
Przegląd
Główną cechą TensorBoard jest interaktywny GUI. Jednak użytkownicy czasami chcą programowo odczytać logi danych przechowywanych w TensorBoard do celów takich jak wykonywanie analizy post-hoc oraz tworzenie niestandardowych wizualizacji danych dziennika.
TensorBoard 2,3 podpór tym przypadku korzystanie z tensorboard.data.experimental.ExperimentFromDev() . Umożliwia on dostęp programistyczny do TensorBoard za skalarnych dzienników . Ta strona przedstawia podstawowe zastosowanie tego nowego interfejsu API.
Ustawiać
W celu skorzystania z programistyczny API, upewnij się zainstalować pandas obok tensorboard .
Użyjemy matplotlib i seaborn dla własnych działek w tej instrukcji, ale można wybrać preferowane narzędzie do analizy i wizualizacji DataFrame s.
pip install tensorboard pandaspip install matplotlib seaborn
from packaging import version
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
from scipy import stats
import tensorboard as tb
major_ver, minor_ver, _ = version.parse(tb.__version__).release
assert major_ver >= 2 and minor_ver >= 3, \
"This notebook requires TensorBoard 2.3 or later."
print("TensorBoard version: ", tb.__version__)
TensorBoard version: 2.3.0a20200626
Ładowanie skalary TensorBoard jako pandas.DataFrame
Gdy logdir TensorBoard został przesłany do TensorBoard.dev, staje się to, co określamy jako eksperyment. Każdy eksperyment ma unikalny identyfikator, który można znaleźć w adresie URL eksperymentu TensorBoard.dev. Dla naszej demonstracji poniżej użyjemy eksperyment TensorBoard.dev w: https://tensorboard.dev/experiment/c1KCv3X3QvGwaXfgX1c4tg
experiment_id = "c1KCv3X3QvGwaXfgX1c4tg"
experiment = tb.data.experimental.ExperimentFromDev(experiment_id)
df = experiment.get_scalars()
df
df jest pandas.DataFrame który zawiera wszystkie skalarne dzienniki eksperymentu.
Kolumny DataFrame są:
-
run: każdy odpowiada biec do podkatalogu oryginalnego logdir. W tym eksperymencie każdy przebieg pochodzi z pełnego treningu splotowej sieci neuronowej (CNN) na zbiorze danych MNIST z danym typem optymalizatora (hiperparametr treningowy). TenDataFramezawiera wiele takich przebiegów, które odpowiadają powtarzającym przebiegów treningowych w różnych typach Optimizer. -
tag: ten opisuje, covaluew tych samych środków rzędowych, czyli to, co reprezentuje wartość metryki w wierszu. W tym doświadczeniu, mamy tylko dwa unikalne tagi:epoch_accuracyiepoch_lossza dokładność i utrata danych odpowiednio. -
step: Jest to ilość, która odzwierciedla porządkowych odpowiedniego wiersza w jej przebiegu. Otosteprzeczywiście odnosi się do liczby epoki. Jeśli chcesz uzyskać timestampów opróczstepwartości, można użyć słowa kluczowego argumentuinclude_wall_time=Truepodczas wywoływaniaget_scalars(). -
value: Jest to rzeczywista wartość liczbowa zainteresowania. Jak opisano powyżej, każdavaluew tym konkretnymDataFramesię straty lub dokładność, w zależności odtagz szeregu.
print(df["run"].unique())
print(df["tag"].unique())
['adam,run_1/train' 'adam,run_1/validation' 'adam,run_2/train' 'adam,run_2/validation' 'adam,run_3/train' 'adam,run_3/validation' 'adam,run_4/train' 'adam,run_4/validation' 'adam,run_5/train' 'adam,run_5/validation' 'rmsprop,run_1/train' 'rmsprop,run_1/validation' 'rmsprop,run_2/train' 'rmsprop,run_2/validation' 'rmsprop,run_3/train' 'rmsprop,run_3/validation' 'rmsprop,run_4/train' 'rmsprop,run_4/validation' 'rmsprop,run_5/train' 'rmsprop,run_5/validation' 'sgd,run_1/train' 'sgd,run_1/validation' 'sgd,run_2/train' 'sgd,run_2/validation' 'sgd,run_3/train' 'sgd,run_3/validation' 'sgd,run_4/train' 'sgd,run_4/validation' 'sgd,run_5/train' 'sgd,run_5/validation'] ['epoch_accuracy' 'epoch_loss']
Uzyskiwanie przestawnej (szerokoformatowej) ramki DataFrame
W naszym eksperymencie dwie zawieszki ( epoch_loss i epoch_accuracy ) są obecne w tych samych etapów w każdym okresie. To sprawia, że możliwe jest uzyskanie „szerokiego arkusza” DataFrame bezpośrednio get_scalars() za pomocą pivot=True kluczowego argumentu. Szeroka forma DataFrame ma wszystkie swoje tagi zawarte w kolumnach DataFrame, który jest bardziej wygodne do pracy z tym w niektórych przypadkach ten jeden.
Jednak pamiętaj, że jeśli warunek posiadania jednolitych zestawów wartości kroku we wszystkich znaczników we wszystkich seriach nie jest spełniony, używając pivot=True spowoduje wystąpienie błędu.
dfw = experiment.get_scalars(pivot=True)
dfw
Należy zauważyć, że zamiast jednej kolumnie „Wartość”, szeroki postać DataFrame zawiera dwa znaczniki (wartości) jak kolumnami wyraźnie: epoch_accuracy i epoch_loss .
Zapisywanie DataFrame jako CSV
pandas.DataFrame ma dobre współdziałanie z CSV . Możesz przechowywać go jako lokalny plik CSV i załadować go później. Na przykład:
csv_path = '/tmp/tb_experiment_1.csv'
dfw.to_csv(csv_path, index=False)
dfw_roundtrip = pd.read_csv(csv_path)
pd.testing.assert_frame_equal(dfw_roundtrip, dfw)
Wykonywanie niestandardowej wizualizacji i analizy statystycznej
# Filter the DataFrame to only validation data, which is what the subsequent
# analyses and visualization will be focused on.
dfw_validation = dfw[dfw.run.str.endswith("/validation")]
# Get the optimizer value for each row of the validation DataFrame.
optimizer_validation = dfw_validation.run.apply(lambda run: run.split(",")[0])
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
sns.lineplot(data=dfw_validation, x="step", y="epoch_accuracy",
hue=optimizer_validation).set_title("accuracy")
plt.subplot(1, 2, 2)
sns.lineplot(data=dfw_validation, x="step", y="epoch_loss",
hue=optimizer_validation).set_title("loss")
Text(0.5, 1.0, 'loss')
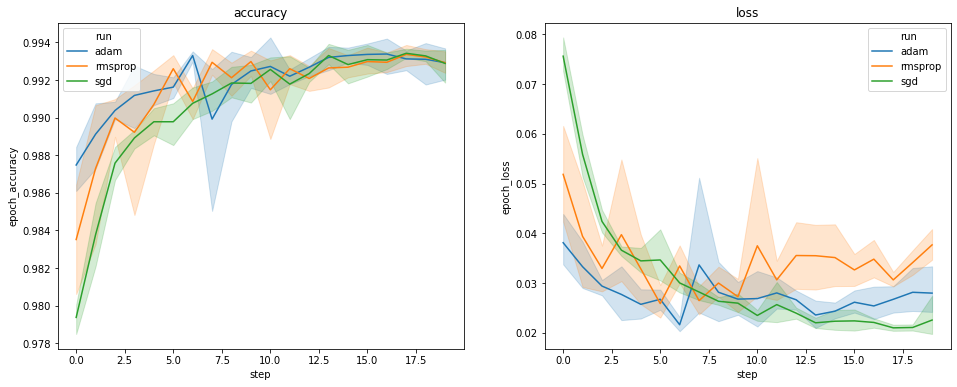
Powyższe wykresy pokazują przebiegi czasowe dokładności walidacji i utraty walidacji. Każda krzywa przedstawia średnią z 5 przebiegów dla danego typu optymalizatora. Dzięki wbudowanym cechą seaborn.lineplot() , każda krzywa Wyświetla również ± 1 odchylenie standardowe wokół średniej, co daje nam jasny sens zmienności tych krzywych i istotności różnic pomiędzy trzema typami Optimizer. Ta wizualizacja zmienności nie jest jeszcze obsługiwana w GUI TensorBoard.
Chcemy zbadać hipotezę, że minimalna utrata walidacji różni się znacząco między optymalizatorami „adam”, „rmsprop” i „sgd”. Tak więc wyodrębniamy DataFrame dla minimalnej utraty walidacji w każdym z optymalizatorów.
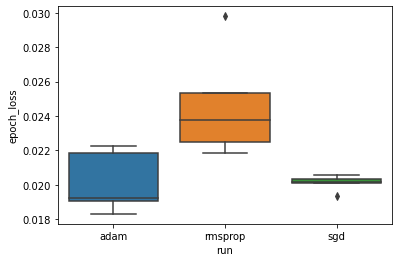
Następnie wykonujemy wykres pudełkowy, aby zwizualizować różnicę w minimalnych stratach walidacyjnych.
adam_min_val_loss = dfw_validation.loc[optimizer_validation=="adam", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
rmsprop_min_val_loss = dfw_validation.loc[optimizer_validation=="rmsprop", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
sgd_min_val_loss = dfw_validation.loc[optimizer_validation=="sgd", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
min_val_loss = pd.concat([adam_min_val_loss, rmsprop_min_val_loss, sgd_min_val_loss])
sns.boxplot(data=min_val_loss, y="epoch_loss",
x=min_val_loss.run.apply(lambda run: run.split(",")[0]))
<matplotlib.axes._subplots.AxesSubplot at 0x7f5e017c8150>
# Perform pairwise comparisons between the minimum validation losses
# from the three optimizers.
_, p_adam_vs_rmsprop = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
rmsprop_min_val_loss["epoch_loss"])
_, p_adam_vs_sgd = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
_, p_rmsprop_vs_sgd = stats.ttest_ind(
rmsprop_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
print("adam vs. rmsprop: p = %.4f" % p_adam_vs_rmsprop)
print("adam vs. sgd: p = %.4f" % p_adam_vs_sgd)
print("rmsprop vs. sgd: p = %.4f" % p_rmsprop_vs_sgd)
adam vs. rmsprop: p = 0.0244 adam vs. sgd: p = 0.9749 rmsprop vs. sgd: p = 0.0135
Dlatego przy poziomie istotności 0,05 nasza analiza potwierdza naszą hipotezę, że minimalna utrata walidacji jest znacznie wyższa (tj. gorsza) w optymalizatorze rmsprop w porównaniu z dwoma pozostałymi optymalizatorami uwzględnionymi w naszym eksperymencie.
Podsumowując, ten poradnik jest przykładem w jaki sposób uzyskać dostęp do danych skalarnych jak panda.DataFrame s od TensorBoard.dev. Świadczy to rodzaj elastycznych i wydajnych analiz i wizualizacji można zrobić z DataFrame s.