
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Przegląd
Ten samouczek jest przeglądem ograniczeń i regulatorów zapewnianych przez bibliotekę TensorFlow Lattice (TFL). Tutaj używamy gotowych estymatorów TFL na syntetycznych zestawach danych, ale zauważ, że wszystko w tym samouczku można również zrobić z modelami zbudowanymi z warstw TFL Keras.
Przed kontynuowaniem upewnij się, że środowisko wykonawcze ma zainstalowane wszystkie wymagane pakiety (zaimportowane w komórkach kodu poniżej).
Ustawiać
Instalowanie pakietu TF Lattice:
pip install -q tensorflow-lattice
Importowanie wymaganych pakietów:
import tensorflow as tf
from IPython.core.pylabtools import figsize
import itertools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
Wartości domyślne używane w tym przewodniku:
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
Zbiór danych szkoleniowych dla rankingowych restauracji
Wyobraźmy sobie uproszczony scenariusz, w którym chcemy określić, czy użytkownicy klikną wynik wyszukiwania restauracji. Zadaniem jest przewidzenie współczynnika klikalności (CTR) przy danych cechach wejściowych:
- Średnia ocena (
avg_rating) liczbowy funkcji o wartościach w zakresie [1,5]. - Ilość opinii (
num_reviews): numeryczny funkcja o wartościach ograniczona do 200, który używamy jako miara trendiness. - Ocena dolara (
dollar_rating): kategoryczne cecha z ciągów znaków w zbiorze { "D", "DD", "DDD", "dddd"}.
Tutaj tworzymy syntetyczny zbiór danych, w którym prawdziwy CTR jest określony wzorem:
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
gdzie \(b(\cdot)\) przekształca każdy dollar_rating do wartości odniesienia:
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
Ta formuła odzwierciedla typowe wzorce użytkowników. np. biorąc pod uwagę wszystko inne, użytkownicy wolą restauracje z wyższą liczbą gwiazdek, a restauracje „\$\$” otrzymają więcej kliknięć niż „\$”, a następnie „\$\$\$” i „\$\$\$ \$".
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
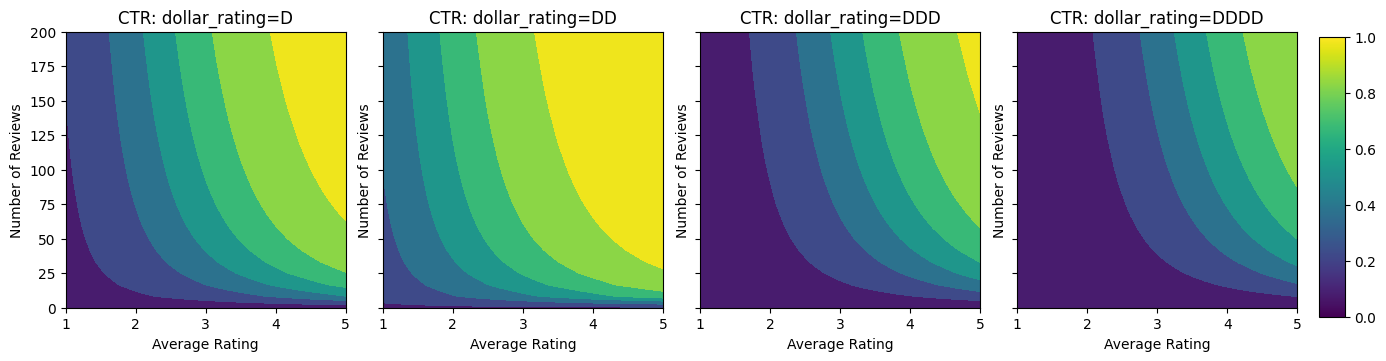
Przyjrzyjmy się wykresom konturowym tej funkcji CTR.
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, split_by_dollar=False, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
if split_by_dollar:
dollar_rating_splits = ["D", "DD", "DDD", "DDDD"]
else:
dollar_rating_splits = [None]
if len(fns) == 1:
fig, axes = plt.subplots(2, 2, sharey=True, tight_layout=False)
else:
fig, axes = plt.subplots(
len(dollar_rating_splits), len(fns), sharey=True, tight_layout=False)
axes = axes.flatten()
axes_index = 0
for dollar_rating_split in dollar_rating_splits:
for title, fn in fns:
if dollar_rating_split is not None:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(),
dollar_ratings)
title = "{}: dollar_rating={}".format(title, dollar_rating_split)
else:
values = fn(avg_ratings.flatten(), num_reviews.flatten())
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
figsize(11, 11)
plot_fns([("CTR", click_through_rate)], split_by_dollar=True)
Przygotowywanie danych
Teraz musimy stworzyć nasze syntetyczne zbiory danych. Zaczynamy od wygenerowania symulowanego zbioru danych restauracji i ich funkcji.
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(["D", "DD", "DDD", "DDDD"], n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, tight_layout=False)
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
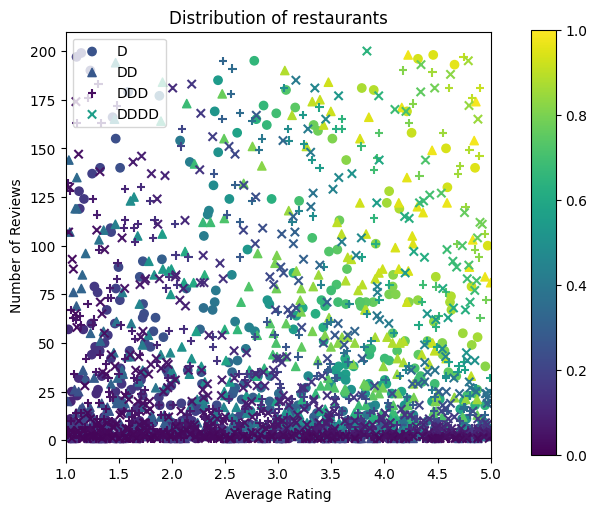
Stwórzmy zestawy danych treningowych, walidacyjnych i testowych. Gdy restauracja jest wyświetlana w wynikach wyszukiwania, możemy zarejestrować zaangażowanie użytkownika (kliknięcie lub brak kliknięcia) jako punkt próbny.
W praktyce użytkownicy często nie przeglądają wszystkich wyników wyszukiwania. Oznacza to, że użytkownicy prawdopodobnie zobaczą tylko restauracje, które są już uważane za „dobre” według obecnego modelu rankingu. W rezultacie „dobre” restauracje są częściej pod wrażeniem i nadreprezentowane w zestawach danych szkoleniowych. W przypadku korzystania z większej liczby funkcji treningowy zestaw danych może mieć duże luki w „złych” częściach przestrzeni funkcji.
Gdy model jest używany do rankingu, często jest oceniany na wszystkich odpowiednich wynikach z bardziej jednorodnym rozkładem, który nie jest dobrze reprezentowany przez zestaw danych uczących. Elastyczny i skomplikowany model może w tym przypadku zawieść z powodu nadmiernego dopasowania nadmiernie reprezentowanych punktów danych, a tym samym braku możliwości uogólnienia. Załatwiamy ten problem przez zastosowanie wiedzy domeny, aby dodać ograniczenia kształt, który poprowadzi model, aby podjąć odpowiednie prognozy, gdy nie można je odebrać ze zbioru danych szkolenia.
W tym przykładzie zestaw danych szkoleniowych składa się głównie z interakcji użytkownika z dobrymi i popularnymi restauracjami. Testowy zestaw danych ma jednolity rozkład, aby symulować omówione powyżej ustawienie oceny. Należy pamiętać, że taki zestaw danych testowych nie będzie dostępny w przypadku rzeczywistego problemu.
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views))
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [(axs[0], data_train, "training"),
(axs[1], data_test, "testing")]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
density=True,
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)

Definiowanie input_fns używane do szkolenia i oceny:
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
shuffle=False,
)
# feature_analysis_input_fn is used for TF Lattice estimators.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
val_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_val,
y=data_val["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_test,
y=data_test["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
Dopasowywanie drzew wzmocnionych gradientem
Zacznijmy od z zaledwie dwóch cech: avg_rating i num_reviews .
Tworzymy kilka funkcji pomocniczych do wykreślania i obliczania metryk walidacji i testów.
def analyze_two_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def two_d_pred(avg_ratings, num_reviews):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
def two_d_click_through_rate(avg_ratings, num_reviews):
return np.mean([
click_through_rate(avg_ratings, num_reviews,
np.repeat(d, len(avg_ratings)))
for d in ["D", "DD", "DDD", "DDDD"]
],
axis=0)
figsize(11, 5)
plot_fns([("{} Estimated CTR".format(name), two_d_pred),
("CTR", two_d_click_through_rate)],
split_by_dollar=False)
Możemy dopasować drzewa decyzyjne wzmocnione gradientem TensorFlow do zbioru danych:
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
gbt_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
n_batches_per_layer=1,
max_depth=2,
n_trees=50,
learning_rate=0.05,
config=tf.estimator.RunConfig(tf_random_seed=42),
)
gbt_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(gbt_estimator, "GBT")
Validation AUC: 0.6333084106445312 Testing AUC: 0.774649977684021

Mimo że model uchwycił ogólny kształt prawdziwego CTR i ma przyzwoite metryki walidacji, zachowuje się on w sposób sprzeczny z intuicją w kilku częściach przestrzeni wejściowej: szacowany CTR zmniejsza się wraz ze wzrostem średniej oceny lub liczby recenzji. Wynika to z braku punktów próbkowania w obszarach, które nie są dobrze objęte zbiorem danych uczących. Model po prostu nie ma możliwości wywnioskowania prawidłowego zachowania wyłącznie z danych.
Aby rozwiązać ten problem, wymuszamy ograniczenie kształtu, zgodnie z którym model musi wyprowadzać wartości monotonicznie rosnące zarówno względem średniej oceny, jak i liczby recenzji. Później zobaczymy, jak to zaimplementować w TFL.
Dopasowanie DNN
Możemy powtórzyć te same kroki z klasyfikatorem DNN. Możemy zaobserwować podobny wzorzec: brak wystarczającej liczby punktów próbnych przy małej liczbie przeglądów skutkuje bezsensowną ekstrapolacją. Należy zauważyć, że chociaż metryka walidacji jest lepsza niż rozwiązanie drzewa, metryka testowania jest znacznie gorsza.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
hidden_units=[16, 8, 8],
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
dnn_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(dnn_estimator, "DNN")
Validation AUC: 0.6696228981018066 Testing AUC: 0.750156044960022

Ograniczenia kształtu
TensorFlow Lattice (TFL) koncentruje się na wymuszaniu ograniczeń kształtu w celu ochrony zachowania modelu poza danymi uczącymi. Te ograniczenia kształtu są stosowane do warstw TFL Keras. Ich dane można znaleźć w naszym artykule JMLR .
W tym samouczku używamy gotowych estymatorów TF, aby pokryć różne ograniczenia kształtu, ale zauważ, że wszystkie te kroki można wykonać z modelami utworzonymi z warstw TFL Keras.
Podobnie jak w przypadku każdej innej TensorFlow estymatora, TFL puszkach estymatory użyciu kolumny funkcji do definiowania formatu wejściowego i użyć input_fn szkolenia przechodzą w danych. Korzystanie z gotowych estymatorów TFL wymaga również:
- model config: zdefiniowanie modelu architektury i ograniczenia oraz regularizers kształt per-feature.
- input_fn analiza cecha: TF input_fn przekazywanie danych dla TSL inicjalizacji.
Bardziej szczegółowy opis można znaleźć w samouczku dotyczącym gotowych estymatorów lub w dokumentacji interfejsu API.
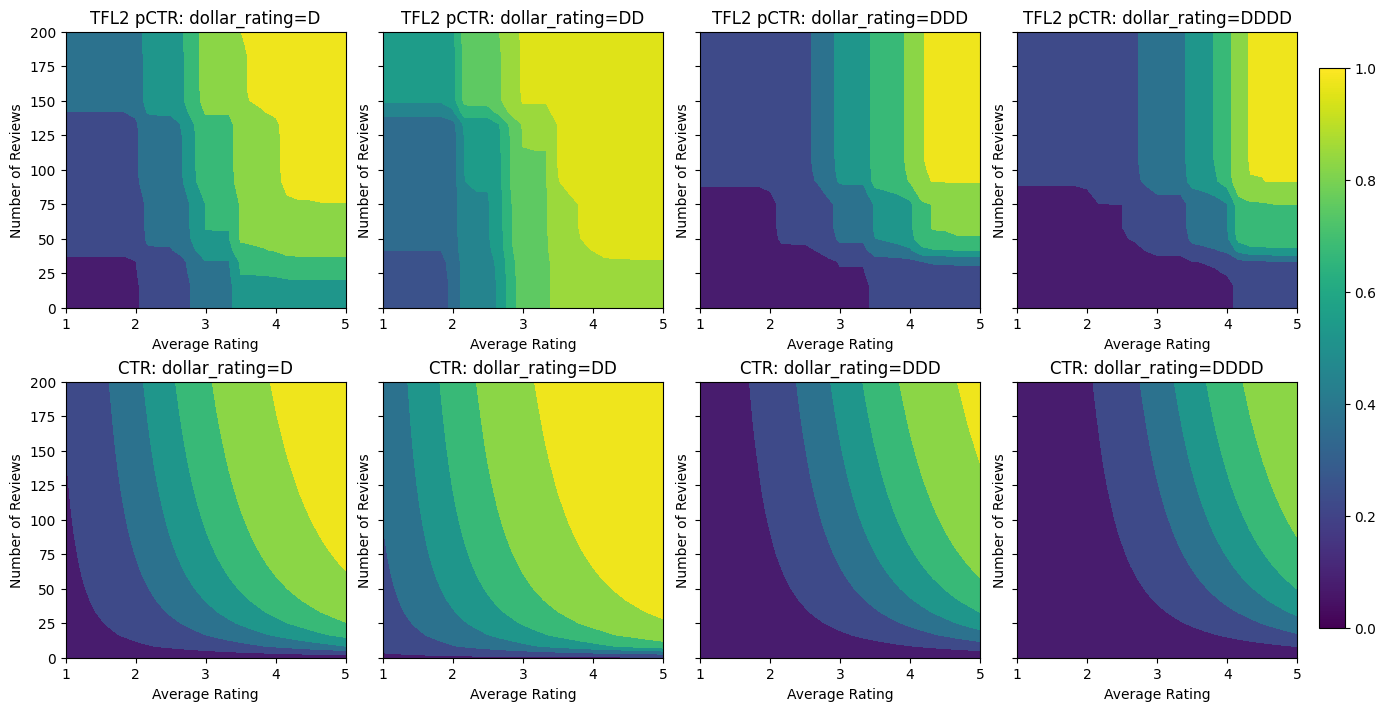
Monotoniczność
Najpierw zajmiemy się problemami monotoniczności, dodając ograniczenia kształtu monotoniczności do obu funkcji.
Pouczać TFL egzekwować ograniczenia kształtu, możemy określić okrojone w configs fabularnych. Poniżej przedstawiono kod jak możemy wymagać wyjście być monotonicznie rosnącą w stosunku do obu num_reviews i avg_rating ustawiając monotonicity="increasing" .
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
Validation AUC: 0.6565533876419067 Testing AUC: 0.7784258723258972

Używanie CalibratedLatticeConfig tworzy puszkowanej klasyfikatora, że najpierw stosuje się kalibrator do każdego wejścia (kawałek mądry funkcją liniową w funkcji numeryczne), a następnie warstwy kratowej do nieliniowo bezpiecznika kalibrowanych funkcji. Możemy użyć tfl.visualization wizualizację modelu. W szczególności poniższy wykres przedstawia dwa wytrenowane kalibratory zawarte w klasyfikatorze w puszkach.
def save_and_visualize_lattice(tfl_estimator):
saved_model_path = tfl_estimator.export_saved_model(
"/tmp/TensorFlow_Lattice_101/",
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=tf.feature_column.make_parse_example_spec(
feature_columns)))
model_graph = tfl.estimators.get_model_graph(saved_model_path)
figsize(8, 8)
tfl.visualization.draw_model_graph(model_graph)
return model_graph
_ = save_and_visualize_lattice(tfl_estimator)

Po dodaniu ograniczeń szacowany CTR będzie zawsze wzrastał wraz ze wzrostem średniej oceny lub liczby recenzji. Odbywa się to poprzez upewnienie się, że kalibratory i siatka są monotoniczne.
Malejące zwroty
Malejących przychodów oznacza, że krańcowy przyrost zwiększenia pewną wartość funkcji zmniejszy się jak zwiększyć wartość. W naszym przypadku możemy spodziewać się, że num_reviews cecha zachowuje ten wzór, dzięki czemu możemy skonfigurować jego kalibrator odpowiednio. Zauważ, że malejące zwroty możemy rozłożyć na dwa wystarczające warunki:
- kalibrator wzrasta monotonicznie i
- kalibrator jest wklęsły.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891247272491455
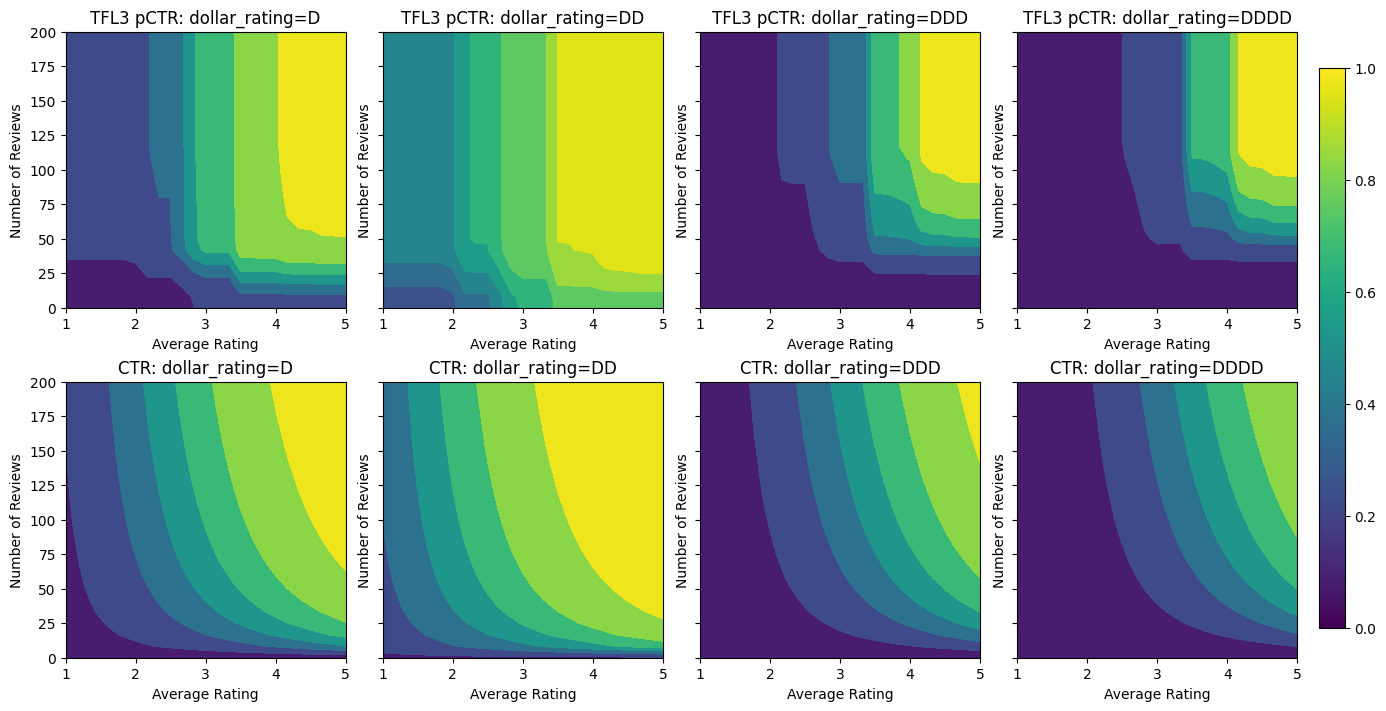

Zwróć uwagę, jak poprawia się metryka testowa, dodając wiązanie wklęsłości. Fabuła przewidywania również lepiej przypomina podstawową prawdę.
Ograniczenie kształtu 2D: Zaufanie
5-gwiazdkowa ocena restauracji, która ma tylko jedną lub dwie recenzje, jest prawdopodobnie niewiarygodną oceną (w rzeczywistości restauracja może nie być dobra), podczas gdy 4-gwiazdkowa ocena restauracji z setkami recenzji jest znacznie bardziej wiarygodna (restauracja jest prawdopodobnie dobre w tym przypadku). Widzimy, że liczba recenzji restauracji wpływa na to, jak duże zaufanie pokładamy w jej średniej ocenie.
Możemy zastosować ograniczenia zaufania TFL, aby poinformować model, że większa (lub mniejsza) wartość jednej cechy wskazuje na większe zaufanie lub zaufanie do innej cechy. Odbywa się to poprzez ustawienie reflects_trust_in konfiguracji w konfiguracji funkcji.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
model_graph = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891043424606323

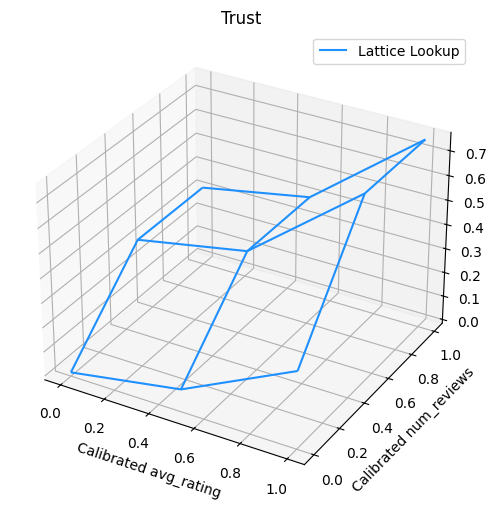
Poniższy wykres przedstawia wytrenowaną funkcję kraty. Ze względu na ograniczenie zaufania, oczekujemy, że większe wartości kalibrowanych num_reviews zmusi wyższe nachylenie względem skalibrowanego avg_rating , co skutkuje bardziej znaczący ruch na wyjściu siatkowej.
lat_mesh_n = 12
lat_mesh_x, lat_mesh_y = tfl.test_utils.two_dim_mesh_grid(
lat_mesh_n**2, 0, 0, 1, 1)
lat_mesh_fn = tfl.test_utils.get_hypercube_interpolation_fn(
model_graph.output_node.weights.flatten())
lat_mesh_z = [
lat_mesh_fn([lat_mesh_x.flatten()[i],
lat_mesh_y.flatten()[i]]) for i in range(lat_mesh_n**2)
]
trust_plt = tfl.visualization.plot_outputs(
(lat_mesh_x, lat_mesh_y),
{"Lattice Lookup": lat_mesh_z},
figsize=(6, 6),
)
trust_plt.title("Trust")
trust_plt.xlabel("Calibrated avg_rating")
trust_plt.ylabel("Calibrated num_reviews")
trust_plt.show()
Kalibratory wygładzające
Załóżmy teraz przyjrzeć kalibratora z avg_rating . Choć monotonicznie wzrasta, zmiany jego zboczy są gwałtowne i trudne do zinterpretowania. Sugeruje, że możemy rozważyć wygładzenie ten kalibrator używając ustawień regularizer w regularizer_configs .
Tutaj stosujemy wrinkle regularizer zmniejszyć zmiany krzywizny. Można również użyć laplacian regularizer spłaszczyć kalibratora i hessian regularizer aby uczynić go bardziej liniowa.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6465646028518677 Testing AUC: 0.7948372960090637


Kalibratory działają teraz płynnie, a ogólny szacowany CTR lepiej odpowiada rzeczywistości. Znajduje to odzwierciedlenie zarówno w metryce testowej, jak i na wykresach konturowych.
Częściowa monotoniczność dla kalibracji kategorycznej
Do tej pory w modelu używaliśmy tylko dwóch funkcji numerycznych. Tutaj dodamy trzecią funkcję za pomocą kategorycznej warstwy kalibracyjnej. Ponownie zaczynamy od skonfigurowania funkcji pomocniczych do kreślenia i obliczania metryk.
def analyze_three_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def three_d_pred(avg_ratings, num_reviews, dollar_rating):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
figsize(11, 22)
plot_fns([("{} Estimated CTR".format(name), three_d_pred),
("CTR", click_through_rate)],
split_by_dollar=True)
Zaangażować trzecią funkcję, dollar_rating , należy przypomnieć, że kategoryczne funkcje wymagają nieco innego traktowania w TFL, zarówno jako kolumny funkcji i jako cecha config. Tutaj wymuszamy częściowe ograniczenie monotoniczności, zgodnie z którym dane wyjściowe dla restauracji „DD” powinny być większe niż restauracji „D”, gdy wszystkie inne dane wejściowe są ustalone. Odbywa się to za pomocą monotonicity ustawienie w konfiguracji funkcji.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7699775695800781 Testing AUC: 0.8594040274620056


Ten kategoryczny kalibrator pokazuje preferencje wyjścia modelu: DD > D > DDD > DDDD, co jest zgodne z naszą konfiguracją. Zauważ, że istnieje również kolumna na brakujące wartości. Chociaż w naszych danych treningowych i testowych nie ma brakujących funkcji, model zapewnia nam imputację brakującej wartości, jeśli ma to miejsce podczas udostępniania modelu podrzędnego.
Tu również wykreślić przewidywany CTR tego modelu uwarunkowanej na dollar_rating . Zauważ, że wszystkie wymagane przez nas ograniczenia są spełnione w każdym z plasterków.
Kalibracja wyjściowa
W przypadku wszystkich modeli TFL, które do tej pory przeszkoliliśmy, warstwa sieci (oznaczona jako „Krata” na wykresie modelu) bezpośrednio generuje prognozę modelu. Czasami nie jesteśmy pewni, czy wyjście sieci powinno zostać przeskalowane, aby emitować wyjścia modelu:
- funkcje są \(log\) liczy natomiast etykiety są liczy.
- sieć jest skonfigurowana tak, aby mieć bardzo mało wierzchołków, ale dystrybucja etykiet jest stosunkowo skomplikowana.
W takich przypadkach możemy dodać kolejny kalibrator między wyjściem siatki a wyjściem modelu, aby zwiększyć elastyczność modelu. Dodajmy tutaj warstwę kalibratora z 5 punktami kluczowymi do modelu, który właśnie zbudowaliśmy. Dodaliśmy również regulator do kalibratora wyjściowego, aby funkcja była płynna.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
output_calibration=True,
output_calibration_num_keypoints=5,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="output_calib_wrinkle", l2=0.1),
],
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7697908878326416 Testing AUC: 0.861327052116394


Ostateczna metryka testowa i wykresy pokazują, w jaki sposób stosowanie ograniczeń zdroworozsądkowych może pomóc modelowi uniknąć nieoczekiwanego zachowania i lepiej ekstrapolować na całą przestrzeń wejściową.