
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Cuando la construcción de modelos de aprendizaje automático, es necesario elegir diferentes hiperparámetros , tales como la tasa de abandono en una capa o la tasa de aprendizaje. Estas decisiones afectan las métricas del modelo, como la precisión. Por lo tanto, un paso importante en el flujo de trabajo del aprendizaje automático es identificar los mejores hiperparámetros para su problema, lo que a menudo implica experimentación. Este proceso se conoce como "Optimización de hiperparámetros" o "Ajuste de hiperparámetros".
El panel de HParams en TensorBoard proporciona varias herramientas para ayudar con este proceso de identificar el mejor experimento o los conjuntos de hiperparámetros más prometedores.
Este tutorial se centrará en los siguientes pasos:
- Configuración del experimento y resumen de HParams
- Adapt TensorFlow se ejecuta para registrar hiperparámetros y métricas
- Inicie las ejecuciones y regístrelas todas en un directorio principal
- Visualice los resultados en el panel de HParams de TensorBoard
Comience instalando TF 2.0 y cargando la extensión para computadora portátil TensorBoard:
# Load the TensorBoard notebook extension
%load_ext tensorboard
# Clear any logs from previous runsrm -rf ./logs/
Importa TensorFlow y el complemento TensorBoard HParams:
import tensorflow as tf
from tensorboard.plugins.hparams import api as hp
Descargar el FashionMNIST conjunto de datos y reduce la escala:
fashion_mnist = tf.keras.datasets.fashion_mnist
(x_train, y_train),(x_test, y_test) = fashion_mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 8192/5148 [===============================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step
1. Configuración del experimento y resumen del experimento de HParams
Experimente con tres hiperparámetros en el modelo:
- Número de unidades en la primera capa densa
- Tasa de abandono en la capa de abandono
- Optimizador
Enumere los valores para probar y registre una configuración de experimento en TensorBoard. Este paso es opcional: puede proporcionar información de dominio para permitir un filtrado más preciso de hiperparámetros en la interfaz de usuario y puede especificar qué métricas deben mostrarse.
HP_NUM_UNITS = hp.HParam('num_units', hp.Discrete([16, 32]))
HP_DROPOUT = hp.HParam('dropout', hp.RealInterval(0.1, 0.2))
HP_OPTIMIZER = hp.HParam('optimizer', hp.Discrete(['adam', 'sgd']))
METRIC_ACCURACY = 'accuracy'
with tf.summary.create_file_writer('logs/hparam_tuning').as_default():
hp.hparams_config(
hparams=[HP_NUM_UNITS, HP_DROPOUT, HP_OPTIMIZER],
metrics=[hp.Metric(METRIC_ACCURACY, display_name='Accuracy')],
)
Si decide omitir este paso, se puede utilizar un literal de cadena donde quiera que de lo contrario usar un HParam valor: por ejemplo, hparams['dropout'] en lugar de hparams[HP_DROPOUT] .
2. Adapte las ejecuciones de TensorFlow para registrar hiperparámetros y métricas
El modelo será bastante simple: dos capas densas con una capa de caída entre ellas. El código de entrenamiento le resultará familiar, aunque los hiperparámetros ya no están codificados. En cambio, los hiperparámetros se proporcionan en una hparams diccionario y utilizan a lo largo de la función de formación:
def train_test_model(hparams):
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(hparams[HP_NUM_UNITS], activation=tf.nn.relu),
tf.keras.layers.Dropout(hparams[HP_DROPOUT]),
tf.keras.layers.Dense(10, activation=tf.nn.softmax),
])
model.compile(
optimizer=hparams[HP_OPTIMIZER],
loss='sparse_categorical_crossentropy',
metrics=['accuracy'],
)
model.fit(x_train, y_train, epochs=1) # Run with 1 epoch to speed things up for demo purposes
_, accuracy = model.evaluate(x_test, y_test)
return accuracy
Para cada ejecución, registre un resumen de hparams con los hiperparámetros y la precisión final:
def run(run_dir, hparams):
with tf.summary.create_file_writer(run_dir).as_default():
hp.hparams(hparams) # record the values used in this trial
accuracy = train_test_model(hparams)
tf.summary.scalar(METRIC_ACCURACY, accuracy, step=1)
Al entrenar modelos de Keras, puede usar devoluciones de llamada en lugar de escribirlas directamente:
model.fit(
...,
callbacks=[
tf.keras.callbacks.TensorBoard(logdir), # log metrics
hp.KerasCallback(logdir, hparams), # log hparams
],
)
3. Inicie las ejecuciones y regístrelas todas en un directorio principal
Ahora puede probar varios experimentos, entrenando cada uno con un conjunto diferente de hiperparámetros.
Para simplificar, use una búsqueda de cuadrícula: pruebe todas las combinaciones de los parámetros discretos y solo los límites inferior y superior del parámetro de valor real. Para escenarios más complejos, podría ser más efectivo elegir cada valor de hiperparámetro al azar (esto se denomina búsqueda aleatoria). Hay métodos más avanzados que se pueden utilizar.
Ejecute algunos experimentos, que tardarán unos minutos:
session_num = 0
for num_units in HP_NUM_UNITS.domain.values:
for dropout_rate in (HP_DROPOUT.domain.min_value, HP_DROPOUT.domain.max_value):
for optimizer in HP_OPTIMIZER.domain.values:
hparams = {
HP_NUM_UNITS: num_units,
HP_DROPOUT: dropout_rate,
HP_OPTIMIZER: optimizer,
}
run_name = "run-%d" % session_num
print('--- Starting trial: %s' % run_name)
print({h.name: hparams[h] for h in hparams})
run('logs/hparam_tuning/' + run_name, hparams)
session_num += 1
--- Starting trial: run-0
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 62us/sample - loss: 0.6872 - accuracy: 0.7564
10000/10000 [==============================] - 0s 35us/sample - loss: 0.4806 - accuracy: 0.8321
--- Starting trial: run-1
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9428 - accuracy: 0.6769
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6519 - accuracy: 0.7770
--- Starting trial: run-2
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 60us/sample - loss: 0.8158 - accuracy: 0.7078
10000/10000 [==============================] - 0s 36us/sample - loss: 0.5309 - accuracy: 0.8154
--- Starting trial: run-3
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 50us/sample - loss: 1.1465 - accuracy: 0.6019
10000/10000 [==============================] - 0s 36us/sample - loss: 0.7007 - accuracy: 0.7683
--- Starting trial: run-4
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 65us/sample - loss: 0.6178 - accuracy: 0.7849
10000/10000 [==============================] - 0s 38us/sample - loss: 0.4645 - accuracy: 0.8395
--- Starting trial: run-5
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 55us/sample - loss: 0.8989 - accuracy: 0.6896
10000/10000 [==============================] - 0s 37us/sample - loss: 0.6335 - accuracy: 0.7853
--- Starting trial: run-6
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 64us/sample - loss: 0.6404 - accuracy: 0.7782
10000/10000 [==============================] - 0s 37us/sample - loss: 0.4802 - accuracy: 0.8265
--- Starting trial: run-7
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9633 - accuracy: 0.6703
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6516 - accuracy: 0.7755
4. Visualice los resultados en el complemento HParams de TensorBoard
Ahora se puede abrir el panel de HParams. Inicie TensorBoard y haga clic en "HParams" en la parte superior.
%tensorboard --logdir logs/hparam_tuning
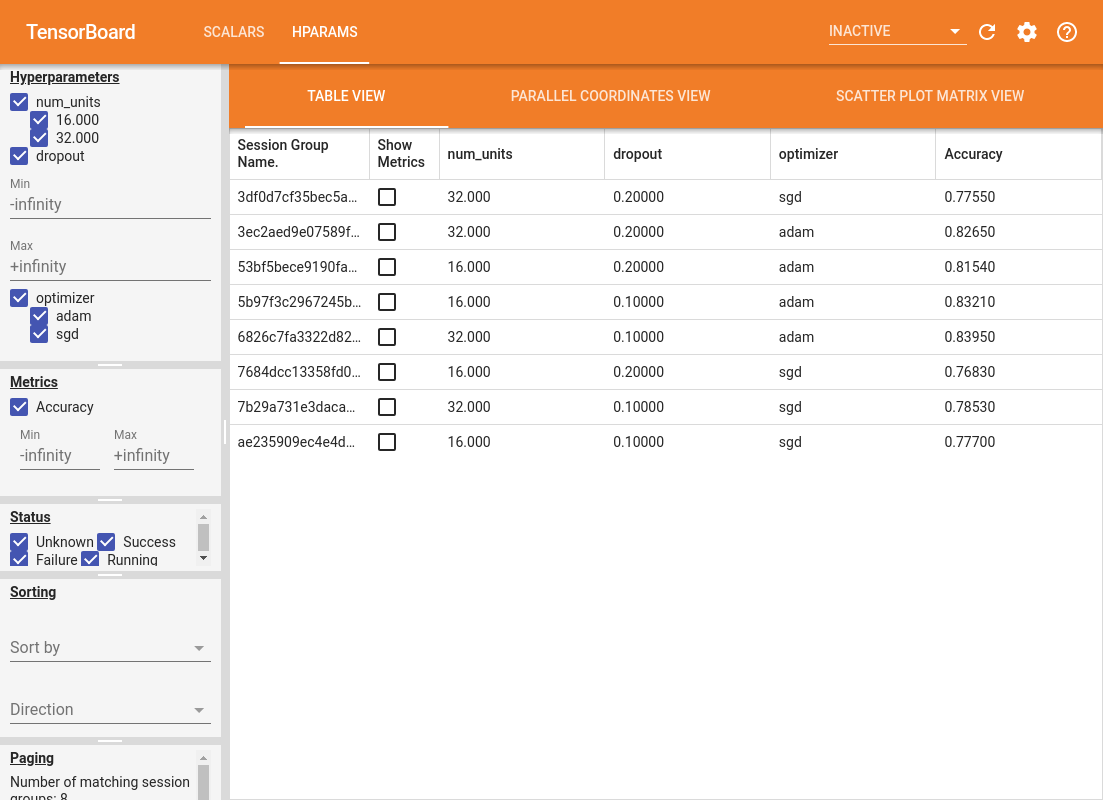
El panel izquierdo del panel proporciona capacidades de filtrado que están activas en todas las vistas en el panel de HParams:
- Filtra qué hiperparámetros / métricas se muestran en el panel
- Filtrar qué valores de hiperparámetros / métricas se muestran en el panel
- Filtrar por estado de ejecución (en ejecución, éxito, ...)
- Ordenar por hiperparámetro / métrica en la vista de tabla
- Número de grupos de sesiones para mostrar (útil para el rendimiento cuando hay muchos experimentos)
El panel de HParams tiene tres vistas diferentes, con diversa información útil:
- La vista de tabla enumera las carreras, sus hiperparámetros, y sus métricas.
- El Paralelo Coordenadas View muestra cada corrida como una línea que va a través de un eje para cada hyperparemeter y métrica. Haga clic y arrastre el mouse sobre cualquier eje para marcar una región que resaltará solo los recorridos que la atraviesan. Esto puede resultar útil para identificar qué grupos de hiperparámetros son más importantes. Los propios ejes se pueden reordenar arrastrándolos.
- Los gráficos de dispersión Ver muestra gráficos que comparan cada hiperparámetro / métrica con cada métrica. Esto puede ayudar a identificar correlaciones. Haga clic y arrastre para seleccionar una región en un gráfico específico y resalte esas sesiones en los otros gráficos.
Se puede hacer clic en una fila de tabla, una línea de coordenadas paralelas y un mercado de gráficos de dispersión para ver un gráfico de las métricas en función de los pasos de entrenamiento para esa sesión (aunque en este tutorial solo se usa un paso para cada ejecución).
Para explorar más las capacidades del panel de HParams, descargue un conjunto de registros pregenerados con más experimentos:
wget -q 'https://storage.googleapis.com/download.tensorflow.org/tensorboard/hparams_demo_logs.zip'unzip -q hparams_demo_logs.zip -d logs/hparam_demo
Vea estos registros en TensorBoard:
%tensorboard --logdir logs/hparam_demo
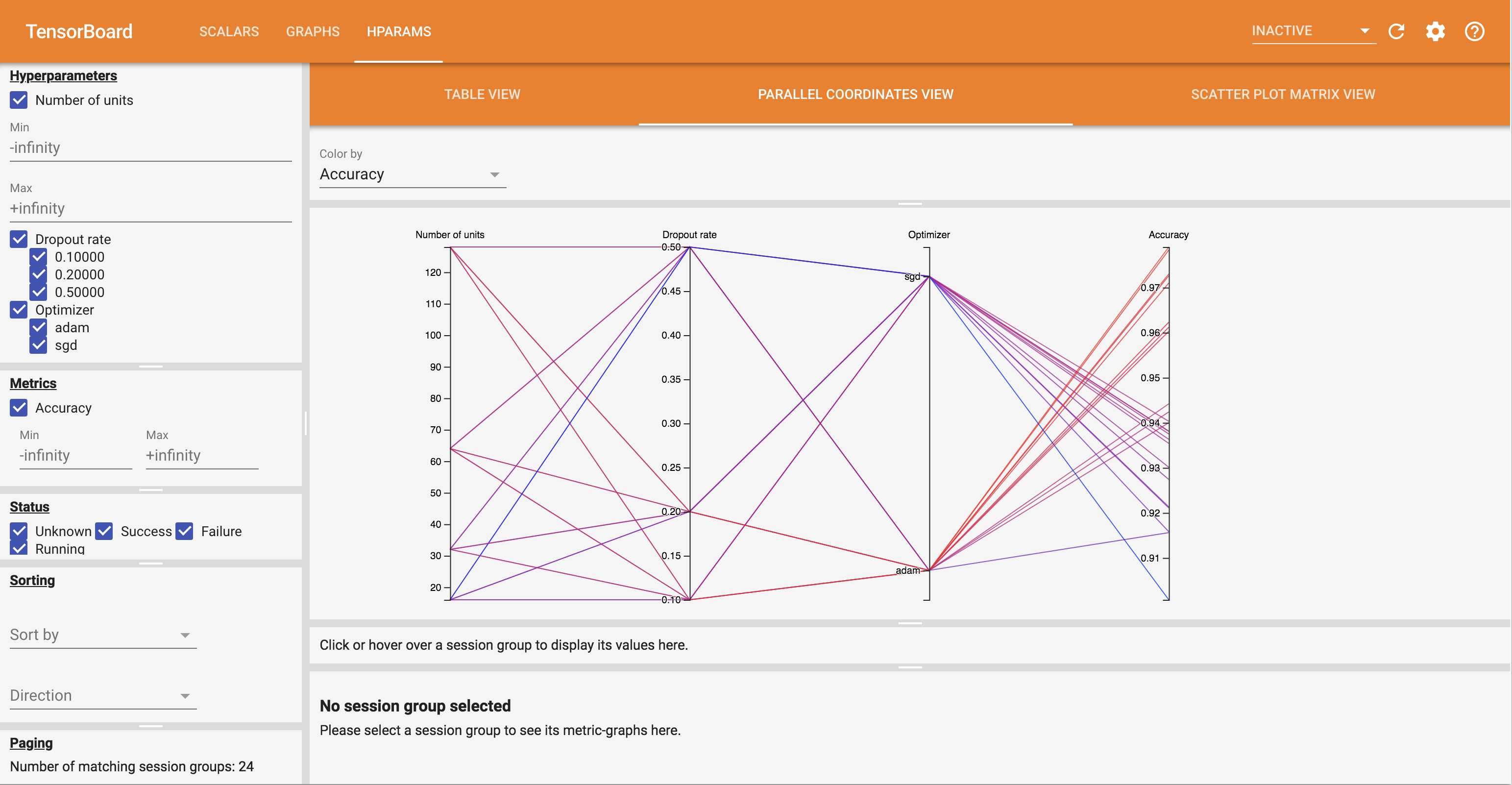
Puede probar las diferentes vistas en el panel de HParams.
Por ejemplo, yendo a la vista de coordenadas paralelas y haciendo clic y arrastrando en el eje de precisión, puede seleccionar las corridas con la mayor precisión. A medida que estas ejecuciones pasan por 'adam' en el eje del optimizador, puede concluir que 'adam' funcionó mejor que 'sgd' en estos experimentos.