| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
genel bakış
Otomatik Konuşma Tanımadaki en büyük zorluklardan biri, ses verilerinin hazırlanması ve güçlendirilmesidir. Ses verisi analizi, görüntüler gibi diğer veri kaynaklarıyla karşılaştırıldığında ek karmaşıklık ekleyen zaman veya frekans alanında olabilir.
TensorFlow ekosistemin bir parçası olarak, tensorflow-io paket ses verilerinin hazırlanmasını ve büyütme hafifletilmesi yardımcı epeyce kullanışlı sesle ilgili API'ler sağlar.
Kurmak
Gerekli Paketleri kurun ve çalışma zamanını yeniden başlatın
pip install tensorflow-io
kullanım
Bir Ses Dosyasını Okuyun
TensorFlow IO olarak, sınıf tfio.audio.AudioIOTensor tembel yüklenmiş bir ses dosyası okumanızı sağlar IOTensor :
import tensorflow as tf
import tensorflow_io as tfio
audio = tfio.audio.AudioIOTensor('gs://cloud-samples-tests/speech/brooklyn.flac')
print(audio)
<AudioIOTensor: shape=[28979 1], dtype=<dtype: 'int16'>, rate=16000>
Yukarıdaki örnekte, FLAC dosya brooklyn.flac genel olarak erişilebilir ses klibi ila hakkında bulutu .
GCS adresi gs://cloud-samples-tests/speech/brooklyn.flac GCS TensorFlow desteklenen bir dosya sistemi olduğu için doğrudan kullanılmaktadır. Ek olarak Flac formatında, WAV , Ogg , MP3 , ve MP4A da desteklediği AudioIOTensor otomatik dosya biçimi algılama.
AudioIOTensor , bu nedenle sadece şekil yüklenen-yavaş d_type ve numune oranı, ilk olarak gösterilmiştir. Şekli AudioIOTensor olarak temsil edilir [samples, channels] Yüklediiniz ses klibi ile mono kanal olduğu anlamına gelir, 28979 numune int16 .
Gerektiğinde ses klibi içeriği yalnızca ya dönüştürerek okunacak AudioIOTensor için Tensor yoluyla to_tensor() veya dilimleme bile. Dilimleme, özellikle büyük bir ses klibinin yalnızca küçük bir kısmına ihtiyaç duyulduğunda kullanışlıdır:
audio_slice = audio[100:]
# remove last dimension
audio_tensor = tf.squeeze(audio_slice, axis=[-1])
print(audio_tensor)
tf.Tensor([16 39 66 ... 56 81 83], shape=(28879,), dtype=int16)
Ses şu yollarla çalınabilir:
from IPython.display import Audio
Audio(audio_tensor.numpy(), rate=audio.rate.numpy())
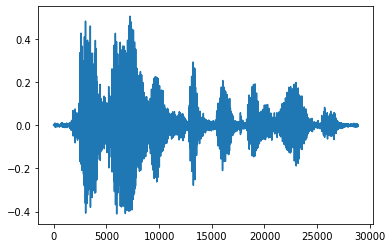
Tensörü kayan sayılara dönüştürmek ve ses klibini grafikte göstermek daha uygundur:
import matplotlib.pyplot as plt
tensor = tf.cast(audio_tensor, tf.float32) / 32768.0
plt.figure()
plt.plot(tensor.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd3eb72d0>]
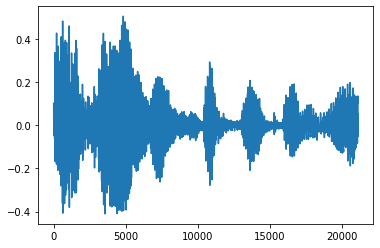
Gürültüyü kırp
Bazen API yoluyla yapılabilir ses, gürültü kesmek için mantıklı tfio.audio.trim . API döndü bir çift [start, stop] bölüt bir pozisyon:
position = tfio.audio.trim(tensor, axis=0, epsilon=0.1)
print(position)
start = position[0]
stop = position[1]
print(start, stop)
processed = tensor[start:stop]
plt.figure()
plt.plot(processed.numpy())
tf.Tensor([ 2398 23546], shape=(2,), dtype=int64) tf.Tensor(2398, shape=(), dtype=int64) tf.Tensor(23546, shape=(), dtype=int64) [<matplotlib.lines.Line2D at 0x7fbdd3dce9d0>]
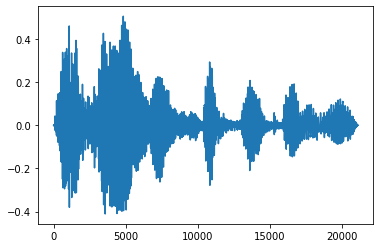
Solmaya ve Kararmaya
Yararlı bir ses mühendisliği tekniği, ses sinyallerini kademeli olarak artıran veya azaltan fadedir. Bu yoluyla yapılabilir tfio.audio.fade . tfio.audio.fade gibi Fades farklı şekillerini destekler linear , logarithmic veya exponential :
fade = tfio.audio.fade(
processed, fade_in=1000, fade_out=2000, mode="logarithmic")
plt.figure()
plt.plot(fade.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd00d9b10>]
Spektrogram
Gelişmiş ses işleme, genellikle zaman içindeki frekans değişiklikleri üzerinde çalışır. Gelen tensorflow-io bir dalga formu ile spektrogram dönüştürülebilir tfio.audio.spectrogram :
# Convert to spectrogram
spectrogram = tfio.audio.spectrogram(
fade, nfft=512, window=512, stride=256)
plt.figure()
plt.imshow(tf.math.log(spectrogram).numpy())
<matplotlib.image.AxesImage at 0x7fbdd005add0>
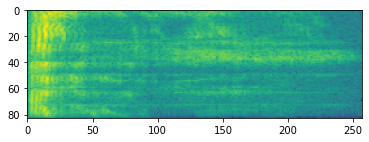
Farklı ölçeklere ek dönüşüm de mümkündür:
# Convert to mel-spectrogram
mel_spectrogram = tfio.audio.melscale(
spectrogram, rate=16000, mels=128, fmin=0, fmax=8000)
plt.figure()
plt.imshow(tf.math.log(mel_spectrogram).numpy())
# Convert to db scale mel-spectrogram
dbscale_mel_spectrogram = tfio.audio.dbscale(
mel_spectrogram, top_db=80)
plt.figure()
plt.imshow(dbscale_mel_spectrogram.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb20bd10>
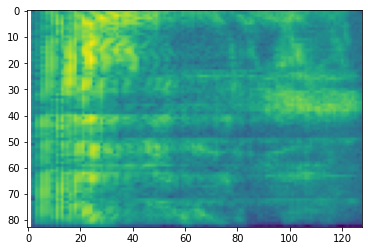
SpecAugment
Bahsedilen veri hazırlama ve büyütme API'leri üzerinde, ek olarak tensorflow-io paketi ayrıca gelişmiş spektrogram augmentations, özellikle Frekans sağlar ve saat maskeleme tartışılan SpecAugment: (. Park ve diğerleri, 2019) 'otomatik konuşma tanıma için basit bir veri Büyütme yöntem .
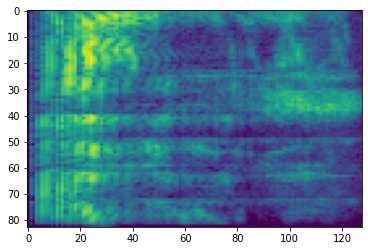
Frekans Maskeleme
Frekans maskeleme, frekans kanallarında [f0, f0 + f) burada maskelenmiş f gelen tek bir şekilde dağılımı seçilmesidir 0 parametre frekans maskeye F ve f0 arasından seçilir (0, ν − f) ν sayısıdır frekans kanalları.
# Freq masking
freq_mask = tfio.audio.freq_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(freq_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb155cd0>
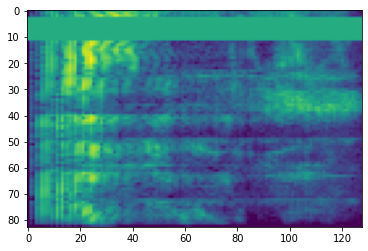
Zaman Maskeleme
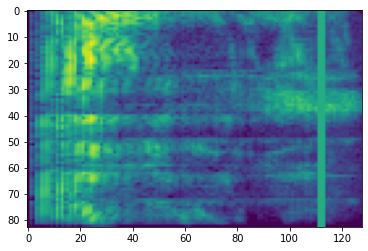
Zaman maskeleme olarak, t ardışık zaman adımları [t0, t0 + t) maskelenir t gelen tek bir şekilde dağılımı seçilmesidir 0 parametre zaman maskeye T ve t0 seçilmesidir [0, τ − t) τ olduğu zaman adımları.
# Time masking
time_mask = tfio.audio.time_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(time_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb0d9bd0>