

تصنيف الفيديو هو مهمة التعلم الآلي لتحديد ما يمثله الفيديو. يتم تدريب نموذج تصنيف الفيديو على مجموعة بيانات فيديو تحتوي على مجموعة من الفئات الفريدة، مثل الإجراءات أو الحركات المختلفة. يستقبل النموذج إطارات الفيديو كمدخلات ويخرج احتمالية تمثيل كل فئة في الفيديو.
يستخدم كل من نموذجي تصنيف الفيديو وتصنيف الصور الصور كمدخلات للتنبؤ باحتمالات تلك الصور التي تنتمي إلى فئات محددة مسبقًا. ومع ذلك، يقوم نموذج تصنيف الفيديو أيضًا بمعالجة العلاقات المكانية والزمانية بين الإطارات المتجاورة للتعرف على الإجراءات في الفيديو.
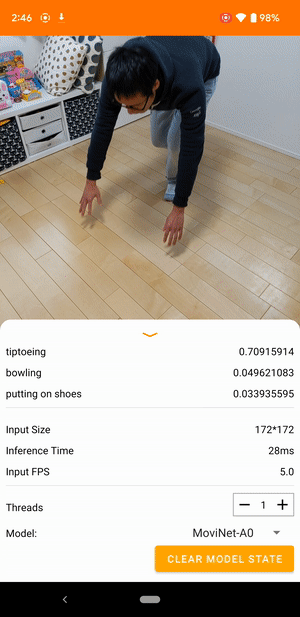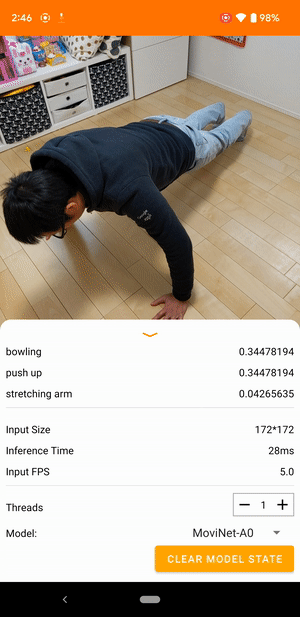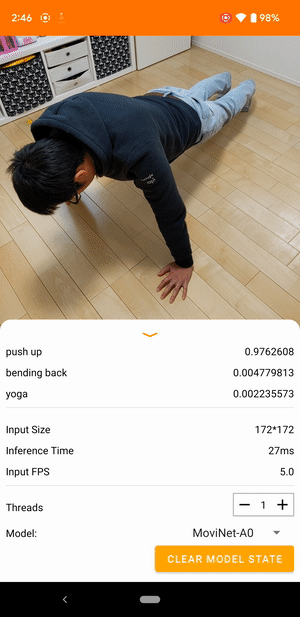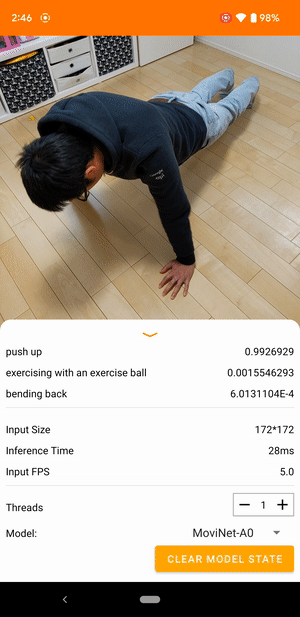
على سبيل المثال، يمكن تدريب نموذج التعرف على حركات الفيديو للتعرف على الأفعال البشرية مثل الجري والتصفيق والتلويح. الصورة التالية توضح مخرجات نموذج تصنيف الفيديو على نظام أندرويد.
البدء
إذا كنت تستخدم نظامًا أساسيًا غير Android أو Raspberry Pi، أو إذا كنت معتادًا بالفعل على TensorFlow Lite APIs ، فقم بتنزيل نموذج تصنيف الفيديو المبدئي والملفات الداعمة. يمكنك أيضًا إنشاء مسار الاستدلال المخصص الخاص بك باستخدام مكتبة دعم TensorFlow Lite .
قم بتنزيل نموذج البداية مع البيانات الوصفية
إذا كنت مستخدمًا جديدًا لـ TensorFlow Lite وتعمل مع Android أو Raspberry Pi، فاستكشف أمثلة التطبيقات التالية لمساعدتك على البدء.
ذكري المظهر
يستخدم تطبيق Android الكاميرا الخلفية للجهاز لتصنيف الفيديو بشكل مستمر. يتم إجراء الاستدلال باستخدام TensorFlow Lite Java API . يقوم التطبيق التجريبي بتصنيف الإطارات وعرض التصنيفات المتوقعة في الوقت الفعلي.
فطيرة التوت
يستخدم مثال Raspberry Pi TensorFlow Lite مع Python لإجراء تصنيف مستمر للفيديو. قم بتوصيل Raspberry Pi بكاميرا، مثل Pi Camera، لإجراء تصنيف الفيديو في الوقت الفعلي. لعرض النتائج من الكاميرا، قم بتوصيل شاشة بـ Raspberry Pi واستخدم SSH للوصول إلى Pi shell (لتجنب توصيل لوحة المفاتيح بـ Pi).
قبل البدء، قم بإعداد Raspberry Pi الخاص بك باستخدام Raspberry Pi OS (يفضل تحديثه إلى Buster).
نموذج الوصف
شبكات الفيديو المحمولة ( MoViNets ) هي مجموعة من نماذج تصنيف الفيديو الفعالة المُحسّنة للأجهزة المحمولة. تُظهر MoViNets أحدث الدقة والكفاءة في العديد من مجموعات بيانات التعرف على إجراءات الفيديو واسعة النطاق، مما يجعلها مناسبة تمامًا لمهام التعرف على إجراءات الفيديو .
هناك ثلاثة أنواع مختلفة من نموذج MoviNet لـ TensorFlow Lite: MoviNet-A0 و MoviNet-A1 و MoviNet-A2 . تم تدريب هذه المتغيرات باستخدام مجموعة بيانات Kinetics-600 للتعرف على 600 إجراء بشري مختلف. MoviNet-A0 هو الأصغر والأسرع والأقل دقة. MoviNet-A2 هو الأكبر والأبطأ والأكثر دقة. MoviNet-A1 هو حل وسط بين A0 وA2.
كيف تعمل
أثناء التدريب، يتم توفير نموذج تصنيف الفيديو مقاطع الفيديو والتسميات المرتبطة بها. كل تسمية هي اسم مفهوم أو فئة مميزة سيتعلم النموذج التعرف عليها. للتعرف على إجراء الفيديو ، ستكون مقاطع الفيديو لأفعال بشرية وستكون التسميات هي الإجراء المرتبط.
يمكن لنموذج تصنيف الفيديو أن يتعلم التنبؤ بما إذا كانت مقاطع الفيديو الجديدة تنتمي إلى أي من الفئات المقدمة أثناء التدريب. وتسمى هذه العملية الاستدلال . يمكنك أيضًا استخدام نقل التعلم لتحديد فئات جديدة من مقاطع الفيديو باستخدام نموذج موجود مسبقًا.
النموذج عبارة عن نموذج دفق يستقبل الفيديو المستمر ويستجيب في الوقت الفعلي. عندما يتلقى النموذج دفق فيديو، فإنه يحدد ما إذا كان أي من الفئات من مجموعة بيانات التدريب ممثلة في الفيديو. لكل إطار، يقوم النموذج بإرجاع هذه الفئات، إلى جانب احتمال أن يمثل الفيديو الفئة. قد يبدو مثال الإخراج في وقت معين كما يلي:
| فعل | احتمالا |
|---|---|
| رقص رباعي | 0.02 |
| إبرة خيوط | 0.08 |
| تلاعب الأصابع | 0.23 |
| يد تلوح | 0.67 |
يتوافق كل إجراء في الإخراج مع تسمية في بيانات التدريب. يشير الاحتمال إلى احتمالية عرض الإجراء في الفيديو.
مدخلات النموذج
يقبل النموذج دفقًا من إطارات فيديو RGB كمدخل. حجم الفيديو المدخل مرن، ولكنه يتطابق بشكل مثالي مع دقة تدريب النموذج ومعدل الإطارات:
- MoviNet-A0 : 172 × 172 بمعدل 5 إطارات في الثانية
- MoviNet-A1 : 172 × 172 بمعدل 5 إطارات في الثانية
- MoviNet-A1 : 224 × 224 بمعدل 5 إطارات في الثانية
من المتوقع أن تحتوي مقاطع الفيديو المدخلة على قيم ألوان ضمن نطاق 0 و1، وفقًا لاصطلاحات إدخال الصور الشائعة.
داخليًا، يقوم النموذج أيضًا بتحليل سياق كل إطار باستخدام المعلومات المجمعة في الإطارات السابقة. يتم تحقيق ذلك عن طريق أخذ الحالات الداخلية من مخرجات النموذج وإعادتها إلى النموذج للإطارات القادمة.
مخرجات النموذج
يقوم النموذج بإرجاع سلسلة من التسميات والنتائج المقابلة لها. الدرجات هي قيم لوغاريتمية تمثل التنبؤ لكل فئة. يمكن تحويل هذه الدرجات إلى احتمالات باستخدام الدالة softmax ( tf.nn.softmax ).
exp_logits = np.exp(np.squeeze(logits, axis=0))
probabilities = exp_logits / np.sum(exp_logits)
داخليًا، يتضمن مخرج النموذج أيضًا حالات داخلية من النموذج ويغذيها مرة أخرى في النموذج للإطارات القادمة.
معايير الأداء
يتم إنشاء أرقام قياس الأداء باستخدام أداة قياس الأداء . تدعم MoviNets وحدة المعالجة المركزية (CPU) فقط.
يتم قياس أداء النموذج بمقدار الوقت الذي يستغرقه النموذج لتشغيل الاستدلال على قطعة معينة من الأجهزة. الوقت الأقل يعني نموذجًا أسرع. يتم قياس الدقة من خلال عدد المرات التي يقوم فيها النموذج بتصنيف فئة ما بشكل صحيح في الفيديو.
| اسم النموذج | مقاس | دقة * | جهاز | وحدة المعالجة المركزية ** |
|---|---|---|---|---|
| MoviNet-A0 (عدد صحيح كمي) | 3.1 ميجابايت | 65% | بكسل 4 | 5 مللي ثانية |
| بكسل 3 | 11 مللي ثانية | |||
| MoviNet-A1 (عدد صحيح كمي) | 4.5 ميجا بايت | 70% | بكسل 4 | 8 مللي ثانية |
| بكسل 3 | 19 مللي ثانية | |||
| MoviNet-A2 (عدد صحيح كمي) | 5.1 ميجابايت | 72% | بكسل 4 | 15 مللي ثانية |
| بكسل 3 | 36 مللي ثانية |
* تم قياس الدقة الأولى في مجموعة بيانات Kinetics-600 .
** يتم قياس زمن الوصول عند التشغيل على وحدة المعالجة المركزية ذات خيط واحد.
تخصيص النموذج
يتم تدريب النماذج المدربة مسبقًا للتعرف على 600 إجراء بشري من مجموعة بيانات Kinetics-600 . يمكنك أيضًا استخدام نقل التعلم لإعادة تدريب النموذج للتعرف على الأفعال البشرية غير الموجودة في المجموعة الأصلية. للقيام بذلك، تحتاج إلى مجموعة من مقاطع الفيديو التدريبية لكل إجراء من الإجراءات الجديدة التي تريد دمجها في النموذج.
لمزيد من المعلومات حول نماذج الضبط الدقيق للبيانات المخصصة، راجع البرنامج التعليمي MoViNets repo و MoViNets .
مزيد من القراءة والموارد
استخدم الموارد التالية لمعرفة المزيد حول المفاهيم التي تمت مناقشتها في هذه الصفحة: