
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
סקירה כללית
ה-API של tf.distribute.Strategy מספק הפשטה להפצת ההדרכה שלך על פני מספר יחידות עיבוד. היא מאפשרת לבצע הדרכה מבוזרת באמצעות מודלים קיימים וקוד הדרכה במינימום שינויים.
מדריך זה מדגים כיצד להשתמש tf.distribute.MirroredStrategy כדי לבצע שכפול בתוך גרף עם אימון סינכרוני על GPUs רבים במכונה אחת . האסטרטגיה בעצם מעתיקה את כל המשתנים של המודל לכל מעבד. לאחר מכן, הוא משתמש ב- all-reduce כדי לשלב את ההדרגות מכל המעבדים, ומחיל את הערך המשולב על כל העותקים של המודל.
אתה תשתמש בממשקי ה-API של tf.keras כדי לבנות את המודל וב- Model.fit להכשרתו. (כדי ללמוד על אימון מבוזר עם לולאת אימון מותאמת אישית MirroredStrategy , עיין במדריך זה .)
MirroredStrategy מאמן את הדגם שלך על מספר GPUs במכונה אחת. לאימון סינכרוני על GPUs רבים על מספר עובדים , השתמש tf.distribute.MultiWorkerMirroredStrategy עם ה-Keras Model.fit או לולאת אימון מותאמת אישית . לאפשרויות אחרות, עיין במדריך ההדרכה המבוזר .
כדי ללמוד על אסטרטגיות שונות אחרות, יש את המדריך המבוזר עם TensorFlow .
להכין
import tensorflow_datasets as tfds
import tensorflow as tf
import os
# Load the TensorBoard notebook extension.
%load_ext tensorboard
print(tf.__version__)
2.8.0-rc1
הורד את מערך הנתונים
טען את מערך הנתונים של MNIST מ- TensorFlow Datasets . זה מחזיר מערך נתונים בפורמט tf.data .
הגדרת הארגומנט with_info ל- True כוללת את המטא נתונים עבור מערך הנתונים כולו, שנשמר כאן ל- info . בין היתר, אובייקט מטא-נתונים זה כולל את מספר דוגמאות הרכבת והמבחן.
datasets, info = tfds.load(name='mnist', with_info=True, as_supervised=True)
mnist_train, mnist_test = datasets['train'], datasets['test']
הגדר את אסטרטגיית ההפצה
צור אובייקט MirroredStrategy . זה יטפל בהפצה ויספק מנהל הקשר ( MirroredStrategy.scope ) כדי לבנות את המודל שלך בפנים.
strategy = tf.distribute.MirroredStrategy()
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
print('Number of devices: {}'.format(strategy.num_replicas_in_sync))
Number of devices: 1
הגדר את צינור הקלט
בעת אימון מודל עם מספר GPUs, אתה יכול להשתמש בכוח המחשוב הנוסף ביעילות על ידי הגדלת גודל האצווה. באופן כללי, השתמש בגודל האצווה הגדול ביותר שמתאים לזיכרון ה-GPU וכוון את קצב הלמידה בהתאם.
# You can also do info.splits.total_num_examples to get the total
# number of examples in the dataset.
num_train_examples = info.splits['train'].num_examples
num_test_examples = info.splits['test'].num_examples
BUFFER_SIZE = 10000
BATCH_SIZE_PER_REPLICA = 64
BATCH_SIZE = BATCH_SIZE_PER_REPLICA * strategy.num_replicas_in_sync
הגדר פונקציה המנרמלת את ערכי הפיקסלים של התמונה מטווח [0, 255] לטווח [0, 1] ( קנה מידה של תכונה ):
def scale(image, label):
image = tf.cast(image, tf.float32)
image /= 255
return image, label
החל את פונקציית scale הזו על נתוני האימון והבדיקה, ולאחר מכן השתמש בממשקי API של tf.data.Dataset כדי לערבב את נתוני האימון ( Dataset.shuffle ), ולצרף אותם באצוות ( Dataset.batch ). שימו לב שאתם גם שומרים מטמון בזיכרון של נתוני האימון כדי לשפר את הביצועים ( Dataset.cache ).
train_dataset = mnist_train.map(scale).cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
eval_dataset = mnist_test.map(scale).batch(BATCH_SIZE)
צור את הדגם
צור והידור מודל Keras בהקשר של Strategy.scope :
with strategy.scope():
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10)
])
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
הגדר את ההתקשרות חזרה
הגדר את ה- tf.keras.callbacks הבאים:
-
tf.keras.callbacks.TensorBoard: כותב יומן עבור TensorBoard, המאפשר לך לדמיין את הגרפים. -
tf.keras.callbacks.ModelCheckpoint: שומר את המודל בתדירות מסוימת, כגון לאחר כל תקופה. -
tf.keras.callbacks.LearningRateScheduler: מתזמן את קצב הלמידה להשתנות לאחר, למשל, כל תקופה/אצווה.
למטרות המחשה, הוסף התקשרות חוזרת מותאמת אישית בשם PrintLR כדי להציג את קצב הלמידה במחברת.
# Define the checkpoint directory to store the checkpoints.
checkpoint_dir = './training_checkpoints'
# Define the name of the checkpoint files.
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt_{epoch}")
# Define a function for decaying the learning rate.
# You can define any decay function you need.
def decay(epoch):
if epoch < 3:
return 1e-3
elif epoch >= 3 and epoch < 7:
return 1e-4
else:
return 1e-5
# Define a callback for printing the learning rate at the end of each epoch.
class PrintLR(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
print('\nLearning rate for epoch {} is {}'.format(epoch + 1,
model.optimizer.lr.numpy()))
# Put all the callbacks together.
callbacks = [
tf.keras.callbacks.TensorBoard(log_dir='./logs'),
tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_prefix,
save_weights_only=True),
tf.keras.callbacks.LearningRateScheduler(decay),
PrintLR()
]
לאמן ולהעריך
כעת, אמנו את המודל בדרך הרגילה על ידי קריאת Model.fit במודל והעברת מערך הנתונים שנוצר בתחילת המדריך. שלב זה זהה בין אם אתה מפיץ את ההדרכה ובין אם לא.
EPOCHS = 12
model.fit(train_dataset, epochs=EPOCHS, callbacks=callbacks)
2022-01-26 05:38:28.865380: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:547] The `assert_cardinality` transformation is currently not handled by the auto-shard rewrite and will be removed.
Epoch 1/12
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
933/938 [============================>.] - ETA: 0s - loss: 0.2029 - accuracy: 0.9399
Learning rate for epoch 1 is 0.0010000000474974513
938/938 [==============================] - 10s 4ms/step - loss: 0.2022 - accuracy: 0.9401 - lr: 0.0010
Epoch 2/12
930/938 [============================>.] - ETA: 0s - loss: 0.0654 - accuracy: 0.9813
Learning rate for epoch 2 is 0.0010000000474974513
938/938 [==============================] - 3s 3ms/step - loss: 0.0652 - accuracy: 0.9813 - lr: 0.0010
Epoch 3/12
931/938 [============================>.] - ETA: 0s - loss: 0.0453 - accuracy: 0.9864
Learning rate for epoch 3 is 0.0010000000474974513
938/938 [==============================] - 3s 3ms/step - loss: 0.0453 - accuracy: 0.9864 - lr: 0.0010
Epoch 4/12
923/938 [============================>.] - ETA: 0s - loss: 0.0246 - accuracy: 0.9933
Learning rate for epoch 4 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0244 - accuracy: 0.9934 - lr: 1.0000e-04
Epoch 5/12
929/938 [============================>.] - ETA: 0s - loss: 0.0211 - accuracy: 0.9944
Learning rate for epoch 5 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0212 - accuracy: 0.9944 - lr: 1.0000e-04
Epoch 6/12
930/938 [============================>.] - ETA: 0s - loss: 0.0192 - accuracy: 0.9950
Learning rate for epoch 6 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0194 - accuracy: 0.9950 - lr: 1.0000e-04
Epoch 7/12
927/938 [============================>.] - ETA: 0s - loss: 0.0179 - accuracy: 0.9953
Learning rate for epoch 7 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0179 - accuracy: 0.9953 - lr: 1.0000e-04
Epoch 8/12
938/938 [==============================] - ETA: 0s - loss: 0.0153 - accuracy: 0.9966
Learning rate for epoch 8 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0153 - accuracy: 0.9966 - lr: 1.0000e-05
Epoch 9/12
927/938 [============================>.] - ETA: 0s - loss: 0.0151 - accuracy: 0.9966
Learning rate for epoch 9 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0150 - accuracy: 0.9966 - lr: 1.0000e-05
Epoch 10/12
935/938 [============================>.] - ETA: 0s - loss: 0.0148 - accuracy: 0.9966
Learning rate for epoch 10 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0148 - accuracy: 0.9966 - lr: 1.0000e-05
Epoch 11/12
937/938 [============================>.] - ETA: 0s - loss: 0.0146 - accuracy: 0.9967
Learning rate for epoch 11 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0146 - accuracy: 0.9967 - lr: 1.0000e-05
Epoch 12/12
926/938 [============================>.] - ETA: 0s - loss: 0.0145 - accuracy: 0.9967
Learning rate for epoch 12 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0144 - accuracy: 0.9967 - lr: 1.0000e-05
<keras.callbacks.History at 0x7fad70067c10>
בדוק אם יש מחסומים שמורים:
# Check the checkpoint directory.ls {checkpoint_dir}
checkpoint ckpt_4.data-00000-of-00001 ckpt_1.data-00000-of-00001 ckpt_4.index ckpt_1.index ckpt_5.data-00000-of-00001 ckpt_10.data-00000-of-00001 ckpt_5.index ckpt_10.index ckpt_6.data-00000-of-00001 ckpt_11.data-00000-of-00001 ckpt_6.index ckpt_11.index ckpt_7.data-00000-of-00001 ckpt_12.data-00000-of-00001 ckpt_7.index ckpt_12.index ckpt_8.data-00000-of-00001 ckpt_2.data-00000-of-00001 ckpt_8.index ckpt_2.index ckpt_9.data-00000-of-00001 ckpt_3.data-00000-of-00001 ckpt_9.index ckpt_3.index
כדי לבדוק עד כמה המודל מתפקד, טען את נקודת הבידוק העדכנית והתקשר Model.evaluate על נתוני הבדיקה:
model.load_weights(tf.train.latest_checkpoint(checkpoint_dir))
eval_loss, eval_acc = model.evaluate(eval_dataset)
print('Eval loss: {}, Eval accuracy: {}'.format(eval_loss, eval_acc))
2022-01-26 05:39:15.260539: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:547] The `assert_cardinality` transformation is currently not handled by the auto-shard rewrite and will be removed. 157/157 [==============================] - 2s 4ms/step - loss: 0.0373 - accuracy: 0.9879 Eval loss: 0.03732967749238014, Eval accuracy: 0.9879000186920166
כדי לראות את הפלט, הפעל את TensorBoard והצג את היומנים:
%tensorboard --logdir=logs
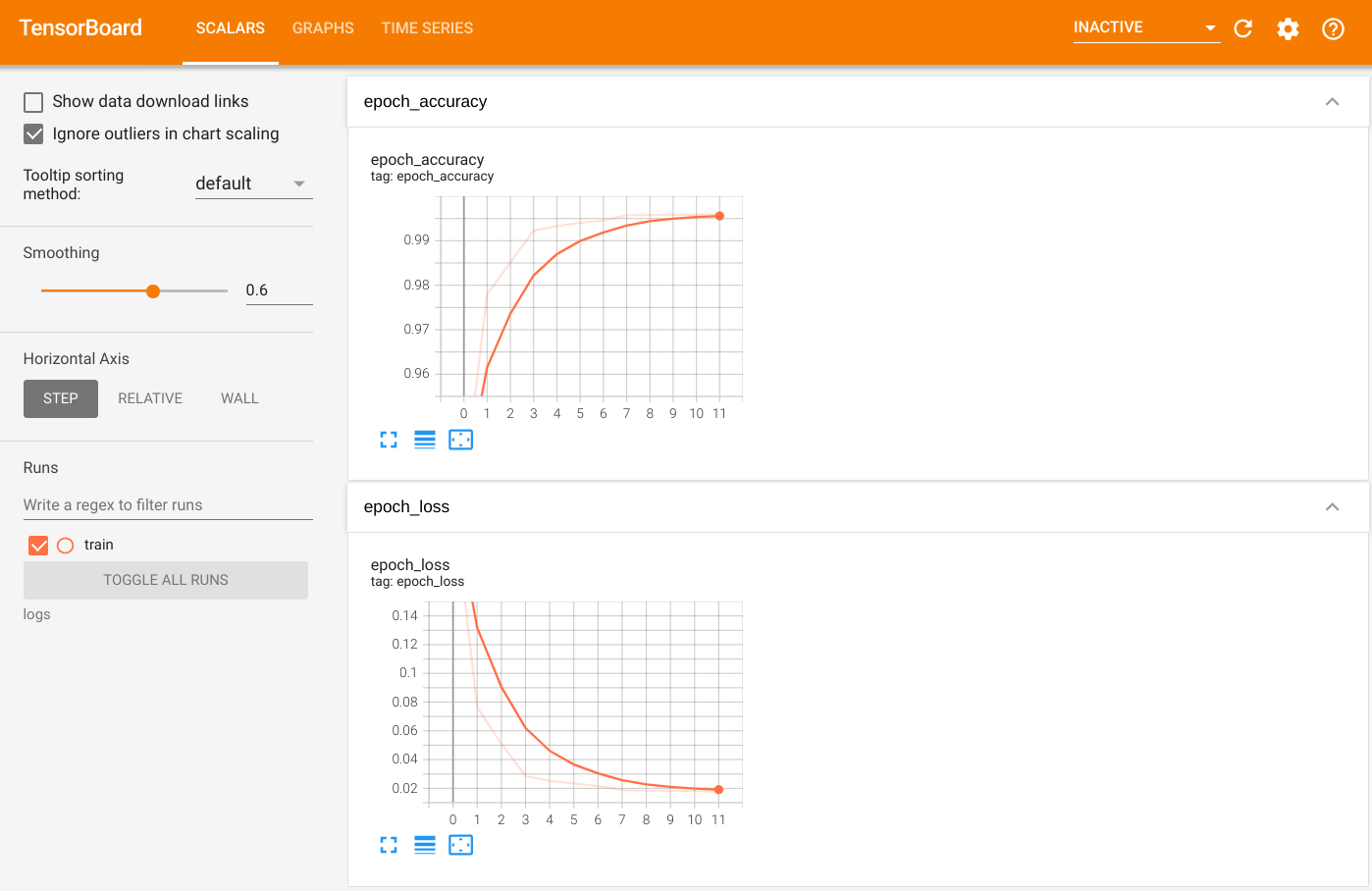
ls -sh ./logs
total 4.0K 4.0K train
ייצוא ל- SavedModel
ייצא את הגרף והמשתנים לפורמט SavedModel האגנסטי לפלטפורמה באמצעות Model.save . לאחר שמירת המודל שלך, תוכל לטעון אותו עם או בלי Strategy.scope .
path = 'saved_model/'
model.save(path, save_format='tf')
2022-01-26 05:39:18.012847: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: saved_model/assets INFO:tensorflow:Assets written to: saved_model/assets
כעת, טען את המודל ללא Strategy.scope :
unreplicated_model = tf.keras.models.load_model(path)
unreplicated_model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
eval_loss, eval_acc = unreplicated_model.evaluate(eval_dataset)
print('Eval loss: {}, Eval Accuracy: {}'.format(eval_loss, eval_acc))
157/157 [==============================] - 1s 2ms/step - loss: 0.0373 - accuracy: 0.9879 Eval loss: 0.03732967749238014, Eval Accuracy: 0.9879000186920166
טען את המודל עם Strategy.scope :
with strategy.scope():
replicated_model = tf.keras.models.load_model(path)
replicated_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
eval_loss, eval_acc = replicated_model.evaluate(eval_dataset)
print ('Eval loss: {}, Eval Accuracy: {}'.format(eval_loss, eval_acc))
2022-01-26 05:39:19.489971: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:547] The `assert_cardinality` transformation is currently not handled by the auto-shard rewrite and will be removed. 157/157 [==============================] - 3s 3ms/step - loss: 0.0373 - accuracy: 0.9879 Eval loss: 0.03732967749238014, Eval Accuracy: 0.9879000186920166
משאבים נוספים
דוגמאות נוספות המשתמשות באסטרטגיות הפצה שונות עם ה-API של Keras Model.fit :
- המשימות Solve GLUE באמצעות BERT ב-TPU משתמשות ב-
tf.distribute.MirroredStrategyלאימון על GPUs ו-tf.distribute.TPUStrategyTPUs. - המדריך ' שמור וטען מודל באמצעות אסטרטגיית הפצה ' מדגים כיצד להשתמש בממשקי ה-API של SavedModel עם
tf.distribute.Strategy. - ניתן להגדיר את המודלים הרשמיים של TensorFlow להפעלת אסטרטגיות הפצה מרובות.
למידע נוסף על אסטרטגיות הפצה של TensorFlow:
- ערכת הדרכה מותאמת אישית עם tf.distribute.Strategy מראה כיצד להשתמש
tf.distribute.MirroredStrategyשל עובד יחיד עם לולאת הדרכה מותאמת אישית. - ההדרכה לריבוי עובדים עם Keras מראה כיצד להשתמש ב-
MultiWorkerMirroredStrategyעםModel.fit. - לולאת האימון המותאמת אישית עם Keras ו-MultiWorkerMirroredStrategy מראה כיצד להשתמש ב-
MultiWorkerMirroredStrategyעם Keras ובלולאת אימון מותאמת אישית. - המדריך המבוזר ב-TensorFlow מספק סקירה כללית של אסטרטגיות ההפצה הזמינות.
- המדריך Better Performance with tf.function מספק מידע על אסטרטגיות וכלים אחרים, כגון TensorFlow Profiler שאתה יכול להשתמש בו כדי לייעל את הביצועים של דגמי TensorFlow שלך.