ML flessibile, controllato e interpretabile con modelli basati su reticolo
import numpy as np import tensorflow as tf import tensorflow_lattice as tfl model = tf.keras.models.Sequential() model.add( tfl.layers.ParallelCombination([ # Monotonic piece-wise linear calibration with bounded output tfl.layers.PWLCalibration( monotonicity='increasing', input_keypoints=np.linspace(1., 5., num=20), output_min=0.0, output_max=1.0), # Diminishing returns tfl.layers.PWLCalibration( monotonicity='increasing', convexity='concave', input_keypoints=np.linspace(0., 200., num=20), output_min=0.0, output_max=2.0), # Partially monotonic categorical calibration: calib(0) <= calib(1) tfl.layers.CategoricalCalibration( num_buckets=4, output_min=0.0, output_max=1.0, monotonicities=[(0, 1)]), ])) model.add( tfl.layers.Lattice( lattice_sizes=[2, 3, 2], monotonicities=['increasing', 'increasing', 'increasing'], # Trust: model is more responsive to input 0 if input 1 increases edgeworth_trusts=(0, 1, 'positive'))) model.compile(...)
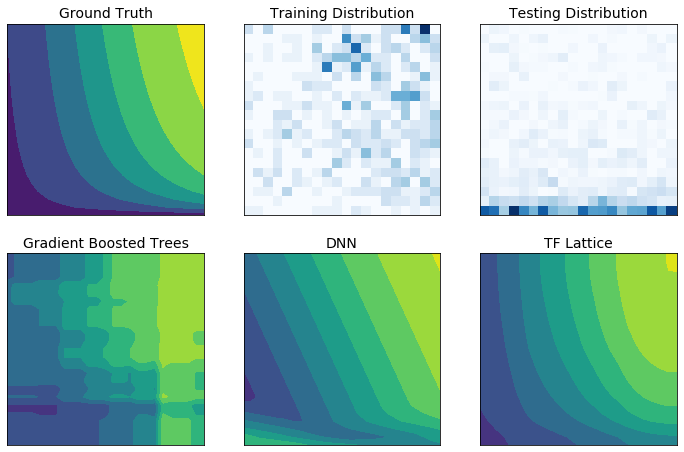
TensorFlow Lattice è una libreria che implementa modelli basati su reticolo vincolato e interpretabile. La libreria consente di inserire la conoscenza del dominio nel processo di apprendimento attraverso vincoli di forma dettati dal buon senso o da politiche. Ciò viene fatto utilizzando una raccolta di livelli Keras in grado di soddisfare vincoli quali monotonicità, convessità e modalità di interazione delle caratteristiche. La libreria fornisce anche modelli prefabbricati facili da configurare.
Con TF Lattice è possibile utilizzare la conoscenza del dominio per estrapolare meglio le parti dello spazio di input non coperte dal set di dati di training. Ciò aiuta a evitare comportamenti imprevisti del modello quando la distribuzione di servizio è diversa dalla distribuzione di training.