
Des événements catastrophiques impliquant des NaN peuvent parfois survenir au cours d'un programme TensorFlow, paralysant les processus de formation du modèle. La cause profonde de tels événements est souvent obscure, en particulier pour les modèles de taille et de complexité non triviales. Pour faciliter le débogage de ce type de bugs de modèle, TensorBoard 2.3+ (avec TensorFlow 2.3+) fournit un tableau de bord spécialisé appelé Debugger V2. Nous montrons ici comment utiliser cet outil en travaillant sur un véritable bug impliquant des NaN dans un réseau neuronal écrit en TensorFlow.
Les techniques illustrées dans ce didacticiel sont applicables à d'autres types d'activités de débogage, telles que l'inspection des formes du tenseur d'exécution dans des programmes complexes. Ce didacticiel se concentre sur les NaN en raison de leur fréquence d'apparition relativement élevée.
Observer le bug
Le code source du programme TF2 que nous allons déboguer est disponible sur GitHub . L'exemple de programme est également intégré au package tensorflow pip (version 2.3+) et peut être invoqué par :
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2
Ce programme TF2 crée une perception multicouche (MLP) et l'entraîne à reconnaître les images MNIST . Cet exemple utilise délibérément l'API de bas niveau de TF2 pour définir des constructions de couches personnalisées, une fonction de perte et une boucle d'entraînement, car la probabilité de bogues NaN est plus élevée lorsque nous utilisons cette API plus flexible mais plus sujette aux erreurs que lorsque nous utilisons l'API plus simple. -des API de haut niveau faciles à utiliser mais légèrement moins flexibles telles que tf.keras .
Le programme imprime un test de précision après chaque étape de formation. Nous pouvons voir dans la console que la précision du test reste bloquée à un niveau proche du hasard (~0,1) après la première étape. Ce n'est certainement pas ainsi que la formation du modèle est censée se comporter : nous nous attendons à ce que la précision se rapproche progressivement de 1,0 (100 %) à mesure que le pas augmente.
Accuracy at step 0: 0.216
Accuracy at step 1: 0.098
Accuracy at step 2: 0.098
Accuracy at step 3: 0.098
...
Une hypothèse raisonnable est que ce problème est causé par une instabilité numérique, telle que NaN ou l'infini. Cependant, comment confirmer que c'est réellement le cas et comment trouver l'opération TensorFlow (op) responsable de la génération de l'instabilité numérique ? Pour répondre à ces questions, instrumentons le programme buggy avec Debugger V2.
Instrumenter le code TensorFlow avec Debugger V2
tf.debugging.experimental.enable_dump_debug_info() est le point d'entrée de l'API de Debugger V2. Il instrumente un programme TF2 avec une seule ligne de code. Par exemple, l'ajout de la ligne suivante au début du programme entraînera l'écriture des informations de débogage dans le répertoire des journaux (logdir) à l'adresse /tmp/tfdbg2_logdir. Les informations de débogage couvrent divers aspects du runtime TensorFlow. Dans TF2, il comprend l'historique complet de l'exécution rapide, la construction de graphiques effectuée par @tf.function , l'exécution des graphiques, les valeurs tensorielles générées par les événements d'exécution, ainsi que l'emplacement du code (traces de pile Python) de ces événements. . La richesse des informations de débogage permet aux utilisateurs de se concentrer sur des bogues obscurs.
tf.debugging.experimental.enable_dump_debug_info(
"/tmp/tfdbg2_logdir",
tensor_debug_mode="FULL_HEALTH",
circular_buffer_size=-1)
L'argument tensor_debug_mode contrôle les informations que Debugger V2 extrait de chaque tenseur impatient ou intégré au graphique. « FULL_HEALTH » est un mode qui capture les informations suivantes sur chaque tenseur de type flottant (par exemple, le type float32 couramment observé et le type bfloat16 , moins courant) :
- TypeD
- Rang
- Nombre total d'éléments
- Une répartition des éléments de type flottant dans les catégories suivantes : fini négatif (
-), zéro (0), fini positif (+), infini négatif (-∞), infini positif (+∞) etNaN.
Le mode « FULL_HEALTH » convient au débogage des bugs impliquant NaN et l'infini. Voir ci-dessous pour les autres tensor_debug_mode pris en charge.
L'argument circular_buffer_size contrôle le nombre d'événements tensoriels enregistrés dans le répertoire logdir. La valeur par défaut est 1000, ce qui fait que seuls les 1000 derniers tenseurs avant la fin du programme TF2 instrumenté sont enregistrés sur le disque. Ce comportement par défaut réduit la surcharge du débogueur en sacrifiant l'exhaustivité des données de débogage. Si l'exhaustivité est préférée, comme dans ce cas, nous pouvons désactiver le tampon circulaire en définissant l'argument sur une valeur négative (par exemple, -1 ici).
L'exemple debug_mnist_v2 appelle enable_dump_debug_info() en lui transmettant des indicateurs de ligne de commande. Pour exécuter à nouveau notre programme TF2 problématique avec cette instrumentation de débogage activée, procédez :
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2 \
--dump_dir /tmp/tfdbg2_logdir --dump_tensor_debug_mode FULL_HEALTH
Démarrage de l'interface graphique de Debugger V2 dans TensorBoard
L'exécution du programme avec l'instrumentation du débogueur crée un répertoire dans /tmp/tfdbg2_logdir. Nous pouvons démarrer TensorBoard et le pointer vers le répertoire avec :
tensorboard --logdir /tmp/tfdbg2_logdir
Dans le navigateur Web, accédez à la page TensorBoard à l'adresse http://localhost:6006. Le plugin « Debugger V2 » sera inactif par défaut, alors sélectionnez-le dans le menu « Plugins inactifs » en haut à droite. Une fois sélectionné, il devrait ressembler à ceci :
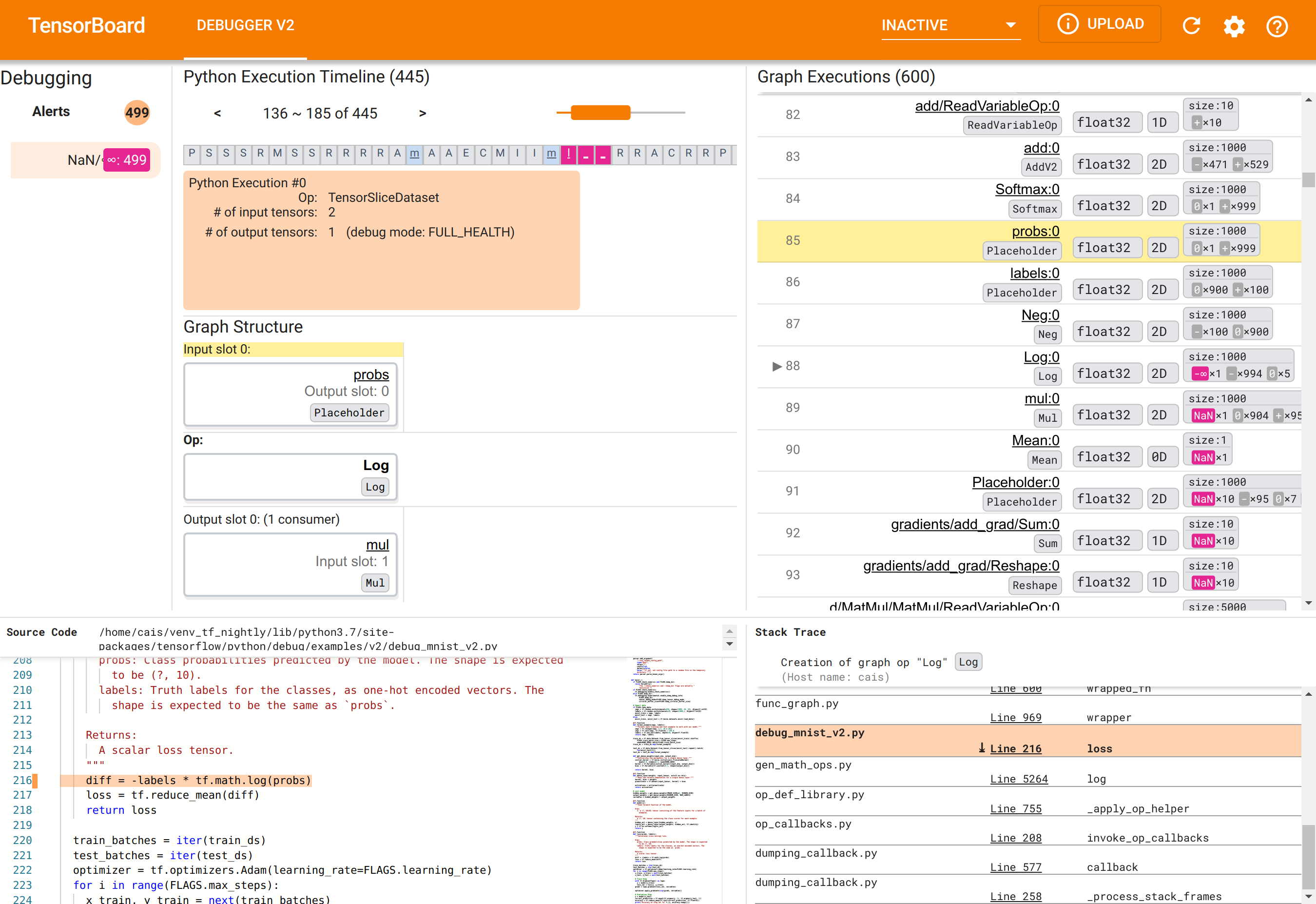
Utilisation de l'interface graphique de Debugger V2 pour trouver la cause première des NaN
L'interface graphique de Debugger V2 dans TensorBoard est organisée en six sections :
- Alertes : cette section en haut à gauche contient une liste des événements « d'alerte » détectés par le débogueur dans les données de débogage du programme TensorFlow instrumenté. Chaque alerte indique une certaine anomalie qui mérite notre attention. Dans notre cas, cette section met en évidence 499 événements NaN/∞ avec une couleur rose-rouge saillante. Cela confirme notre suspicion selon laquelle le modèle ne parvient pas à apprendre en raison de la présence de NaN et/ou d'infinis dans ses valeurs tensorielles internes. Nous examinerons ces alertes sous peu.
- Chronologie d'exécution Python : il s'agit de la moitié supérieure de la section supérieure centrale. Il présente l’historique complet de l’exécution enthousiaste des opérations et des graphiques. Chaque case de la chronologie est marquée par la lettre initiale du nom de l'opération ou du graphique (par exemple, « T » pour l'opération « TensorSliceDataset », « m » pour le « modèle »
tf.function). Nous pouvons parcourir cette chronologie en utilisant les boutons de navigation et la barre de défilement au-dessus de la chronologie. - Exécution de graphiques : située dans le coin supérieur droit de l'interface graphique, cette section sera au cœur de notre tâche de débogage. Il contient un historique de tous les tenseurs de type flottant calculés à l'intérieur des graphiques (c'est-à-dire compilés par
@tf-functions). - La structure du graphique (moitié inférieure de la section supérieure centrale), le code source (section inférieure gauche) et Stack Trace (section inférieure droite) sont initialement vides. Leur contenu sera renseigné lorsque nous interagissons avec l'interface graphique. Ces trois sections joueront également un rôle important dans notre tâche de débogage.
Après nous être orientés vers l'organisation de l'interface utilisateur, suivons les étapes suivantes pour comprendre pourquoi les NaN sont apparus. Tout d’abord, cliquez sur l’alerte NaN/∞ dans la section Alertes. Cela fait automatiquement défiler la liste des 600 tenseurs graphiques dans la section Exécution graphique et se concentre sur le #88, qui est un tenseur nommé Log:0 généré par une Log (logarithme naturel). Une couleur rose-rouge saillante met en évidence un élément -∞ parmi les 1000 éléments du tenseur 2D float32. Il s'agit du premier tenseur de l'historique d'exécution du programme TF2 qui contenait du NaN ou de l'infini : les tenseurs calculés avant lui ne contiennent pas de NaN ou ∞ ; de nombreux tenseurs (en fait, la plupart) calculés ultérieurement contiennent des NaN. Nous pouvons le confirmer en faisant défiler la liste d’exécution de graphiques de haut en bas. Cette observation donne une forte indication que l'opération Log est à l'origine de l'instabilité numérique de ce programme TF2.
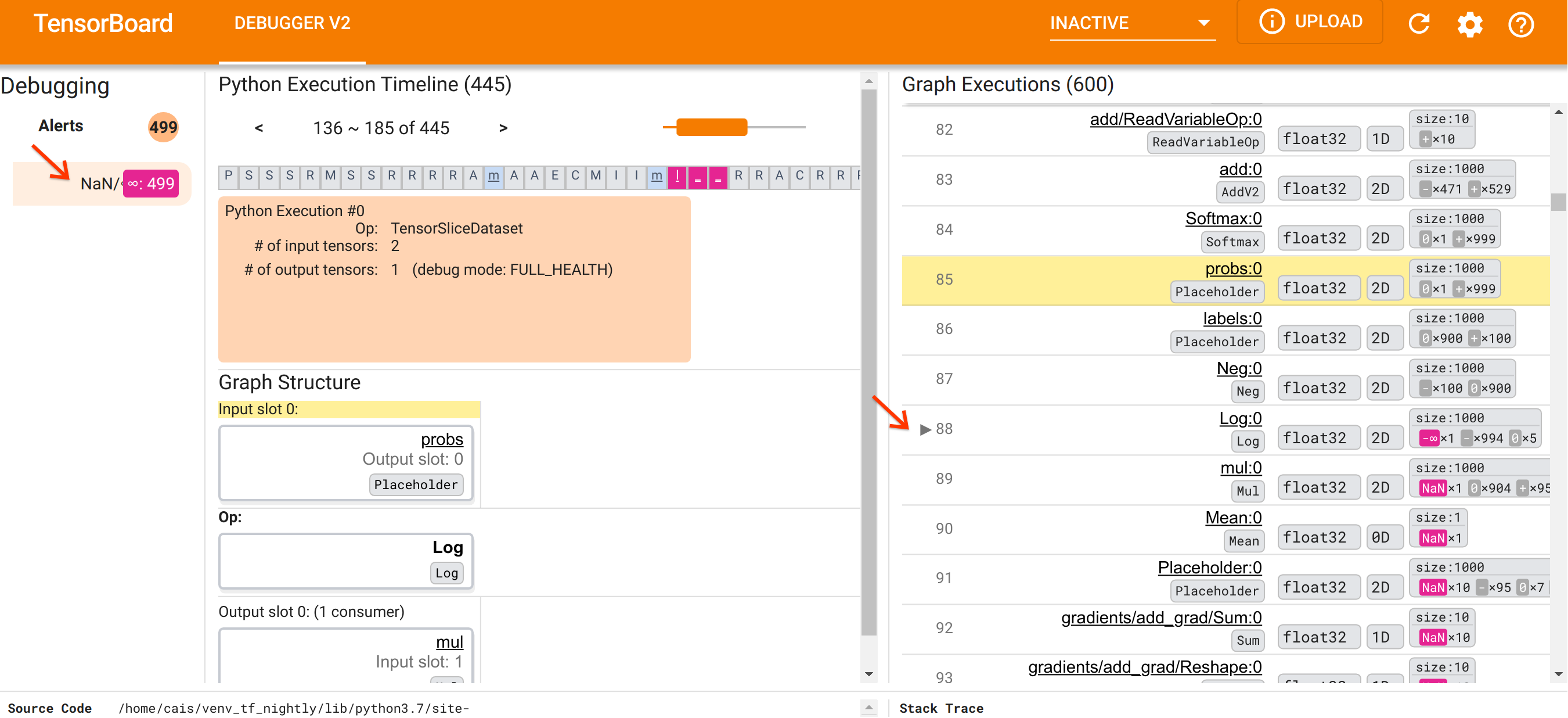
Pourquoi cette opération Log crache-t-elle un -∞ ? Répondre à cette question nécessite d’examiner la contribution à l’opération. Cliquer sur le nom du tenseur ( Log:0 ) fait apparaître une visualisation simple mais informative du voisinage de l'opération Log dans son graphique TensorFlow dans la section Structure du graphique. Notez le sens du flux d’informations de haut en bas. L'opération elle-même est affichée en gras au milieu. Immédiatement au-dessus, nous pouvons voir qu'une opération Placeholder fournit la seule et unique entrée à l'opération Log . Où est le tenseur généré par cet espace réservé aux probs dans la liste d'exécution du graphique ? En utilisant la couleur de fond jaune comme aide visuelle, nous pouvons voir que le tenseur probs:0 est trois lignes au-dessus du tenseur Log:0 , c'est-à-dire dans la ligne 85.
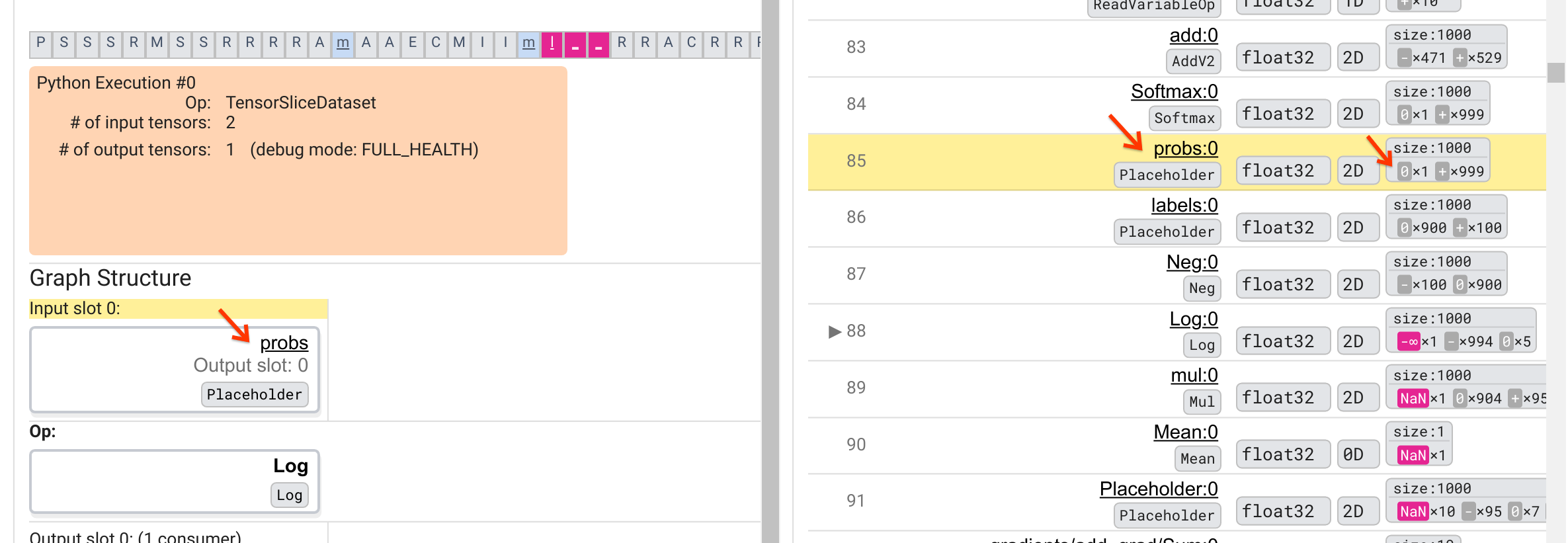
Un examen plus attentif de la répartition numérique du tenseur probs:0 dans la ligne 85 révèle pourquoi son consommateur Log:0 produit un -∞ : Parmi les 1000 éléments de probs:0 , un élément a une valeur de 0. Le -∞ est le résultat du calcul du logarithme népérien de 0 ! Si nous pouvons d'une manière ou d'une autre garantir que l'opération Log n'est exposée qu'à des entrées positives, nous serons en mesure d'empêcher le NaN/∞ de se produire. Ceci peut être réalisé en appliquant un découpage (par exemple, en utilisant tf.clip_by_value() ) sur le tenseur probs Placeholder.
Nous nous rapprochons de la résolution du bug, mais ce n’est pas encore tout à fait fait. Afin d'appliquer le correctif, nous devons savoir d'où proviennent l'opération Log et son entrée Placeholder dans le code source Python. Debugger V2 fournit une prise en charge de première classe pour tracer les opérations graphiques et les événements d'exécution jusqu'à leur source. Lorsque nous avons cliqué sur le tenseur Log:0 dans les exécutions graphiques, la section Stack Trace a été remplie avec la trace de pile originale de la création de l'opération Log . La trace de la pile est quelque peu volumineuse car elle inclut de nombreuses images du code interne de TensorFlow (par exemple, gen_math_ops.py et dumping_callback.py), que nous pouvons ignorer en toute sécurité pour la plupart des tâches de débogage. Le cadre qui nous intéresse est la ligne 216 de debug_mnist_v2.py (c'est-à-dire le fichier Python que nous essayons réellement de déboguer). Cliquer sur « Ligne 216 » fait apparaître une vue de la ligne de code correspondante dans la section Code source.
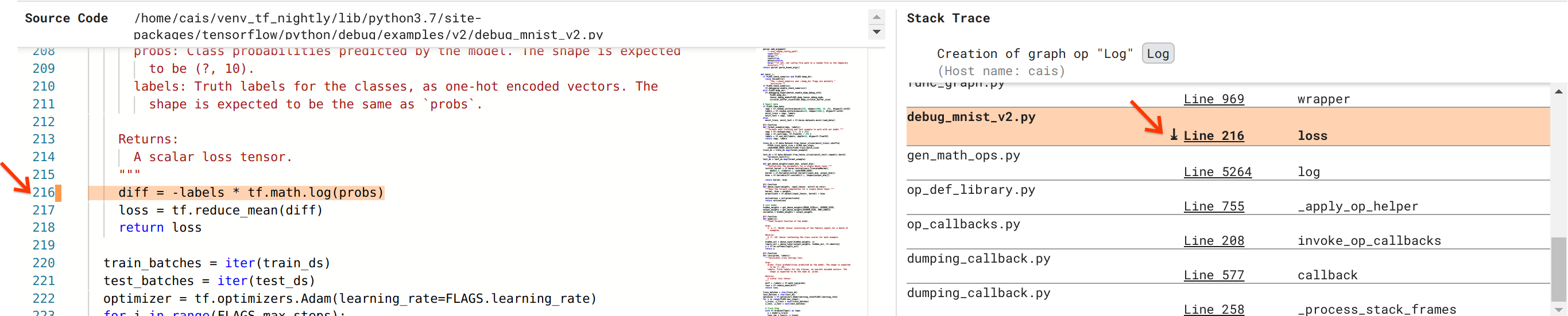
Cela nous amène enfin au code source qui a créé l'opération Log problématique à partir de son entrée probs . Il s'agit de notre fonction de perte d'entropie croisée catégorielle personnalisée décorée avec @tf.function et donc convertie en un graphique TensorFlow. Les probs op Placeholder correspondent au premier argument d’entrée de la fonction de perte. L'opération Log est créée avec l'appel API tf.math.log().
Le correctif de découpage de valeur pour ce bug ressemblera à ceci :
diff = -(labels *
tf.math.log(tf.clip_by_value(probs), 1e-6, 1.))
Cela résoudra l'instabilité numérique de ce programme TF2 et permettra au MLP de s'entraîner avec succès. Une autre approche possible pour corriger l'instabilité numérique consiste à utiliser tf.keras.losses.CategoricalCrossentropy .
Ceci conclut notre parcours depuis l'observation d'un bug du modèle TF2 jusqu'à la proposition d'un changement de code qui corrige le bug, aidé par l'outil Debugger V2, qui offre une visibilité complète sur l'historique d'exécution avide et graphique du programme TF2 instrumenté, y compris les résumés numériques. des valeurs de tenseurs et association entre les opérations, les tenseurs et leur code source d'origine.
Compatibilité matérielle du débogueur V2
Debugger V2 prend en charge le matériel de formation grand public, notamment le CPU et le GPU. La formation multi-GPU avec tf.distributed.MirroredStrategy est également prise en charge. La prise en charge du TPU en est encore à ses débuts et nécessite un appel
tf.config.set_soft_device_placement(True)
avant d'appeler enable_dump_debug_info() . Il peut également y avoir d'autres limitations sur les TPU. Si vous rencontrez des problèmes lors de l'utilisation de Debugger V2, veuillez signaler les bogues sur notre page de problèmes GitHub .
Compatibilité API du débogueur V2
Debugger V2 est implémenté à un niveau relativement bas de la pile logicielle de TensorFlow et est donc compatible avec tf.keras , tf.data et d'autres API construites au-dessus des niveaux inférieurs de TensorFlow. Debugger V2 est également rétrocompatible avec TF1, bien que la chronologie d'exécution Eager soit vide pour les répertoires de débogage générés par les programmes TF1.
Conseils d'utilisation des API
Une question fréquemment posée à propos de cette API de débogage est de savoir où dans le code TensorFlow il faut insérer l'appel à enable_dump_debug_info() . En règle générale, l'API doit être appelée le plus tôt possible dans votre programme TF2, de préférence après les lignes d'importation Python et avant le début de la construction et de l'exécution du graphique. Cela garantira une couverture complète de toutes les opérations et graphiques qui alimentent votre modèle et sa formation.
Les tensor_debug_modes actuellement pris en charge sont : NO_TENSOR , CURT_HEALTH , CONCISE_HEALTH , FULL_HEALTH et SHAPE . Ils varient en fonction de la quantité d'informations extraites de chaque tenseur et de la surcharge de performances du programme débogué. Veuillez vous référer à la section args de la documentation de enable_dump_debug_info() .
Surcharge de performances
L'API de débogage introduit une surcharge de performances pour le programme TensorFlow instrumenté. La surcharge varie en fonction de tensor_debug_mode , du type de matériel et de la nature du programme TensorFlow instrumenté. À titre de référence, sur un GPU, le mode NO_TENSOR ajoute une surcharge de 15 % lors de la formation d'un modèle Transformer sous une taille de lot de 64. Le pourcentage de surcharge pour les autres tensor_debug_modes est plus élevé : environ 50 % pour CURT_HEALTH , CONCISE_HEALTH , FULL_HEALTH et SHAPE modes. Sur les processeurs, la surcharge est légèrement inférieure. Sur les TPU, la surcharge est actuellement plus élevée.
Relation avec d'autres API de débogage TensorFlow
Notez que TensorFlow propose d'autres outils et API pour le débogage. Vous pouvez parcourir ces API sous l' espace de noms tf.debugging.* sur la page de documentation de l'API. Parmi ces API, la plus fréquemment utilisée est tf.print() . Quand faut-il utiliser Debugger V2 et quand faut-il utiliser tf.print() à la place ? tf.print() est pratique dans le cas où
- nous savons exactement quels tenseurs imprimer,
- nous savons où exactement dans le code source insérer ces instructions
tf.print(), - le nombre de ces tenseurs n'est pas trop grand.
Pour d'autres cas (par exemple, examen de nombreuses valeurs de tenseur, examen des valeurs de tenseur générées par le code interne de TensorFlow et recherche de l'origine de l'instabilité numérique comme nous l'avons montré ci-dessus), Debugger V2 fournit un moyen de débogage plus rapide. De plus, Debugger V2 fournit une approche unifiée pour inspecter les tenseurs impatients et graphiques. Il fournit en outre des informations sur la structure du graphique et les emplacements du code, qui dépassent les capacités de tf.print() .
Une autre API qui peut être utilisée pour déboguer les problèmes impliquant ∞ et NaN est tf.debugging.enable_check_numerics() . Contrairement à enable_dump_debug_info() , enable_check_numerics() n'enregistre pas les informations de débogage sur le disque. Au lieu de cela, il surveille simplement ∞ et NaN pendant l'exécution de TensorFlow et génère des erreurs avec l'emplacement du code d'origine dès qu'une opération génère de telles mauvaises valeurs numériques. Il a une surcharge de performances inférieure à celle de enable_dump_debug_info() , mais ne permet pas une trace complète de l'historique d'exécution du programme et n'est pas livré avec une interface utilisateur graphique comme Debugger V2.