在 GitHub 上查看源代码 在 GitHub 上查看源代码 |
概述
自动语音识别面临的最大挑战之一是音频数据的准备和增强。音频数据分析可能涉及时域或频域,与图像等其他数据源相比,这提高了复杂性。
作为 TensorFlow 生态系统的一部分,tensorflow-io 软件包提供了不少与音频相关的 API。这些 API 非常有用,可简化音频数据的准备和增强。
设置
安装要求的软件包,然后重新启动运行时
pip install tensorflow-io使用方法
读取音频文件
在 TensorFlow IO 中,利用类 tfio.audio.AudioIOTensor 可以将音频文件读取到延迟加载的 IOTensor 中:
import tensorflow as tf
import tensorflow_io as tfio
audio = tfio.audio.AudioIOTensor('gs://cloud-samples-tests/speech/brooklyn.flac')
print(audio)
2021-08-13 21:06:31.371935: W tensorflow_io/core/kernels/audio_video_mp3_kernels.cc:271] libmp3lame.so.0 or lame functions are not available 2021-08-13 21:06:31.372324: I tensorflow_io/core/kernels/cpu_check.cc:128] Your CPU supports instructions that this TensorFlow IO binary was not compiled to use: AVX2 AVX512F FMA 2021-08-13 21:06:32.108629: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2021-08-13 21:06:32.115449: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2021-08-13 21:06:32.116341: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2021-08-13 21:06:32.118294: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F FMA To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags. 2021-08-13 21:06:32.118864: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2021-08-13 21:06:32.119922: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2021-08-13 21:06:32.120789: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2021-08-13 21:06:32.712633: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2021-08-13 21:06:32.713583: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2021-08-13 21:06:32.714501: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2021-08-13 21:06:32.715324: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1510] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 14648 MB memory: -> device: 0, name: Tesla V100-SXM2-16GB, pci bus id: 0000:00:05.0, compute capability: 7.0 <AudioIOTensor: shape=[28979 1], dtype=<dtype: 'int16'>, rate=16000>
在上面的示例中,Flac 文件 brooklyn.flac 来自 Google Cloud 中可公开访问的音频片段。
示例中直接使用 GCS 地址 gs://cloud-samples-tests/speech/brooklyn.flac,因为 TensorFlow 支持 GCS 文件系统。除了 Flac 格式,凭借自动文件格式检测,AudioIOTensor 还支持 WAV、Ogg、MP3 和 MP4A 格式。
AudioIOTensor 是一个延迟加载张量,因此,刚开始只显示形状、dtype 和采样率。AudioIOTensor 的形状用 [samples, channels] 表示,这表示您加载的音频片段是单声道音频(int16 类型的 28979 个样本)。
仅需要时才会读取该音频片段的内容。要读取音频片段的内容,可通过 to_tensor() 将 AudioIOTensor 转换为 Tensor,也可以通过切片读取。如果只需要一个大音频片段的一小部分,切片尤其实用:
audio_slice = audio[100:]
# remove last dimension
audio_tensor = tf.squeeze(audio_slice, axis=[-1])
print(audio_tensor)
tf.Tensor([16 39 66 ... 56 81 83], shape=(28879,), dtype=int16)
音频可通过以下方式播放:
from IPython.display import Audio
Audio(audio_tensor.numpy(), rate=audio.rate.numpy())
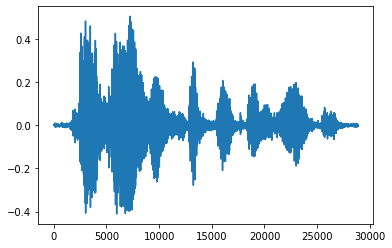
更方便的方式是,将张量转换为浮点数并在计算图中显示音频片段:
import matplotlib.pyplot as plt
tensor = tf.cast(audio_tensor, tf.float32) / 32768.0
plt.figure()
plt.plot(tensor.numpy())
[<matplotlib.lines.Line2D at 0x7f8950070710>]
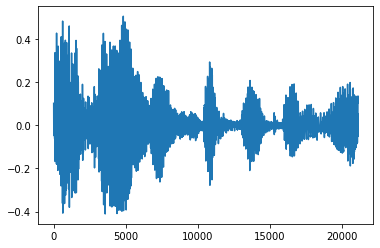
降噪
为音频降噪有时很有意义,这可以通过 API tfio.audio.trim 实现。从该 API 返回的是片段的一对 [start, stop] 位置:
position = tfio.audio.trim(tensor, axis=0, epsilon=0.1)
print(position)
start = position[0]
stop = position[1]
print(start, stop)
processed = tensor[start:stop]
plt.figure()
plt.plot(processed.numpy())
tf.Tensor([ 2398 23546], shape=(2,), dtype=int64) tf.Tensor(2398, shape=(), dtype=int64) tf.Tensor(23546, shape=(), dtype=int64) [<matplotlib.lines.Line2D at 0x7f893c4be050>]
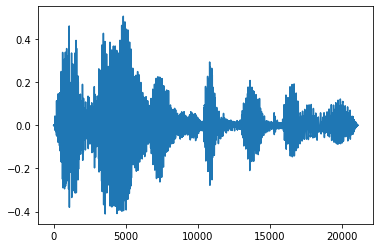
淡入和淡出
一种有用的音频工程技术是淡入淡出,也就是逐渐增强或减弱音频信号。这可以通过 tfio.audio.fade 实现。tfio.audio.fade 支持不同的淡入淡出形状,如 linear、logarithmic 或 exponential:
fade = tfio.audio.fade(
processed, fade_in=1000, fade_out=2000, mode="logarithmic")
plt.figure()
plt.plot(fade.numpy())
[<matplotlib.lines.Line2D at 0x7f893c43b1d0>]
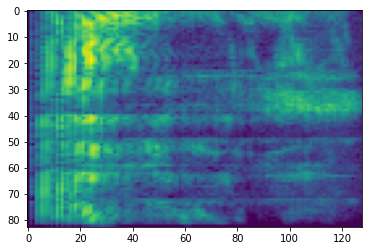
声谱图
高级音频处理通常需要根据时间调整音频频率。在 tensorflow-io 中,可通过 tfio.audio.spectrogram 将波形图转换为声谱图。
# Convert to spectrogram
spectrogram = tfio.audio.spectrogram(
fade, nfft=512, window=512, stride=256)
plt.figure()
plt.imshow(tf.math.log(spectrogram).numpy())
<matplotlib.image.AxesImage at 0x7f893c3ac690>
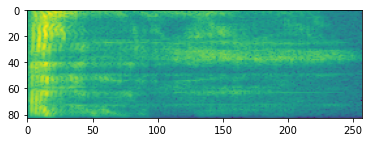
也可以转换为其他不同的比例:
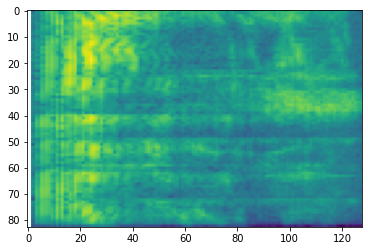
# Convert to mel-spectrogram
mel_spectrogram = tfio.audio.melscale(
spectrogram, rate=16000, mels=128, fmin=0, fmax=8000)
plt.figure()
plt.imshow(tf.math.log(mel_spectrogram).numpy())
# Convert to db scale mel-spectrogram
dbscale_mel_spectrogram = tfio.audio.dbscale(
mel_spectrogram, top_db=80)
plt.figure()
plt.imshow(dbscale_mel_spectrogram.numpy())
<matplotlib.image.AxesImage at 0x7f893c315350>
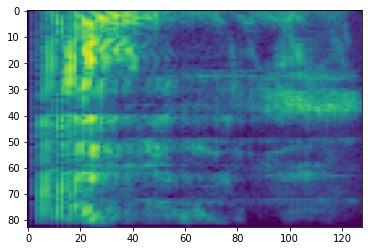
SpecAugment
除上述数据准备和增强 API 外,tensorflow-io 软件包还提供了高级声谱图增强,最主要的是在 SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition (Park et al., 2019) 中讨论的频率掩蔽和时间掩蔽。
频率掩蔽
在频率掩蔽中,对频率通道 [f0, f0 + f) 进行掩蔽,其中 f 选自从 0 到频率掩蔽参数 F 的均匀分布,而 f0 则选自 (0, ν − f),其中 ν 是频率通道的数量。
# Freq masking
freq_mask = tfio.audio.freq_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(freq_mask.numpy())
<matplotlib.image.AxesImage at 0x7f893c2c03d0>
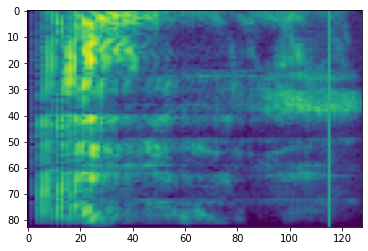
时间掩蔽
在时间掩蔽中,对 t 个连续时间步骤 [t0, t0 + t) 进行掩蔽,其中 t 选自从 0 到时间掩蔽参数 T 的均匀分布,而 t0 则选自 [0, τ − t),其中 τ 是时间步数。
# Time masking
time_mask = tfio.audio.time_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(time_mask.numpy())
<matplotlib.image.AxesImage at 0x7f893c256750>