
개요
이 페이지에서는 TensorFlow의 복합 연산을 TensorFlow Lite의 융합 연산으로 변환하는 데 필요한 설계 및 단계를 설명합니다. 이 인프라는 범용이며 TensorFlow의 모든 복합 연산을 TensorFlow Lite의 해당 융합 연산으로 변환하는 작업을 지원합니다.
이 인프라의 사용 예는 여기의 설명대로 TensorFlow Lite로의 TensorFlow RNN 연산 융합입니다.
융합 연산이란?

TensorFlow 연산은 기본 연산(예: tf.add)이거나 다른 기본 연산(예: tf.einsum)을 바탕으로 구성될 수 있습니다. 기본 연산은 TensorFlow 그래프에서 단일 노드로 표시되는 반면, 복합 연산은 TensorFlow 그래프에서 노드의 집합체입니다. 복합 연산을 실행하는 것은 이를 구성하는 기본 연산 각각을 실행하는 것과 같습니다.
융합 연산은 해당 복합 연산 내에서 각 기본 연산에 의해 수행되는 모든 계산을 포함하는 단일 연산에 해당합니다.
융합 연산의 이점
융합 연산은 전체 계산을 최적화하고 메모리 공간을 줄임으로써 기본 커널 구현의 성능을 최대화하는 데 목적을 두고 있습니다. 특히 대기 시간이 짧은 추론 워크로드와 리소스가 제한된 모바일 플랫폼에 매우 유용합니다.
융합 연산은 또한 양자화와 같은 복잡한 변환을 정의하기 위한 더 높은 수준의 인터페이스를 제공합니다. 이러한 인터페이스가 없다면 양자화는 실행 불가능하거나 보다 세분화된 수준에서 수행하기가 매우 어렵습니다.
TensorFlow Lite에는 위에 설명한 이유 때문에 여러 곳에서 융합 연산이 이용됩니다. 이들 융합 연산은 일반적으로 소스 TensorFlow 프로그램의 복합 연산에 해당합니다. TensorFlow Lite에서 단일 융합 연산으로 구현되는 TensorFlow 복합 연산의 예에는 단방향 및 양방향 시퀀스 LSTM, 컨볼루션(conv2d, bias add, relu), 완전 연결(matmul, bias add, relu) 등과 같은 다양한 RNN 연산이 포함됩니다. TensorFlow Lite에서 LSTM 양자화는 현재 융합된 LSTM 연산에서만 구현됩니다.
융합 연산에서 해결해야 할 과제
TensorFlow의 복합 연산을 TensorFlow Lite의 융합 연산으로 변환하는 것은 어려운 문제입니다. 그 이유는 다음과 같습니다.
복합 연산은 TensorFlow 그래프에서 잘 정의된 경계가 없는 기본 연산 집합으로 표시됩니다. 이러한 복합 연산에 해당하는 하위 그래프를 식별하는 것은(예: 패턴 일치를 통해) 매우 어려울 수 있습니다.
TensorFlow Lite 융합 연산을 대상으로 하는 TensorFlow 구현이 두 개 이상 있을 수 있습니다. 예를 들어, TensorFlow에는 많은 LSTM 구현(Keras, Babelfish/lingvo 등)이 있으며 이들 각각은 서로 다른 기본 연산으로 구성되어 있지만 모두 TensorFlow Lite에서 동일한 융합 LSTM 연산으로 변환될 수 있습니다.
따라서 융합 연산의 변환은 매우 어려운 것으로 알려져 있습니다.
복합 연산에서 융합 연산으로 변환하기
TensorFlow 복합 연산을 TensorFlow Lite 융합 연산으로 변환하기 위한 전반적인 아키텍처는 다음과 같습니다.
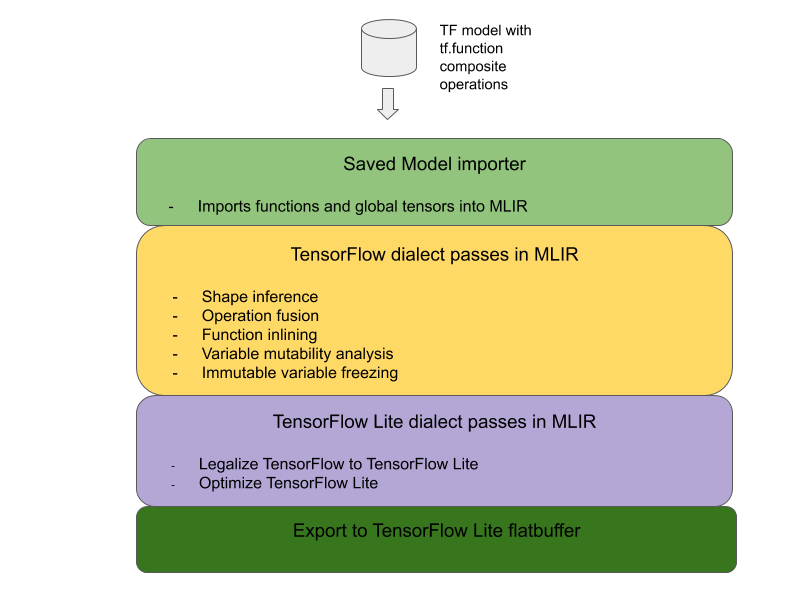
tf.function에서 복합 연산 래핑하기
TensorFlow 모델 소스 코드에서 Experiment_implements 함수 주석을 사용하여 복합 연산을 식별하고 tf.function으로 추상화합니다. 임베딩 조회의 예를 참조하세요. 이 함수는 인터페이스를 정의하고 해당 인수는 변환 논리를 구현하는 데 사용되어야 합니다.
변환 코드 작성하기
변환 코드는 implements 주석을 사용하여 함수의 인터페이스별로 작성됩니다. 임베딩 조회에 대한 융합의 예를 참조하세요. 개념적으로, 변환 코드는 이 인터페이스의 복합 구현을 융합 구현으로 대체합니다.
prepare-composite-functions 전달에서 변환 코드를 플러그인합니다.
보다 수준 높은 사용의 경우, 융합 연산의 피연산자를 유도하기 위해 복합 연산 피연산자의 복합 변환을 구현할 수 있습니다. 변환 코드의 예는 Keras LSTM을 참조하세요.
TensorFlow Lite로 변환하기
TFLiteConverter.from_saved_model API를 사용하여 TensorFlow Lite로 변환합니다.
배경
이제 TensorFlow Lite에서 융합 연산으로 변환할 때 전반적인 설계에 대해 높은 수준의 세부 사항을 설명합니다.
TensorFlow에서 연산 구성하기
experiment_implements 함수 속성과 함께 tf.function을 사용하면 사용자가 TensorFlow 기본 연산을 사용하여 새 연산을 명시적으로 구성하고 최종 복합 연산이 구현하는 인터페이스를 지정할 수 있습니다. 이 인터페이스는 다음과 같은 유용성을 제공합니다.
- 기본 TensorFlow 그래프의 복합 연산에 대해 잘 정의된 경계입니다.
- 이 연산이 구현하는 인터페이스를 명시적으로 지정합니다.
tf.function의 인수는 이 인터페이스의 인수에 해당합니다.
예를 들어, 임베딩 조회를 구현하기 위해 정의된 복합 연산을 고려해 보겠습니다. 이 복합 연산은 TensorFlow Lite의 융합 연산에 매핑됩니다.
@tf.function(
experimental_implements="embedding_lookup")
def EmbFprop(embs, ids_vec):
"""Embedding forward prop.
Effectively, it computes:
num = size of ids_vec
rets = zeros([num, embedding dim])
for i in range(num):
rets[i, :] = embs[ids_vec[i], :]
return rets
Args:
embs: The embedding matrix.
ids_vec: A vector of int32 embedding ids.
Returns:
The result of embedding lookups. A matrix of shape
[num ids in ids_vec, embedding dims].
"""
num = tf.shape(ids_vec)[0]
rets = inplace_ops.empty([num] + emb_shape_suf, py_utils.FPropDtype(p))
def EmbFpropLoop(i, embs, ids_vec, rets):
# row_id = ids_vec[i]
row_id = tf.gather(ids_vec, i)
# row = embs[row_id]
row = tf.reshape(tf.gather(embs, row_id), [1] + emb_shape_suf)
# rets[i] = row
rets = inplace_ops.alias_inplace_update(rets, [i], row)
return embs, ids_vec, rets
_, _, rets = functional_ops.For(
start=0,
limit=num,
delta=1,
inputs=[embs, ids_vec, rets],
body=EmbFpropLoop,
rewrite_with_while=compiled)
if len(weight_shape) > 2:
rets = tf.reshape(rets, [num, symbolic.ToStatic(p.embedding_dim)])
return rets
위의 설명과 같이 모델이 tf.function을 통해 복합 연산을 사용하도록 함으로써 이러한 연산을 TensorFlow Lite 융합 연산으로 식별 및 변환하는 일반적인 인프라를 구축할 수 있습니다.
TensorFlow Lite 변환기 확장하기
올해 초 출시된 TensorFlow Lite 변환기는 모든 변수가 해당 상수 값으로 대체된 그래프로 TensorFlow 모델을 가져오는 작업만 지원했습니다. 이러한 그래프에는 변수가 상수로 변환될 수 있도록 모든 함수가 인라인으로 배치되어 있어 연산 융합에는 효과가 없습니다.
변환 프로세스 중에 experimental_implements 특성과 함께 tf.function을 활용하려면 변환 프로세스 후반까지 함수를 보존해야 합니다.
따라서 복합 연산 융합 사용 사례를 지원하기 위해 변환기에서 TensorFlow 모델을 가져오고 변환하는 새로운 워크플로를 구현했습니다. 특히 다음과 같은 특성들이 추가되었습니다.
- TensorFlow 저장 모델을 MLIR로 가져오기
- 복합 연산 융합
- 변수 변경 가능성 분석
- 모든 읽기 전용 변수 고정
이를 통해 함수를 인라인 배치하고 변수를 고정하기 전에 복합 연산을 나타내는 함수를 사용하여 연산 융합을 수행할 수 있습니다.
연산 융합 구현하기
연산 융합 전달에 대해 좀 더 자세히 살펴보겠습니다. 이 전달은 다음을 수행합니다.
- MLIR 모듈의 모든 기능을 반복합니다.
- 함수에 tf._implements 속성이 있는 경우, 속성 값에 따라 적절한 연산 융합 유틸리티를 호출합니다.
- 연산 융합 유틸리티는 함수의 피연산자 및 속성(변환을 위한 인터페이스 역할을 함)에서 동작하며, 함수 본문을 융합 연산을 포함하는 동등한 함수 본문으로 바꿉니다.
- 대부분의 경우, 대체된 본문에는 융합 연산 이외의 연산이 포함됩니다. 이러한 연산은 융합 연산의 피연산자를 얻기 위해 함수의 피연산자에 이루어진 일부 정적 변환에 해당합니다. 이러한 계산은 모두 상수 접기를 지원하므로 융합 연산만 존재하는 내보낸 flatbuffer에는 나타나지 않습니다.
다음은 기본 워크플로를 보여주는 전달의 코드 조각입니다.
void PrepareCompositeFunctionsPass::ConvertTFImplements(FuncOp func,
StringAttr attr) {
if (attr.getValue() == "embedding_lookup") {
func.eraseBody();
func.addEntryBlock();
// Convert the composite embedding_lookup function body to a
// TFLite fused embedding_lookup op.
ConvertEmbeddedLookupFunc convert_embedded_lookup(func);
if (failed(convert_embedded_lookup.VerifySignature())) {
return signalPassFailure();
}
convert_embedded_lookup.RewriteFunc();
} else if (attr.getValue() == mlir::TFL::kKerasLstm) {
func.eraseBody();
func.addEntryBlock();
OpBuilder builder(func.getBody());
if (failed(ConvertKerasLSTMLayer(func, &builder))) {
return signalPassFailure();
}
} else if (.....) /* Other fusions can plug in here */
}
다음은 함수를 변환 인터페이스로 사용하여 이 복합 연산을 TensorFlow Lite의 융합 연산에 매핑하는 코드 조각입니다.
void RewriteFunc() {
Value lookup = func_.getArgument(1);
Value value = func_.getArgument(0);
auto output_type = func_.getType().getResult(0);
OpBuilder builder(func_.getBody());
auto op = builder.create<mlir::TFL::EmbeddingLookupOp>(
func_.getLoc(), output_type, lookup, value);
builder.create<mlir::ReturnOp>(func_.getLoc(), op.getResult());
}