
ベンチマークツール
現在、TensorFlow Lite ベンチマークツールは次の重要なパフォーマンス指標の統計を測定および計算します。
- 初期化時間
- ウォームアップ状態の推論時間
- 定常状態の推論時間
- 初期化時のメモリ使用量
- 全体的なメモリ使用量
ベンチマークツールは、Android と iOS のベンチマークアプリ、および、ネイティブコマンドラインバイナリとして利用できます。すべて同一のコアパフォーマンス測定ロジックを共有します。ランタイム環境の違いにより、利用可能なオプションと出力形式がわずかに異なることに注意してください。
Android ベンチマークアプリ
Android でベンチマークツールを使用するには、2つのオプションがあります。1つ目はネイティブベンチマークバイナリで、2つ目は Android ベンチマークアプリです。これは、モデルがアプリでどのように機能するかをより正確に把握するためのものです。いずれの場合も、ベンチマークツールの数値は、実際のアプリでモデルを使用して推論を実行した場合とは少し異なります。
この Android ベンチマークアプリには UI がありません。adbコマンドを使用してインストールおよび実行し、adb logcatコマンドを使用して結果を取得します。
アプリをダウンロードまたはビルドする
以下のリンクを使用して、ナイトリービルドの Android ベンチマークアプリをダウンロードします。
- android_aarch64
- android_arm
Flex デリゲートを介して TF 演算をサポートする Android ベンチマークアプリは、以下のリンクをクリックしてください。
- android_aarch64
- android_arm
また、これらの説明に従って、ソースからアプリをビルドすることもできます。
注:x86 CPU または Hexagon デリゲートで Android ベンチマーク apk を実行する場合、またはモデルに Select TF 演算子またはカスタム演算子が含まれている場合は、ソースからアプリをビルドする必要があります。
ベンチマークを準備する
ベンチマークアプリを実行する前に、アプリをインストールし、次のようにモデルファイルをデバイスにプッシュします。
adb install -r -d -g android_aarch64_benchmark_model.apk
adb push your_model.tflite /data/local/tmp
ベンチマークを実行する
adb shell am start -S \
-n org.tensorflow.lite.benchmark/.BenchmarkModelActivity \
--es args '"--graph=/data/local/tmp/your_model.tflite \
--num_threads=4"'
graphは必須パラメータです。
- graph: string TFLite モデルファイルへのパス。
ベンチマークを実行するためのオプションのパラメータをさらに指定できます。
- num_threads: int (デフォルト=1) TFLite インタープリタの実行に使用するスレッドの数。
- use_gpu: bool (デフォルト=false) GPU デレゲートを使用する。
- use_nnapi: bool (デフォルト=false) NNAPI デレゲートを使用する。
- use_xnnpack: bool (デフォルト=false) XNNPACK デレゲートを使用する。
- use_hexagon: bool (デフォルト=false) Hexagon デレゲートを使用する。
使用しているデバイスによっては、これらのオプションの一部が使用できない場合や使用しても効果がない場合があります。ベンチマークアプリで実行できるその他のパフォーマンスパラメータについては、パラメータを参照してください。
logcatコマンドを使用して結果を表示します。
adb logcat | grep "Inference timings"
ベンチマーク結果は次のように報告されます。
... tflite : Inference timings in us: Init: 5685, First inference: 18535, Warmup (avg): 14462.3, Inference (avg): 14575.2
ネイティブベンチマークバイナリ
ベンチマークツールは、ネイティブバイナリBenchmark_modelとしても提供されます。このツールは、Linux、Mac、組み込みデバイス、および Android デバイスのシェルコマンドラインから実行できます。
バイナリをダウンロードまたはビルドする
以下のリンクを使用して、ナイトリービルドのネイティブコマンドラインバイナリをダウンロードします。
- linux_x86-64
- linux_aarch64
- linux_arm
- android_aarch64
- android_arm
Flex デリゲートを介して TF 演算をサポートする ナイトリ―ビルドのバイナリは、以下のリンクをクリックしてください。
- linux_x86-64
- linux_aarch64
- linux_arm
- android_aarch64
- android_arm
TensorFlow Lite Hexagon デリゲートでベンチマークを行うために、必要な libhexagon_interface.so ファイル(このファイルの詳細はこちら)も事前ビルドしました。対応するプラットフォームのファイルを以下のリンクからダウンロードしたら、ファイルの名前を libhexagon_interface.so に変更してください。
- linux_x86-64
- linux_aarch64
コンピュータのソースからネイティブベンチマークバイナリをビルドすることもできます。
bazel build -c opt //tensorflow/lite/tools/benchmark:benchmark_model
Android NDK ツールチェーンを使用してビルドするには、まずこのガイドに従ってビルド環境をセットアップするか、このガイドで説明されているように Docker イメージを使用する必要があります。
bazel build -c opt --config=android_arm64 \
//tensorflow/lite/tools/benchmark:benchmark_model
注意:ベンチマークのために Android デバイスでバイナリを直接プッシュして実行することも可能ですが、実際の Android アプリ内での実行と比較してパフォーマンスにわずかな(観察可能な)違いが生じる可能性があります。特に、Android のスケジューラーは、スレッドとプロセスの優先度に基づいて動作を調整します。これは、フォアグラウンドアクティビティ/アプリケーションとadb shell ...を介して実行される通常のバックグラウンドバイナリとの間で異なります。この調整された動作は、TensorFlow Lite でマルチスレッド CPU 実行を有効にする場合に最も顕著になります。したがって、パフォーマンス測定には Android ベンチマークアプリが推奨されます。
ベンチマークを実行する
コンピュータでベンチマークを実行するには、シェルからバイナリを実行します。
path/to/downloaded_or_built/benchmark_model \
--graph=your_model.tflite \
--num_threads=4
上記と同じパラメータのセットをネイティブコマンドラインバイナリで使用できます。
モデル演算のプロファイリング
ベンチマークモデルバイナリを使用すると、モデル演算のプロファイルを作成し、各演算子の実行時間を取得することもできます。これを実行するには、呼び出し中にフラグ--enable_op_profiling=trueをbenchmark_modelに渡します。詳細はこちらを参照してください。
1回の実行で複数のパフォーマンスオプションを実行するためのネイティブベンチマークバイナリ
また、1回の実行で複数のパフォーマンスオプションをベンチマークするために便利でシンプルな C++ バイナリが提供されています。このバイナリは、一度に1つのパフォーマンスオプションしかベンチマークできない前述のベンチマークツールに基づいて構築されています。これらは同一のビルド/インストール/実行プロセスを共有しますが、このバイナリの BUILD ターゲット名はBenchmark_model_performance_optionsで、複数の追加パラメータを取ります。このバイナリの重要なパラメータは次のとおりです。
perf_options_list: string (デフォルト='all') ベンチマークする TFLite パフォーマンスオプションのコンマ区切りリスト。
以下のリストから、このツール用にナイトリービルドのバイナリを取得できます。
- linux_x86-64
- linux_aarch64
- linux_arm
- android_aarch64
- android_arm
iOS ベンチマークアプリ
iOS デバイスでベンチマークを実行するには、ソースからアプリをビルドする必要があります。TensorFlow Lite モデルファイルをソースツリーの benchmark_data ディレクトリに配置し、Benchmark_params.jsonファイルを変更します。これらのファイルはアプリにパッケージ化され、アプリはディレクトリからデータを読み取ります。詳細については、iOS ベンチマークアプリを参照してください。
既知のモデルのパフォーマンスベンチマーク
このセクションは、一部の Android および iOS デバイスで既知のモデルを実行した場合の TensorFlow Lite のパフォーマンスベンチマークについて説明します。
Android パフォーマンスベンチマーク
これらのパフォーマンスベンチマーク数は、ネイティブベンチマークバイナリを使用して生成されています。
Android ベンチマークの場合、CPU アフィニティは、デバイスで多いコア数を使用して差異を減らすように設定されています(詳細はこちらを参照してください)。
モデルがダウンロードされ、/data/local/tmp/tflite_modelsディレクトリに解凍されたことが想定されます。ベンチマークバイナリは、これらの指示を使用して構築され、/data/local/tmpディレクトリにあると想定されます。
ベンチマークの実行:
adb shell /data/local/tmp/benchmark_model \
--num_threads=4 \
--graph=/data/local/tmp/tflite_models/${GRAPH} \
--warmup_runs=1 \
--num_runs=50
nnapi デリゲートで実行するには、-use_nnapi = trueを設定します。GPU デリゲートで実行するには、-use_gpu = trueを設定します。
以下のパフォーマンス値は Android 10 で測定されています。
| モデル名 | デバイス | CPU、4 スレッド | GPU | NNAPI |
|---|---|---|---|---|
| Mobilenet_1.0_224(float) | Pixel 3 | 23.9 ms | 6.45 ms | 13.8 ms |
| Pixel 4 | 14.0 ms | 9.0 ms | 14.8 ms | |
| Mobilenet_1.0_224 (quant) | Pixel 3 | 13.4 ms | --- | 6.0 ms |
| Pixel 4 | 5.0 ms | --- | 3.2 ms | |
| NASNet mobile | Pixel 3 | 56 ms | --- | 102 ms |
| Pixel 4 | 34.5 ms | --- | 99.0 ms | |
| SqueezeNet | Pixel 3 | 35.8 ms | 9.5 ms | 18.5 ms |
| Pixel 4 | 23.9 ms | 11.1 ms | 19.0 ms | |
| Inception_ResNet_V2 | Pixel 3 | 422 ms | 99.8 ms | 201 ms |
| Pixel 4 | 272.6 ms | 87.2 ms | 171.1 ms | |
| Inception_V4 | Pixel 3 | 486 ms | 93 ms | 292 ms |
| Pixel 4 | 324.1 ms | 97.6 ms | 186.9 ms |
iOS パフォーマンスベンチマーク
これらのパフォーマンスベンチマークの数値は、iOS ベンチマークアプリを使用して生成されています。
iOS ベンチマークを実行するために、適切なモデルを含めるためにベンチマークアプリが変更され、num_threadsを2に設定するためにbenchmark_params.jsonが変更されました。また、GPU デリゲートを使用するために、"use_gpu" : "1"および"gpu_wait_type" : "aggressive"オプションもbenchmark_params.jsonに追加されました 。
| モデル名 | デバイス | CPU、2 スレッド | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | iPhone XS | 14.8 ms | 3.4 ms |
| Mobilenet_1.0_224 (quant) | iPhone XS | 11 ms | --- |
| NASNet mobile | iPhone XS | 30.4 ms | --- |
| SqueezeNet | iPhone XS | 21.1 ms | 15.5 ms |
| Inception_ResNet_V2 | iPhone XS | 261.1 ms | 45.7 ms |
| Inception_V4 | iPhone XS | 309 ms | 54.4 ms |
TensorFlow Lite の内部をトレースする
Android で TensorFlow Lite の内部をトレースする
注意: この機能は Tensorflow Lite v2.4 以降で利用できます。
Android アプリの TensorFlow Lite インタープリタからの内部イベントは、Android トレースツールでキャプチャできます。これは Android Trace API と同じイベントであるため、Java/Kotlin コードからキャプチャされたイベントは TensorFlow Lite 内部イベントと共に表示されます。
イベントの例は次のとおりです。
- 演算子の呼び出し
- デリゲートによるグラフの変更
- テンソルの割り当て
トレースをキャプチャするオプションは複数ありますが、本ガイドでは Android Studio CPU Profiler とシステムトレースアプリについて説明します。その他のオプションについては、Perfetto コマンドラインツールまたは Systrace コマンドラインツールを参照してください。
Java コードにトレースイベントを追加する
これは、画像分類サンプルアプリのコードスニペットです。TensorFlow Lite インタープリタは、recognizeImage/runInferenceセクションで実行されます。この手順はオプションですが、推論呼び出しが行われた場所を確認するのに役立ちます。
Trace.beginSection("recognizeImage");
...
// Runs the inference call.
Trace.beginSection("runInference");
tflite.run(inputImageBuffer.getBuffer(), outputProbabilityBuffer.getBuffer().rewind());
Trace.endSection();
...
Trace.endSection();
TensorFlow Lite トレースを有効にする
TensorFlow Lite トレースを有効にするには、Android アプリを起動する前に、Android システムプロパティの debug.tflite.trace を1に設定します。
adb shell setprop debug.tflite.trace 1
TensorFlow Lite インタープリタの初期化時にこのプロパティが設定されている場合、インタープリタからの主要なイベント(演算子の呼び出しなど)がトレースされます。
すべてのトレースをキャプチャしたら、プロパティ値を0に設定してトレースを無効にします。
adb shell setprop debug.tflite.trace 0
Android Studio CPU Profiler
以下の手順に従って、Android Studio CPU Profiler でトレースをキャプチャします。
トップメニューから実行>プロファイル「アプリ」を選択します。
プロファイラーウィンドウが表示されたら、CPU タイムラインの任意の場所をクリックします。
CPU プロファイリングモードから「システムコールのトレース」を選択します。
「記録」ボタンを押します。
「停止」ボタンを押します。
トレース結果を調査します。
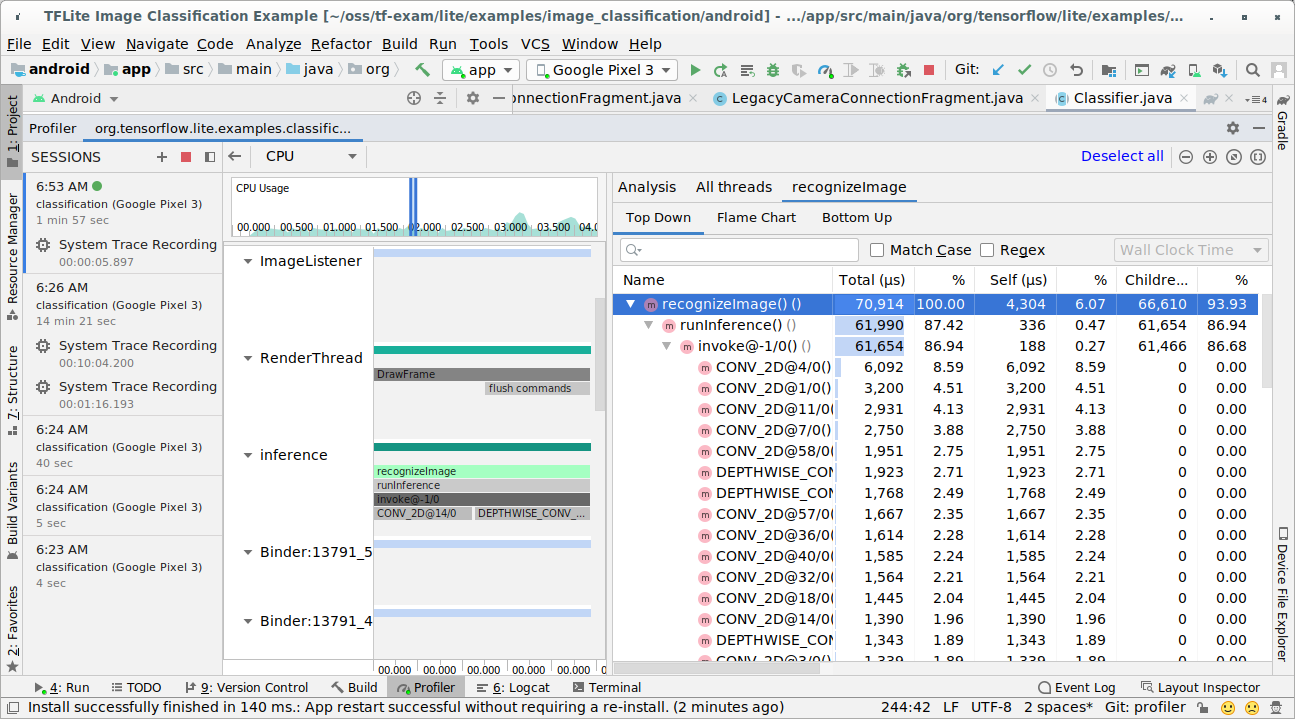
この例では、スレッド内のイベントの階層と各演算子の時間の統計、および、スレッド間のアプリ全体のデータフローを確認できます。
システムトレースアプリ
Android Studio を使用せずにトレースをキャプチャするにはシステムトレースアプリで詳しく説明されている手順に従います。
この例では、同じ TFLite イベントがキャプチャされ、Android デバイスのバージョンに応じて、Perfetto または Systrace 形式で保存されました。キャプチャされたトレースファイルは、Perfetto UI で開くことができます。
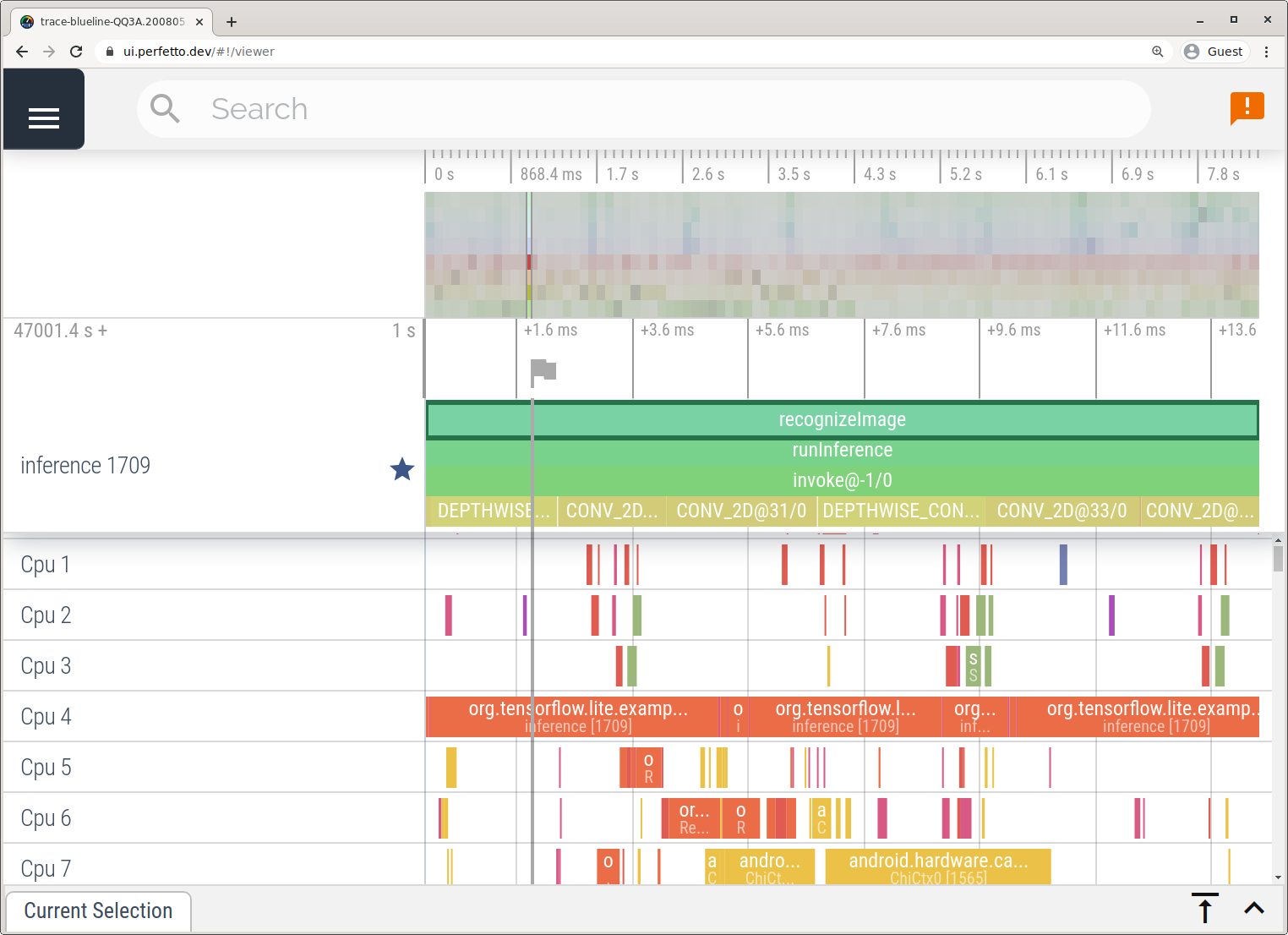
iOS で TensorFlow Lite の内部をトレースする
注意: この機能は Tensorflow Lite v2.5 以降で利用できます。
iOS アプリの TensorFlow Lite インタープリターからの内部イベントは、Xcode に含まれる Instruments ツールでキャプチャできます。これは iOS の Signpost イベントであるため、Swift/Objective-C コードからキャプチャされたイベントは、TensorFlow Lite 内部イベントと共に表示されます。
イベントの例は次のとおりです。
- 演算子の呼び出し
- デリゲートによるグラフの変更
- テンソルの割り当て
TensorFlow Lite トレースを有効にする
以下の手順に従って、環境変数 debug.tflite.trace を設定します。
Xcode のトップメニューから Product > Scheme > Edit Scheme... を選択します。
左ペインの 'Profile' をクリックします。
'Use the Run action's arguments and environment variables' チェックボックスをオフにします。
'Environment Variables' セクションに
debug.tflite.traceを追加します。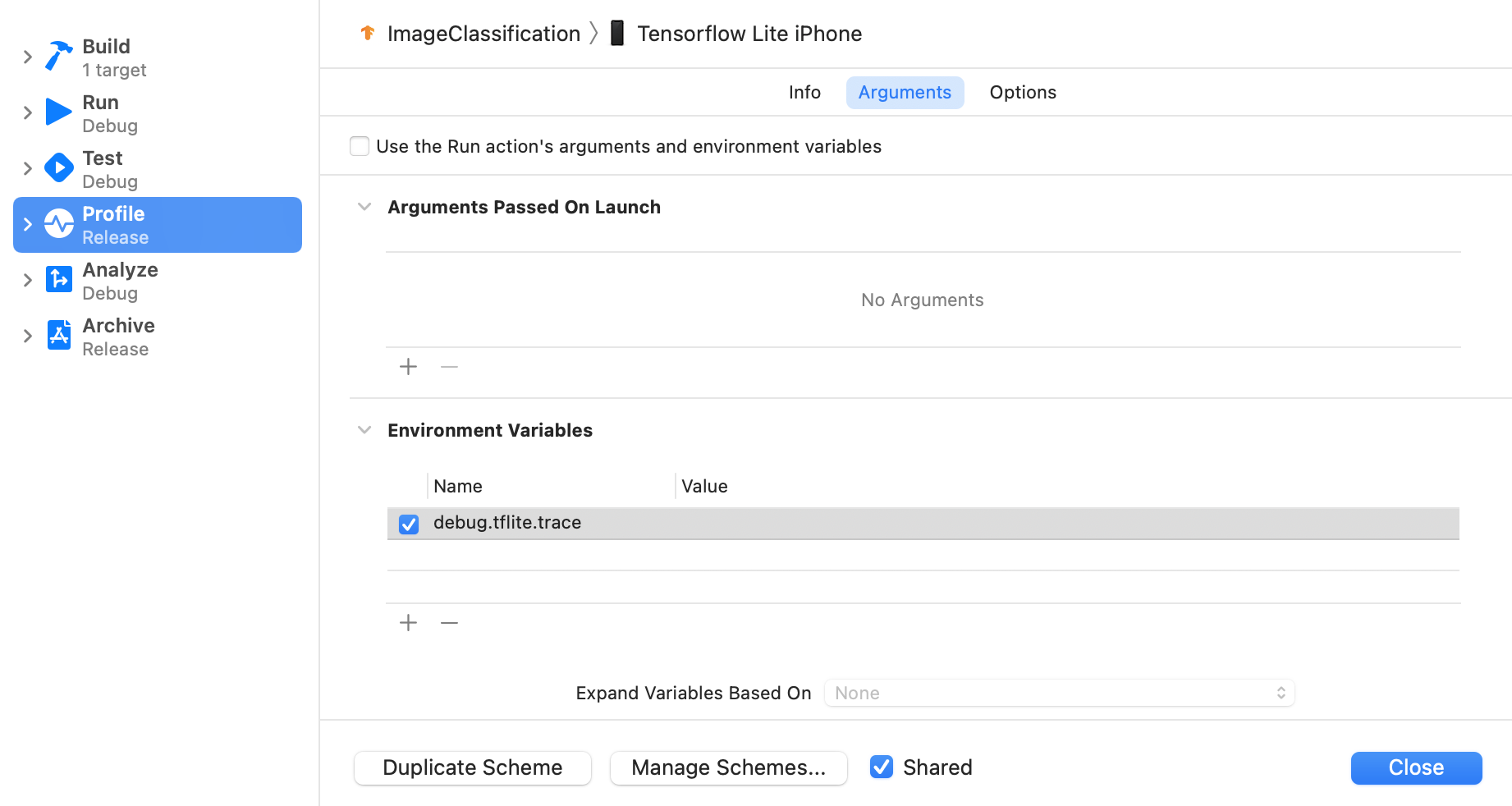
iOS アプリをプロファイリングする際に TesorFlow Lite イベントを除外する場合は、環境変数を削除してトレースを無効にします。
XCode Instruments
以下の手順に従って、トレースをキャプチャします。
Xcode のトップメニューから Product > Profile を選択します。
Instruments ツールが起動する際に、プロファイリングテンプレートの中から Logging をクリックします。
'Start' ボタンを押します。
「停止」ボタンを押します。
'os_signpost' をクリックして、OS Logging のサブシステムアイテムを展開します。
'org.tensorflow.lite' OS Logging サブシステムをクリックします。
トレース結果を調査します。
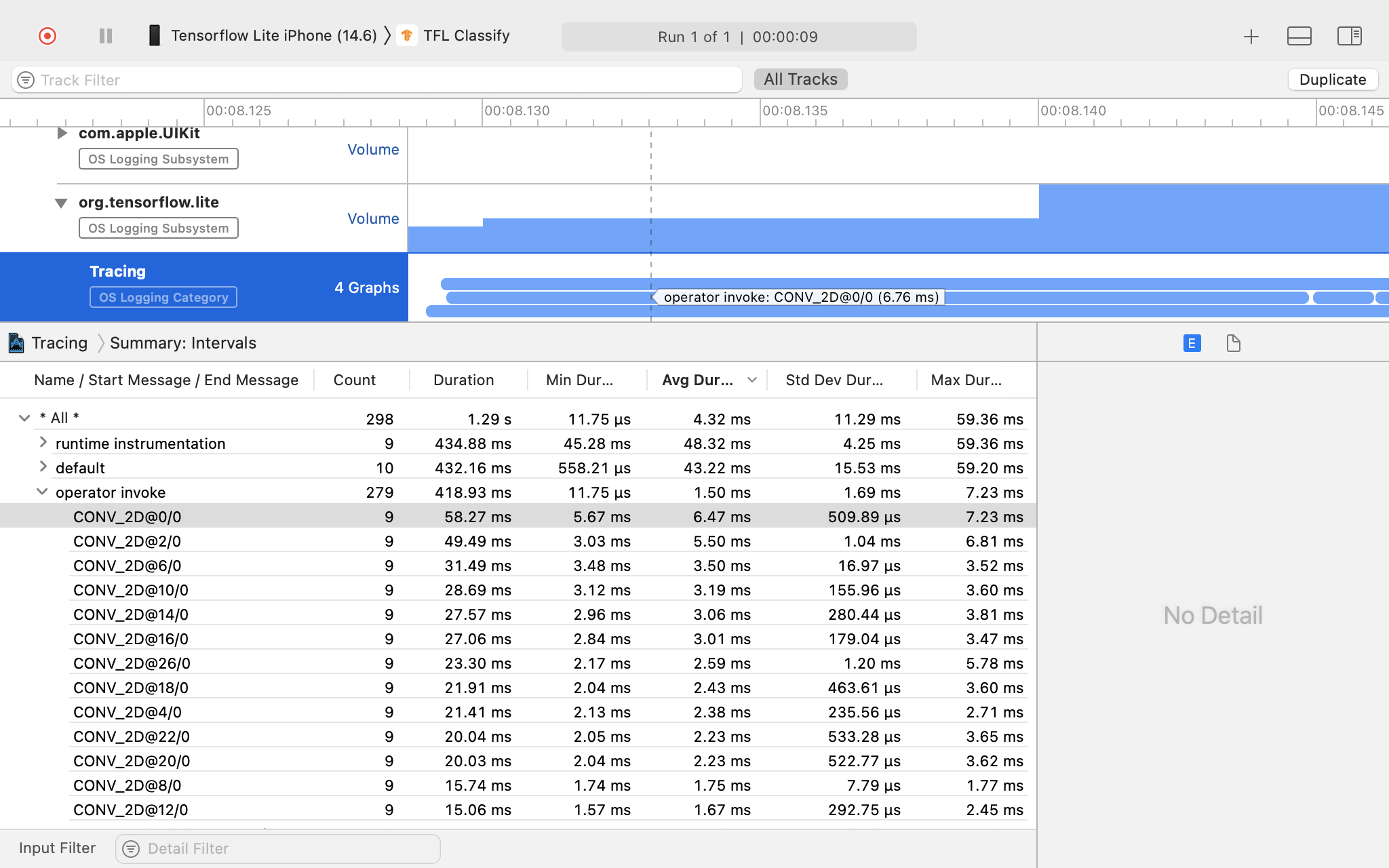
この例では、演算子の時間ごとにイベントと統計の階層が表示されます。
トレースデータの使用
トレースデータを使用すると、パフォーマンスのボトルネックを特定できます。
以下はプロファイラーから得られる洞察とパフォーマンスを向上させるための潜在的なソリューションの例です。
- 使用可能な CPU コアの数が推論スレッドの数よりも少ない場合、CPU スケジューリングのオーバーヘッドがパフォーマンスを低下させる可能性があります。アプリで他の CPU を集中的に使用するタスクを再スケジュールし、モデルの推論との重複を回避したり、インタープリタースレッドの数を微調整したりできます。
- 演算子が完全にデレゲートされていない場合、モデルグラフの一部は、期待されるハードウェアアクセラレータではなく、CPU で実行されます。サポートされていない演算子は、同様のサポートされている演算子に置き換えます。