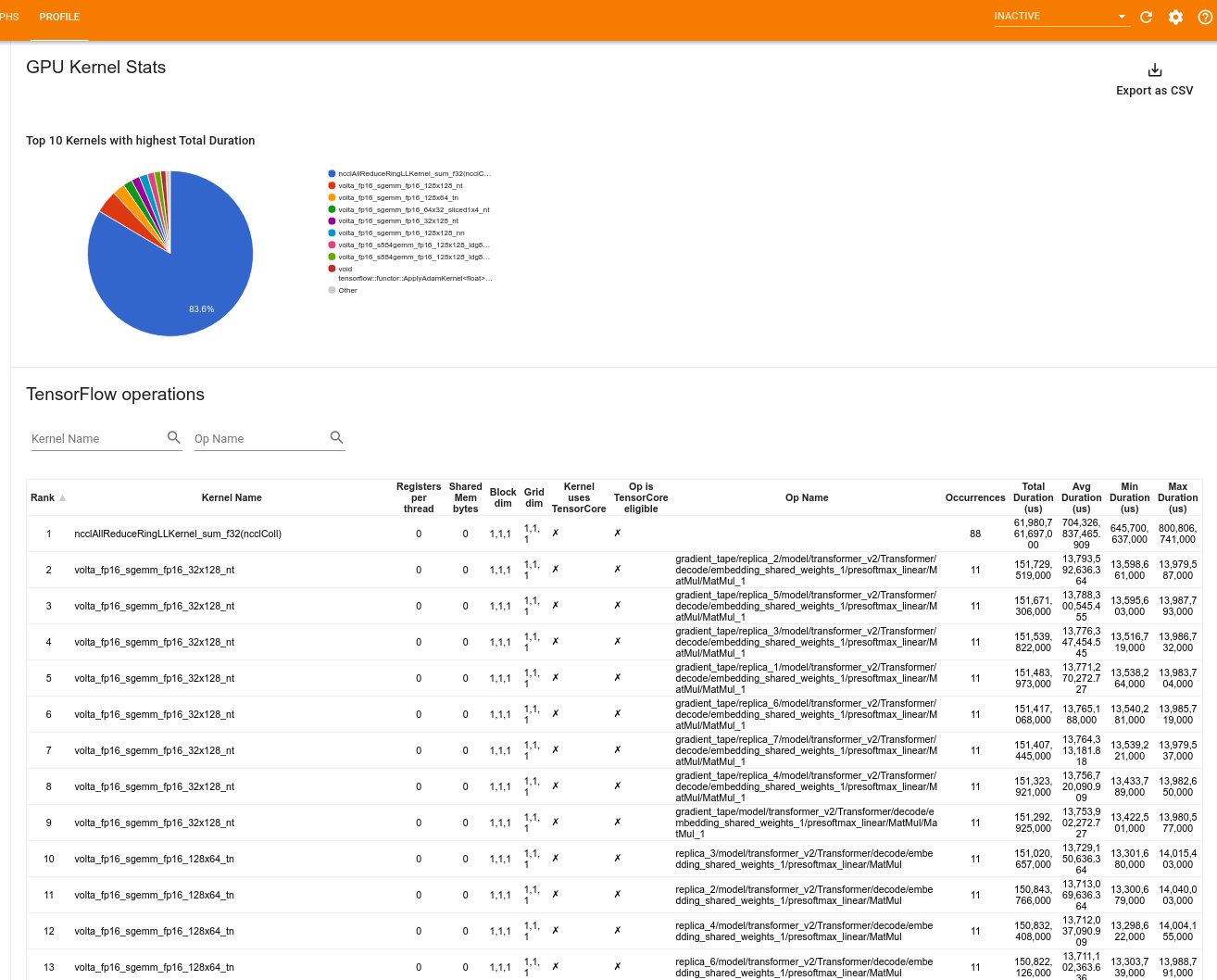
GPU カーネル統計
このツールには、すべての GPU アクセラレータカーネルのパフォーマンス統計と元の演算を表示されます。
このツールでは 2 つのペインで情報が表示されます。
上のペインには、合計経過時間が最も長い CUDA カーネルを示す円グラフが表示されます。
下のペインには、一意のカーネル演算ペアごとに次のデータを含むテーブルが表示されます。
- カーネルと演算のペアでグループ化された合計経過 GPU 時間の階数(降順)
- 起動されたカーネルの名前
- カーネルが使用している GPU レジスタの数
- 使用されている共有(静的+動的共有)メモリの合計サイズ(バイト単位)
blockDim.x, blockDim.y, blockDim.zで表現されたブロックの次元gridDim.x, gridDim.y, gridDim.zで表現されたグリッドの次元- 演算がテンソルコアを使用可能かどうか
- カーネルにテンソルコア命令が含まれているかどうか
- このカーネルを起動した演算の名前
- このカーネル演算のペアが発生した数
- 合計経過 GPU 時間(マイクロ秒)
- 平均経過 GPU 時間(マイクロ秒)
- 最小経過 GPU 時間(マイクロ秒)
- 最大経過 GPU 時間(マイクロ秒)
メモリのプロファイリングツール
メモリプロファイルツールは、プロファイリング間のデバイスのメモリ使用状況を監視します。このツールを使用して、次のことを実行できます。
- ピークメモリ使用状況とそれに対応する TensorFlow 演算への割り当てメモリを特定することで、メモリ不足(OOM)の問題をデバッグします。また、マルチテナントの推論を実行する場合に発生する OOM 問題もデバッグできます。
- メモリの断片化の問題をデバッグします。
メモリプロファイルツールには、次の 3 つのセクションにデータが表示されます。
- メモリプロファイルのサマリー
- メモリのタイムライングラフ
- メモリの詳細テーブル
メモリプロファイルのサマリー
このセクションには、以下に示されるように、TensorFlow プログラムの要約が表示されます。
<img src="./images/tf_profiler/memory_profile_summary.png" width="400", height="450">
メモリプロファイルのサマリーには、次の 6 つのフィールドがあります。
- Memory ID: すべての利用可能なデバイスメモリシステムをリストするドロップダウン。ドロップダウンから、表示するメモリシステムを選択できます。
- #Allocation: プロファイリングのインターバル中に作成されるメモリ割り当ての数です。
- #Deallocation: プロファイリングのインターバル中に行われるメモリ割り当て解除の数です。
- Memory Capacity: 選択したメモリシステムの合計容量(GiB)です。
- Peak Heap Usage: モデルが実行し始めてからのピークメモリ使用率(GiB)です。
- Peak Memory Usage: プロファイリングのインターバル中のピークメモリ使用率(GiB)です。このフィールドには次のサブフィールドがあります。
- Timestamp: タイムライングラフ上でピークメモリ使用率が発生したときのタイムスタンプです。
- Stack Reservation: スタックに予約されたメモリの量(GiB)です。
- Heap Allocation: ヒープに割り当てられたメモリの量(GiB)です。
- Free Memory: 空きメモリの量(GiB)です。Memory Capacity は、Stack Reservation、Heap Allocation、および Free Memory の総計です。
- Fragmentation: 断片率です(低いほど良)。
(1 - 空きメモリの最大チャンクサイズ / 合計空きメモリ)のパーセント率で計算されます。
メモリのタイムライングラフ
このセクションには、メモリ使用率(GiB)と断片率を時間(ms)比較した図が表示されます。
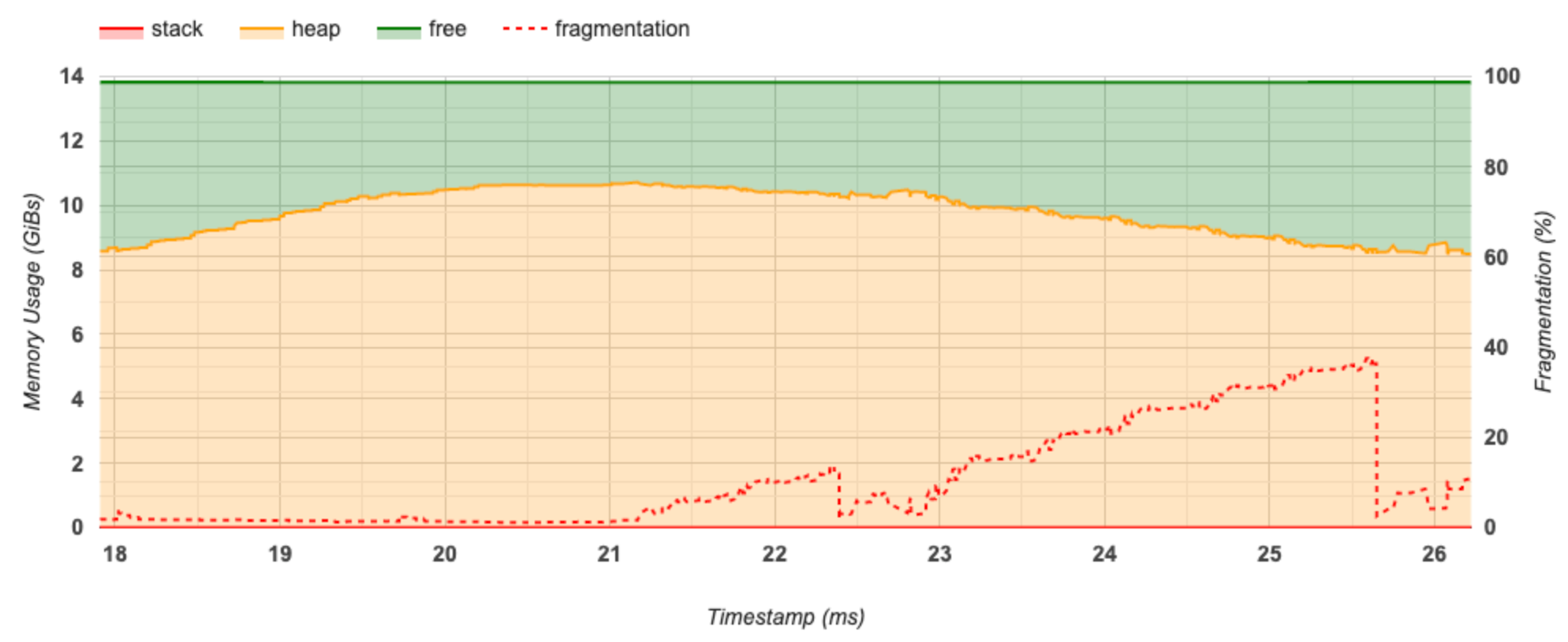
X 軸は、プロファイリングインターバルのタイムライン(ms)を表します。左の Y 軸はメモリ使用率(GiB)を、右の Y 軸は断片率を表します。合計メモリは、X 軸のある時点で、スタック(赤)、ヒープ(オレンジ)、空き(緑)の 3 つに分けて示されています。特定のタイムスタンプにマウスポインタを合わせると、以下のように、その時点でのメモリの割り当てと割り当て解除の詳細を確認できます。
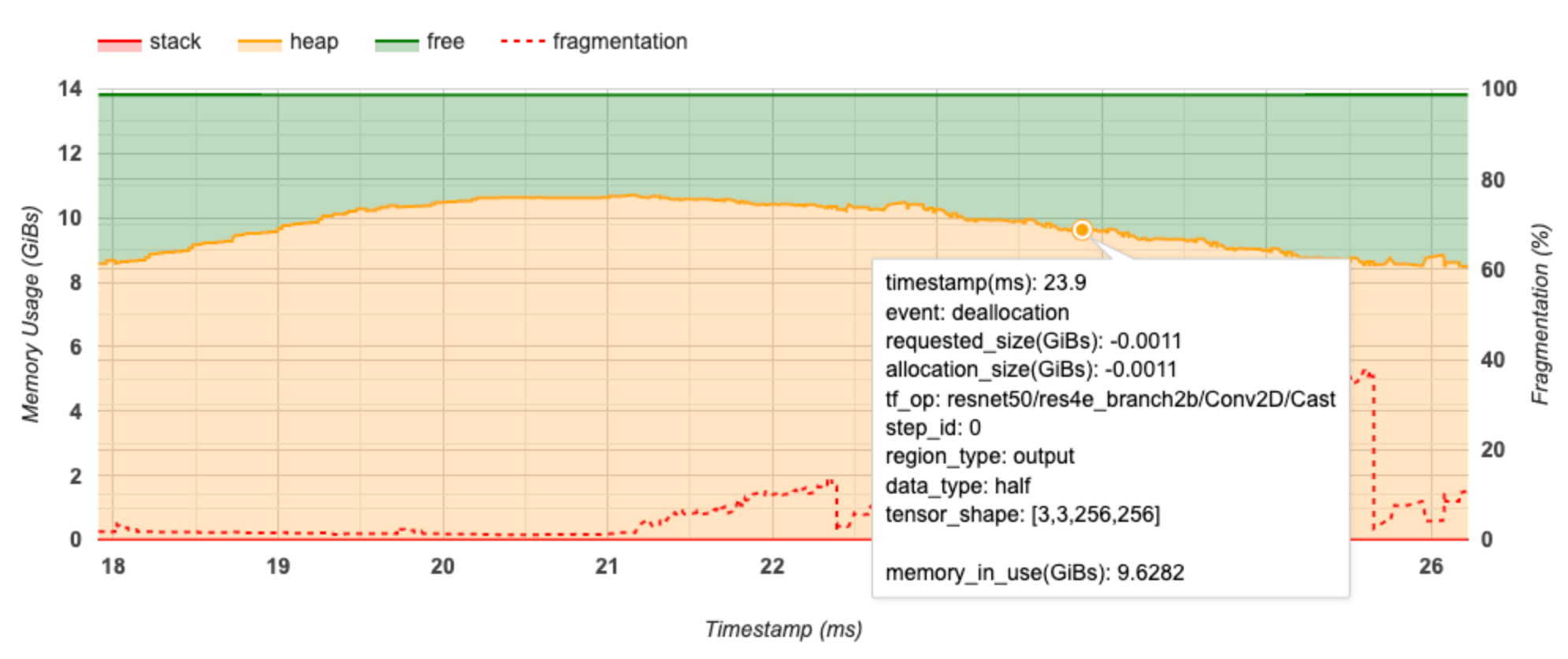
ポップアップウィンドウには、次の情報が表示されます。
- timestamp(ms): タイムライン上の選択されたイベントの場所
- event: イベントの種類(割り当てまたは割り当て解除)
- requested_size(GiBs): 要求されたメモリ量。割り当て解除イベントの場合、これは負の値になります。
- allocation_size(GiBs): 割り当てられた実際のメモリ量。割り当て解除イベントの場合、これは負の値になります。
- tf_op: 割り当てと割り当て解除を要求する TensorFlow Op
- step_id: このイベントが発生したトレーニングステップ
- region_type: この割り当てメモリの対象であるデータエントリーの種類。可能な値は、一時を意味する
temp、アクティベーションと勾配のoutput、および重みと定数のpersist/dynamicです。 - data_type: テンソル要素の種類(8-bit 署名無し整数を表す uint8 など)
- tensor_shape: 割り当て/割り当て解除されるテンソルの形状
- memory_in_use(GiBs): この時点で使用されている合計メモリ
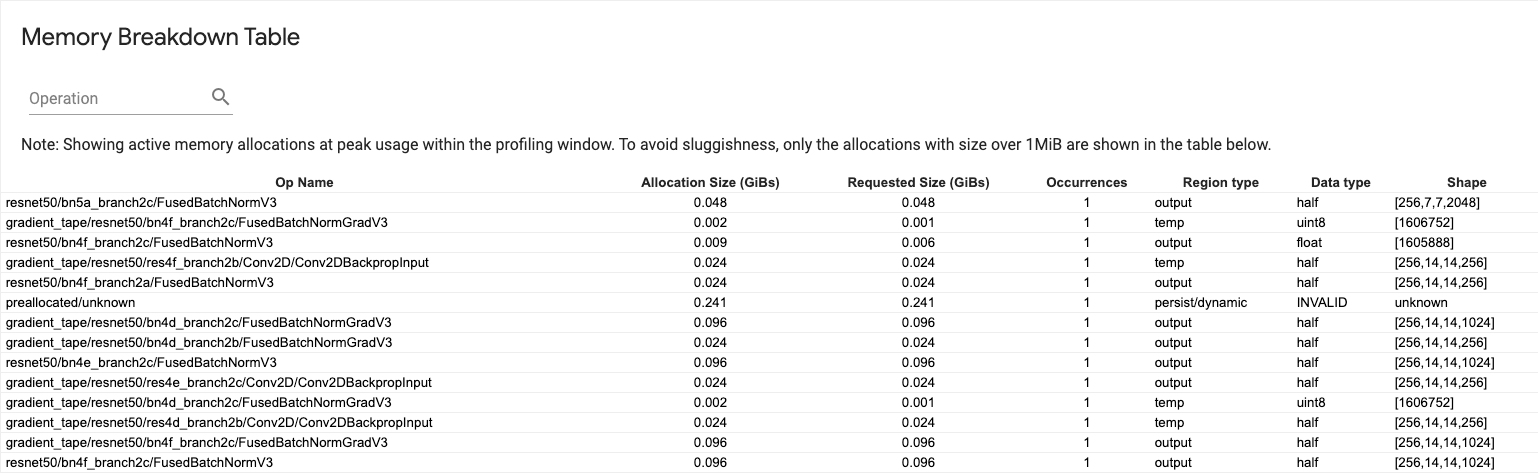
メモリの詳細テーブル
このテーブルには、プロファイリングインターバルのピークメモリ使用率の時点でアクティブなメモリの割り当てが示されます。
TensorFlow 演算ごとに 1 つの行があり、各行には次の列があります。
- Op Name: TensorFlow 演算の名前
- Allocation Size (GiBs): この演算に割り当てられている合計メモリ量
- Requested Size (GiBs): この演算に要求されたメモリの合計量
- Occurrences: この演算の割り当て数
- Region type: この割り当てメモリの対象であるデータエンティティの種類。可能な値は、一時を意味する
temp、活性化と勾配のoutput、および重みと定数のpersist/dynamicです。 - Data type: テンソル要素の型
- Shape: 割り当てられたテンソルの形状
注意: テーブル内のすべての列は並べ替え可能で、演算名で行をフィルタできます。
Pod ビューア
Pod ビューアツールには、すべてのワーカーのトレーニングステップの詳細が表示されます。
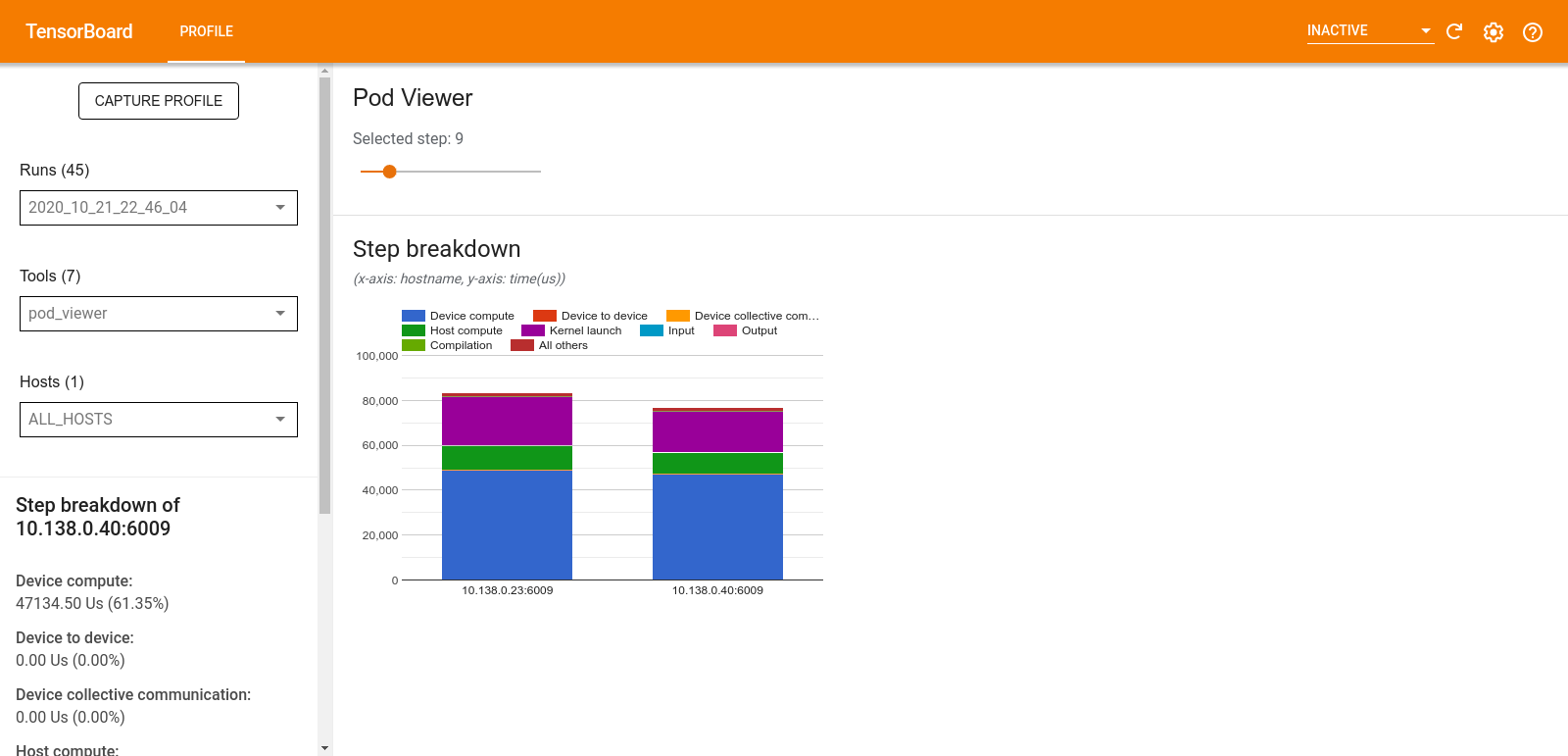
- 上部のペインには、ステップ番号を選択するためのスライダーがあります。
- 下部のペインには、スタックされた列のグラフが表示されます。これは相互に重なったステップ時間カテゴリの詳細を示す要約です。各スタックの列は、一意のワーカーを表します。
- スタックされた列にマウスポインタを合わせると、左側のカードにそのステップの詳細に関するさらに詳しい情報が表示されます。
tf.data のボトルネック分析
警告: このツールは実験的です。分析結果が誤っていると思われる場合は、GitHub 課題を報告してください。
tf.data ボトルネック分析は、プログラム内の tf.data 入力パイプラインに存在するボトルネックを自動的に検出し、その修正方法を推奨します。プラットフォーム(CPU/GPU/TPU)に関係なく、tf.data を使用しているあらゆるプログラムで機能します。分析と推奨は、こちらのガイドに基づきます。
次のステップで、ボトルネックを検出します。
- 最も多い入力バウンドのホストを見つけます。
- 最も実行の遅い
tf.data入力パイプラインを見つけます。 - プロファイラのトレースから入力パイプラインのグラフを再構築します。
- 入力パイプライングラフの重要なパスを見つけます。
- その重要なパスで最も遅い変換をボトルネックとして識別します。
UI は、パフォーマンス分析サマリー、全入力パイプラインのサマリー、入力パイプラインのグラフの 3 つのセクションに分かれています。
パフォーマンス分析サマリー
このセクションには、分析の概要が示されます。プロファイル内に処理の遅い tf.data 入力パイプラインが検出されたかどうかがわかります。このセクションには、最も多い入力境界のホストと、その中で最も遅い入力パイプラインが最大レイテンシとともに表示されます。最も重要なのは、入力パイプラインのどの部分がボトルネックであり、それをどのように修正するかと示しているところです。ボトルネックの情報には、イテレータの種類とそのロング名が示されます。
tf.data イテレータのロング名の読み取り方
ロング名は、Iterator::<Dataset_1>::...::<Dataset_n> のような形式です。ロング名内の <Dataset_n> は、イテレータの種類に一致しており、ロング名の他のデータセットは、下流の変換を表します。
たとえば、次の入力パイプラインデータセットを見てみましょう。
dataset = tf.data.Dataset.range(10).map(lambda x: x).repeat(2).batch(5)
上記のデータセットから、イテレータのロング名は次のように読み取れます。
| イテレータの種類 | ロング名 |
|---|---|
| 範囲 | Iterator::Batch::Repeat::Map::Range |
| マップ | Iterator::Batch::Repeat::Map |
| 反復 | Iterator::Batch::Repeat |
| バッチ | Iterator::Batch |
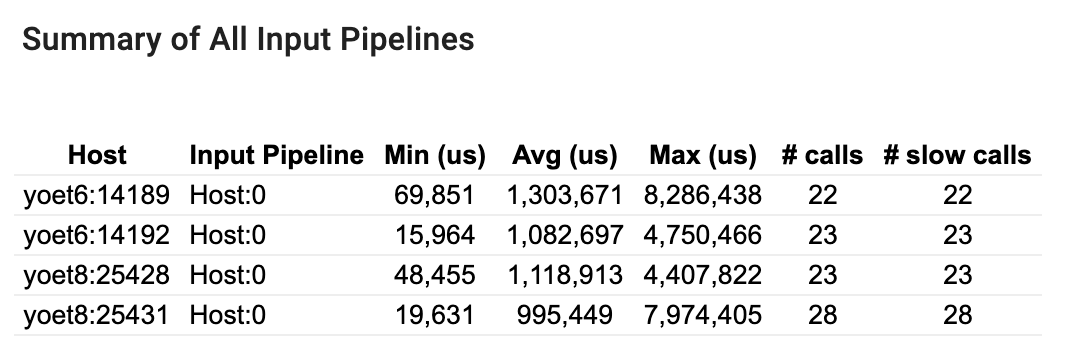
すべての入力パイプラインのサマリー
このセクションには、全ホストのすべての入力パイプラインの概要が示されます。通常、入力パイプラインは 1 つです。分散ストラテジーを使用している場合、プログラムの tf.data コードを実行しているホスト入力パイプラインが 1 つと、そのホスト入力パイプラインからデータを取得してデバイスに転送しているデバイス入力パイプラインが複数あります。
入力パイプラインごとに、実行時間の統計が表示されます。50 μs より長くかかる呼び出しは、遅いと見なされます。
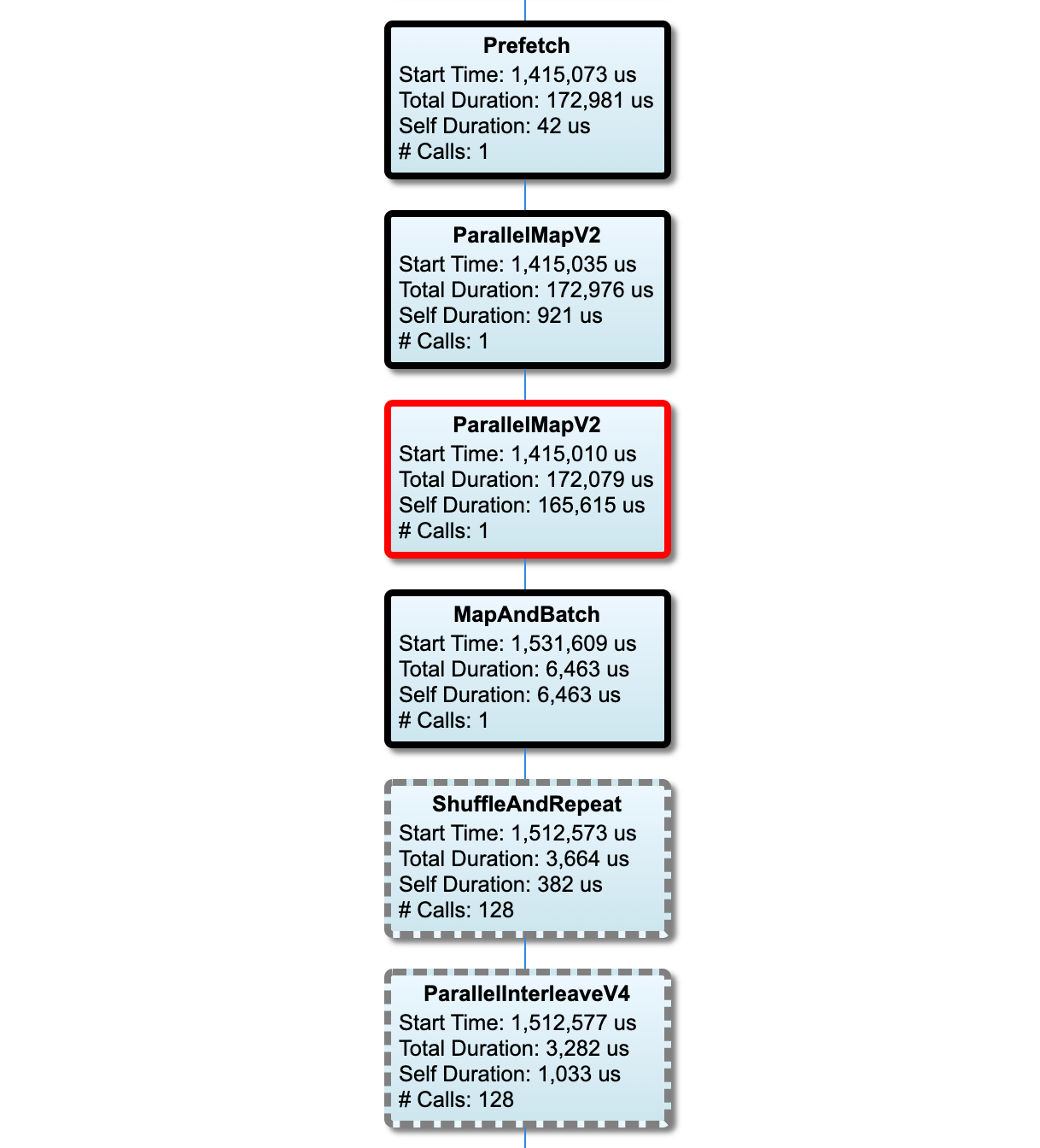
入力パイプラインのグラフ
このセクションには、入力パイプラインのグラフが実行時間と共に示されます。「Host」と「Input Pipeline」を使って、どのホストと入力パイプラインを表示するかを選択できます。入力パイプラインの実行は、実行時間別に降順で並べ替えられており、この順序は Rank ドロップダウンを使って選択できます。
重要なパスにあるノードは太いアウトラインで示されます。ボトルネックノードは重要なパスにある、それ自体の処理に最も時間のかかったノードで、赤いアウトラインで示されます。その他の重要でないノードは、グレーの破線で示されます。
各ノードの Start Time は、実行の開始時刻を示します。入力パイプラインに Batch 演算がある場合などは、同一のノードが何度も実行されることがありますが、その場合の開始時刻は、最初に実行されたときの時刻です。
Total Duration は実行の実測時間です。何度も実行されている場合の実測時間は、各実行の実測時間の合計です。
Self Time は直下の子ノードと重複した時間を除く Total Time です。
「# Calls」は、入力パイプラインが実行された回数です。
パフォーマンスデータの収集
TensorFlow プロファイラは、TensorFlow モデルのホストアクティビティと GPU トレースを収集します。プロファイラは、プログラムモードかサンプリングモードのいずれかでパフォーマンスデータを収集するように構成できます。
プロファイリング API
次の API を使用してプロファイリングを実行できます。
TensorBoard Keras のコールバックを使用したプログラムモード(
tf.keras.callbacks.TensorBoard)# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])tf.profiler関数 API を使用したプログラムモードtf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()コンテキストマネージャを使用したプログラムモード
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
注意: プロファイラを長時間実行すると、メモリ不足になる可能性があります。一度にプロファイリングするのは 10 ステップまでにすることをお勧めします。初期化のオーバーヘッドによる精度低下を回避するため、最初の数バッチはプロファイリングを避けてください。
サンプリングモード:
tf.profiler.experimental.server.startを使用してオンデマンドプロファイリングを実行し、gRPC サーバーを起動して TensorFlow モデルを実行します。gRPC サーバーを起動してモデルを実行したら、TensorBoard プロファイルプラグインの Capture Profile ボタンを使用してプロファイルをキャプチャできます。まだ実行されていない場合は、上記の「プロファイラのインストール」セクションのスクリプトを使用して TensorBoard インスタンスを起動してください。以下に例を示します。
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)複数のワーカーのプロファイリング例を以下に示します。
# E.g. your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)
<img src="./images/tf_profiler/capture_profile.png" width="400", height="450">
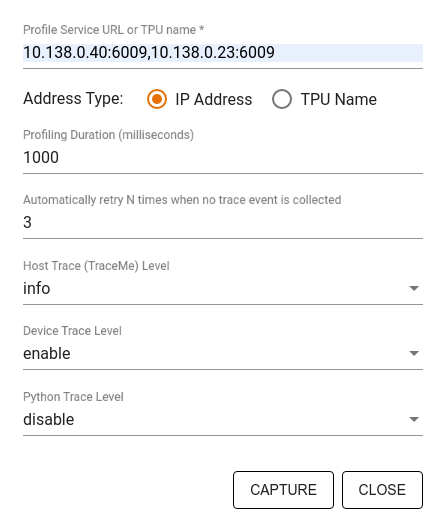
以下の項目を指定するには、Capture Profile ダイアログを使用します。
- プロファイルサービス URL または TPU 名のカンマ区切りのリスト
- プロファイリング期間
- デバイス、ホスト、Python 関数呼び出しのトレースレベル
- 初回失敗時にプロファイラにプロファイルのキャプチャを再試行させる回数
カスタムトレーニングループのプロファイリング
TensorFlow コードでカスタムトレーニングループをプロファイリングするには、トレーニングループに tf.profiler.experimental.Trace API を使用して、プロファイラ用にステップ境界をマークします。
name 引数は、ステップ名のプレフィックスとして使用され、ステップ名に step_num キーワードが追加されます。また、_r キーワード引数によって、プロファイラはステップイベントとしてこのトレースイベントを処理します。
以下に例を示します。
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
これにより、プロファイラのステップごとのパフォーマンス分析が有効になり、ステップイベントがトレースビューアに表示されるようになります。
入力パイプラインで正確な分析を行うため、tf.profiler.experimental.Trace コンテキスト内にデータセットイテレータを必ず含めるようにしてください。
以下のコードスニペットはアンチパターンです。
警告: このコードにより、不正確な入力パイプライン分析が実行されます。
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
プロファイリングの使用事例
プロファイラは、4 種類の軸に沿って多数の使用事例をカバーしています。これらの組み合わせの中には、現在サポートされているものもあれば、今後の追加が予定されているものもあります。次に一部の使用事例を示します。
- ローカルプロファイリングとリモートプロファイリング: これら 2 つは、プロファイリング環境を設定するための一般的な方法です。ローカルプロファイリングでは、モデルが実行されているのと同じマシン(GPU を備えたローカルのワークステーションなど)でプロファイリング API が呼び出されます。リモートプロファイリングでは、モデルが実行されているマシンとは異なるマシン(Cloud TPU 上など)でプロファイリング API が呼び出されます。
- 複数のワーカーのプロファイリング: TensorFlow の分散トレーニング機能を使用すると、複数のマシンをプロファイリングできます。
- ハードウェアプラットフォーム: CPU、GPU、TPU のプロファイリング。
以下のテーブルに、前述の TensorFlow 対応ユースケースの簡単な概要を示します。
| プロファイリング API | ローカル | リモート | 複数 | ハードウェア | : : : : ワーカー : プラットフォーム : | :--------------------------- | :-------- | :-------- | :-------- | :-------- | | TensorBoard Keras | サポート対象 | サポート | サポート | CPU、GPU | : コールバック : : 対象外 : 対象外 : : | tf.profiler.experimental | サポート対象 | サポート | サポート | CPU、GPU | : start/stop API : : 対象外 : 対象外 : : | tf.profiler.experimental | サポート対象 | サポート対象 | サポート対象 | CPU、GPU, | : client.trace API : : : : TPU : | コンテキストマネージャ API | サポート対象 | サポート | サポート | CPU、GPU | : : : 対象外 : 対象外 : :
最適なモデルパフォーマンスのベストプラクティス
TensorFlow モデルに適用可能な次の推奨事項を参照し、パフォーマンスの最適化を実現してください。
一般的にはデバイス上ですべての変換を実行し、cuDNN や Intel MKL などのご使用のプラットフォームと互換性のあるライブラリの最新バージョンを使用するようにしてください。
入力データパイプラインの最適化
[#input_pipeline_analyzer] のデータを使用して、データ入力パイプラインを最適化します。データ入力パイプラインの効率性が高まると、デバイスのアイドル時間を短縮することで、モデルの実行速度を大幅に改善できます。Better performance with the tf.data API ガイドと以下に記載されたベストプラクティスを合わせ、データ入力パイプラインの効率を高めてみてください。
一般に、順次に実行する必要のない演算を並行処理すると、データ入力パイプラインを大幅に最適化できます。
多くの場合、呼び出しの順序を変更したり、モデルごとに最も良く機能するように引数を調整したりすることで最適化することができます。入力データパイプラインを最適化する際は、最適化の効果を個別に定量化できるよう、トレーニングとバックプロパゲーションステップなしで、データローダーのみをベンチマークします。
合成データを使用してモデルを実行し、入力パイプラインがパフォーマンスのボトルネックになっていないかどうかを確認してください。
マルチ GPU トレーニングには、
tf.data.Dataset.shardを使用してください。入力ループの非常に早い段階でシャードすることで、スループットの低下を回避できます。TFRecords を操作する際は、TFRecords のコンテンツではなく、リストをシャードするようにしてください。tf.data.AUTOTUNEを使用して、num_parallel_callsの値を動的に設定することで、複数の演算を並行処理します。純粋な TensorFlow 演算と比べ、
tf.data.Dataset.from_generatorの実行は低速であるため、その使用を制限することを検討してください。tf.py_functionはシリアル化できず、分散 TensorFlow での実行に対応していないため、その使用を制限することを検討してください。tf.data.Optionsを使用して、入力パイプラインへの静的最適化を制御します。
入力パイプラインの最適化に関するその他のガイダンスについては、tf.data パフォーマンス分析ガイドもご覧ください。
データ拡張を最適化する
画像データを操作する場合、フリップ、クロップ、回転といった空間変換を適用した後に様々なデータ型をキャストすることで、データ拡張の効率をたかめるようにします。
注意: tf.image.resize などの一部の演算は、透過的に dtype を fp32 に変更します。データが自動的に 0 と 1 の間にならない場合は、そのようになるように必ずデータを正規化してください。この手順を省略すると、AMP が有効である場合に NaN エラーが発生する可能性があります。
NVIDIA® DALI を使用する
GPU 対 CPU 比の高いシステムを使用しているなどの一部のケースでは、上記の最適化だけでは、CPU サイクルの制限によるデータローダー内のボトルネックを十分に除去できない可能性があります。
コンピュータービジョンやオーディオのディープラーニングアプリケーション用に NVIDIA® GPU を使用している場合は、データパイプラインを高速化するために、Data Loading Library(DALI)を使用することを検討してください。
サポートされている DALI 演算のリストは、NVIDIA® DALI: Operations ドキュメントをご覧ください。
スレッド化と並列実行を使用する
マルチ CPU スレッドでの演算の実行を高速化するには、tf.config.threading API を使用して実行します。
TensorFlow はデフォルトで自動的に並列処理するスレッドの数を設定します。TensorFlow 演算の実行に使用できるスレッドプールは、使用できる CPU スレッド数に応じて異なります。
1 つの演算の最大並列高速化は、tf.config.threading.set_intra_op_parallelism_threads を使用して制御します。複数の演算を並列実行する場合、これらの演算は使用可能なスレッドプールを共有することに注意してください。
独立した非ブロッキング演算(グラフ上で演算間のパスが指示されていない演算)を使用している場合は、tf.config.threading.set_inter_op_parallelism_threads を使用して、使用可能なスレッドプールを同時に使用して実行するようにします。
その他
NVIDIA® GPU でより小さなモデルを操作する場合は、 tf.compat.v1.ConfigProto.force_gpu_compatible=True を設定し、CUDA pinned メモリですべての CPU テンソルを割り当てるように強制することで、モデルパフォーマンスを大幅に向上させることができます。ただし、不明または非常に大きなモデルにこのオプションを使用する際には注意が必要です。これにより、ホスト(CPU)パフォーマンスに悪影響が及ぶ可能性があります。
デバイスのパフォーマンス改善
ここと GPU パフォーマンス最適化ガイドに説明されているベストプラクティスに従って、オンデバイス TensorFlow モデルパフォーマンスを最適化します。
NVIDIA GPU を使用している場合は、以下を実行して、CPU とメモリの使用率を CSV ファイルにログ記録します。
nvidia-smi
--query-gpu=utilization.gpu,utilization.memory,memory.total,
memory.free,memory.used --format=csv
データレイアウトを構成する
チャンネル情報を含むデータ(画像など)を操作している場合は、チャンネルラストを優先するように(NCHW より NHWC を優先)、データレイアウト形式を最適化します。
チャンネルラストデータ形式は、テンソルコアの使用率を改善し、AMP と組み合わせられたときに、特に畳み込みモデルでパフォーマンスの大幅な改善が得られます。NCHW データレイアウトはテンソルコアによって操作されますが、自動転置演算により、オーバーヘッドを追加してしまいます。
NHWC レイアウトを優先するようにデータレイアウトを最適化するには、tf.keras.layers.Conv2D、tf.keras.layers.Conv3D、tf.keras.layers.RandomRotation などのレイヤーに data_format="channels_last" を設定してください。
Keras バックエンド API にデフォルトのデータレイアウト形式を設定するには、tf.keras.backend.set_image_data_format を使用します。
L2 キャッシュの上限に達する
NVIDIA® GPU を使用する際に、トレーニングループの前に以下のコードスニペットを実行することで、L2 フェッチの粒度を 128 バイトの上限まで引き上げることができます。
import ctypes
_libcudart = ctypes.CDLL('libcudart.so')
# Set device limit on the current device
# cudaLimitMaxL2FetchGranularity = 0x05
pValue = ctypes.cast((ctypes.c_int*1)(), ctypes.POINTER(ctypes.c_int))
_libcudart.cudaDeviceSetLimit(ctypes.c_int(0x05), ctypes.c_int(128))
_libcudart.cudaDeviceGetLimit(pValue, ctypes.c_int(0x05))
assert pValue.contents.value == 128
GPU スレッドの使用を構成する
GPU スレッドモードは、GPU スレッドがどのように使用されるかを決定します。
すべての GPU スレッドが前処理に取られないようにするために、スレッドモードを gpu_private に設定します。こうすることで、トレーニング中のカーネルの起動遅延を抑制できます。また、GPU ごとのスレッド数を設定することも可能です。これらの値は、環境変数を使用して設定します。
import os
os.environ['TF_GPU_THREAD_MODE']='gpu_private'
os.environ['TF_GPU_THREAD_COUNT']='1'
GPU のメモリオプションを構成する
一般に、バッチサイズを増やしてモデルをスケーリングすることで、GPU 使用率とスループットを向上させることができます。バッチサイズを増やすとモデルの精度が変わるため、学習率などのハイパーパラメータをターゲット精度を満たすように調整することで、モデルをスケーリングする必要があることに注意してください。
また、tf.config.experimental.set_memory_growth を使用すると、わずかなメモリのみを必要とする演算に、使用可能なメモリがすべて割り当てられないように、GPU メモリを増やすこともできます。こうすることで、GPU メモリを消費する他のプロセスを同じデバイス上で実行させられるようになります。
詳細については、GPU ガイドの GPU メモリ増加を制限するの説明をご覧ください。
その他
トレーニングのミニバッチサイズ(トレーニングループの 1 つのイテレーションでデバイスごとに使用されるトレーニングサンプル数)を、GPU でメモリ不足(OOM)が発生しない程度の最大量まで増やします。バッチサイズを増やすとモデルの精度が変化するため、ターゲット精度を満たすようにハイパーパラメータを調整して、モデルをスケーリングするようにしてください。
本番コードでは、テンソルの割り当て中に OOM エラーがレポートされないように機能を無効にしてください。
tf.compat.v1.RunOptionsでreport_tensor_allocations_upon_oom=Falseを設定します。畳み込みレイヤーのあるモデルでは、バッチ正規化を使用する場合は、バイアスの追加を取り除きます。バッチ正規化は、平均値で値をシフトするため、定数のバイアス項を含める必要がなくなります。
TF Stats を使用し、オンデバイスの演算がどの程度効率的に実行されているかを確認します。
tf.functionを使用して計算を実行し、オプションとして、jit_compile=Trueフラグを有効にします(tf.function(jit_compile=True)。詳細は、XLA tf.function を使用するをご覧ください。ステップ間でホスト側の Python 演算を最小化し、コールバックを減らす。すべてのステップではなく、数ステップごとにメトリックを計算します。
デバイスの演算ユニットをビジー状態に保ちます。
複数のデバイスに対して並列にデータを送信します。
IEEE が規定した半精度浮動小数点形式である
fp16、または Brain 浮動小数点である bfloat16 形式などの 16 ビット数値表現を使用することを検討してください。
追加リソース
- Keras と TensorBoard を使用した TensorFlow Profiler: プロファイルモデルのパフォーマンスチュートリアル。このガイドの推奨事項を適用できます。
- TensorFlow Dev Summit 2020 の講演「TensorFlow 2 のパフォーマンスプロファイリング」
- TensorFlow Dev Summit 2020 の TensorFlow Profiler でも
既知の制限
TensorFlow 2.2 と TensorFlow 2.3 におけるマルチ GPU のプロファイリング
TensorFlow 2.2 と 2.3 では、シングルホストシステムのみのマルチ GPU プロファイリングがサポートされています。マルチホストシステムの GPU プロファイリングはサポートされていません。マルチワーカー GPU 構成のプロファイリングを行うには、各ワーカーを個別にプロファイルする必要があります。TensorFlow 2.4 より、tf.profiler.experimental.client.trace API を使って複数のワーカーをプロファイルすることが可能です。
CUDA® Toolkit 10.2 以降では、マルチ GPU のプロファイリングが必要です。TensorFlow 2.2 と 2.3 では、CUDA® Toolkit のバージョン 10.1 までをサポートしているため、libcudart.so.10.1 と libcupti.so.10.1 にシンボリックリンクを作成してください。
sudo ln -s /usr/local/cuda/lib64/libcudart.so.10.2 /usr/local/cuda/lib64/libcudart.so.10.1
sudo ln -s /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.2 /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.1