
TL;DR : צמצם את קוד ה-boilerplate כדי לבנות, לאמן ולהגיש דגמי דירוג TensorFlow עם TensorFlow Ranking Pipelines; השתמש באסטרטגיות מבוזרות נאותות עבור יישומי דירוג בקנה מידה גדול בהתחשב במקרה השימוש והמשאבים.
מָבוֹא
TensorFlow Ranking Pipeline מורכב מסדרה של תהליכי עיבוד נתונים, בניית מודלים, הדרכה והגשה המאפשרים לך לבנות, לאמן ולהגיש מודלים מדרגיים מבוססי רשתות עצביות מתוך יומני נתונים במינימום מאמצים. הצינור יעיל ביותר כאשר המערכת מגדילה את קנה המידה. באופן כללי, אם המודל שלך לוקח 10 דקות או יותר לרוץ על מכונה בודדת, שקול להשתמש במסגרת צינור זו כדי לפזר את העומס ולהאיץ את העיבוד.
צינור הדירוג של TensorFlow הופעל באופן קבוע ויציב בניסויים והפקות בקנה מידה גדול עם נתונים גדולים (טרה-בייט+) ודגמים גדולים (100M+ של FLOPs) במערכות מבוזרות (1K+ CPU ו-100+ GPU ו-TPUs). לאחר שהוכח מודל TensorFlow עם model.fit על חלק קטן מהנתונים, הצינור מומלץ לסריקת היפר-פרמטרים, אימון רציף ושאר מצבים בקנה מידה גדול.
דירוג צינור
ב-TensorFlow, צינור טיפוסי לבנייה, הדרכה ושירות של מודל דירוג כולל את השלבים האופייניים הבאים.
- הגדר את מבנה המודל:
- יצירת תשומות;
- צור שכבות עיבוד מקדים;
- צור ארכיטקטורת רשת עצבית;
- דגם רכבת:
- צור מערכי נתונים של רכבות ואימות מיומני נתונים;
- הכן את המודל עם הפרמטרים המתאימים:
- ייעול;
- דירוג הפסדים;
- מדדי דירוג;
- הגדר אסטרטגיות מבוזרות לאימון על פני מספר מכשירים.
- הגדרת התקשרות חוזרת עבור הנהלת חשבונות שונות.
- דגם ייצוא להגשה;
- דגם הגשה:
- קבע פורמט נתונים בעת ההגשה;
- בחר וטען דגם מאומן;
- תהליך עם דגם טעון.
אחת המטרות העיקריות של צינור דירוג TensorFlow היא לצמצם את קוד ה-boilerplate בשלבים, כגון טעינת נתונים ועיבוד מקדים, תאימות של נתונים רשימתיים ופונקציית ניקוד נקודתית, ויצוא מודלים. המטרה החשובה הנוספת היא לאכוף את התכנון העקבי של תהליכים רבים המתואמים מטבעם, למשל, תשומות המודל חייבות להיות תואמות הן למערכי נתונים של אימון והן לפורמט הנתונים בעת ההגשה.
השתמש במדריך
עם כל העיצוב שלעיל, השקת מודל בדירוג TF נופלת לשלבים הבאים, כפי שמוצג באיור 1.
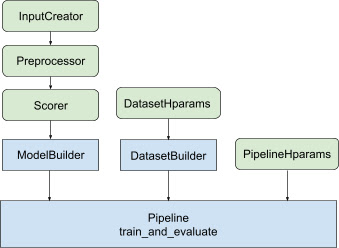
דוגמה באמצעות רשת עצבית מבוזרת
בדוגמה זו, תמנף את ה- tfr.keras.model.FeatureSpecInputCreator המובנה, tfr.keras.pipeline.SimpleDatasetBuilder ו- tfr.keras.pipeline.SimplePipeline שמקבלים את s feature_spec כדי להגדיר באופן עקבי את תכונות הקלט בתשומות המודל שרת נתונים. ניתן למצוא את גרסת המחברת עם הדרכה שלב אחר שלב במדריך דירוג מבוזר .
תחילה הגדר את feature_spec עבור תכונות ההקשר והן לדוגמה.
context_feature_spec = {}
example_feature_spec = {
'custom_features_{}'.format(i + 1):
tf.io.FixedLenFeature(shape=(1,), dtype=tf.float32, default_value=0.0)
for i in range(10)
}
label_spec = ('utility', tf.io.FixedLenFeature(
shape=(1,), dtype=tf.float32, default_value=-1))
בצע את השלבים המוצגים באיור 1:
הגדר input_creator מ- feature_spec .
input_creator = tfr.keras.model.FeatureSpecInputCreator(
context_feature_spec, example_feature_spec)
לאחר מכן הגדר טרנספורמציות של תכונות עיבוד מקדים עבור אותה קבוצה של תכונות קלט.
def log1p(tensor):
return tf.math.log1p(tensor * tf.sign(tensor)) * tf.sign(tensor)
preprocessor = {
'custom_features_{}'.format(i + 1): log1p
for i in range(10)
}
הגדר סקורר עם מודל DNN מובנה של FeedForward.
dnn_scorer = tfr.keras.model.DNNScorer(
hidden_layer_dims=[1024, 512, 256],
output_units=1,
activation=tf.nn.relu,
use_batch_norm=True,
batch_norm_moment=0.99,
dropout=0.4)
צור את model_builder עם input_creator , preprocessor scorer .
model_builder = tfr.keras.model.ModelBuilder(
input_creator=input_creator,
preprocessor=preprocessor,
scorer=dnn_scorer,
mask_feature_name='__list_mask__',
name='web30k_dnn_model')
כעת הגדר את הפרמטרים ההיפר עבור dataset_builder .
dataset_hparams = tfr.keras.pipeline.DatasetHparams(
train_input_pattern='/path/to/MSLR-WEB30K-ELWC/train-*',
valid_input_pattern='/path/to/MSLR-WEB30K-ELWC/vali-*',
train_batch_size=128,
valid_batch_size=128,
list_size=200,
dataset_reader=tf.data.RecordIODataset,
convert_labels_to_binary=False)
צור את dataset_builder .
tfr.keras.pipeline.SimpleDatasetBuilder(
context_feature_spec=context_feature_spec,
example_feature_spec=example_feature_spec,
mask_feature_name='__list_mask__',
label_spec=label_spec,
hparams=dataset_hparams)
הגדר גם את הפרמטרים ההיפר של הצינור.
pipeline_hparams = tfr.keras.pipeline.PipelineHparams(
model_dir='/tmp/web30k_dnn_model',
num_epochs=100,
num_train_steps=100000,
num_valid_steps=100,
loss='softmax_loss',
loss_reduction=tf.losses.Reduction.AUTO,
optimizer='adam',
learning_rate=0.0001,
steps_per_execution=100,
export_best_model=True,
strategy='MirroredStrategy',
tpu=None)
עשה את ranking_pipeline ותאמן.
ranking_pipeline = tfr.keras.pipeline.SimplePipeline(
model_builder=model_builder,
dataset_builder=dataset_builder,
hparams=pipeline_hparams,
)
ranking_pipeline.train_and_validate()
עיצוב צינור דירוג TensorFlow
צינור הדירוג של TensorFlow מסייע לחסוך בזמן הנדסי עם קוד ה-boilerplate, בו-זמנית, מאפשר גמישות של התאמה אישית באמצעות דריסה וסיווג משנה. כדי להשיג זאת, הצינור מציג מחלקות הניתנות להתאמה אישית tfr.keras.model.AbstractModelBuilder , tfr.keras.pipeline.AbstractDatasetBuilder ו- tfr.keras.pipeline.AbstractPipeline כדי להגדיר את צינור דירוג TensorFlow.

בונה מודלים
קוד ה-boilerplate הקשור לבניית מודל Keras משולב ב- AbstractModelBuilder , אשר מועבר ל- AbstractPipeline ונקרא בתוך ה-pipeline כדי לבנות את המודל במסגרת האסטרטגיה. זה מוצג באיור 1. שיטות מחלקות מוגדרות במחלקת הבסיס המופשטת.
class AbstractModelBuilder:
def __init__(self, mask_feature_name, name):
@abstractmethod
def create_inputs(self):
// To create tf.keras.Input. Abstract method, to be overridden.
...
@abstractmethod
def preprocess(self, context_inputs, example_inputs, mask):
// To preprocess input features. Abstract method, to be overridden.
...
@abstractmethod
def score(self, context_features, example_features, mask):
// To score based on preprocessed features. Abstract method, to be overridden.
...
def build(self):
context_inputs, example_inputs, mask = self.create_inputs()
context_features, example_features = self.preprocess(
context_inputs, example_inputs, mask)
logits = self.score(context_features, example_features, mask)
return tf.keras.Model(inputs=..., outputs=logits, name=self._name)
אתה יכול ישירות לסווג את AbstractModelBuilder ולדרוס עם השיטות הקונקרטיות להתאמה אישית, כמו
class MyModelBuilder(AbstractModelBuilder):
def create_inputs(self, ...):
...
במקביל, עליך להשתמש ModelBuilder עם תכונות קלט, טרנספורמציות קדם-תהליכיות ופונקציות ניקוד שצוינו ככניסות פונקציות input_creator , preprocessor ו- scorer במחלקה init במקום סיווג משנה.
class ModelBuilder(AbstractModelBuilder):
def __init__(self, input_creator, preprocessor, scorer, mask_feature_name, name):
...
כדי לצמצם את הלוחיות של יצירת תשומות אלה, מסופקות מחלקות פונקציות tfr.keras.model.InputCreator עבור input_creator , tfr.keras.model.Preprocessor עבור preprocessor ו- tfr.keras.model.Scorer עבור scorer , יחד עם תת-מחלקות קונקרטיות tfr.keras.model.FeatureSpecInputCreator , tfr.keras.model.TypeSpecInputCreator , tfr.keras.model.PreprocessorWithSpec , tfr.keras.model.UnivariateScorer , tfr.keras.model.DNNScorer ו- tfr.keras.model.GAMScorer . אלה אמורים לכסות את רוב מקרי השימוש הנפוצים.
שימו לב שמחלקות הפונקציות הללו הן מחלקות Keras, כך שאין צורך בהמשכה. סיווג משנה הוא הדרך המומלצת להתאמה אישית שלהם.
DatasetBuilder
המחלקה DatasetBuilder אוספת לוח נתונים הקשורים למערך נתונים. הנתונים מועברים ל- Pipeline ונקראים לשרת את מערכי ההדרכה והאימות ולהגדרת חתימות ההגשה עבור מודלים שמורים. כפי שמוצג באיור 1, שיטות DatasetBuilder מוגדרות במחלקת הבסיס tfr.keras.pipeline.AbstractDatasetBuilder ,
class AbstractDatasetBuilder:
@abstractmethod
def build_train_dataset(self, *arg, **kwargs):
// To return the training dataset.
...
@abstractmethod
def build_valid_dataset(self, *arg, **kwargs):
// To return the validation dataset.
...
@abstractmethod
def build_signatures(self, *arg, **kwargs):
// To build the signatures to export saved model.
...
במחלקה קונקרטית DatasetBuilder , עליך ליישם build_train_datasets , build_valid_datasets ו- build_signatures .
מחלקה קונקרטית המייצרת מערכי נתונים מ- feature_spec s מסופקת גם:
class BaseDatasetBuilder(AbstractDatasetBuilder):
def __init__(self, context_feature_spec, example_feature_spec,
training_only_example_spec,
mask_feature_name, hparams,
training_only_context_spec=None):
// Specify label and weight specs in training_only_example_spec.
...
def _features_and_labels(self, features):
// To split the labels and weights from input features.
...
def _build_dataset(self, ...):
return tfr.data.build_ranking_dataset(
context_feature_spec+training_only_context_spec,
example_feature_spec+training_only_example_spec, mask_feature_name, ...)
def build_train_dataset(self):
return self._build_dataset(...)
def build_valid_dataset(self):
return self._build_dataset(...)
def build_signatures(self, model):
return saved_model.Signatures(model, context_feature_spec,
example_feature_spec, mask_feature_name)()
ה- hparams המשמשים ב- DatasetBuilder מצוינים במחלקת הנתונים tfr.keras.pipeline.DatasetHparams .
צינור
צינור הדירוג מבוסס על המחלקה tfr.keras.pipeline.AbstractPipeline :
class AbstractPipeline:
@abstractmethod
def build_loss(self):
// Returns a tf.keras.losses.Loss or a dict of Loss. To be overridden.
...
@abstractmethod
def build_metrics(self):
// Returns a list of evaluation metrics. To be overridden.
...
@abstractmethod
def build_weighted_metrics(self):
// Returns a list of weighted metrics. To be overridden.
...
@abstractmethod
def train_and_validate(self, *arg, **kwargs):
// Main function to run the training pipeline. To be overridden.
...
מסופק גם מחלקה של צינורות בטון שמכשירה את הדגם עם tf.distribute.strategy שונות התואמות ל- model.fit :
class ModelFitPipeline(AbstractPipeline):
def __init__(self, model_builder, dataset_builder, hparams):
...
def build_callbacks(self):
// Builds callbacks used in model.fit. Override for customized usage.
...
def export_saved_model(self, model, export_to, checkpoint=None):
if checkpoint:
model.load_weights(checkpoint)
model.save(export_to, signatures=dataset_builder.build_signatures(model))
def train_and_validate(self, verbose=0):
with self._strategy.scope():
model = model_builder.build()
model.compile(
optimizer,
loss=self.build_loss(),
metrics=self.build_metrics(),
loss_weights=self.hparams.loss_weights,
weighted_metrics=self.build_weighted_metrics())
train_dataset, valid_dataset = (
dataset_builder.build_train_dataset(),
dataset_builder.build_valid_dataset())
model.fit(
x=train_dataset,
validation_data=valid_dataset,
callbacks=self.build_callbacks(),
verbose=verbose)
self.export_saved_model(model, export_to=model_output_dir)
ה- hparams המשמשים ב- tfr.keras.pipeline.ModelFitPipeline מצוינים במחלקת הנתונים tfr.keras.pipeline.PipelineHparams . מחלקה ModelFitPipeline זו מספיקה עבור רוב מקרי השימוש ב-TF Ranking. לקוחות יכולים בקלות לסווג אותו למטרות ספציפיות.
תמיכה באסטרטגיה מבוזרת
אנא עיין בהדרכה מבוזרת לקבלת מבוא מפורט של אסטרטגיות מבוזרות הנתמכות ב-TensorFlow. נכון לעכשיו, צינור הדירוג של TensorFlow תומך ב- tf.distribute.MirroredStrategy (ברירת מחדל), tf.distribute.TPUStrategy , tf.distribute.MultiWorkerMirroredStrategy ו- tf.distribute.ParameterServerStrategy . אסטרטגיית שיקוף תואמת לרוב מערכות המכונה הבודדת. אנא הגדר strategy ל- None עבור אסטרטגיה לא מבוזרת.
באופן כללי, MirroredStrategy עובד עבור דגמים קטנים יחסית ברוב המכשירים עם אפשרויות מעבד ו-GPU. MultiWorkerMirroredStrategy עובד עבור דגמים גדולים שאינם מתאימים לעובד אחד. ParameterServerStrategy מבצע אימון אסינכרוני ודורש מספר עובדים זמינים. TPUStrategy היא אידיאלית עבור דגמים גדולים וביג דאטה כאשר TPUs זמינים, עם זאת, היא פחות גמישה מבחינת צורות הטנזור שהיא יכולה להתמודד.
שאלות נפוצות
סט הרכיבים המינימלי לשימוש ב-
RankingPipeline
ראה קוד לדוגמה למעלה.מה אם יש לי
modelמשלי של קרס
כדי להיות מאומן עם אסטרטגיותtf.distribute,modelצריך להיות בנוי עם כל המשתנים הניתנים לאימון המוגדרים תחת ה-strategi.scope(). אז עטפו את הדגם שלכם ב-ModelBuilderכמו,
class MyModelBuilder(AbstractModelBuilder):
def __init__(self, model, context_feature_names, example_feature_names,
mask_feature_name, name):
super().__init__(mask_feature_name, name)
self._model = model
self._context_feature_names = context_feature_names
self._example_feature_names = example_feature_names
def create_inputs(self):
inputs = self._model.input
context_inputs = {inputs[name] for name in self._context_feature_names}
example_inputs = {inputs[name] for name in self._example_feature_names}
mask = inputs[self._mask_feature_name]
return context_inputs, example_inputs, mask
def preprocess(self, context_inputs, example_inputs, mask):
return context_inputs, example_inputs, mask
def score(self, context_features, example_features, mask):
inputs = dict(
list(context_features.items()) + list(example_features.items()) +
[(self._mask_feature_name, mask)])
return self._model(inputs)
model_builder = MyModelBuilder(model, context_feature_names, example_feature_names,
mask_feature_name, "my_model")
לאחר מכן הזינו את בונה המודלים הזה לצינור להכשרה נוספת.