
| | |  Zobacz źródło w GitHub Zobacz źródło w GitHub |
Spersonalizowane rekomendacje są szeroko stosowane w różnych przypadkach użycia na urządzeniach mobilnych, takich jak wyszukiwanie treści multimedialnych, sugestie dotyczące produktów do zakupów i rekomendacje kolejnych aplikacji. Jeśli jesteś zainteresowany dostarczaniem spersonalizowanych rekomendacji w swojej aplikacji, przy jednoczesnym poszanowaniu prywatności użytkowników, zalecamy zapoznanie się z poniższym przykładem i zestawem narzędzi.
Zaczynaj
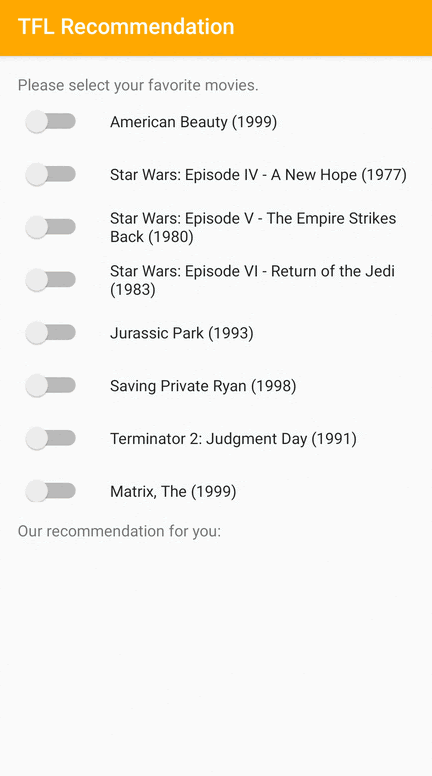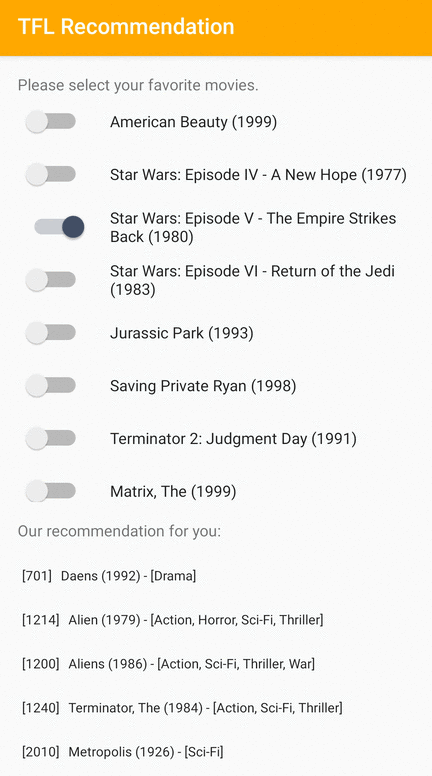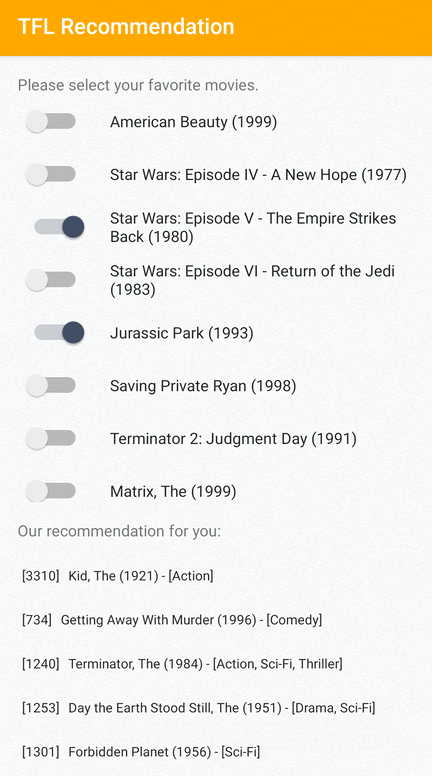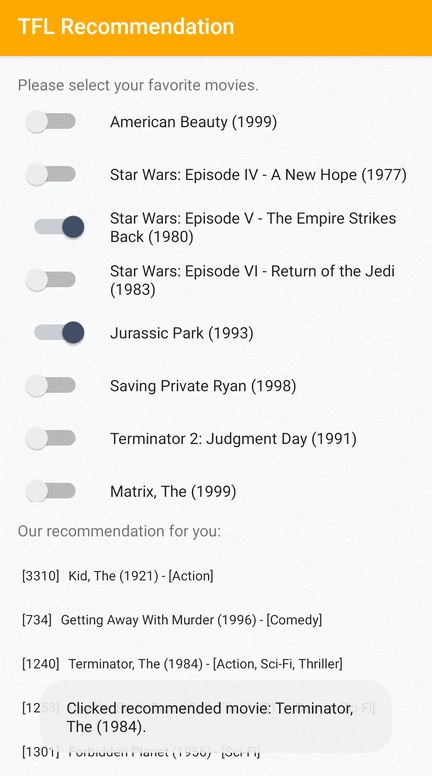
Udostępniamy przykładową aplikację TensorFlow Lite, która pokazuje, jak polecać odpowiednie elementy użytkownikom na Androidzie.
Jeśli korzystasz z platformy innej niż Android lub znasz już API TensorFlow Lite, możesz pobrać nasz model rekomendacji na start.
Udostępniamy także skrypt szkoleniowy w Githubie, umożliwiający trenowanie własnego modelu w konfigurowalny sposób.
Zrozumienie architektury modelu
Wykorzystujemy architekturę modelu z dwoma koderami, z koderem kontekstu do kodowania sekwencyjnej historii użytkownika i koderem etykiet do kodowania przewidywanego kandydata do rekomendacji. Podobieństwo między kodowaniem kontekstu i etykiety służy do przedstawienia prawdopodobieństwa, że przewidywany kandydat spełni potrzeby użytkownika.
W tej bazie kodu dostępne są trzy różne techniki sekwencyjnego kodowania historii użytkownika:
- Koder worka słów (BOW): uśrednianie osadzania działań użytkownika bez uwzględnienia kolejności kontekstu.
- Koder splotowej sieci neuronowej (CNN): zastosowanie wielu warstw splotowych sieci neuronowych w celu wygenerowania kodowania kontekstu.
- Koder rekurencyjnej sieci neuronowej (RNN): zastosowanie rekurencyjnej sieci neuronowej do kodowania sekwencji kontekstu.
Aby modelować każde działanie użytkownika, możemy użyć identyfikatora elementu działania (w oparciu o identyfikator) lub wielu funkcji elementu (w oparciu o funkcje) lub kombinacji obu. Model oparty na funkcjach, wykorzystujący wiele funkcji do zbiorczego kodowania zachowań użytkowników. Dzięki tej bazie kodu można w konfigurowalny sposób tworzyć modele oparte na identyfikatorach lub funkcjach.
Po szkoleniu zostanie wyeksportowany model TensorFlow Lite, który może bezpośrednio dostarczyć prognozy najwyższej jakości wśród kandydatów do rekomendacji.
Wykorzystaj swoje dane treningowe
Oprócz przeszkolonego modelu udostępniamy w serwisie GitHub zestaw narzędzi typu open source do uczenia modeli przy użyciu własnych danych. Możesz skorzystać z tego samouczka, aby dowiedzieć się, jak korzystać z zestawu narzędzi i wdrażać przeszkolone modele we własnych aplikacjach mobilnych.
Skorzystaj z tego samouczka , aby zastosować tę samą technikę, która została użyta w tym miejscu do uczenia modelu rekomendacji przy użyciu własnych zestawów danych.
Przykłady
Jako przykłady przeszkoliliśmy modele rekomendacji zarówno w oparciu o podejście oparte na identyfikatorach, jak i na funkcjach. Model oparty na identyfikatorach jako dane wejściowe przyjmuje tylko identyfikatory filmów, a model oparty na funkcjach jako dane wejściowe przyjmuje zarówno identyfikatory filmów, jak i identyfikatory gatunków filmów. Poniżej znajdziesz przykłady wejść i wyjść.
Wejścia
Identyfikatory filmów kontekstowych:
- Król Lew (ID: 362)
- Toy Story (ID: 1)
- (i więcej)
Identyfikatory gatunków filmów kontekstowych:
- Animacja (ID: 15)
- Dziecięce (ID: 9)
- Muzyczne (ID: 13)
- Animacja (ID: 15)
- Dziecięce (ID: 9)
- Komedia (ID: 2)
- (i więcej)
Wyjścia:
- Polecane identyfikatory filmów:
- Zabawkowa historia 2 (ID: 3114)
- (i więcej)
Benchmarki wydajności
Wartości porównawcze wydajności są generowane za pomocą narzędzia opisanego tutaj .
| Nazwa modelu | Rozmiar modelu | Urządzenie | procesor |
|---|---|---|---|
| rekomendacja (identyfikator filmu jako dane wejściowe) | 0,52 Mb | Piksel 3 | 0,09 ms* |
| Piksel 4 | 0,05 ms* | ||
| rekomendacja (jako dane wejściowe identyfikator filmu i gatunek filmu) | 1,3 Mb | Piksel 3 | 0,13 ms* |
| Piksel 4 | 0,06 ms* |
* Wykorzystano 4 wątki.
Wykorzystaj swoje dane treningowe
Oprócz przeszkolonego modelu udostępniamy w serwisie GitHub zestaw narzędzi typu open source do uczenia modeli przy użyciu własnych danych. Możesz skorzystać z tego samouczka, aby dowiedzieć się, jak korzystać z zestawu narzędzi i wdrażać przeszkolone modele we własnych aplikacjach mobilnych.
Skorzystaj z tego samouczka , aby zastosować tę samą technikę, która została użyta w tym miejscu do uczenia modelu rekomendacji przy użyciu własnych zestawów danych.
Wskazówki dotyczące dostosowywania modelu przy użyciu danych
Wstępnie wytrenowany model zintegrowany w tej aplikacji demonstracyjnej jest szkolony przy użyciu zestawu danych MovieLens . Możesz chcieć zmodyfikować konfigurację modelu w oparciu o własne dane, takie jak rozmiar słownictwa, przyciemnienia osadzania i długość kontekstu wejściowego. Oto kilka wskazówek:
Długość kontekstu wejściowego: najlepsza długość kontekstu wejściowego różni się w zależności od zestawu danych. Sugerujemy wybranie długości kontekstu wejściowego na podstawie tego, jak bardzo zdarzenia na etykiecie są skorelowane z długoterminowymi zainteresowaniami w porównaniu z kontekstem krótkoterminowym.
Wybór typu enkodera: sugerujemy wybór typu enkodera na podstawie długości kontekstu wejściowego. Koder worka słów dobrze sprawdza się w przypadku krótkiego kontekstu wejściowego (np. <10), kodery CNN i RNN zapewniają większe możliwości podsumowania w przypadku długiego kontekstu wejściowego.
Używanie podstawowych funkcji do reprezentowania elementów lub działań użytkownika może poprawić wydajność modelu, lepiej dostosować się do nowych elementów, ewentualnie zmniejszyć przestrzeń do osadzania, a tym samym zmniejszyć zużycie pamięci i zwiększyć przyjazność dla urządzenia.