
| | |  Visualizza la fonte su GitHub Visualizza la fonte su GitHub | |
Questo tutorial mostra come utilizzare Deep & Cross Network (DCN) per apprendere in modo efficace le funzioni incrociate.
Sfondo
Cosa sono le croci di funzionalità e perché sono importanti? Immagina di creare un sistema di raccomandazione per vendere un frullatore ai clienti. Poi, passato storico degli acquisti di un cliente, come purchased_bananas e purchased_cooking_books , o le caratteristiche geografiche, sono caratteristiche singoli. Se uno ha acquistato due banane e libri di cucina, allora questo cliente sarà più probabile che cliccare sul frullatore consigliato. La combinazione di purchased_bananas e purchased_cooking_books viene indicato come una croce caratteristica, che fornisce informazioni di interazione supplementare oltre le singole caratteristiche.
Quali sono le sfide nell'apprendimento delle croci di funzionalità? Nelle applicazioni su scala Web, i dati sono per lo più categorici, portando a uno spazio di funzionalità ampio e sparso. L'identificazione di incroci di funzionalità efficaci in questa impostazione spesso richiede la progettazione manuale delle funzionalità o una ricerca esauriente. I tradizionali modelli feed-forward perceptron multistrato (MLP) sono approssimatori di funzioni universali; tuttavia, non si può approssimare in modo efficiente anche 2 ° o 3 ° ordine caratteristica croci [ 1 , 2 ].
Che cos'è Deep & Cross Network (DCN)? DCN è stato progettato per apprendere in modo più efficace le funzioni incrociate esplicite e di grado limitato. Si inizia con uno strato di input (tipicamente uno strato incorporamento), seguita da una rete di cross contenente più strati incrociati che includono interazioni modelli espliciti, e quindi combina con una rete profonda che modella implicite includono interazioni.
- Rete incrociata. Questo è il cuore di DCN. Applica esplicitamente l'intersezione di feature a ogni livello e il grado polinomiale più alto aumenta con la profondità del livello. Mostrato nella figura seguente il \((i+1)\)-esimo strato trasversale.
- Rete profonda. È un perceptron multistrato feedforward tradizionale (MLP).
La rete e la rete profonda croce vengono quindi combinati per formare DCN [ 1 ]. Comunemente, potremmo impilare una rete profonda sopra la rete incrociata (struttura impilata); potremmo anche metterli in parallelo (struttura parallela).
Di seguito, mostreremo prima il vantaggio di DCN con un esempio di giocattolo, quindi ti guideremo attraverso alcuni modi comuni per utilizzare DCN utilizzando il set di dati MovieLen-1M.
Per prima cosa installiamo e importiamo i pacchetti necessari per questa colab.
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import pprint
%matplotlib inline
import matplotlib.pyplot as plt
from mpl_toolkits.axes_grid1 import make_axes_locatable
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
Esempio di giocattolo
Per illustrare i vantaggi di DCN, esaminiamo un semplice esempio. Supponiamo di avere un set di dati in cui stiamo cercando di modellare la probabilità che un cliente faccia clic su un annuncio blender, con le sue caratteristiche e l'etichetta descritte come segue.
| Caratteristiche / Etichetta | Descrizione | Tipo di valore / intervallo |
|---|---|---|
| \(x_1\) = paese | il paese in cui vive questo cliente | Int in [0, 199] |
| \(x_2\) = banane | # banane che il cliente ha acquistato | Int in [0, 23] |
| \(x_3\) = cookbooks | # libri di cucina che il cliente ha acquistato | Int in [0, 5] |
| \(y\) | la probabilità di fare clic su un annuncio frullatore | -- |
Quindi, lasciamo che i dati seguano la seguente distribuzione sottostante:
\[y = f(x_1, x_2, x_3) = 0.1x_1 + 0.4x_2+0.7x_3 + 0.1x_1x_2+3.1x_2x_3+0.1x_3^2\]
dove la probabilità \(y\) dipende linearmente sia sulle caratteristiche \(x_i\)'s, ma anche sulle interazioni moltiplicative tra \(x_i\)' s. Nel nostro caso, si direbbe che la probabilità di acquisto di un frullatore (\(y\)) dipende non solo per l'acquisto di banane (\(x_2\)) o libri di cucina (\(x_3\)), ma anche per l'acquisto di banane e libri di cucina insieme (\(x_2x_3\)).
Possiamo generare i dati per questo come segue:
Generazione di dati sintetici
Prima si definisce \(f(x_1, x_2, x_3)\) come descritto sopra.
def get_mixer_data(data_size=100_000, random_seed=42):
# We need to fix the random seed
# to make colab runs repeatable.
rng = np.random.RandomState(random_seed)
country = rng.randint(200, size=[data_size, 1]) / 200.
bananas = rng.randint(24, size=[data_size, 1]) / 24.
coockbooks = rng.randint(6, size=[data_size, 1]) / 6.
x = np.concatenate([country, bananas, coockbooks], axis=1)
# # Create 1st-order terms.
y = 0.1 * country + 0.4 * bananas + 0.7 * coockbooks
# Create 2nd-order cross terms.
y += 0.1 * country * bananas + 3.1 * bananas * coockbooks + (
0.1 * coockbooks * coockbooks)
return x, y
Generiamo i dati che seguono la distribuzione e dividiamo i dati in 90% per l'addestramento e 10% per il test.
x, y = get_mixer_data()
num_train = 90000
train_x = x[:num_train]
train_y = y[:num_train]
eval_x = x[num_train:]
eval_y = y[num_train:]
Costruzione del modello
Proveremo sia la rete incrociata che la rete profonda per illustrare il vantaggio che una rete incrociata può portare ai consiglieri. Poiché i dati che abbiamo appena creato contengono solo interazioni di funzionalità di 2° ordine, sarebbe sufficiente illustrare con una rete incrociata a livello singolo. Se volessimo modellare interazioni di funzionalità di ordine superiore, potremmo impilare più livelli trasversali e utilizzare una rete incrociata a più livelli. I due modelli che costruiremo sono:
- Rete incrociata con un solo livello incrociato;
- Deep Network con livelli ReLU più ampi e profondi.
Per prima cosa costruiamo una classe di modello unificato la cui perdita è l'errore quadratico medio.
class Model(tfrs.Model):
def __init__(self, model):
super().__init__()
self._model = model
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[
tf.keras.metrics.RootMeanSquaredError("RMSE")
]
)
def call(self, x):
x = self._model(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
x, labels = features
scores = self(x)
return self.task(
labels=labels,
predictions=scores,
)
Quindi, specifichiamo la rete incrociata (con 1 livello incrociato di dimensione 3) e il DNN basato su ReLU (con dimensioni del livello [512, 256, 128]):
crossnet = Model(tfrs.layers.dcn.Cross())
deepnet = Model(
tf.keras.Sequential([
tf.keras.layers.Dense(512, activation="relu"),
tf.keras.layers.Dense(256, activation="relu"),
tf.keras.layers.Dense(128, activation="relu")
])
)
Formazione modello
Ora che abbiamo i dati e i modelli pronti, andremo ad addestrare i modelli. Per prima cosa mescoliamo e lottiamo i dati per prepararci all'addestramento del modello.
train_data = tf.data.Dataset.from_tensor_slices((train_x, train_y)).batch(1000)
eval_data = tf.data.Dataset.from_tensor_slices((eval_x, eval_y)).batch(1000)
Quindi, definiamo il numero di epoche e il tasso di apprendimento.
epochs = 100
learning_rate = 0.4
Bene, ora è tutto pronto e compiliamo e addestriamo i modelli. È possibile impostare verbose=True se si desidera vedere come i progressi del modello.
crossnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
crossnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d82ef390>
deepnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
deepnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d07a3dd0>
Valutazione del modello
Verifichiamo le prestazioni del modello sul set di dati di valutazione e riportiamo il Root Mean Squared Error (RMSE, più basso è, meglio è).
crossnet_result = crossnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"CrossNet(1 layer) RMSE is {crossnet_result['RMSE']:.4f} "
f"using {crossnet.count_params()} parameters.")
deepnet_result = deepnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"DeepNet(large) RMSE is {deepnet_result['RMSE']:.4f} "
f"using {deepnet.count_params()} parameters.")
CrossNet(1 layer) RMSE is 0.0011 using 16 parameters. DeepNet(large) RMSE is 0.1258 using 166401 parameters.
Vediamo che la rete croce grandezze raggiunti abbassare RMSE di un DNN Relu-based, con grandezze meno parametri. Ciò ha suggerito l'efficienza di una rete incrociata nell'apprendimento degli incroci di caratteristiche.
Comprensione del modello
Sappiamo già quali incroci di funzionalità sono importanti nei nostri dati, sarebbe divertente verificare se il nostro modello ha effettivamente appreso l'importante croce di funzionalità. Questo può essere fatto visualizzando la matrice del peso appreso in DCN. Il peso \(W_{ij}\) rappresenta l'importanza appreso di interazione tra funzione \(x_i\) e \(x_j\).
mat = crossnet._model._dense.kernel
features = ["country", "purchased_bananas", "purchased_cookbooks"]
plt.figure(figsize=(9,9))
im = plt.matshow(np.abs(mat.numpy()), cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([''] + features, rotation=45, fontsize=10)
_ = ax.set_yticklabels([''] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:11: UserWarning: FixedFormatter should only be used together with FixedLocator # This is added back by InteractiveShellApp.init_path() /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:12: UserWarning: FixedFormatter should only be used together with FixedLocator if sys.path[0] == '': <Figure size 648x648 with 0 Axes>
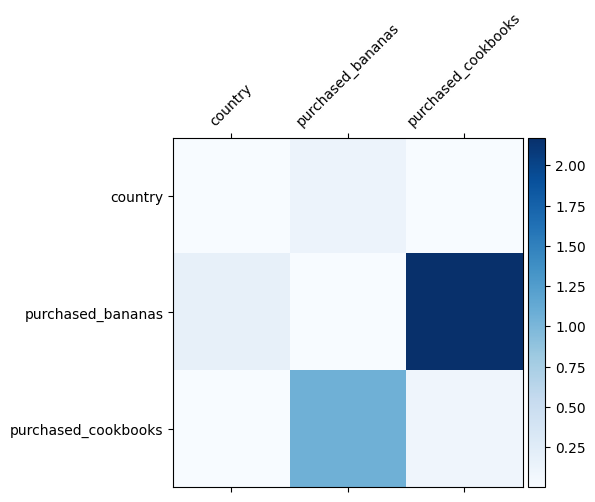
I colori più scuri rappresentano interazioni apprese più forti: in questo caso, è chiaro che il modello ha appreso che l'acquisto di babane e libri di cucina insieme è importante.
Se siete interessati a provare i dati di sintesi più complicato, si sentono liberi di controllare questo documento .
Esempio Movielens 1M
Esaminiamo ora l'efficacia di DCN su un set di dati del mondo reale: MovieLens 1M [ 3 ]. Movielens 1M è un popolare set di dati per la ricerca di consigli. Prevede le valutazioni dei film degli utenti in base alle funzionalità relative all'utente e alle funzionalità relative al film. Utilizziamo questo set di dati per dimostrare alcuni modi comuni di utilizzare DCN.
Elaborazione dati
La procedura di elaborazione dei dati segue una procedura simile a quella del tutorial di base graduatoria .
ratings = tfds.load("movie_lens/100k-ratings", split="train")
ratings = ratings.map(lambda x: {
"movie_id": x["movie_id"],
"user_id": x["user_id"],
"user_rating": x["user_rating"],
"user_gender": int(x["user_gender"]),
"user_zip_code": x["user_zip_code"],
"user_occupation_text": x["user_occupation_text"],
"bucketized_user_age": int(x["bucketized_user_age"]),
})
WARNING:absl:The handle "movie_lens" for the MovieLens dataset is deprecated. Prefer using "movielens" instead.
Successivamente, abbiamo suddiviso casualmente i dati in 80% per l'addestramento e 20% per il test.
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
Quindi, creiamo il vocabolario per ogni funzione.
feature_names = ["movie_id", "user_id", "user_gender", "user_zip_code",
"user_occupation_text", "bucketized_user_age"]
vocabularies = {}
for feature_name in feature_names:
vocab = ratings.batch(1_000_000).map(lambda x: x[feature_name])
vocabularies[feature_name] = np.unique(np.concatenate(list(vocab)))
Costruzione del modello
L'architettura del modello che costruiremo inizia con un livello di incorporamento, che viene inserito in una rete incrociata seguita da una rete profonda. La dimensione di incorporamento è impostata su 32 per tutte le funzionalità. Puoi anche utilizzare diverse dimensioni di incorporamento per funzioni diverse.
class DCN(tfrs.Model):
def __init__(self, use_cross_layer, deep_layer_sizes, projection_dim=None):
super().__init__()
self.embedding_dimension = 32
str_features = ["movie_id", "user_id", "user_zip_code",
"user_occupation_text"]
int_features = ["user_gender", "bucketized_user_age"]
self._all_features = str_features + int_features
self._embeddings = {}
# Compute embeddings for string features.
for feature_name in str_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.StringLookup(
vocabulary=vocabulary, mask_token=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
# Compute embeddings for int features.
for feature_name in int_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.IntegerLookup(
vocabulary=vocabulary, mask_value=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
if use_cross_layer:
self._cross_layer = tfrs.layers.dcn.Cross(
projection_dim=projection_dim,
kernel_initializer="glorot_uniform")
else:
self._cross_layer = None
self._deep_layers = [tf.keras.layers.Dense(layer_size, activation="relu")
for layer_size in deep_layer_sizes]
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[tf.keras.metrics.RootMeanSquaredError("RMSE")]
)
def call(self, features):
# Concatenate embeddings
embeddings = []
for feature_name in self._all_features:
embedding_fn = self._embeddings[feature_name]
embeddings.append(embedding_fn(features[feature_name]))
x = tf.concat(embeddings, axis=1)
# Build Cross Network
if self._cross_layer is not None:
x = self._cross_layer(x)
# Build Deep Network
for deep_layer in self._deep_layers:
x = deep_layer(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
labels = features.pop("user_rating")
scores = self(features)
return self.task(
labels=labels,
predictions=scores,
)
Formazione modello
Mescoliamo, eseguiamo in batch e mettiamo in cache i dati di allenamento e test.
cached_train = train.shuffle(100_000).batch(8192).cache()
cached_test = test.batch(4096).cache()
Definiamo una funzione che esegue un modello più volte e restituisce la media RMSE e la deviazione standard del modello su più esecuzioni.
def run_models(use_cross_layer, deep_layer_sizes, projection_dim=None, num_runs=5):
models = []
rmses = []
for i in range(num_runs):
model = DCN(use_cross_layer=use_cross_layer,
deep_layer_sizes=deep_layer_sizes,
projection_dim=projection_dim)
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate))
models.append(model)
model.fit(cached_train, epochs=epochs, verbose=False)
metrics = model.evaluate(cached_test, return_dict=True)
rmses.append(metrics["RMSE"])
mean, stdv = np.average(rmses), np.std(rmses)
return {"model": models, "mean": mean, "stdv": stdv}
Impostiamo alcuni iperparametri per i modelli. Si noti che questi iperparametri sono impostati globalmente per tutti i modelli a scopo dimostrativo. Se vuoi ottenere le migliori prestazioni per ogni modello o effettuare un confronto equo tra i modelli, ti consigliamo di mettere a punto gli iperparametri. Ricorda che l'architettura del modello e gli schemi di ottimizzazione sono intrecciati.
epochs = 8
learning_rate = 0.01
DCN (impilato). Per prima cosa addestriamo un modello DCN con una struttura impilata, ovvero gli input vengono inviati a una rete incrociata seguita da una rete profonda.
dcn_result = run_models(use_cross_layer=True,
deep_layer_sizes=[192, 192])
WARNING:tensorflow:mask_value is deprecated, use mask_token instead. WARNING:tensorflow:mask_value is deprecated, use mask_token instead. 5/5 [==============================] - 3s 24ms/step - RMSE: 0.9312 - loss: 0.8674 - regularization_loss: 0.0000e+00 - total_loss: 0.8674 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8726 - regularization_loss: 0.0000e+00 - total_loss: 0.8726 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9326 - loss: 0.8703 - regularization_loss: 0.0000e+00 - total_loss: 0.8703 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9351 - loss: 0.8752 - regularization_loss: 0.0000e+00 - total_loss: 0.8752 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8729 - regularization_loss: 0.0000e+00 - total_loss: 0.8729
DCN di basso rango. Per ridurre i costi di formazione e servizio, utilizziamo tecniche di basso rango per approssimare le matrici di peso DCN. Il rango viene passato attraverso argomento projection_dim ; un piccolo projection_dim comporta un costo inferiore. Si noti che projection_dim deve essere più piccolo (dimensioni in entrata) / 2 per ridurre il costo. In pratica, abbiamo osservato che l'utilizzo di DCN di basso rango con rank (dimensione di input)/4 ha mantenuto costantemente l'accuratezza di un DCN di rango completo.
dcn_lr_result = run_models(use_cross_layer=True,
projection_dim=20,
deep_layer_sizes=[192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9307 - loss: 0.8669 - regularization_loss: 0.0000e+00 - total_loss: 0.8669 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9312 - loss: 0.8668 - regularization_loss: 0.0000e+00 - total_loss: 0.8668 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9303 - loss: 0.8666 - regularization_loss: 0.0000e+00 - total_loss: 0.8666 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9337 - loss: 0.8723 - regularization_loss: 0.0000e+00 - total_loss: 0.8723 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9300 - loss: 0.8657 - regularization_loss: 0.0000e+00 - total_loss: 0.8657
DNN. Formiamo un modello DNN della stessa dimensione come riferimento.
dnn_result = run_models(use_cross_layer=False,
deep_layer_sizes=[192, 192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9462 - loss: 0.8989 - regularization_loss: 0.0000e+00 - total_loss: 0.8989 5/5 [==============================] - 0s 4ms/step - RMSE: 0.9352 - loss: 0.8765 - regularization_loss: 0.0000e+00 - total_loss: 0.8765 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9393 - loss: 0.8840 - regularization_loss: 0.0000e+00 - total_loss: 0.8840 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9362 - loss: 0.8772 - regularization_loss: 0.0000e+00 - total_loss: 0.8772 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9377 - loss: 0.8798 - regularization_loss: 0.0000e+00 - total_loss: 0.8798
Valutiamo il modello sui dati del test e riportiamo la media e la deviazione standard su 5 esecuzioni.
print("DCN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_result["mean"], dcn_result["stdv"]))
print("DCN (low-rank) RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_lr_result["mean"], dcn_lr_result["stdv"]))
print("DNN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dnn_result["mean"], dnn_result["stdv"]))
DCN RMSE mean: 0.9333, stdv: 0.0013 DCN (low-rank) RMSE mean: 0.9312, stdv: 0.0013 DNN RMSE mean: 0.9389, stdv: 0.0039
Vediamo che DCN ha ottenuto prestazioni migliori rispetto a un DNN delle stesse dimensioni con livelli ReLU. Inoltre, il DCN di basso rango è stato in grado di ridurre i parametri mantenendo la precisione.
Maggiori informazioni su DCN. Oltre Cos'hai stato dimostrato sopra, ci sono modi ancora praticamente utile più creativi per utilizzare DCN [ 1 ].
DCN con una struttura parallela. Gli ingressi sono alimentati in parallelo a una rete incrociata ea una rete profonda.
Concatenazione di strati incrociati. Gli ingressi sono alimentati in parallelo a più livelli trasversali per catturare incroci di caratteristiche complementari.
Comprensione del modello
La matrice peso \(W\) in DCN rivela ciò caratteristica attraversa il modello è imparato ad essere importante. Ricordiamo che nell'esempio giocattolo precedente, l'importanza delle interazioni tra la \(i\)-esimo e \(j\)-esimo caratteristiche viene catturato dal (\(i, j\)) -esimo elemento di \(W\).
Nei un po 'diverso è che le funzionalità incastri sono di dimensioni 32 invece di dimensione 1. Quindi, l'importanza saranno caratterizzati dal \((i, j)\)blocco -esimo\(W_{i,j}\) che è di dimensione 32 e 32. Nel seguito, abbiamo visualizza la norma di Frobenius [ 4 ] \(||W_{i,j}||_F\) di ogni blocco, e una norma maggiore suggerirebbe maggiore importanza (supponendo embeddings le caratteristiche sono di scale simili).
Oltre alla norma del blocco, potremmo anche visualizzare l'intera matrice, o il valore medio/mediano/max di ogni blocco.
model = dcn_result["model"][0]
mat = model._cross_layer._dense.kernel
features = model._all_features
block_norm = np.ones([len(features), len(features)])
dim = model.embedding_dimension
# Compute the norms of the blocks.
for i in range(len(features)):
for j in range(len(features)):
block = mat[i * dim:(i + 1) * dim,
j * dim:(j + 1) * dim]
block_norm[i,j] = np.linalg.norm(block, ord="fro")
plt.figure(figsize=(9,9))
im = plt.matshow(block_norm, cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([""] + features, rotation=45, ha="left", fontsize=10)
_ = ax.set_yticklabels([""] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:23: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:24: UserWarning: FixedFormatter should only be used together with FixedLocator <Figure size 648x648 with 0 Axes>
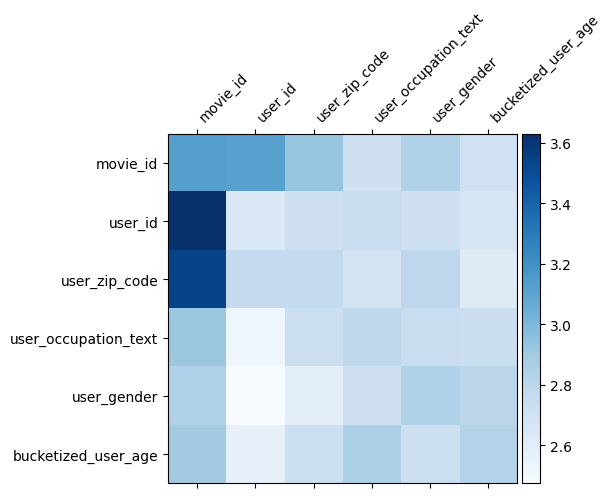
Questo è tutto per questa colab! Ci auguriamo che ti sia piaciuto apprendere alcune nozioni di base di DCN e modi comuni per utilizzarlo. Se siete interessati a saperne di più, si potrebbe verificare due documenti rilevanti: DCN-V1-carta , DCN-v2-carta .
Riferimenti
DCN V2: Migliorato profonda e Croce di rete e lezioni pratiche per l'apprendimento Web-scala per classificare i sistemi .
Ruoxi Wang, Rakesh Shivanna, Derek Zhiyuan Cheng, Sagar Jain, Dong Lin, Lichan Hong, Ed Chi. (2020)
Profondo & Cross Network per clic sull'annuncio previsioni .
Ruoxi Wang, Bin Fu, Gang Fu, Mingliang Wang. (AdKDD 2017)