
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
Gelen featurization öğretici bizim modellere birden çok özellik dahil, fakat modeller yalnızca bir gömme tabaka oluşur. Modellerimize ifade güçlerini artırmak için daha yoğun katmanlar ekleyebiliriz.
Genel olarak, daha derin modeller, daha sığ modellerden daha karmaşık kalıpları öğrenme yeteneğine sahiptir. Örneğin, bizim kullanıcı modeli zaman içinde bir noktada örnek kullanıcı tercihlerine kullanıcı kimlikleri ve damgaları içermektedir. Sığ bir model (örneğin, tek bir gömme katmanı) yalnızca bu özellikler ve filmler arasındaki en basit ilişkileri öğrenebilir: belirli bir film, yayınlandığı dönemde en popüler olanıdır ve belirli bir kullanıcı genellikle korku filmlerini komedilere tercih eder. Zaman içinde gelişen kullanıcı tercihleri gibi daha karmaşık ilişkileri yakalamak için, birden çok yığılmış yoğun katmana sahip daha derin bir modele ihtiyacımız olabilir.
Elbette, karmaşık modellerin dezavantajları da vardır. Birincisi, daha büyük modeller sığdırmak ve hizmet etmek için hem daha fazla bellek hem de daha fazla hesaplama gerektirdiğinden, hesaplama maliyetidir. İkincisi, daha fazla veri gereksinimidir: genel olarak, daha derin modellerden yararlanmak için daha fazla eğitim verisine ihtiyaç vardır. Daha fazla parametreyle, derin modeller, genelleme yapabilen bir işlevi öğrenmek yerine, eğitim örneklerini fazla sığdırabilir veya hatta basitçe ezberleyebilir. Son olarak, daha derin modelleri eğitmek daha zor olabilir ve düzenleme ve öğrenme oranı gibi ayarların seçiminde daha fazla özen gösterilmesi gerekir.
Bir gerçek dünya recommender sistemi için iyi bir mimariyi bulma sezgileri ve dikkatli gerektiren karmaşık bir sanattır, hyperparameter ayarlama . Örneğin modelin derinliği ve genişliği, aktivasyon fonksiyonu, öğrenme hızı ve optimize edici gibi faktörler modelin performansını kökten değiştirebilir. İyi çevrimdışı değerlendirme metriklerinin iyi çevrimiçi performansa karşılık gelmeyebileceği ve neyin optimize edileceğinin seçiminin genellikle model seçiminden daha kritik olduğu gerçeği, modelleme seçimlerini daha da karmaşık hale getirir.
Bununla birlikte, daha büyük modelleri oluşturmak ve ince ayar yapmak için harcanan çaba genellikle karşılığını verir. Bu öğreticide, TensorFlow Önerilerini kullanarak derin alma modellerinin nasıl oluşturulacağını göstereceğiz. Bunun model performansını nasıl etkilediğini görmek için aşamalı olarak daha karmaşık modeller oluşturarak bunu yapacağız.
ön elemeler
Öncelikle gerekli paketleri import ediyoruz.
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import os
import tempfile
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
plt.style.use('seaborn-whitegrid')
Bu dersimizde gelen modelleri kullanacağız featurization öğretici katıştırmalarını üretmek için. Bu nedenle yalnızca kullanıcı kimliği, zaman damgası ve film başlığı özelliklerini kullanacağız.
ratings = tfds.load("movielens/100k-ratings", split="train")
movies = tfds.load("movielens/100k-movies", split="train")
ratings = ratings.map(lambda x: {
"movie_title": x["movie_title"],
"user_id": x["user_id"],
"timestamp": x["timestamp"],
})
movies = movies.map(lambda x: x["movie_title"])
2021-10-02 11:11:47.672650: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
Ayrıca, özellik sözlükleri hazırlamak için bazı temizlik işleri yapıyoruz.
timestamps = np.concatenate(list(ratings.map(lambda x: x["timestamp"]).batch(100)))
max_timestamp = timestamps.max()
min_timestamp = timestamps.min()
timestamp_buckets = np.linspace(
min_timestamp, max_timestamp, num=1000,
)
unique_movie_titles = np.unique(np.concatenate(list(movies.batch(1000))))
unique_user_ids = np.unique(np.concatenate(list(ratings.batch(1_000).map(
lambda x: x["user_id"]))))
Model tanımı
sorgu modeli
Biz tanımlanan kullanıcı modeli ile başlar featurization öğretici eden modelinin ilk katman olarak, özellik tespitlerinin ham giriş örnekleri dönüştürme görevi.
class UserModel(tf.keras.Model):
def __init__(self):
super().__init__()
self.user_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_user_ids, mask_token=None),
tf.keras.layers.Embedding(len(unique_user_ids) + 1, 32),
])
self.timestamp_embedding = tf.keras.Sequential([
tf.keras.layers.Discretization(timestamp_buckets.tolist()),
tf.keras.layers.Embedding(len(timestamp_buckets) + 1, 32),
])
self.normalized_timestamp = tf.keras.layers.Normalization(
axis=None
)
self.normalized_timestamp.adapt(timestamps)
def call(self, inputs):
# Take the input dictionary, pass it through each input layer,
# and concatenate the result.
return tf.concat([
self.user_embedding(inputs["user_id"]),
self.timestamp_embedding(inputs["timestamp"]),
tf.reshape(self.normalized_timestamp(inputs["timestamp"]), (-1, 1)),
], axis=1)
Daha derin modeller tanımlamak, mod katmanlarını bu ilk girdinin üzerine yığmamızı gerektirecektir. Bir etkinleştirme işleviyle ayrılmış, giderek daha dar bir katman yığını yaygın bir kalıptır:
+----------------------+
| 128 x 64 |
+----------------------+
| relu
+--------------------------+
| 256 x 128 |
+--------------------------+
| relu
+------------------------------+
| ... x 256 |
+------------------------------+
Derin lineer modellerin ifade gücü, sığ lineer modellerinkinden daha büyük olmadığından, son gizli katman hariç tümü için ReLU aktivasyonlarını kullanırız. Son gizli katman herhangi bir etkinleştirme işlevi kullanmaz: bir etkinleştirme işlevinin kullanılması, son yerleştirmelerin çıktı alanını sınırlayabilir ve modelin performansını olumsuz etkileyebilir. Örneğin, projeksiyon katmanında ReLU'lar kullanılıyorsa, çıktı gömmedeki tüm bileşenler negatif olmayacaktır.
Burada benzer bir şey deneyeceğiz. Farklı derinliklerle deney yapmayı kolaylaştırmak için, derinliği (ve genişliği) bir dizi yapıcı parametresi tarafından tanımlanan bir model tanımlayalım.
class QueryModel(tf.keras.Model):
"""Model for encoding user queries."""
def __init__(self, layer_sizes):
"""Model for encoding user queries.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
# We first use the user model for generating embeddings.
self.embedding_model = UserModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
layer_sizes parametre bize modelin derinliği ve genişliği verir. Daha sığ veya daha derin modellerle deney yapmak için değiştirebiliriz.
aday modeli
Aynı yaklaşımı film modeli için de benimseyebiliriz. Yine, başlayalım MovieModel gelen featurization öğretici:
class MovieModel(tf.keras.Model):
def __init__(self):
super().__init__()
max_tokens = 10_000
self.title_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_movie_titles,mask_token=None),
tf.keras.layers.Embedding(len(unique_movie_titles) + 1, 32)
])
self.title_vectorizer = tf.keras.layers.TextVectorization(
max_tokens=max_tokens)
self.title_text_embedding = tf.keras.Sequential([
self.title_vectorizer,
tf.keras.layers.Embedding(max_tokens, 32, mask_zero=True),
tf.keras.layers.GlobalAveragePooling1D(),
])
self.title_vectorizer.adapt(movies)
def call(self, titles):
return tf.concat([
self.title_embedding(titles),
self.title_text_embedding(titles),
], axis=1)
Ve gizli katmanlarla genişletin:
class CandidateModel(tf.keras.Model):
"""Model for encoding movies."""
def __init__(self, layer_sizes):
"""Model for encoding movies.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
self.embedding_model = MovieModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
kombine model
Her ikisiyle QueryModel ve CandidateModel tanımlanan, bir kombine modeli araya koymak ve bizim kaybı ve ölçümlerini mantığını uygulayabilir. İşleri basitleştirmek için, model yapısının sorgu ve aday modellerde aynı olmasını zorunlu kılacağız.
class MovielensModel(tfrs.models.Model):
def __init__(self, layer_sizes):
super().__init__()
self.query_model = QueryModel(layer_sizes)
self.candidate_model = CandidateModel(layer_sizes)
self.task = tfrs.tasks.Retrieval(
metrics=tfrs.metrics.FactorizedTopK(
candidates=movies.batch(128).map(self.candidate_model),
),
)
def compute_loss(self, features, training=False):
# We only pass the user id and timestamp features into the query model. This
# is to ensure that the training inputs would have the same keys as the
# query inputs. Otherwise the discrepancy in input structure would cause an
# error when loading the query model after saving it.
query_embeddings = self.query_model({
"user_id": features["user_id"],
"timestamp": features["timestamp"],
})
movie_embeddings = self.candidate_model(features["movie_title"])
return self.task(
query_embeddings, movie_embeddings, compute_metrics=not training)
Modeli eğitmek
Verileri hazırlayın
İlk önce verileri bir eğitim seti ve bir test seti olarak ayırdık.
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
cached_train = train.shuffle(100_000).batch(2048)
cached_test = test.batch(4096).cache()
sığ model
İlk sığ modelimizi denemeye hazırız!
num_epochs = 300
model = MovielensModel([32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
one_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.27.
Bu bize 0,27 civarında bir üst 100 doğruluk verir. Bunu daha derin modelleri değerlendirmek için bir referans noktası olarak kullanabiliriz.
Daha derin model
İki katmanlı daha derin bir modele ne dersiniz?
model = MovielensModel([64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
two_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.29.
Buradaki doğruluk 0.29, sığ modelden biraz daha iyi.
Bunu göstermek için doğrulama doğruluğu eğrilerini çizebiliriz:
num_validation_runs = len(one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"])
epochs = [(x + 1)* 5 for x in range(num_validation_runs)]
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c7513d0>
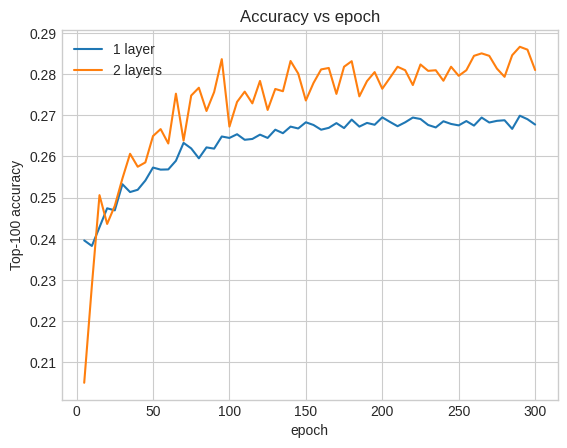
Eğitimin başlarında bile, daha büyük modelin sığ modele göre net ve istikrarlı bir üstünlüğü vardır, bu da derinlik eklemenin modelin verilerde daha nüanslı ilişkileri yakalamasına yardımcı olduğunu düşündürür.
Bununla birlikte, daha derin modeller bile mutlaka daha iyi değildir. Aşağıdaki model, derinliği üç katmana genişletir:
model = MovielensModel([128, 64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
three_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.26.
Aslında, sığ model üzerinde bir gelişme görmüyoruz:
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.plot(epochs, three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="3 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c6d8590>
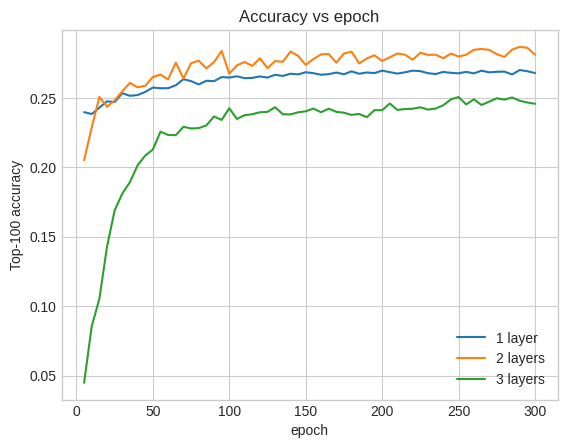
Bu, daha derin ve daha büyük modellerin üstün performans göstermelerine rağmen genellikle çok dikkatli ayar gerektirdiği gerçeğinin iyi bir örneğidir. Örneğin, bu eğitim boyunca tek, sabit bir öğrenme oranı kullandık. Alternatif seçenekler çok farklı sonuçlar verebilir ve araştırmaya değerdir.
Uygun ayarlama ve yeterli veri ile, daha büyük ve daha derin modeller oluşturmak için harcanan çaba çoğu durumda buna değer: daha büyük modeller tahmin doğruluğunda önemli gelişmelere yol açabilir.
Sonraki adımlar
Bu öğreticide, yoğun katmanlar ve etkinleştirme işlevleriyle alma modelimizi genişlettik. Alma görevleri aynı zamanda reytinge görevleri sadece gerçekleştirebilen bir model oluşturmak için nasıl çalıştığını görmek için, bakmak çoklu görev öğretici .