
Este tutorial le muestra cómo crear una aplicación de Android utilizando TensorFlow Lite para proporcionar respuestas a preguntas estructuradas en texto en lenguaje natural. La aplicación de ejemplo utiliza la API de respuesta a preguntas BERT ( BertQuestionAnswerer ) dentro de la biblioteca de tareas para lenguaje natural (NL) para habilitar los modelos de aprendizaje automático de respuesta a preguntas. La aplicación está diseñada para un dispositivo Android físico, pero también puede ejecutarse en un emulador de dispositivo.
Si está actualizando un proyecto existente, puede utilizar la aplicación de ejemplo como referencia o plantilla. Para obtener instrucciones sobre cómo agregar respuestas a preguntas a una aplicación existente, consulte Actualización y modificación de su aplicación .
Resumen de respuestas a preguntas
La respuesta a preguntas es la tarea de aprendizaje automático de responder preguntas planteadas en lenguaje natural. Un modelo de respuesta a preguntas entrenado recibe un pasaje de texto y una pregunta como entrada e intenta responder la pregunta basándose en su interpretación de la información contenida en el pasaje.
Un modelo de respuesta a preguntas se entrena en un conjunto de datos de respuesta a preguntas, que consta de un conjunto de datos de comprensión lectora junto con pares de preguntas y respuestas basados en diferentes segmentos de texto.
Para obtener más información sobre cómo se generan los modelos en este tutorial, consulte el tutorial BERT Question Answer with TensorFlow Lite Model Maker .
Modelos y conjunto de datos
La aplicación de ejemplo utiliza el modelo Mobile BERT Q&A ( mobilebert ), que es una versión más ligera y rápida de BERT (Representaciones de codificador bidireccional de Transformers). Para obtener más información sobre mobilebert , consulte el artículo de investigación MobileBERT: un BERT compacto e independiente de tareas para dispositivos con recursos limitados .
El modelo mobilebert se entrenó utilizando el conjunto de datos de Stanford Question Answering Dataset ( SQuAD ), un conjunto de datos de comprensión lectora que consta de artículos de Wikipedia y un conjunto de pares de preguntas y respuestas para cada artículo.
Configurar y ejecutar la aplicación de ejemplo
Para configurar la aplicación de respuesta a preguntas, descargue la aplicación de ejemplo de GitHub y ejecútela con Android Studio .
Requisitos del sistema
- Android Studio versión 2021.1.1 (Bumblebee) o superior.
- Android SDK versión 31 o superior
- Dispositivo Android con una versión mínima del sistema operativo SDK 21 (Android 7.0 - Nougat) con el modo de desarrollador habilitado o un emulador de Android.
Obtenga el código de ejemplo
Cree una copia local del código de ejemplo. Utilizará este código para crear un proyecto en Android Studio y ejecutar la aplicación de ejemplo.
Para clonar y configurar el código de ejemplo:
- Clonar el repositorio git
git clone https://github.com/tensorflow/examples.git
- Opcionalmente, configure su instancia de git para usar el pago disperso, de modo que solo tenga los archivos para la aplicación de ejemplo de respuesta a preguntas:
cd examples git sparse-checkout init --cone git sparse-checkout set lite/examples/bert_qa/android
Importar y ejecutar el proyecto.
Cree un proyecto a partir del código de ejemplo descargado, compílelo y luego ejecútelo.
Para importar y construir el proyecto de código de ejemplo:
- Inicie Android Studio .
- Desde Android Studio, seleccione Archivo > Nuevo > Importar proyecto .
- Navegue hasta el directorio del código de ejemplo que contiene el archivo build.gradle (
.../examples/lite/examples/bert_qa/android/build.gradle) y seleccione ese directorio. - Si Android Studio solicita Gradle Sync, elija Aceptar.
- Asegúrese de que su dispositivo Android esté conectado a su computadora y que el modo de desarrollador esté habilitado. Haga clic en la flecha verde
Run.
Si selecciona el directorio correcto, Android Studio crea un nuevo proyecto y lo construye. Este proceso puede tardar unos minutos, dependiendo de la velocidad de tu computadora y si has usado Android Studio para otros proyectos. Cuando se completa la compilación, Android Studio muestra un mensaje BUILD SUCCESSFUL en el panel de estado de Salida de la compilación .
Para ejecutar el proyecto:
- Desde Android Studio, ejecute el proyecto seleccionando Ejecutar > Ejecutar… .
- Seleccione un dispositivo Android (o emulador) conectado para probar la aplicación.
Usando la aplicación
Después de ejecutar el proyecto en Android Studio, la aplicación se abre automáticamente en el dispositivo o emulador de dispositivo conectado.
Para utilizar la aplicación de ejemplo de Respuesta a preguntas:
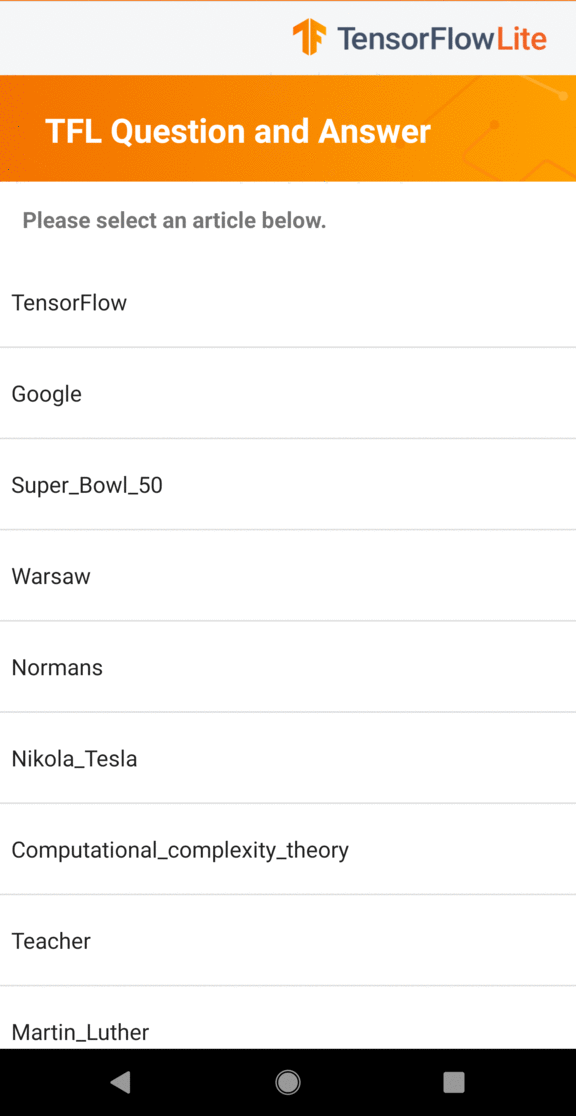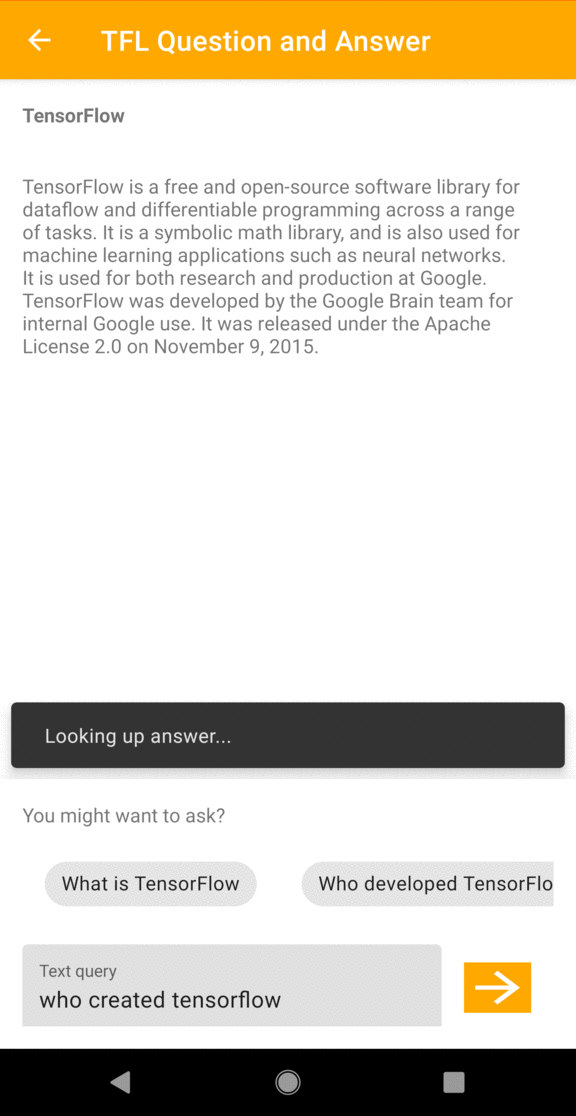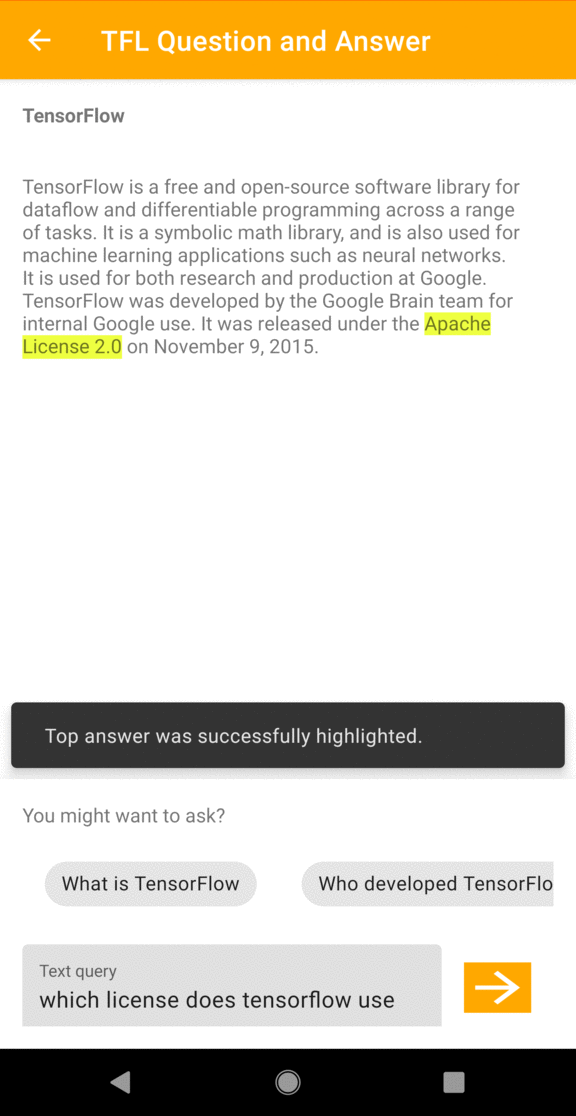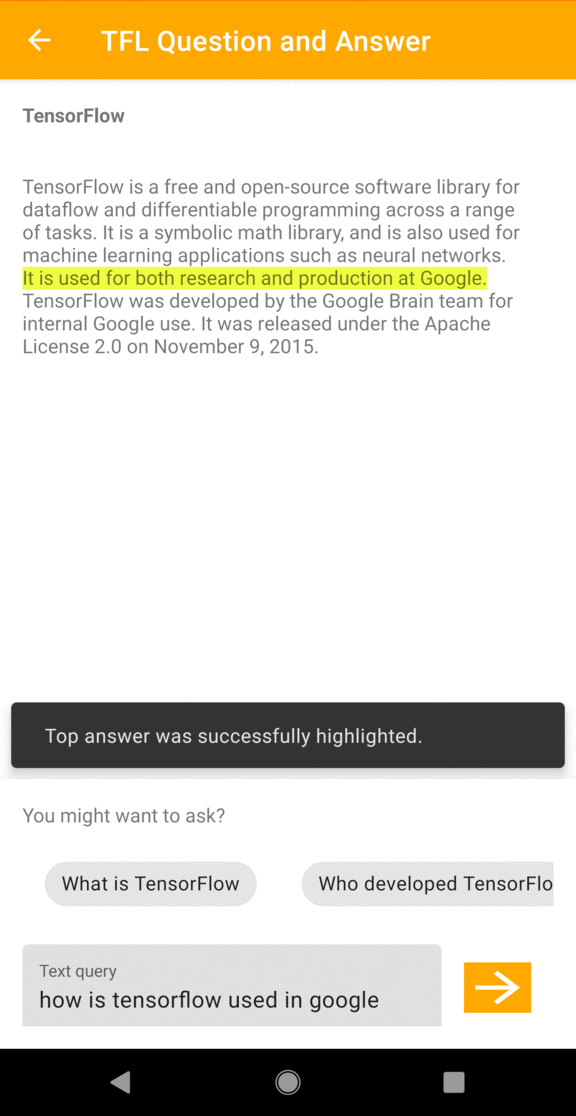
- Elija un tema de la lista de temas.
- Elija una pregunta sugerida o ingrese la suya propia en el cuadro de texto.
- Mueva la flecha naranja para ejecutar el modelo.
La aplicación intenta identificar la respuesta a la pregunta a partir del texto del pasaje. Si el modelo detecta una respuesta dentro del pasaje, la aplicación resalta el fragmento de texto relevante para el usuario.
Ahora tiene una aplicación de respuesta a preguntas en funcionamiento. Utilice las siguientes secciones para comprender mejor cómo funciona la aplicación de ejemplo y cómo implementar funciones de respuesta a preguntas en sus aplicaciones de producción:
Cómo funciona la aplicación : un recorrido por la estructura y los archivos clave de la aplicación de ejemplo.
Modifique su solicitud : instrucciones para agregar respuestas a preguntas a una solicitud existente.
Cómo funciona la aplicación de ejemplo
La aplicación utiliza la API BertQuestionAnswerer dentro de la biblioteca de tareas para el paquete de lenguaje natural (NL) . El modelo MobileBERT se entrenó utilizando TensorFlow Lite Model Maker . La aplicación se ejecuta en la CPU de forma predeterminada, con la opción de aceleración de hardware mediante la GPU o el delegado NNAPI.
Los siguientes archivos y directorios contienen el código crucial para esta aplicación:
- BertQaHelper.kt : inicializa el contestador de preguntas y maneja el modelo y la selección del delegado.
- QaFragment.kt : maneja y formatea los resultados.
- MainActivity.kt : proporciona la lógica organizativa de la aplicación.
Modifica tu aplicación
Las siguientes secciones explican los pasos clave para modificar su propia aplicación de Android para ejecutar el modelo que se muestra en la aplicación de ejemplo. Estas instrucciones utilizan la aplicación de ejemplo como punto de referencia. Los cambios específicos necesarios para su propia aplicación pueden variar respecto a la aplicación de ejemplo.
Abrir o crear un proyecto de Android
Necesita un proyecto de desarrollo de Android en Android Studio para seguir el resto de estas instrucciones. Siga las instrucciones a continuación para abrir un proyecto existente o crear uno nuevo.
Para abrir un proyecto de desarrollo de Android existente:
- En Android Studio, seleccione Archivo > Abrir y seleccione un proyecto existente.
Para crear un proyecto de desarrollo básico de Android:
- Siga las instrucciones en Android Studio para crear un proyecto básico .
Para obtener más información sobre el uso de Android Studio, consulte la documentación de Android Studio .
Agregar dependencias del proyecto
En su propia aplicación, agregue dependencias específicas del proyecto para ejecutar modelos de aprendizaje automático de TensorFlow Lite y acceder a funciones de utilidad. Estas funciones convierten datos como cadenas en un formato de datos tensoriales que el modelo puede procesar. Las siguientes instrucciones explican cómo agregar las dependencias requeridas del proyecto y del módulo a su propio proyecto de aplicación de Android.
Para agregar dependencias de módulos:
En el módulo que usa TensorFlow Lite, actualice el archivo
build.gradledel módulo para incluir las siguientes dependencias.En la aplicación de ejemplo, las dependencias se encuentran en app/build.gradle :
dependencies { ... // Import tensorflow library implementation 'org.tensorflow:tensorflow-lite-task-text:0.3.0' // Import the GPU delegate plugin Library for GPU inference implementation 'org.tensorflow:tensorflow-lite-gpu-delegate-plugin:0.4.0' implementation 'org.tensorflow:tensorflow-lite-gpu:2.9.0' }El proyecto debe incluir la biblioteca de tareas de Texto (
tensorflow-lite-task-text).Si desea modificar esta aplicación para que se ejecute en una unidad de procesamiento de gráficos (GPU), la biblioteca de GPU (
tensorflow-lite-gpu-delegate-plugin) proporciona la infraestructura para ejecutar la aplicación en GPU y Delegate (tensorflow-lite-gpu) proporciona la lista de compatibilidad.En Android Studio, sincronice las dependencias del proyecto seleccionando: Archivo > Sincronizar proyecto con archivos Gradle .
Inicializar los modelos ML
En su aplicación de Android, debe inicializar el modelo de aprendizaje automático de TensorFlow Lite con parámetros antes de ejecutar predicciones con el modelo.
Un modelo de TensorFlow Lite se almacena como un archivo *.tflite . El archivo de modelo contiene la lógica de predicción y normalmente incluye metadatos sobre cómo interpretar los resultados de la predicción. Normalmente, los archivos de modelo se almacenan en el directorio src/main/assets de su proyecto de desarrollo, como en el ejemplo de código:
-
<project>/src/main/assets/mobilebert_qa.tflite
Por conveniencia y legibilidad del código, el ejemplo declara un objeto complementario que define la configuración del modelo.
Para inicializar el modelo en su aplicación:
Cree un objeto complementario para definir la configuración del modelo. En la aplicación de ejemplo, este objeto se encuentra en BertQaHelper.kt :
companion object { private const val BERT_QA_MODEL = "mobilebert.tflite" private const val TAG = "BertQaHelper" const val DELEGATE_CPU = 0 const val DELEGATE_GPU = 1 const val DELEGATE_NNAPI = 2 }Cree la configuración para el modelo creando un objeto
BertQaHelpery construya un objeto TensorFlow Lite conbertQuestionAnswerer.En la aplicación de ejemplo, esto se encuentra en la función
setupBertQuestionAnswerer()dentro de BertQaHelper.kt :class BertQaHelper( ... ) { ... init { setupBertQuestionAnswerer() } fun clearBertQuestionAnswerer() { bertQuestionAnswerer = null } private fun setupBertQuestionAnswerer() { val baseOptionsBuilder = BaseOptions.builder().setNumThreads(numThreads) ... val options = BertQuestionAnswererOptions.builder() .setBaseOptions(baseOptionsBuilder.build()) .build() try { bertQuestionAnswerer = BertQuestionAnswerer.createFromFileAndOptions(context, BERT_QA_MODEL, options) } catch (e: IllegalStateException) { answererListener ?.onError("Bert Question Answerer failed to initialize. See error logs for details") Log.e(TAG, "TFLite failed to load model with error: " + e.message) } } ... }
Habilitar la aceleración de hardware (opcional)
Al inicializar un modelo de TensorFlow Lite en su aplicación, debe considerar el uso de funciones de aceleración de hardware para acelerar los cálculos de predicción del modelo. Los delegados de TensorFlow Lite son módulos de software que aceleran la ejecución de modelos de aprendizaje automático utilizando hardware de procesamiento especializado en un dispositivo móvil, como una unidad de procesamiento de gráficos (GPU) o unidades de procesamiento de tensor (TPU).
Para habilitar la aceleración de hardware en su aplicación:
Cree una variable para definir el delegado que utilizará la aplicación. En la aplicación de ejemplo, esta variable se encuentra al principio de BertQaHelper.kt :
var currentDelegate: Int = 0Crea un selector de delegados. En la aplicación de ejemplo, el selector de delegados se encuentra en la función
setupBertQuestionAnswererdentro de BertQaHelper.kt :when (currentDelegate) { DELEGATE_CPU -> { // Default } DELEGATE_GPU -> { if (CompatibilityList().isDelegateSupportedOnThisDevice) { baseOptionsBuilder.useGpu() } else { answererListener?.onError("GPU is not supported on this device") } } DELEGATE_NNAPI -> { baseOptionsBuilder.useNnapi() } }
Se recomienda utilizar delegados para ejecutar modelos de TensorFlow Lite, pero no es obligatorio. Para obtener más información sobre el uso de delegados con TensorFlow Lite, consulte Delegados de TensorFlow Lite .
Preparar datos para el modelo.
En su aplicación de Android, su código proporciona datos al modelo para su interpretación transformando datos existentes, como texto sin formato, en un formato de datos Tensor que puede ser procesado por su modelo. El tensor que pasa a un modelo debe tener dimensiones o forma específicas que coincidan con el formato de datos utilizados para entrenar el modelo. Esta aplicación de respuesta a preguntas acepta cadenas como entradas tanto para el pasaje de texto como para la pregunta. El modelo no reconoce caracteres especiales ni palabras que no estén en inglés.
Para proporcionar datos de texto de pasaje al modelo:
Utilice el objeto
LoadDataSetClientpara cargar los datos de texto del pasaje en la aplicación. En la aplicación de ejemplo, esto se encuentra en LoadDataSetClient.ktfun loadJson(): DataSet? { var dataSet: DataSet? = null try { val inputStream: InputStream = context.assets.open(JSON_DIR) val bufferReader = inputStream.bufferedReader() val stringJson: String = bufferReader.use { it.readText() } val datasetType = object : TypeToken<DataSet>() {}.type dataSet = Gson().fromJson(stringJson, datasetType) } catch (e: IOException) { Log.e(TAG, e.message.toString()) } return dataSet }Utilice el objeto
DatasetFragmentpara enumerar los títulos de cada pasaje de texto e iniciar la pantalla de preguntas y respuestas de TFL . En la aplicación de ejemplo, se encuentra en DatasetFragment.kt :class DatasetFragment : Fragment() { ... override fun onViewCreated(view: View, savedInstanceState: Bundle?) { super.onViewCreated(view, savedInstanceState) val client = LoadDataSetClient(requireActivity()) client.loadJson()?.let { titles = it.getTitles() } ... } ... }Utilice la función
onCreateViewHolderdentro del objetoDatasetAdapterpara presentar los títulos de cada pasaje de texto. En la aplicación de ejemplo, se encuentra en DatasetAdapter.kt :override fun onCreateViewHolder(parent: ViewGroup, viewType: Int): ViewHolder { val binding = ItemDatasetBinding.inflate( LayoutInflater.from(parent.context), parent, false ) return ViewHolder(binding) }
Para proporcionar preguntas de los usuarios al modelo:
Utilice el objeto
QaAdapterpara proporcionar la pregunta al modelo. En la aplicación de ejemplo, se encuentra en QaAdapter.kt :class QaAdapter(private val question: List<String>, private val select: (Int) -> Unit) : RecyclerView.Adapter<QaAdapter.ViewHolder>() { inner class ViewHolder(private val binding: ItemQuestionBinding) : RecyclerView.ViewHolder(binding.root) { init { binding.tvQuestionSuggestion.setOnClickListener { select.invoke(adapterPosition) } } fun bind(question: String) { binding.tvQuestionSuggestion.text = question } } ... }
Ejecutar predicciones
En su aplicación de Android, una vez que haya inicializado un objeto BertQuestionAnswerer , puede comenzar a ingresar preguntas en forma de texto en lenguaje natural en el modelo. El modelo intenta identificar la respuesta dentro del pasaje del texto.
Para ejecutar predicciones:
Cree una función
answer, que ejecute el modelo y mida el tiempo necesario para identificar la respuesta (inferenceTime). En la aplicación de ejemplo, la funciónanswerse encuentra en BertQaHelper.kt :fun answer(contextOfQuestion: String, question: String) { if (bertQuestionAnswerer == null) { setupBertQuestionAnswerer() } var inferenceTime = SystemClock.uptimeMillis() val answers = bertQuestionAnswerer?.answer(contextOfQuestion, question) inferenceTime = SystemClock.uptimeMillis() - inferenceTime answererListener?.onResults(answers, inferenceTime) }Pase los resultados de la
answeral objeto de escucha.interface AnswererListener { fun onError(error: String) fun onResults( results: List<QaAnswer>?, inferenceTime: Long ) }
Manejar la salida del modelo
Después de ingresar una pregunta, el modelo proporciona un máximo de cinco respuestas posibles dentro del pasaje.
Para obtener los resultados del modelo:
Cree una función
onResultpara que el objeto de escucha maneje la salida. En la aplicación de ejemplo, el objeto de escucha se encuentra en BertQaHelper.ktinterface AnswererListener { fun onError(error: String) fun onResults( results: List<QaAnswer>?, inferenceTime: Long ) }Resalte secciones del pasaje según los resultados. En la aplicación de ejemplo, se encuentra en QaFragment.kt :
override fun onResults(results: List<QaAnswer>?, inferenceTime: Long) { results?.first()?.let { highlightAnswer(it.text) } fragmentQaBinding.tvInferenceTime.text = String.format( requireActivity().getString(R.string.bottom_view_inference_time), inferenceTime ) }
Una vez que el modelo ha devuelto un conjunto de resultados, su aplicación puede actuar según esas predicciones presentando el resultado a su usuario o ejecutando lógica adicional.
Próximos pasos
- Entrene e implemente los modelos desde cero con el tutorial Pregunta y respuesta con TensorFlow Lite Model Maker .
- Explore más herramientas de procesamiento de texto para TensorFlow .
- Descargue otros modelos BERT en TensorFlow Hub .
- Explore varios usos de TensorFlow Lite en los ejemplos .