
يمكن أن تحدث أحيانًا أحداث كارثية تتضمن NaN أثناء برنامج TensorFlow، مما يؤدي إلى تعطيل عمليات التدريب النموذجية. غالبًا ما يكون السبب الجذري لمثل هذه الأحداث غامضًا، خاصة بالنسبة للنماذج ذات الحجم والتعقيد غير التافهين. لتسهيل تصحيح هذا النوع من أخطاء النماذج، يوفر TensorBoard 2.3+ (مع TensorFlow 2.3+) لوحة معلومات متخصصة تسمى Debugger V2. نوضح هنا كيفية استخدام هذه الأداة من خلال التعامل مع خطأ حقيقي يتضمن NaNs في شبكة عصبية مكتوبة في TensorFlow.
تنطبق التقنيات الموضحة في هذا البرنامج التعليمي على أنواع أخرى من أنشطة تصحيح الأخطاء مثل فحص أشكال موتر وقت التشغيل في البرامج المعقدة. يركز هذا البرنامج التعليمي على NaNs نظرًا لتكرار حدوثها المرتفع نسبيًا.
مراقبة الخلل
الكود المصدري لبرنامج TF2 الذي سنقوم بتصحيحه متاح على GitHub . يتم أيضًا تجميع البرنامج النموذجي في حزمة Tensorflow pip (الإصدار 2.3+) ويمكن استدعاؤه بواسطة:
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2
يقوم برنامج TF2 بإنشاء إدراك متعدد الطبقات (MLP) ويدربه على التعرف على صور MNIST . يستخدم هذا المثال بشكل مقصود واجهة برمجة التطبيقات (API) ذات المستوى المنخفض لـ TF2 لتحديد بنيات الطبقة المخصصة ووظيفة الخسارة وحلقة التدريب، لأن احتمال حدوث أخطاء NaN يكون أعلى عندما نستخدم واجهة برمجة التطبيقات (API) الأكثر مرونة ولكن الأكثر عرضة للخطأ مقارنة عندما نستخدم واجهة برمجة التطبيقات الأسهل (API) - واجهات برمجة التطبيقات (APIs) عالية المستوى للاستخدام ولكن أقل مرونة قليلاً مثل tf.keras .
يقوم البرنامج بطباعة دقة الاختبار بعد كل خطوة تدريبية. يمكننا أن نرى في وحدة التحكم أن دقة الاختبار تتعطل عند مستوى قريب من الصدفة (~ 0.1) بعد الخطوة الأولى. من المؤكد أن هذه ليست الطريقة التي من المتوقع أن يتصرف بها تدريب النموذج: نتوقع أن تقترب الدقة تدريجيًا من 1.0 (100%) مع زيادة الخطوة.
Accuracy at step 0: 0.216
Accuracy at step 1: 0.098
Accuracy at step 2: 0.098
Accuracy at step 3: 0.098
...
التخمين المدروس هو أن سبب هذه المشكلة هو عدم الاستقرار العددي، مثل NaN أو اللانهاية. ومع ذلك، كيف نؤكد أن هذا هو الحال بالفعل وكيف نجد عملية TensorFlow (op) المسؤولة عن توليد عدم الاستقرار العددي؟ للإجابة على هذه الأسئلة، دعونا نجهز برنامج الأخطاء باستخدام Debugger V2.
استخدام كود TensorFlow باستخدام Debugger V2
tf.debugging.experimental.enable_dump_debug_info() هي نقطة إدخال API الخاصة بـ Debugger V2. إنه يستخدم برنامج TF2 مع سطر واحد من التعليمات البرمجية. على سبيل المثال، ستؤدي إضافة السطر التالي بالقرب من بداية البرنامج إلى كتابة معلومات تصحيح الأخطاء في دليل السجل (logdir) على /tmp/tfdbg2_logdir. تغطي معلومات التصحيح جوانب مختلفة من وقت تشغيل TensorFlow. في TF2، يتضمن التاريخ الكامل للتنفيذ المتحمس، وبناء الرسم البياني الذي يتم تنفيذه بواسطة @tf.function ، وتنفيذ الرسوم البيانية، وقيم الموتر الناتجة عن أحداث التنفيذ، بالإضافة إلى موقع التعليمات البرمجية (تتبعات مكدس بايثون) لتلك الأحداث . إن ثراء معلومات تصحيح الأخطاء يمكّن المستخدمين من تضييق نطاق الأخطاء الغامضة.
tf.debugging.experimental.enable_dump_debug_info(
"/tmp/tfdbg2_logdir",
tensor_debug_mode="FULL_HEALTH",
circular_buffer_size=-1)
تتحكم الوسيطة tensor_debug_mode في المعلومات التي يستخرجها Debugger V2 من كل موتر حريص أو في الرسم البياني. "FULL_HEALTH" هو الوضع الذي يلتقط المعلومات التالية حول كل موتر من النوع العائم (على سبيل المثال، float32 الشائع والنوع bfloat16 dtype الأقل شيوعًا):
- نوع D
- رتبة
- العدد الإجمالي للعناصر
- تقسيم العناصر العائمة إلى الفئات التالية: سالب محدود (
-)، صفر (0)، موجب محدود (+)، سالب لا نهاية (-∞)، موجب لانهاية (+∞) ، وNaN.
يعد الوضع "FULL_HEALTH" مناسبًا لتصحيح الأخطاء التي تتضمن NaN وInfinity. انظر أدناه للتعرف على أدوات tensor_debug_mode الأخرى المدعومة.
تتحكم الوسيطة circular_buffer_size في عدد أحداث الموتر التي يتم حفظها في السجل. يكون الإعداد الافتراضي هو 1000، مما يؤدي إلى حفظ آخر 1000 موتر فقط قبل نهاية برنامج TF2 المُجهز على القرص. يعمل هذا السلوك الافتراضي على تقليل حمل مصحح الأخطاء عن طريق التضحية باكتمال بيانات تصحيح الأخطاء. إذا كان الاكتمال هو المفضل، كما في هذه الحالة، يمكننا تعطيل المخزن المؤقت الدائري عن طريق تعيين الوسيط إلى قيمة سالبة (على سبيل المثال، -1 هنا).
يستدعي مثال debug_mnist_v2 enable_dump_debug_info() عن طريق تمرير إشارات سطر الأوامر إليه. لتشغيل برنامج TF2 الذي به مشكلات مرة أخرى مع تمكين أدوات تصحيح الأخطاء هذه، قم بما يلي:
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2 \
--dump_dir /tmp/tfdbg2_logdir --dump_tensor_debug_mode FULL_HEALTH
بدء تشغيل واجهة المستخدم الرسومية Debugger V2 في TensorBoard
يؤدي تشغيل البرنامج باستخدام أدوات مصحح الأخطاء إلى إنشاء ملف logdir على /tmp/tfdbg2_logdir. يمكننا تشغيل TensorBoard وتوجيهه إلى logdir باستخدام:
tensorboard --logdir /tmp/tfdbg2_logdir
في متصفح الويب، انتقل إلى صفحة TensorBoard على http://localhost:6006. سيكون المكون الإضافي "Debugger V2" غير نشط بشكل افتراضي، لذا حدده من قائمة "المكونات الإضافية غير النشطة" في أعلى اليمين. بعد التحديد، يجب أن يبدو كما يلي:
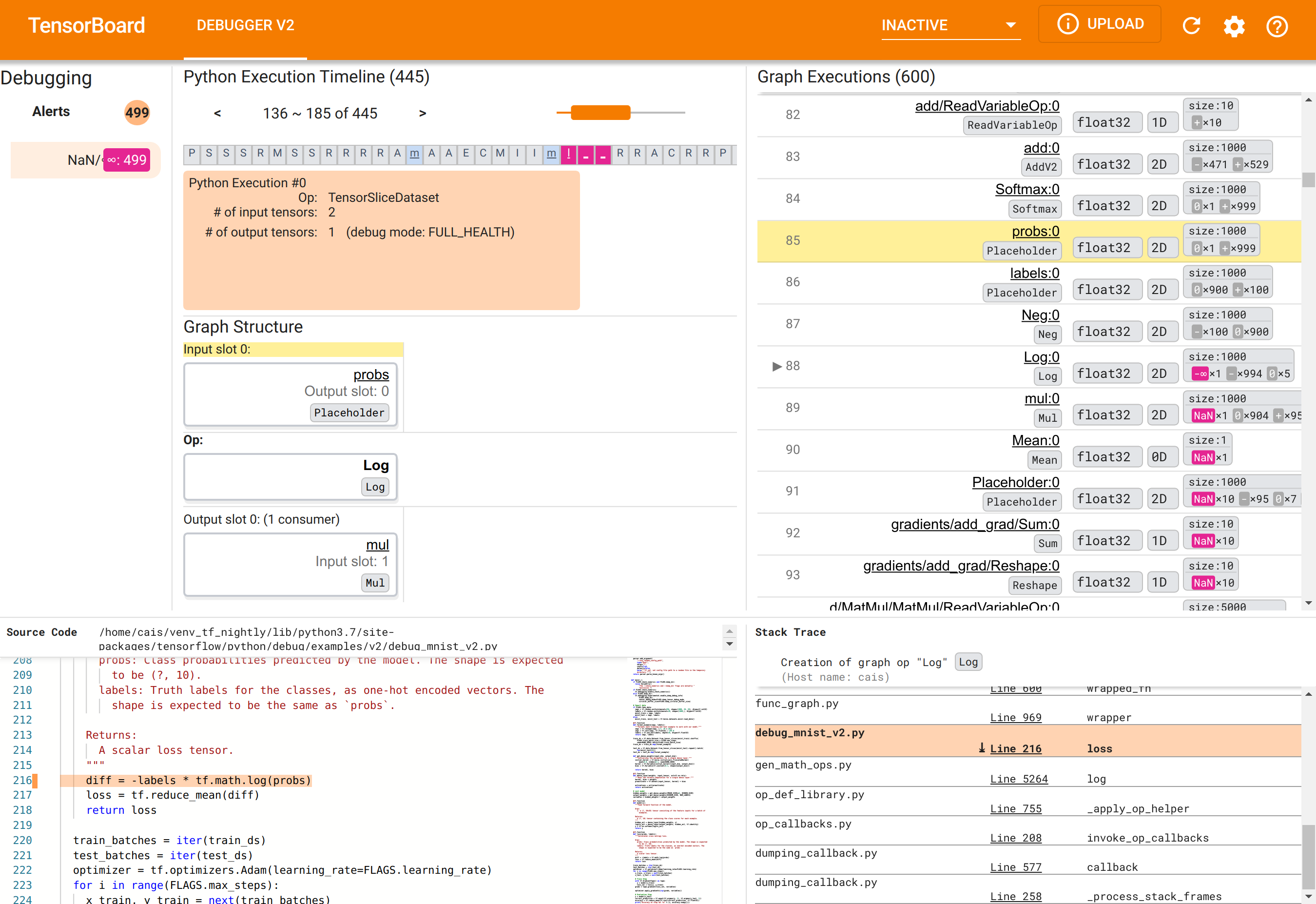
استخدام Debugger V2 GUI للعثور على السبب الجذري لـ NaNs
يتم تنظيم واجهة المستخدم الرسومية Debugger V2 في TensorBoard إلى ستة أقسام:
- التنبيهات : يحتوي هذا القسم العلوي الأيسر على قائمة بأحداث "التنبيه" التي اكتشفها مصحح الأخطاء في بيانات تصحيح الأخطاء من برنامج TensorFlow المُجهز. يشير كل تنبيه إلى حالة شاذة معينة تستحق الاهتمام. في حالتنا، يسلط هذا القسم الضوء على 499 حدثًا NaN/∞ بلون وردي-أحمر بارز. وهذا يؤكد شكوكنا في أن النموذج يفشل في التعلم بسبب وجود NaNs و/أو اللانهاية في قيم الموتر الداخلية الخاصة به. سنتعمق في هذه التنبيهات قريبًا.
- الجدول الزمني لتنفيذ بايثون : هذا هو النصف العلوي من القسم العلوي الأوسط. ويعرض التاريخ الكامل للتنفيذ المتلهف للعمليات والرسوم البيانية. يتم تمييز كل مربع من المخطط الزمني بالحرف الأول من اسم العملية أو الرسم البياني (على سبيل المثال، "T" بالنسبة إلى "TensorSliceDataset" op، و"m" بالنسبة إلى "model"
tf.function). يمكننا التنقل في هذا المخطط الزمني باستخدام أزرار التنقل وشريط التمرير الموجود أعلى المخطط الزمني. - تنفيذ الرسم البياني : يقع هذا القسم في الزاوية العلوية اليمنى من واجهة المستخدم الرسومية، وسيكون محوريًا في مهمة تصحيح الأخطاء لدينا. يحتوي على تاريخ لجميع موترات النوع العائم المحسوبة داخل الرسوم البيانية (أي، تم تجميعها بواسطة
@tf-functions). - هيكل الرسم البياني (النصف السفلي من القسم العلوي الأوسط)، وشفرة المصدر (القسم السفلي الأيسر)، وتتبع المكدس (القسم السفلي الأيمن) تكون فارغة في البداية. سيتم ملء محتوياتها عندما نتفاعل مع واجهة المستخدم الرسومية. ستلعب هذه الأقسام الثلاثة أيضًا أدوارًا مهمة في مهمة تصحيح الأخطاء لدينا.
بعد أن وجهنا أنفسنا نحو تنظيم واجهة المستخدم، فلنتخذ الخطوات التالية للوصول إلى سبب ظهور NaNs. أولاً، انقر فوق تنبيه NaN/∞ في قسم التنبيهات. يؤدي هذا تلقائيًا إلى تمرير قائمة موترات الرسم البياني البالغ عددها 600 في قسم تنفيذ الرسم البياني والتركيز على رقم 88، وهو موتر يسمى Log:0 تم إنشاؤه بواسطة Log (اللوغاريتم الطبيعي). يسلط اللون الوردي والأحمر البارز الضوء على عنصر -∞ من بين 1000 عنصر في الموتر ثنائي الأبعاد float32. هذا هو الموتر الأول في تاريخ تشغيل برنامج TF2 الذي يحتوي على أي NaN أو لانهاية: الموترات المحسوبة قبله لا تحتوي على NaN أو ∞؛ تحتوي العديد من الموترات (في الواقع، معظمها) المحسوبة بعد ذلك على NaNs. يمكننا تأكيد ذلك من خلال التمرير لأعلى ولأسفل في قائمة تنفيذ الرسم البياني. توفر هذه الملاحظة تلميحًا قويًا بأن عملية Log op هي مصدر عدم الاستقرار العددي في برنامج TF2 هذا.
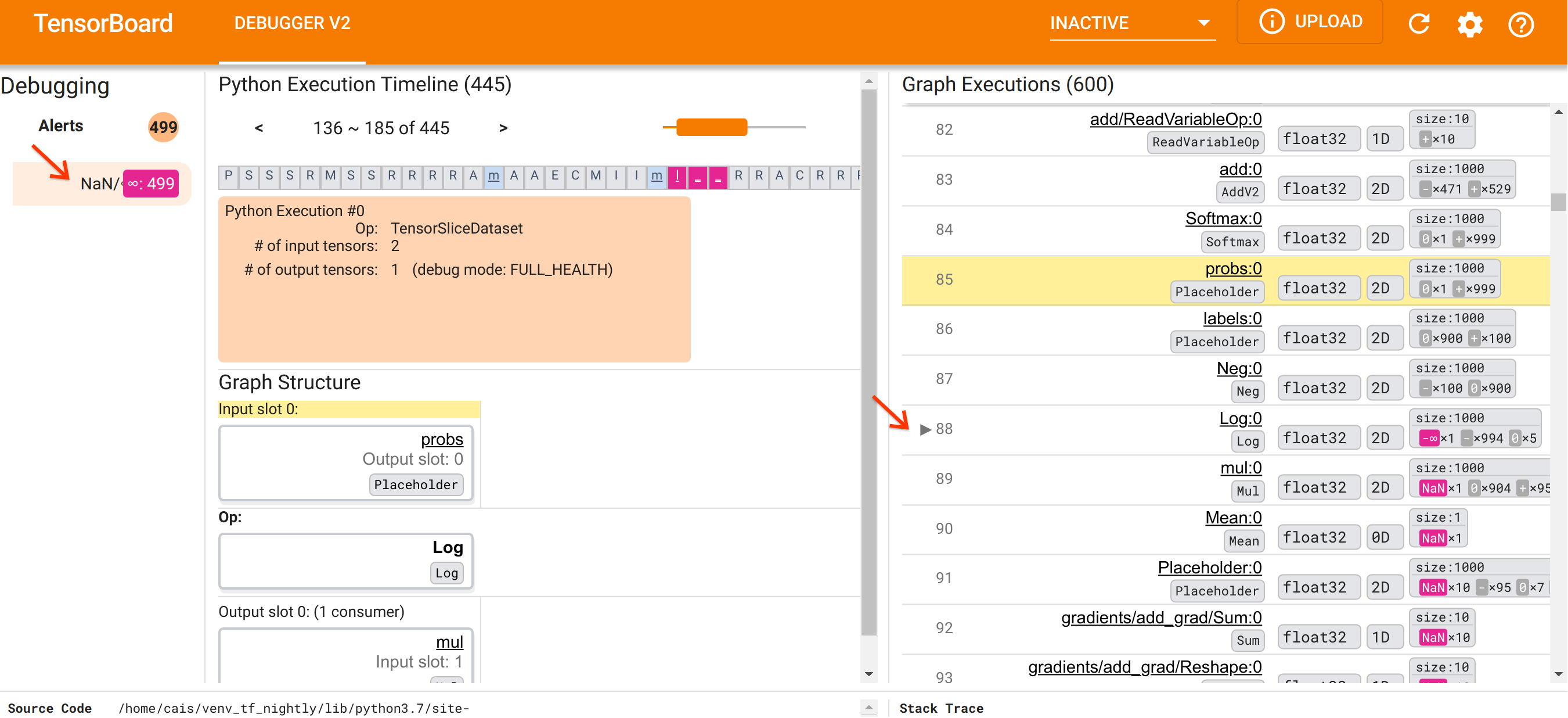
لماذا يقوم Log هذا بإخراج -∞؟ تتطلب الإجابة على هذا السؤال فحص المدخلات إلى المرجع. يؤدي النقر فوق اسم الموتر ( Log:0 ) إلى إظهار تصور بسيط ولكنه غني بالمعلومات للمنطقة المجاورة لـ Log op في الرسم البياني TensorFlow الخاص به في قسم Graph Structure. لاحظ الاتجاه من أعلى إلى أسفل لتدفق المعلومات. يظهر المرجع نفسه بالخط العريض في المنتصف. مباشرة فوقه، يمكننا أن نرى عنصرًا نائبًا يوفر الإدخال الوحيد لعملية Log . أين يوجد الموتر الناتج عن هذا العنصر probs في قائمة تنفيذ الرسم البياني؟ باستخدام لون الخلفية الصفراء كمساعد بصري، يمكننا أن نرى أن موتر probs:0 يقع بثلاثة صفوف فوق Log:0 ، أي في الصف 85.
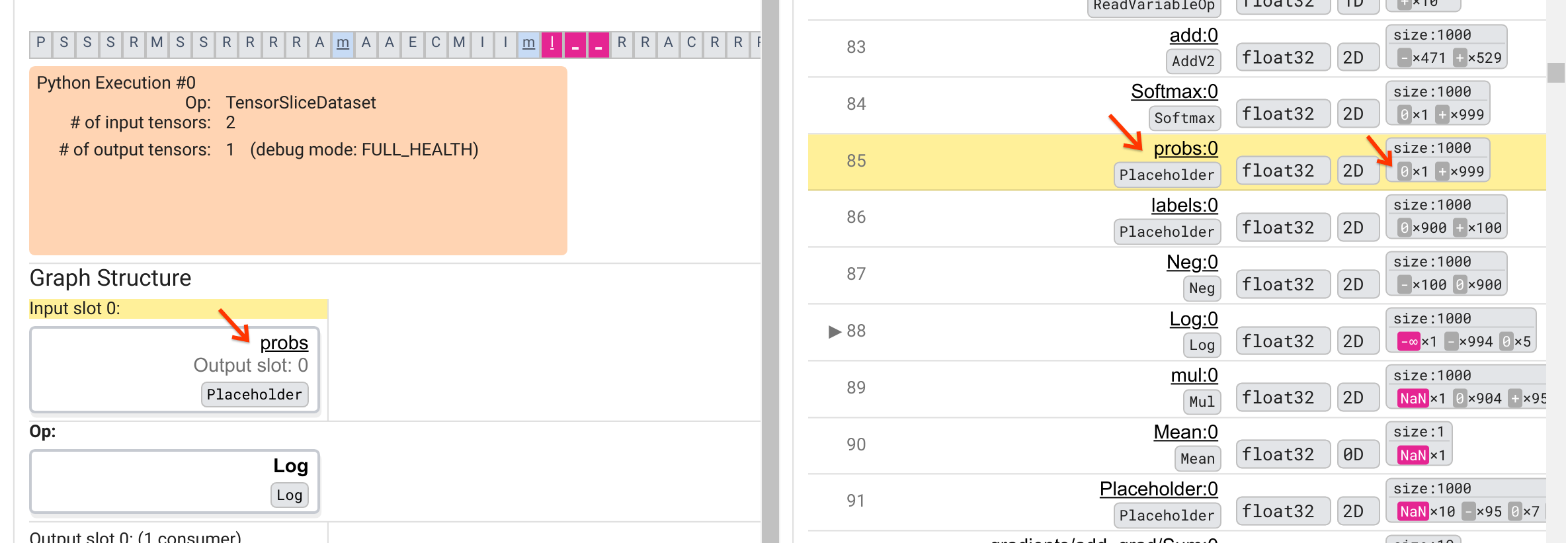
نظرة أكثر دقة على التقسيم العددي لـ probs:0 Tensor في الصف 85 تكشف سبب إنتاج Log:0 لـ -∞: من بين 1000 عنصر من probs:0 ، عنصر واحد له قيمة 0. -∞ هو نتيجة لحساب اللوغاريتم الطبيعي لل0! إذا تمكنا بطريقة ما من التأكد من أن عملية Log تتعرض للمدخلات الإيجابية فقط، فسنكون قادرين على منع حدوث NaN/∞. يمكن تحقيق ذلك عن طريق تطبيق القطع (على سبيل المثال، باستخدام tf.clip_by_value() ) على موتر probs للعنصر النائب.
نحن نقترب من حل الخلل، ولكننا لم ننته بعد. من أجل تطبيق الإصلاح، نحتاج إلى معرفة مكان إنشاء Log وإدخال العنصر النائب في كود مصدر Python. يوفر Debugger V2 دعمًا من الدرجة الأولى لتتبع عمليات الرسم البياني وأحداث التنفيذ حتى مصدرها. عندما نقرنا على Log:0 في عمليات تنفيذ الرسم البياني، تمت تعبئة قسم تتبع المكدس بتتبع المكدس الأصلي لإنشاء عملية Log . يعد تتبع المكدس كبيرًا إلى حد ما لأنه يتضمن العديد من الإطارات من التعليمات البرمجية الداخلية لـ TensorFlow (على سبيل المثال، gen_math_ops.py و dumping_callback.py)، والتي يمكننا تجاهلها بأمان لمعظم مهام تصحيح الأخطاء. الإطار محل الاهتمام هو السطر 216 من debug_mnist_v2.py (أي ملف Python الذي نحاول تصحيحه بالفعل). يؤدي النقر فوق "السطر 216" إلى عرض السطر المقابل من التعليمات البرمجية في قسم كود المصدر.
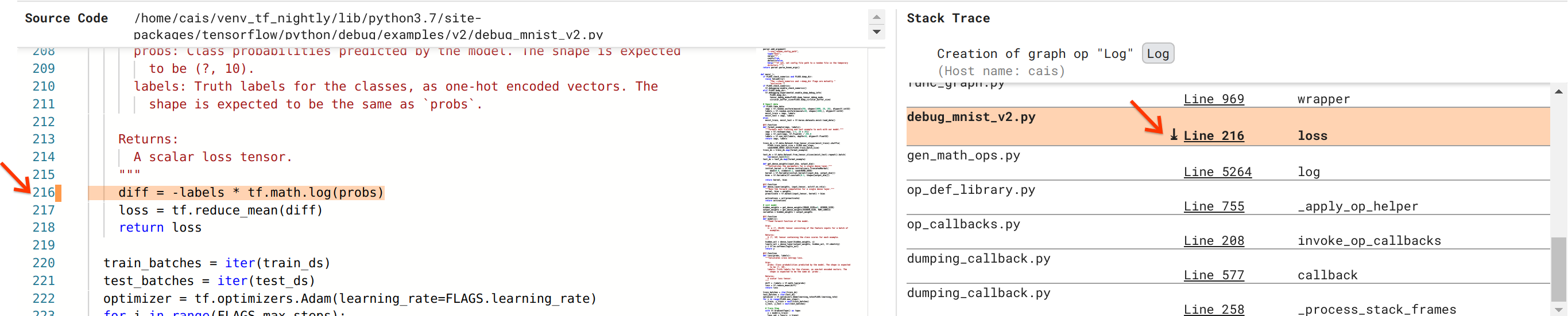
يقودنا هذا أخيرًا إلى الكود المصدري الذي أنشأ عملية Log op الإشكالية من مدخلات probs الخاصة بها. هذه هي دالة الخسارة الفئوية المخصصة للإنتروبيا المزينة بـ @tf.function وبالتالي يتم تحويلها إلى رسم بياني TensorFlow. تتوافق probs الخاصة بالعنصر النائب مع وسيطة الإدخال الأولى لوظيفة الخسارة. يتم إنشاء عملية Log باستخدام استدعاء tf.math.log() API.
سيبدو إصلاح قص القيمة لهذا الخطأ كما يلي:
diff = -(labels *
tf.math.log(tf.clip_by_value(probs), 1e-6, 1.))
سوف يحل عدم الاستقرار العددي في برنامج TF2 ويتسبب في تدريب MLP بنجاح. هناك طريقة أخرى محتملة لإصلاح عدم الاستقرار العددي وهي استخدام tf.keras.losses.CategoricalCrossentropy .
بهذا نختتم رحلتنا من ملاحظة خطأ في نموذج TF2 إلى التوصل إلى تغيير في التعليمات البرمجية يعمل على إصلاح الخطأ، بمساعدة أداة Debugger V2، التي توفر رؤية كاملة لتاريخ التنفيذ المتلهف والرسم البياني لبرنامج TF2 المجهز، بما في ذلك الملخصات الرقمية لقيم الموتر والارتباط بين العمليات والموترات وكود مصدرها الأصلي.
توافق الأجهزة مع Debugger V2
يدعم Debugger V2 أجهزة التدريب السائدة بما في ذلك وحدة المعالجة المركزية (CPU) ووحدة معالجة الرسومات (GPU). يتم أيضًا دعم التدريب على وحدات معالجة الرسومات المتعددة باستخدام tf.distributed.MirroredStrategy . لا يزال دعم TPU في مرحلة مبكرة ويتطلب الاتصال
tf.config.set_soft_device_placement(True)
قبل استدعاء enable_dump_debug_info() . قد يكون لها قيود أخرى على TPU أيضًا. إذا واجهت مشكلات في استخدام Debugger V2، فيرجى الإبلاغ عن الأخطاء على صفحة مشكلات GitHub الخاصة بنا.
توافق API لـ Debugger V2
يتم تطبيق Debugger V2 على مستوى منخفض نسبيًا من مجموعة برامج TensorFlow، وبالتالي فهو متوافق مع tf.keras و tf.data وواجهات برمجة التطبيقات الأخرى المبنية على أعلى مستويات TensorFlow المنخفضة. Debugger V2 متوافق أيضًا مع الإصدارات السابقة مع TF1، على الرغم من أن الجدول الزمني لتنفيذ Eager سيكون فارغًا لأقراص تسجيل التصحيح التي تم إنشاؤها بواسطة برامج TF1.
نصائح لاستخدام واجهة برمجة التطبيقات
السؤال المتكرر حول واجهة برمجة التطبيقات لتصحيح الأخطاء هذه هو المكان الذي يجب فيه إدراج استدعاء enable_dump_debug_info() في كود TensorFlow. عادةً، يجب استدعاء واجهة برمجة التطبيقات (API) في أقرب وقت ممكن في برنامج TF2 الخاص بك، ويفضل أن يكون ذلك بعد سطور استيراد Python وقبل البدء في إنشاء الرسم البياني وتنفيذه. سيضمن هذا التغطية الكاملة لجميع العمليات والرسوم البيانية التي تدعم نموذجك وتدريبه.
أوضاع Tensor_debug_modes المدعومة حاليًا هي: NO_TENSOR و CURT_HEALTH و CONCISE_HEALTH و FULL_HEALTH و SHAPE . وهي تختلف في كمية المعلومات المستخرجة من كل موتر وأداء البرنامج الذي تم تصحيحه. يرجى الرجوع إلى قسم الوسائط في وثائق enable_dump_debug_info() .
الأداء العام
تقدم واجهة برمجة التطبيقات (API) لتصحيح الأخطاء أداءً إضافيًا لبرنامج TensorFlow المُجهز. يختلف الحمل حسب tensor_debug_mode ونوع الجهاز وطبيعة برنامج TensorFlow المجهز. كنقطة مرجعية، على وحدة معالجة الرسومات، يضيف وضع NO_TENSOR حملًا إضافيًا بنسبة 15% أثناء تدريب نموذج Transformer ضمن حجم الدفعة 64. وتكون نسبة الحمل الزائد لأوضاع Tensor_debug_modes الأخرى أعلى: حوالي 50% لـ CURT_HEALTH و CONCISE_HEALTH و FULL_HEALTH و SHAPE وسائط. على وحدات المعالجة المركزية (CPU)، يكون الحمل أقل قليلاً. على أجهزة TPU، يكون الحمل أعلى حاليًا.
العلاقة بواجهات برمجة التطبيقات الأخرى لتصحيح أخطاء TensorFlow
لاحظ أن TensorFlow يقدم أدوات وواجهات برمجة تطبيقات أخرى لتصحيح الأخطاء. يمكنك تصفح واجهات برمجة التطبيقات هذه ضمن مساحة الاسم tf.debugging.* في صفحة مستندات API. من بين واجهات برمجة التطبيقات هذه الأكثر استخدامًا هي tf.print() . متى يجب استخدام Debugger V2 ومتى يجب استخدام tf.print() بدلاً من ذلك؟ tf.print() مناسب في حالة وجود
- نحن نعرف بالضبط أي التوترات يجب طباعتها،
- نحن نعرف المكان المحدد في الكود المصدري لإدراج عبارات
tf.print()، - عدد هذه الموترات ليس كبيرًا جدًا.
بالنسبة للحالات الأخرى (على سبيل المثال، فحص العديد من قيم الموتر، وفحص قيم الموتر التي تم إنشاؤها بواسطة التعليمات البرمجية الداخلية لـ TensorFlow، والبحث عن أصل عدم الاستقرار الرقمي كما أظهرنا أعلاه)، يوفر Debugger V2 طريقة أسرع لتصحيح الأخطاء. بالإضافة إلى ذلك، يوفر Debugger V2 أسلوبًا موحدًا لفحص موترات التواقة والرسم البياني. بالإضافة إلى ذلك، فإنه يوفر معلومات حول بنية الرسم البياني ومواقع التعليمات البرمجية، والتي تتجاوز قدرة tf.print() .
واجهة برمجة تطبيقات أخرى يمكن استخدامها لتصحيح المشكلات المتعلقة بـ ∞ وNaN هي tf.debugging.enable_check_numerics() . على عكس enable_dump_debug_info() ، لا يحفظ enable_check_numerics() معلومات تصحيح الأخطاء على القرص. بدلاً من ذلك، فهو يقوم فقط بمراقبة ∞ وNaN أثناء وقت تشغيل TensorFlow والأخطاء في موقع رمز الأصل بمجرد أن تولد أي عملية مثل هذه القيم الرقمية السيئة. يتميز بأداء أقل مقارنةً بـ enable_dump_debug_info() ، لكنه لا يوفر تتبعًا كاملاً لسجل تنفيذ البرنامج ولا يأتي مزودًا بواجهة مستخدم رسومية مثل Debugger V2.