
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
W uczeniu maszynowym, aby coś ulepszyć, często trzeba umieć to zmierzyć. TensorBoard to narzędzie do dostarczania pomiarów i wizualizacji potrzebnych podczas przepływu pracy uczenia maszynowego. Umożliwia śledzenie metryk eksperymentu, takich jak strata i dokładność, wizualizacja wykresu modelu, rzutowanie osadzeń na niższą przestrzeń wymiarową i wiele więcej.
Ten krótki start pokaże, jak szybko rozpocząć pracę z TensorBoard. Pozostałe przewodniki w tej witrynie internetowej zawierają więcej szczegółów na temat konkretnych możliwości, z których wiele nie jest tutaj uwzględnionych.
# Load the TensorBoard notebook extension
%load_ext tensorboard
import tensorflow as tf
import datetime
# Clear any logs from previous runsrm -rf ./logs/
Korzystanie z MNIST zestaw danych jako przykład normalizacji danych i napisać funkcję, która tworzy prosty Keras modelu klasyfikacji obrazów w 10 klasach.
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
def create_model():
return tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 11493376/11490434 [==============================] - 0s 0us/step
Używanie TensorBoard z Keras Model.fit()
Podczas szkolenia z Keras za Model.fit () , dodając tf.keras.callbacks.TensorBoard zwrotna zapewnia, że dzienniki są tworzone i przechowywane. Ponadto, umożliwiają obliczenie histogramu każda epoka z histogram_freq=1 (to się domyślnie)
Umieść dzienniki w podkatalogu oznaczonym znacznikiem czasu, aby umożliwić łatwy wybór różnych przebiegów treningowych.
model = create_model()
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
log_dir = "logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
model.fit(x=x_train,
y=y_train,
epochs=5,
validation_data=(x_test, y_test),
callbacks=[tensorboard_callback])
Train on 60000 samples, validate on 10000 samples Epoch 1/5 60000/60000 [==============================] - 15s 246us/sample - loss: 0.2217 - accuracy: 0.9343 - val_loss: 0.1019 - val_accuracy: 0.9685 Epoch 2/5 60000/60000 [==============================] - 14s 229us/sample - loss: 0.0975 - accuracy: 0.9698 - val_loss: 0.0787 - val_accuracy: 0.9758 Epoch 3/5 60000/60000 [==============================] - 14s 231us/sample - loss: 0.0718 - accuracy: 0.9771 - val_loss: 0.0698 - val_accuracy: 0.9781 Epoch 4/5 60000/60000 [==============================] - 14s 227us/sample - loss: 0.0540 - accuracy: 0.9820 - val_loss: 0.0685 - val_accuracy: 0.9795 Epoch 5/5 60000/60000 [==============================] - 14s 228us/sample - loss: 0.0433 - accuracy: 0.9862 - val_loss: 0.0623 - val_accuracy: 0.9823 <tensorflow.python.keras.callbacks.History at 0x7fc8a5ee02e8>
Uruchom TensorBoard za pomocą wiersza poleceń lub w środowisku notebooka. Oba interfejsy są zasadniczo takie same. W notebookach, użyj %tensorboard magię linii. W wierszu poleceń uruchom to samo polecenie bez „%”.
%tensorboard --logdir logs/fit
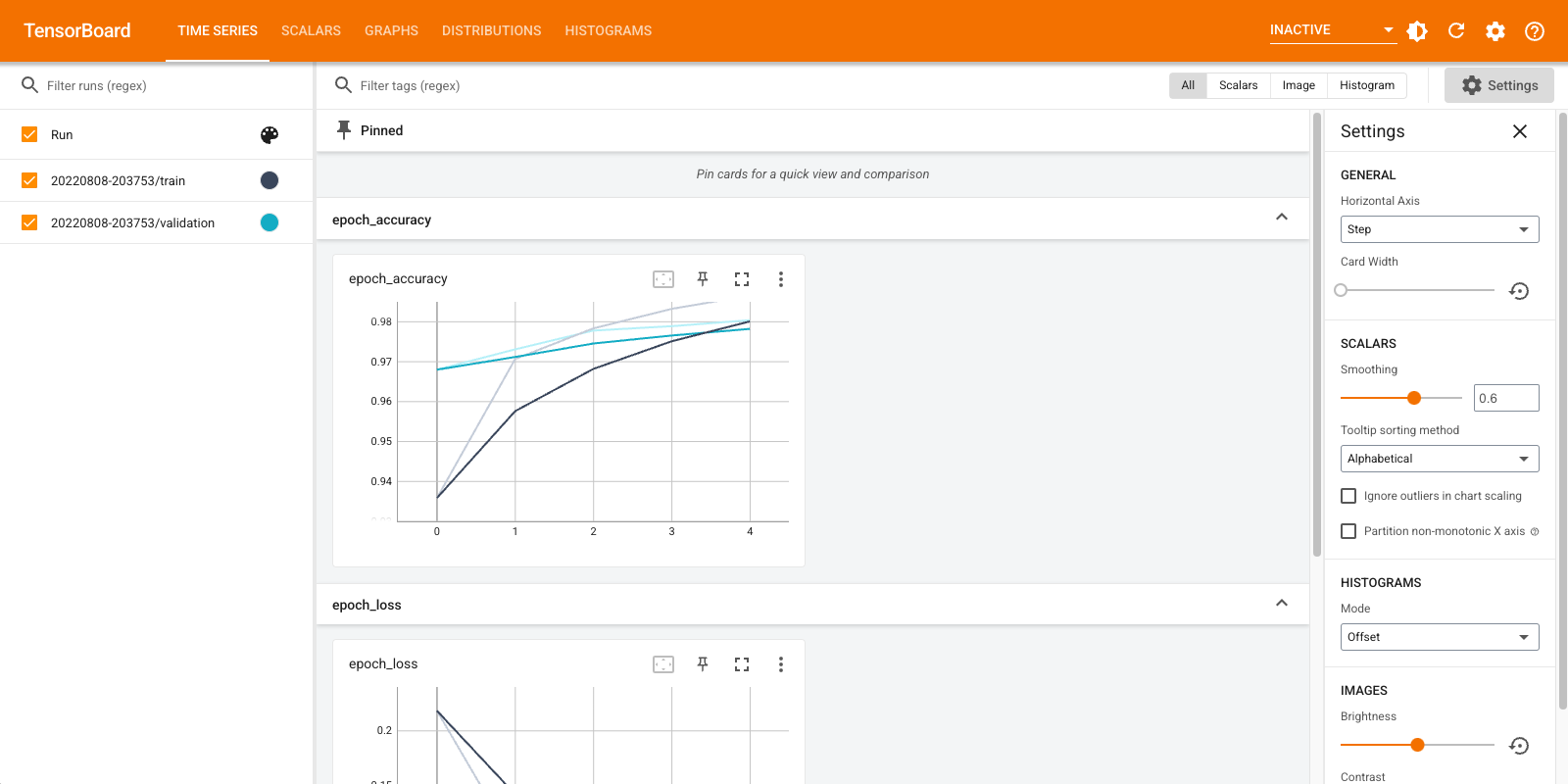
Krótki przegląd wyświetlanych pulpitów nawigacyjnych (karty na górnym pasku nawigacyjnym):
- Na wyświetlaczu deski rozdzielczej skalary jak strata i metryki zmienić z każdej epoce. Możesz go również użyć do śledzenia prędkości treningu, tempa uczenia się i innych wartości skalarnych.
- Wykresy desce rozdzielczej pozwala wizualizować swój model. W takim przypadku wyświetlany jest wykres warstw Keras, który może pomóc w zapewnieniu, że jest on poprawnie zbudowany.
- Rozkłady i kokpity Histogramy przedstawiają rozkład tensora w czasie. Może to być przydatne do wizualizacji wag i błędów systematycznych oraz weryfikacji, czy zmieniają się w oczekiwany sposób.
Dodatkowe wtyczki TensorBoard są automatycznie włączane, gdy logujesz inne rodzaje danych. Na przykład wywołanie zwrotne Keras TensorBoard pozwala również rejestrować obrazy i osadzania. Możesz zobaczyć, jakie inne wtyczki są dostępne w TensorBoard, klikając menu „nieaktywne” w prawym górnym rogu.
Korzystanie z TensorBoard z innymi metodami
Podczas szkolenia z metod, takich jak tf.GradientTape() , stosowanie tf.summary do logowania wymagane informacje.
Korzystać z tego samego zestawu danych jak wyżej, ale przekształcić go tf.data.Dataset do skorzystania z możliwości dozowania:
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
train_dataset = train_dataset.shuffle(60000).batch(64)
test_dataset = test_dataset.batch(64)
Kod szkolenia następuje zaawansowanego quickstart samouczek, ale pokazuje jak dane logowania do TensorBoard. Wybierz stratę i optymalizator:
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
optimizer = tf.keras.optimizers.Adam()
Twórz stanowe metryki, których można używać do gromadzenia wartości podczas uczenia i rejestrowania w dowolnym momencie:
# Define our metrics
train_loss = tf.keras.metrics.Mean('train_loss', dtype=tf.float32)
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('train_accuracy')
test_loss = tf.keras.metrics.Mean('test_loss', dtype=tf.float32)
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('test_accuracy')
Zdefiniuj funkcje treningowe i testowe:
def train_step(model, optimizer, x_train, y_train):
with tf.GradientTape() as tape:
predictions = model(x_train, training=True)
loss = loss_object(y_train, predictions)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
train_loss(loss)
train_accuracy(y_train, predictions)
def test_step(model, x_test, y_test):
predictions = model(x_test)
loss = loss_object(y_test, predictions)
test_loss(loss)
test_accuracy(y_test, predictions)
Skonfiguruj programy zapisujące podsumowania, aby zapisywały podsumowania na dysku w innym katalogu dzienników:
current_time = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
train_log_dir = 'logs/gradient_tape/' + current_time + '/train'
test_log_dir = 'logs/gradient_tape/' + current_time + '/test'
train_summary_writer = tf.summary.create_file_writer(train_log_dir)
test_summary_writer = tf.summary.create_file_writer(test_log_dir)
Zacznij trenować. Użyj tf.summary.scalar() do metryk (strata i dokładność) log podczas treningu / testowania w ramach podsumowania pisarzy pisać streszczenia na dysku. Masz kontrolę nad tym, które metryki chcesz rejestrować i jak często to robić. Inne tf.summary funkcje umożliwiają zalogowaniu inne rodzaje danych.
model = create_model() # reset our model
EPOCHS = 5
for epoch in range(EPOCHS):
for (x_train, y_train) in train_dataset:
train_step(model, optimizer, x_train, y_train)
with train_summary_writer.as_default():
tf.summary.scalar('loss', train_loss.result(), step=epoch)
tf.summary.scalar('accuracy', train_accuracy.result(), step=epoch)
for (x_test, y_test) in test_dataset:
test_step(model, x_test, y_test)
with test_summary_writer.as_default():
tf.summary.scalar('loss', test_loss.result(), step=epoch)
tf.summary.scalar('accuracy', test_accuracy.result(), step=epoch)
template = 'Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, Test Accuracy: {}'
print (template.format(epoch+1,
train_loss.result(),
train_accuracy.result()*100,
test_loss.result(),
test_accuracy.result()*100))
# Reset metrics every epoch
train_loss.reset_states()
test_loss.reset_states()
train_accuracy.reset_states()
test_accuracy.reset_states()
Epoch 1, Loss: 0.24321186542510986, Accuracy: 92.84333801269531, Test Loss: 0.13006582856178284, Test Accuracy: 95.9000015258789 Epoch 2, Loss: 0.10446818172931671, Accuracy: 96.84833526611328, Test Loss: 0.08867532759904861, Test Accuracy: 97.1199951171875 Epoch 3, Loss: 0.07096975296735764, Accuracy: 97.80166625976562, Test Loss: 0.07875105738639832, Test Accuracy: 97.48999786376953 Epoch 4, Loss: 0.05380449816584587, Accuracy: 98.34166717529297, Test Loss: 0.07712937891483307, Test Accuracy: 97.56999969482422 Epoch 5, Loss: 0.041443776339292526, Accuracy: 98.71833038330078, Test Loss: 0.07514958828687668, Test Accuracy: 97.5
Otwórz ponownie TensorBoard, tym razem wskazując go na nowy katalog dziennika. Mogliśmy również uruchomić TensorBoard, aby monitorować postępy w szkoleniu.
%tensorboard --logdir logs/gradient_tape
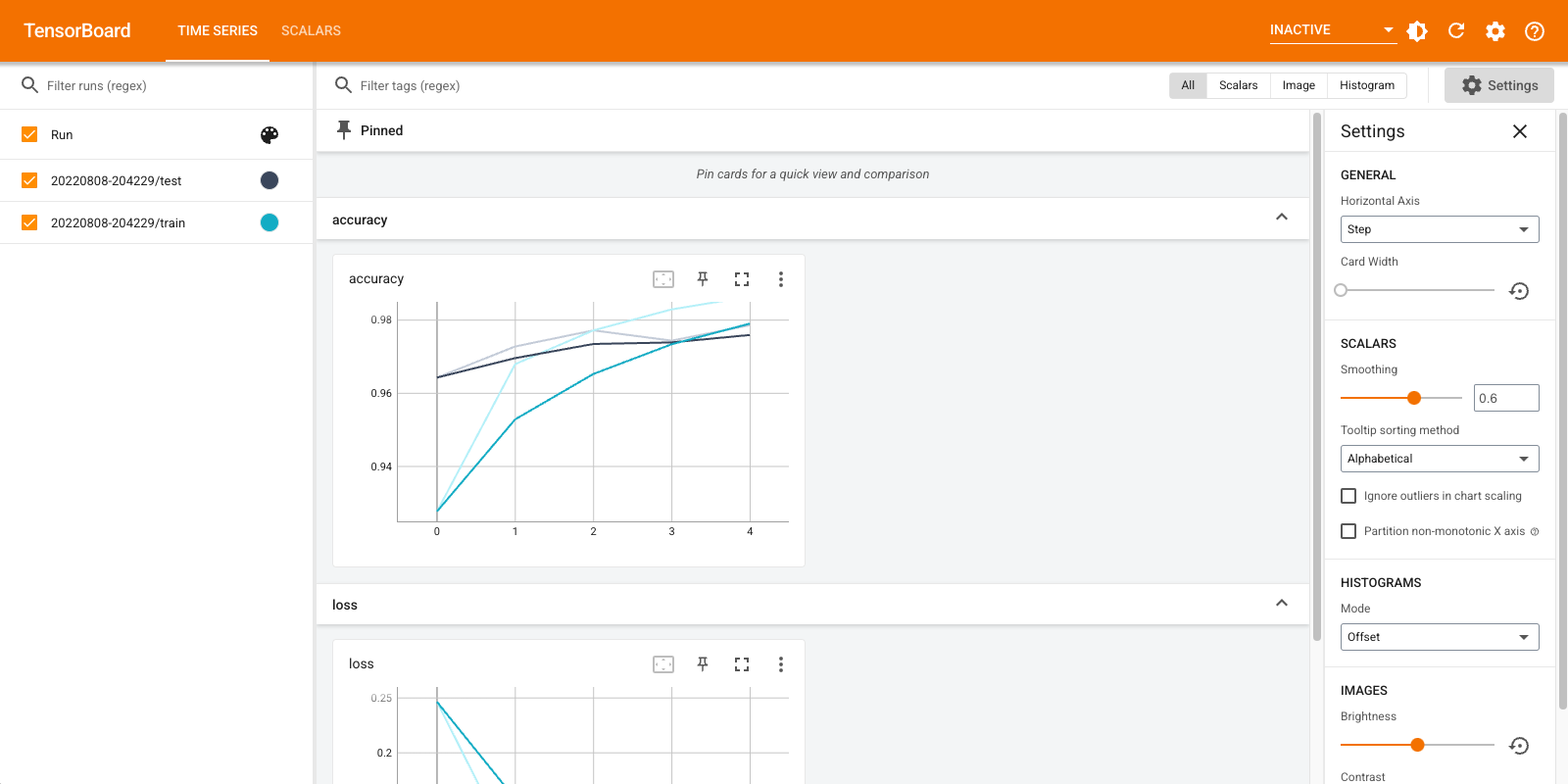
Otóż to! Już teraz widać, jak korzystać TensorBoard zarówno poprzez oddzwonienie Keras i przez tf.summary dla bardziej niestandardowych scenariuszy.
TensorBoard.dev: Hostuj i udostępniaj wyniki swoich eksperymentów ML
TensorBoard.dev to darmowa usługa publiczna, która pozwala na przesyłanie logów TensorBoard a otrzymasz odnośnik, który może być udostępniony wszystkim prac naukowych, blogach, social media itp Może to umożliwić lepszą powtarzalność i współpracę.
Aby użyć TensorBoard.dev, uruchom następujące polecenie:
!tensorboard dev upload \
--logdir logs/fit \
--name "(optional) My latest experiment" \
--description "(optional) Simple comparison of several hyperparameters" \
--one_shot
Zauważ, że ta inwokacja wykorzystuje prefiks wykrzyknik ( ! ), Aby uruchomić powłokę zamiast prefiksu procentu ( % ) do powoływania się na magię colab. Podczas wywoływania tego polecenia z wiersza poleceń nie ma potrzeby stosowania żadnego przedrostka.
Zobacz przykład tutaj .
Aby uzyskać więcej informacji na temat korzystania z TensorBoard.dev patrz https://tensorboard.dev/#get-started