
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Przegląd
Gotowe estymatory to szybkie i łatwe sposoby uczenia modeli TFL dla typowych przypadków użycia. W tym przewodniku przedstawiono kroki potrzebne do utworzenia estymatora w puszce TFL.
Ustawiać
Instalowanie pakietu TF Lattice:
pip install tensorflow-lattice
Importowanie wymaganych pakietów:
import tensorflow as tf
import copy
import logging
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
from tensorflow import feature_column as fc
logging.disable(sys.maxsize)
Pobieranie zbioru danych UCI Statlog (Heart):
csv_file = tf.keras.utils.get_file(
'heart.csv', 'http://storage.googleapis.com/download.tensorflow.org/data/heart.csv')
df = pd.read_csv(csv_file)
target = df.pop('target')
train_size = int(len(df) * 0.8)
train_x = df[:train_size]
train_y = target[:train_size]
test_x = df[train_size:]
test_y = target[train_size:]
df.head()
Ustawianie wartości domyślnych używanych do szkolenia w tym przewodniku:
LEARNING_RATE = 0.01
BATCH_SIZE = 128
NUM_EPOCHS = 500
PREFITTING_NUM_EPOCHS = 10
Kolumny funkcji
Jak dla każdego innego TF estymatora danych potrzeby być przekazane do estymatora, który jest zazwyczaj poprzez input_fn i analizowany za pomocą FeatureColumns .
# Feature columns.
# - age
# - sex
# - cp chest pain type (4 values)
# - trestbps resting blood pressure
# - chol serum cholestoral in mg/dl
# - fbs fasting blood sugar > 120 mg/dl
# - restecg resting electrocardiographic results (values 0,1,2)
# - thalach maximum heart rate achieved
# - exang exercise induced angina
# - oldpeak ST depression induced by exercise relative to rest
# - slope the slope of the peak exercise ST segment
# - ca number of major vessels (0-3) colored by flourosopy
# - thal 3 = normal; 6 = fixed defect; 7 = reversable defect
feature_columns = [
fc.numeric_column('age', default_value=-1),
fc.categorical_column_with_vocabulary_list('sex', [0, 1]),
fc.numeric_column('cp'),
fc.numeric_column('trestbps', default_value=-1),
fc.numeric_column('chol'),
fc.categorical_column_with_vocabulary_list('fbs', [0, 1]),
fc.categorical_column_with_vocabulary_list('restecg', [0, 1, 2]),
fc.numeric_column('thalach'),
fc.categorical_column_with_vocabulary_list('exang', [0, 1]),
fc.numeric_column('oldpeak'),
fc.categorical_column_with_vocabulary_list('slope', [0, 1, 2]),
fc.numeric_column('ca'),
fc.categorical_column_with_vocabulary_list(
'thal', ['normal', 'fixed', 'reversible']),
]
Gotowe estymatory TFL używają typu kolumny obiektów, aby zdecydować, jakiego typu warstwy kalibracyjnej użyć. Używamy tfl.layers.PWLCalibration warstwę dla kolumn numerycznych fabularnych i tfl.layers.CategoricalCalibration warstwę dla kategorycznych kolumn fabularnych.
Należy zauważyć, że kolumny elementów jakościowych nie są otoczone kolumną elementów osadzania. Są one bezpośrednio wprowadzane do estymatora.
Tworzenie input_fn
Podobnie jak w przypadku każdego innego estymatora, możesz użyć input_fn, aby przekazać dane do modelu w celu uczenia i oceny. Estymatory TFL mogą automatycznie obliczać kwantyle cech i używać ich jako kluczowych punktów wejściowych dla warstwy kalibracji PWL. Aby to zrobić, one wymagają podjęcia feature_analysis_input_fn , który jest podobny do treningu input_fn ale z jednym epoki lub podgrupę danych.
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=train_x,
y=train_y,
shuffle=False,
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
num_threads=1)
# feature_analysis_input_fn is used to collect statistics about the input.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=train_x,
y=train_y,
shuffle=False,
batch_size=BATCH_SIZE,
# Note that we only need one pass over the data.
num_epochs=1,
num_threads=1)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=test_x,
y=test_y,
shuffle=False,
batch_size=BATCH_SIZE,
num_epochs=1,
num_threads=1)
# Serving input fn is used to create saved models.
serving_input_fn = (
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=fc.make_parse_example_spec(feature_columns)))
Konfiguracje funkcji
Funkcja kalibracji i konfiguracji per-feature są ustawiane za pomocą tfl.configs.FeatureConfig . Konfiguracje funkcji zawiera ograniczenia monotoniczności, uregulowania per-funkcji (patrz tfl.configs.RegularizerConfig ) i rozmiary kratowe dla modeli sieciowych.
Jeśli konfiguracja nie jest określona dla funkcji wejściowej, domyślna konfiguracja w tfl.config.FeatureConfig służy.
# Feature configs are used to specify how each feature is calibrated and used.
feature_configs = [
tfl.configs.FeatureConfig(
name='age',
lattice_size=3,
# By default, input keypoints of pwl are quantiles of the feature.
pwl_calibration_num_keypoints=5,
monotonicity='increasing',
pwl_calibration_clip_max=100,
# Per feature regularization.
regularizer_configs=[
tfl.configs.RegularizerConfig(name='calib_wrinkle', l2=0.1),
],
),
tfl.configs.FeatureConfig(
name='cp',
pwl_calibration_num_keypoints=4,
# Keypoints can be uniformly spaced.
pwl_calibration_input_keypoints='uniform',
monotonicity='increasing',
),
tfl.configs.FeatureConfig(
name='chol',
# Explicit input keypoint initialization.
pwl_calibration_input_keypoints=[126.0, 210.0, 247.0, 286.0, 564.0],
monotonicity='increasing',
# Calibration can be forced to span the full output range by clamping.
pwl_calibration_clamp_min=True,
pwl_calibration_clamp_max=True,
# Per feature regularization.
regularizer_configs=[
tfl.configs.RegularizerConfig(name='calib_hessian', l2=1e-4),
],
),
tfl.configs.FeatureConfig(
name='fbs',
# Partial monotonicity: output(0) <= output(1)
monotonicity=[(0, 1)],
),
tfl.configs.FeatureConfig(
name='trestbps',
pwl_calibration_num_keypoints=5,
monotonicity='decreasing',
),
tfl.configs.FeatureConfig(
name='thalach',
pwl_calibration_num_keypoints=5,
monotonicity='decreasing',
),
tfl.configs.FeatureConfig(
name='restecg',
# Partial monotonicity: output(0) <= output(1), output(0) <= output(2)
monotonicity=[(0, 1), (0, 2)],
),
tfl.configs.FeatureConfig(
name='exang',
# Partial monotonicity: output(0) <= output(1)
monotonicity=[(0, 1)],
),
tfl.configs.FeatureConfig(
name='oldpeak',
pwl_calibration_num_keypoints=5,
monotonicity='increasing',
),
tfl.configs.FeatureConfig(
name='slope',
# Partial monotonicity: output(0) <= output(1), output(1) <= output(2)
monotonicity=[(0, 1), (1, 2)],
),
tfl.configs.FeatureConfig(
name='ca',
pwl_calibration_num_keypoints=4,
monotonicity='increasing',
),
tfl.configs.FeatureConfig(
name='thal',
# Partial monotonicity:
# output(normal) <= output(fixed)
# output(normal) <= output(reversible)
monotonicity=[('normal', 'fixed'), ('normal', 'reversible')],
),
]
Skalibrowany model liniowy
Skonstruować TFL puszkach estymator skonstruować konfiguracji modelu z tfl.configs . Kalibrowany model liniowy zbudowany jest przy użyciu tfl.configs.CalibratedLinearConfig . Stosuje kalibrację odcinkowo liniową i kategoryczną dla cech wejściowych, a następnie kombinację liniową i opcjonalną wyjściową kalibrację odcinkowo-liniową. Podczas korzystania z kalibracji wyjściowej lub gdy określone są granice wyjściowe, warstwa liniowa zastosuje uśrednienie ważone na skalibrowanych danych wejściowych.
Ten przykład tworzy skalibrowany model liniowy na pierwszych 5 obiektach. Używamy tfl.visualization wykreślić wykres modelu z działek kalibratora.
# Model config defines the model structure for the estimator.
model_config = tfl.configs.CalibratedLinearConfig(
feature_configs=feature_configs,
use_bias=True,
output_calibration=True,
regularizer_configs=[
# Regularizer for the output calibrator.
tfl.configs.RegularizerConfig(name='output_calib_hessian', l2=1e-4),
])
# A CannedClassifier is constructed from the given model config.
estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns[:5],
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42))
estimator.train(input_fn=train_input_fn)
results = estimator.evaluate(input_fn=test_input_fn)
print('Calibrated linear test AUC: {}'.format(results['auc']))
saved_model_path = estimator.export_saved_model(estimator.model_dir,
serving_input_fn)
model_graph = tfl.estimators.get_model_graph(saved_model_path)
tfl.visualization.draw_model_graph(model_graph)
2021-09-30 20:54:06.660239: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected Calibrated linear test AUC: 0.834586501121521
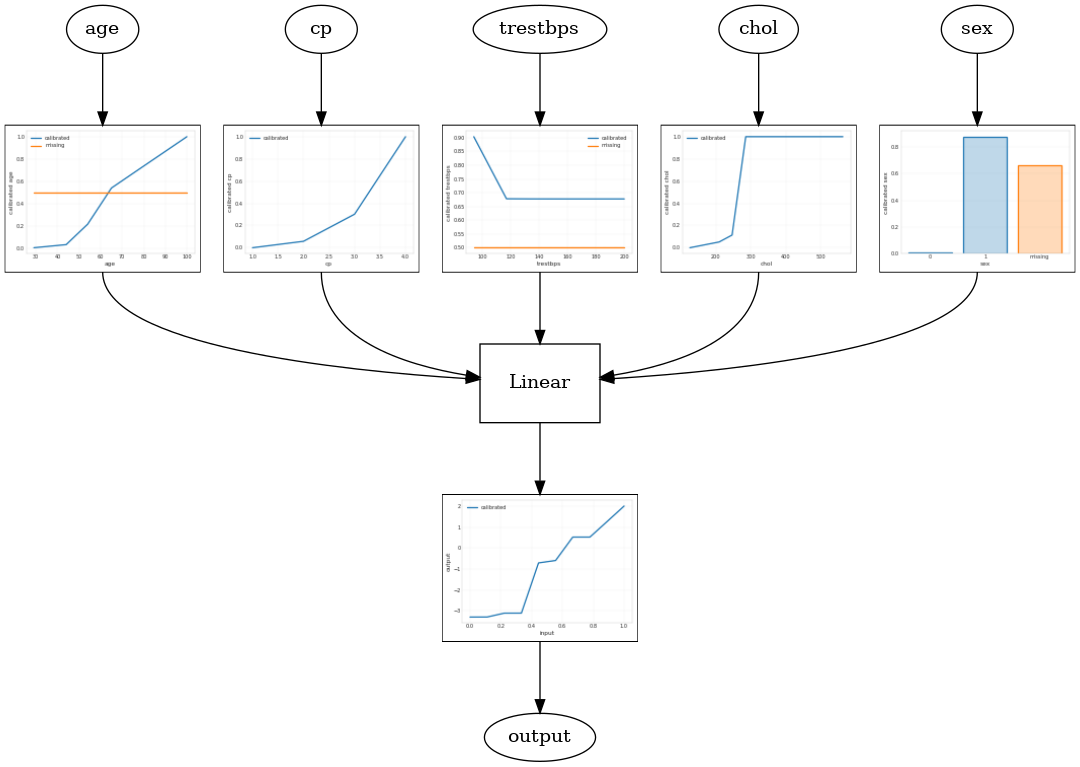
Skalibrowany model kraty
Kalibrowany kraty model jest wykonana przy użyciu tfl.configs.CalibratedLatticeConfig . Skalibrowany model sieci stosuje kalibrację odcinkowo liniową i kategoryczną na cechach wejściowych, a następnie model sieciowy i opcjonalną kalibrację odcinkowo liniową wyjściową.
Ten przykład tworzy skalibrowany model sieci na pierwszych 5 cechach.
# This is calibrated lattice model: Inputs are calibrated, then combined
# non-linearly using a lattice layer.
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=feature_configs,
regularizer_configs=[
# Torsion regularizer applied to the lattice to make it more linear.
tfl.configs.RegularizerConfig(name='torsion', l2=1e-4),
# Globally defined calibration regularizer is applied to all features.
tfl.configs.RegularizerConfig(name='calib_hessian', l2=1e-4),
])
# A CannedClassifier is constructed from the given model config.
estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns[:5],
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42))
estimator.train(input_fn=train_input_fn)
results = estimator.evaluate(input_fn=test_input_fn)
print('Calibrated lattice test AUC: {}'.format(results['auc']))
saved_model_path = estimator.export_saved_model(estimator.model_dir,
serving_input_fn)
model_graph = tfl.estimators.get_model_graph(saved_model_path)
tfl.visualization.draw_model_graph(model_graph)
Calibrated lattice test AUC: 0.8427318930625916
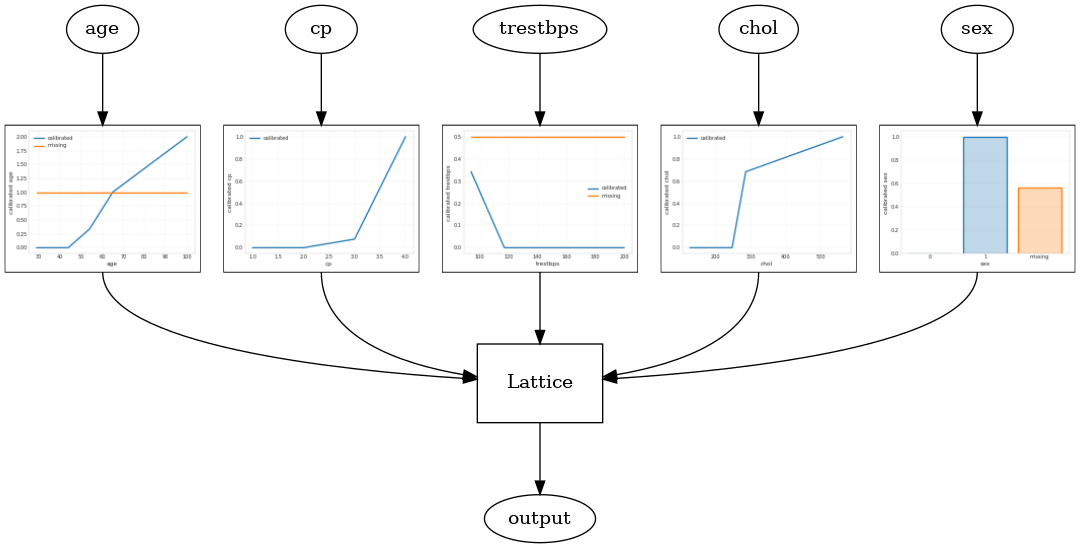
Skalibrowany zespół kratowy
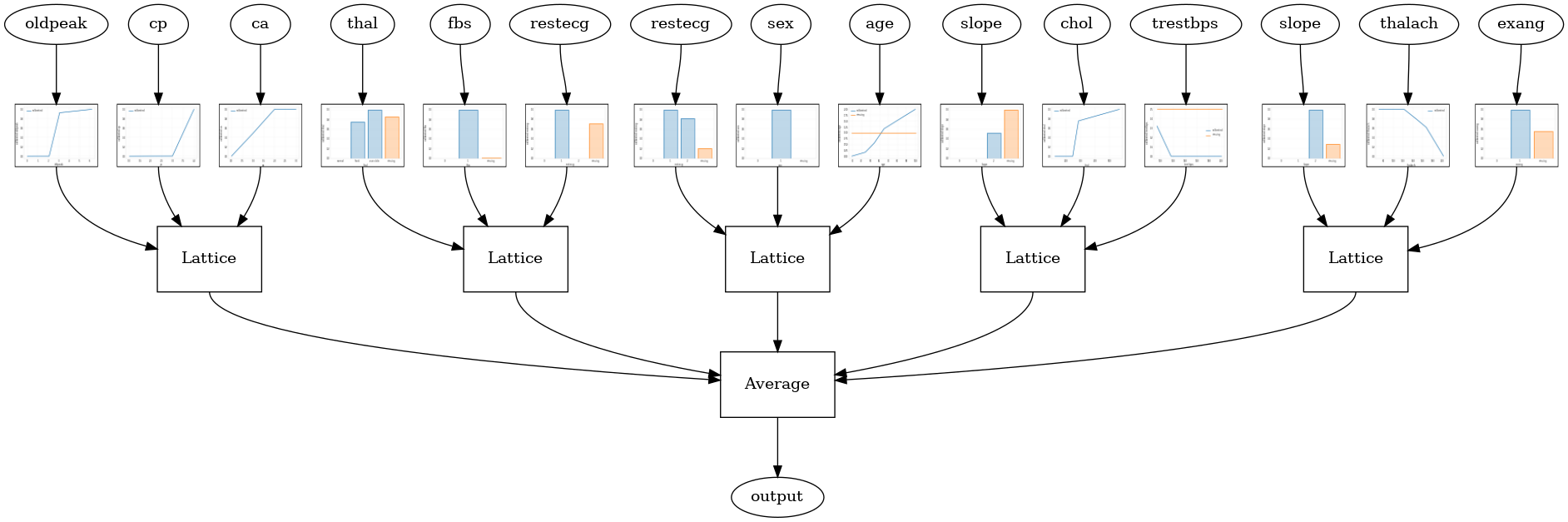
Gdy liczba funkcji jest duża, można użyć modelu zespołowego, który tworzy wiele mniejszych sieci dla podzbiorów funkcji i uśrednia ich wyniki zamiast tworzyć tylko jedną ogromną sieć. Muzycy modele kratowe są skonstruowane przy użyciu tfl.configs.CalibratedLatticeEnsembleConfig . Skalibrowany model sieciowy stosuje kalibrację odcinkowo liniową i kategoryczną na obiekcie wejściowym, a następnie zespół modeli sieci i opcjonalną kalibrację odcinkowo liniową wyjściową.
Losowy zespół kratowy
Poniższa konfiguracja modelu używa losowego podzbioru funkcji dla każdej sieci.
# This is random lattice ensemble model with separate calibration:
# model output is the average output of separately calibrated lattices.
model_config = tfl.configs.CalibratedLatticeEnsembleConfig(
feature_configs=feature_configs,
num_lattices=5,
lattice_rank=3)
# A CannedClassifier is constructed from the given model config.
estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42))
estimator.train(input_fn=train_input_fn)
results = estimator.evaluate(input_fn=test_input_fn)
print('Random ensemble test AUC: {}'.format(results['auc']))
saved_model_path = estimator.export_saved_model(estimator.model_dir,
serving_input_fn)
model_graph = tfl.estimators.get_model_graph(saved_model_path)
tfl.visualization.draw_model_graph(model_graph, calibrator_dpi=15)
Random ensemble test AUC: 0.9003759026527405
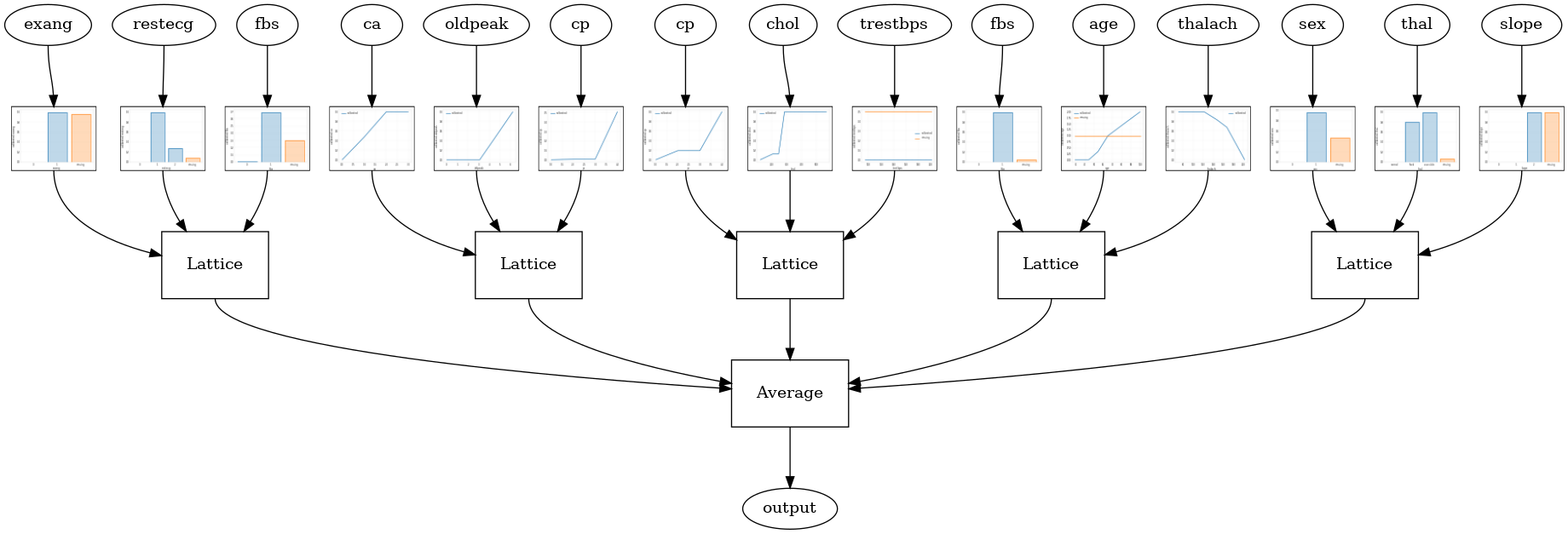
RTL Layer Random Lattice Ensemble
Następujący model konfiguracji wykorzystuje tfl.layers.RTL warstwę używa losowego podzbioru funkcji dla każdej kraty. Zauważmy, że tfl.layers.RTL obsługuje tylko ograniczenia monotoniczności i muszą mieć ten sam rozmiar siatki dla wszystkich funkcji i nie uregulowania per-feature. Należy pamiętać, że stosując tfl.layers.RTL warstwę pozwala skalować do znacznie większych niż przy użyciu oddzielnych zespołów tfl.layers.Lattice instancji.
# Make sure our feature configs have the same lattice size, no per-feature
# regularization, and only monotonicity constraints.
rtl_layer_feature_configs = copy.deepcopy(feature_configs)
for feature_config in rtl_layer_feature_configs:
feature_config.lattice_size = 2
feature_config.unimodality = 'none'
feature_config.reflects_trust_in = None
feature_config.dominates = None
feature_config.regularizer_configs = None
# This is RTL layer ensemble model with separate calibration:
# model output is the average output of separately calibrated lattices.
model_config = tfl.configs.CalibratedLatticeEnsembleConfig(
lattices='rtl_layer',
feature_configs=rtl_layer_feature_configs,
num_lattices=5,
lattice_rank=3)
# A CannedClassifier is constructed from the given model config.
estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42))
estimator.train(input_fn=train_input_fn)
results = estimator.evaluate(input_fn=test_input_fn)
print('Random ensemble test AUC: {}'.format(results['auc']))
saved_model_path = estimator.export_saved_model(estimator.model_dir,
serving_input_fn)
model_graph = tfl.estimators.get_model_graph(saved_model_path)
tfl.visualization.draw_model_graph(model_graph, calibrator_dpi=15)
Random ensemble test AUC: 0.8903509378433228
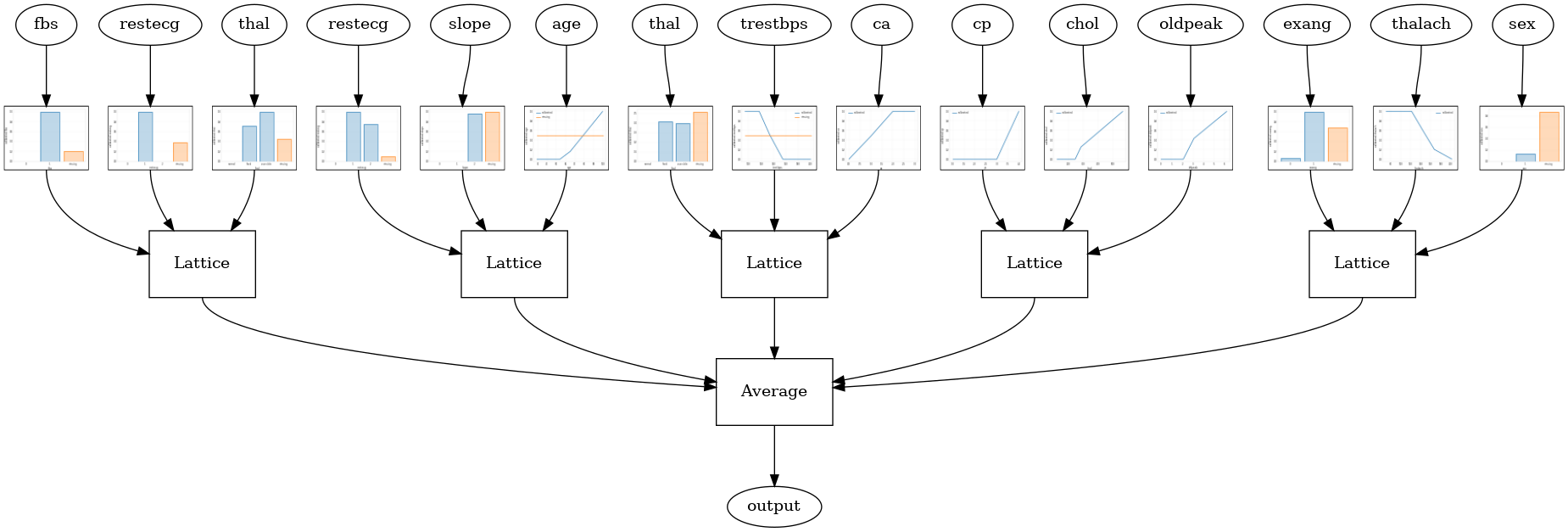
Kryształowy zespół kratowy
TFL zapewnia również algorytm heurystyczny aranżacji funkcja o nazwie Crystals . Kryształy pierwszego algorytmu pociągów prefitting model, który szacunki parami interakcje fabularnych. Następnie układa ostateczny zespół w taki sposób, aby elementy o bardziej nieliniowych interakcjach znajdowały się w tych samych sieciach.
Dla modeli kryształów, będzie trzeba także zapewnić prefitting_input_fn , który jest używany do szkolenia model prefitting, jak opisano powyżej. Model wstępnego dopasowania nie musi być w pełni przeszkolony, więc kilka epok powinno wystarczyć.
prefitting_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=train_x,
y=train_y,
shuffle=False,
batch_size=BATCH_SIZE,
num_epochs=PREFITTING_NUM_EPOCHS,
num_threads=1)
Następnie można utworzyć model Crystal od ustawiania lattice='crystals' w modelu config.
# This is Crystals ensemble model with separate calibration: model output is
# the average output of separately calibrated lattices.
model_config = tfl.configs.CalibratedLatticeEnsembleConfig(
feature_configs=feature_configs,
lattices='crystals',
num_lattices=5,
lattice_rank=3)
# A CannedClassifier is constructed from the given model config.
estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
# prefitting_input_fn is required to train the prefitting model.
prefitting_input_fn=prefitting_input_fn,
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
prefitting_optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42))
estimator.train(input_fn=train_input_fn)
results = estimator.evaluate(input_fn=test_input_fn)
print('Crystals ensemble test AUC: {}'.format(results['auc']))
saved_model_path = estimator.export_saved_model(estimator.model_dir,
serving_input_fn)
model_graph = tfl.estimators.get_model_graph(saved_model_path)
tfl.visualization.draw_model_graph(model_graph, calibrator_dpi=15)
Crystals ensemble test AUC: 0.8840851783752441
Można wykreślić kalibratory fabularnych z większą ilością szczegółów przy użyciu tfl.visualization moduł.
_ = tfl.visualization.plot_feature_calibrator(model_graph, "age")
_ = tfl.visualization.plot_feature_calibrator(model_graph, "restecg")

