
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Descripción general
Los algoritmos de aprendizaje automático suelen ser computacionalmente costosos. Por lo tanto, es vital cuantificar el rendimiento de su aplicación de aprendizaje automático para asegurarse de que está ejecutando la versión más optimizada de su modelo. Usa TensorFlow Profiler para perfilar la ejecución de tu código de TensorFlow.
Configuración
from datetime import datetime
from packaging import version
import os
El TensorFlow Profiler requiere las últimas versiones de TensorFlow y TensorBoard ( >=2.2 ).
pip install -U tensorboard_plugin_profile
import tensorflow as tf
print("TensorFlow version: ", tf.__version__)
TensorFlow version: 2.2.0-dev20200405
Confirma que TensorFlow pueda acceder a la GPU.
device_name = tf.test.gpu_device_name()
if not device_name:
raise SystemError('GPU device not found')
print('Found GPU at: {}'.format(device_name))
Found GPU at: /device:GPU:0
Entrena un modelo de clasificación de imágenes con devoluciones de llamada de TensorBoard
En este tutorial, que explora las capacidades de la TensorFlow Profiler capturando el perfil de rendimiento obtenida mediante la formación de un modelo de imágenes Clasificar en el conjunto de datos MNIST .
Usa los conjuntos de datos de TensorFlow para importar los datos de entrenamiento y dividirlos en conjuntos de prueba y entrenamiento.
import tensorflow_datasets as tfds
tfds.disable_progress_bar()
(ds_train, ds_test), ds_info = tfds.load(
'mnist',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
WARNING:absl:Dataset mnist is hosted on GCS. It will automatically be downloaded to your local data directory. If you'd instead prefer to read directly from our public GCS bucket (recommended if you're running on GCP), you can instead set data_dir=gs://tfds-data/datasets. Downloading and preparing dataset mnist/3.0.0 (download: 11.06 MiB, generated: Unknown size, total: 11.06 MiB) to /root/tensorflow_datasets/mnist/3.0.0... Dataset mnist downloaded and prepared to /root/tensorflow_datasets/mnist/3.0.0. Subsequent calls will reuse this data.
Procese previamente los datos de entrenamiento y prueba normalizando los valores de píxeles para que estén entre 0 y 1.
def normalize_img(image, label):
"""Normalizes images: `uint8` -> `float32`."""
return tf.cast(image, tf.float32) / 255., label
ds_train = ds_train.map(normalize_img)
ds_train = ds_train.batch(128)
ds_test = ds_test.map(normalize_img)
ds_test = ds_test.batch(128)
Cree el modelo de clasificación de imágenes usando Keras.
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28, 1)),
tf.keras.layers.Dense(128,activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(0.001),
metrics=['accuracy']
)
Cree una devolución de llamada de TensorBoard para capturar perfiles de rendimiento y llamarla mientras entrena el modelo.
# Create a TensorBoard callback
logs = "logs/" + datetime.now().strftime("%Y%m%d-%H%M%S")
tboard_callback = tf.keras.callbacks.TensorBoard(log_dir = logs,
histogram_freq = 1,
profile_batch = '500,520')
model.fit(ds_train,
epochs=2,
validation_data=ds_test,
callbacks = [tboard_callback])
Epoch 1/2 469/469 [==============================] - 11s 22ms/step - loss: 0.3684 - accuracy: 0.8981 - val_loss: 0.1971 - val_accuracy: 0.9436 Epoch 2/2 50/469 [==>...........................] - ETA: 9s - loss: 0.2014 - accuracy: 0.9439WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/summary_ops_v2.py:1271: stop (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01. Instructions for updating: use `tf.profiler.experimental.stop` instead. WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/summary_ops_v2.py:1271: stop (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01. Instructions for updating: use `tf.profiler.experimental.stop` instead. 469/469 [==============================] - 11s 24ms/step - loss: 0.1685 - accuracy: 0.9525 - val_loss: 0.1376 - val_accuracy: 0.9595 <tensorflow.python.keras.callbacks.History at 0x7f23919a6a58>
Usa TensorFlow Profiler para perfilar el rendimiento del entrenamiento del modelo
TensorFlow Profiler está integrado en TensorBoard. Cargue TensorBoard usando Colab Magic y ejecútelo. Ver los perfiles de rendimiento navegando a la pestaña Perfil.
# Load the TensorBoard notebook extension.
%load_ext tensorboard
El perfil de rendimiento de este modelo es similar al de la siguiente imagen.
# Launch TensorBoard and navigate to the Profile tab to view performance profile
%tensorboard --logdir=logs
<IPython.core.display.Javascript object>
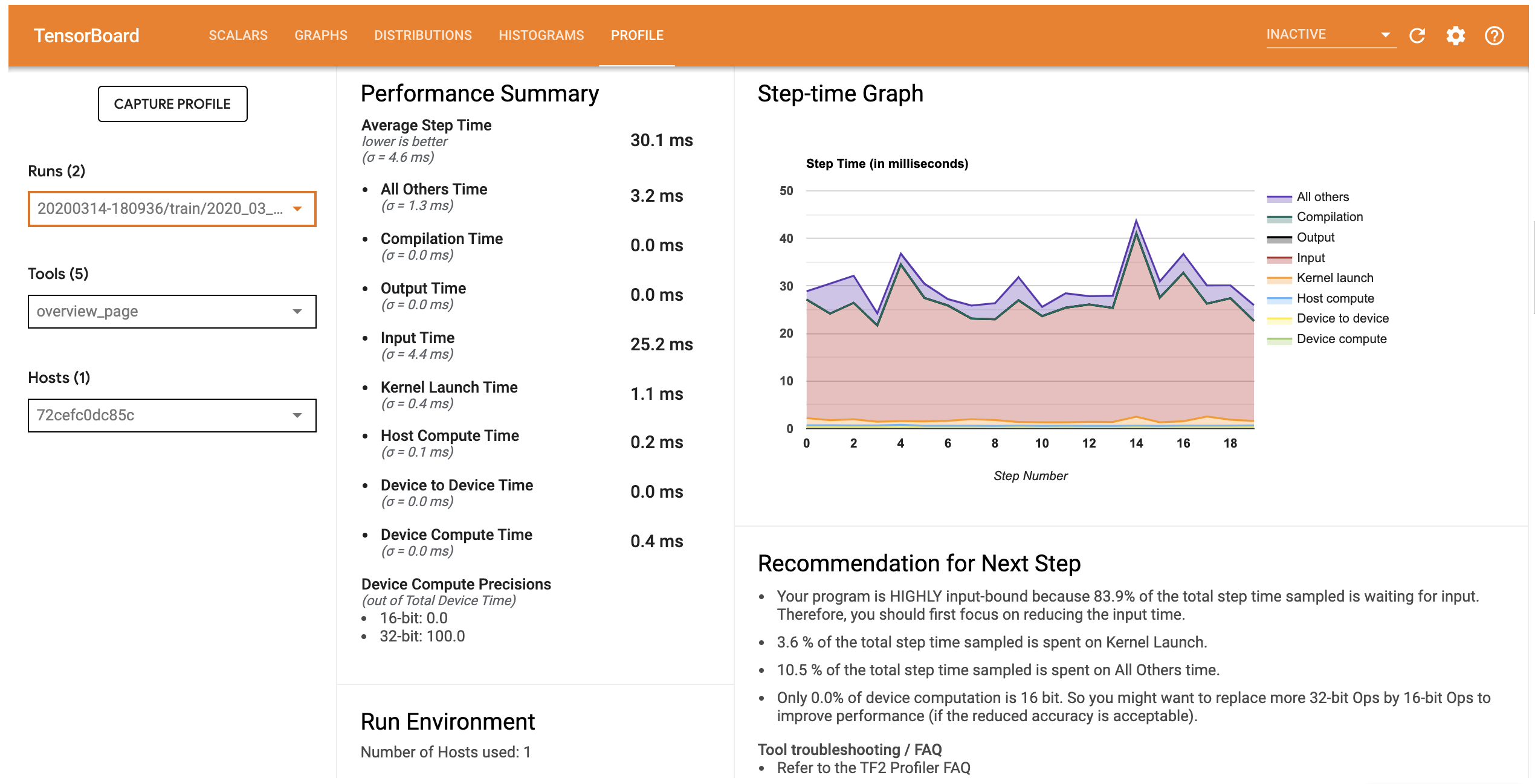
La ficha Perfil abre la página Descripción general, que muestra un resumen de alto nivel de su rendimiento del modelo. Si observa el gráfico de tiempo de paso a la derecha, puede ver que el modelo está muy ligado a la entrada (es decir, pasa mucho tiempo en la línea circular de entrada de datos). La página Descripción general también le brinda recomendaciones sobre los próximos pasos potenciales que puede seguir para optimizar el rendimiento de su modelo.
Para entender de dónde se produce el cuello de botella en la tubería de entrada, seleccione el visor de seguimiento de las herramientas desplegable de la izquierda. El Visor de seguimiento le muestra una línea de tiempo de los diferentes eventos que ocurrieron en la CPU y la GPU durante el período de creación de perfiles.
El Visor de seguimiento muestra varios grupos de eventos en el eje vertical. Cada grupo de eventos tiene múltiples pistas horizontales, llenas de eventos de seguimiento. La pista es una línea de tiempo de eventos para eventos ejecutados en un hilo o una secuencia de GPU. Los eventos individuales son los bloques rectangulares de colores en las pistas de la línea de tiempo. El tiempo se mueve de izquierda a derecha. Navegar por los eventos de seguimiento mediante el uso de las combinaciones de teclas W (zoom), S (alejar), A (desplazarse a la izquierda) y D (desplazamiento a la derecha).
Un solo rectángulo representa un evento de seguimiento. Seleccione el icono del cursor del ratón en la barra de herramientas flotante (o utilizar el atajo de teclado 1 ) y haga clic en el evento de seguimiento para analizarlo. Esto mostrará información sobre el evento, como su hora de inicio y duración.
Además de hacer clic, puede arrastrar el mouse para seleccionar un grupo de eventos de seguimiento. Esto le dará una lista de todos los eventos en esa área junto con un resumen del evento. Usar la M clave para medir el tiempo de duración de los eventos seleccionados.
Los eventos de seguimiento se recopilan de:
- CPU: CPU eventos se muestran en un grupo de eventos llamado
/host:CPU. Cada pista representa un hilo en la CPU. Los eventos de CPU incluyen eventos de canalización de entrada, eventos de programación de operaciones (op) de GPU, eventos de ejecución de operaciones de CPU, etc. - GPU: eventos GPU se muestran en grupos de eventos prefijo
/device:GPU:. Cada grupo de eventos representa una secuencia en la GPU.
Depurar los cuellos de botella del rendimiento
Utilice Trace Viewer para localizar los cuellos de botella de rendimiento en su canal de entrada. La siguiente imagen es una instantánea del perfil de rendimiento.
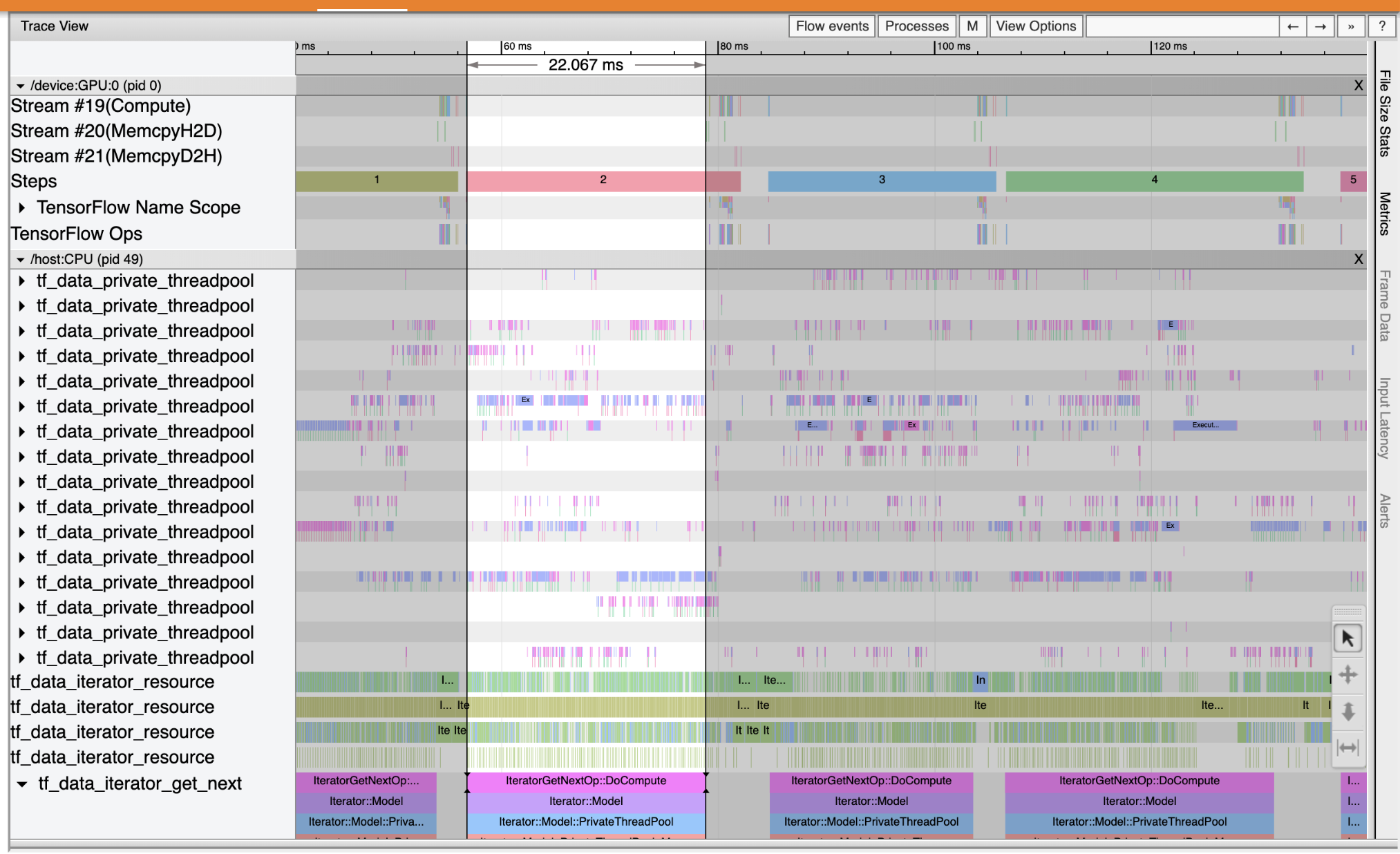
En cuanto a los seguimientos de sucesos, se puede ver que la GPU está inactivo mientras que el tf_data_iterator_get_next op se está ejecutando en la CPU. Esta operación es responsable de procesar los datos de entrada y enviarlos a la GPU para su entrenamiento. Como regla general, es una buena idea mantener siempre activo el dispositivo (GPU / TPU).
Usar la tf.data API para optimizar la tubería de entrada. En este caso, vamos a almacenar en caché el conjunto de datos de entrenamiento y precargar los datos para asegurarnos de que siempre haya datos disponibles para que la GPU los procese. Ver aquí para más detalles sobre el uso tf.data para optimizar sus tuberías de entrada.
(ds_train, ds_test), ds_info = tfds.load(
'mnist',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
ds_train = ds_train.map(normalize_img)
ds_train = ds_train.batch(128)
ds_train = ds_train.cache()
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = ds_test.map(normalize_img)
ds_test = ds_test.batch(128)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
Entrene el modelo nuevamente y capture el perfil de rendimiento reutilizando la devolución de llamada de antes.
model.fit(ds_train,
epochs=2,
validation_data=ds_test,
callbacks = [tboard_callback])
Epoch 1/2 469/469 [==============================] - 10s 22ms/step - loss: 0.1194 - accuracy: 0.9658 - val_loss: 0.1116 - val_accuracy: 0.9680 Epoch 2/2 469/469 [==============================] - 1s 3ms/step - loss: 0.0918 - accuracy: 0.9740 - val_loss: 0.0979 - val_accuracy: 0.9712 <tensorflow.python.keras.callbacks.History at 0x7f23908762b0>
Relanzamiento TensorBoard y abra la pestaña Perfil para observar el perfil de rendimiento de la tubería de entrada actualizada.
El perfil de rendimiento para el modelo con la canalización de entrada optimizada es similar a la imagen a continuación.
%tensorboard --logdir=logs
Reusing TensorBoard on port 6006 (pid 750), started 0:00:12 ago. (Use '!kill 750' to kill it.) <IPython.core.display.Javascript object>
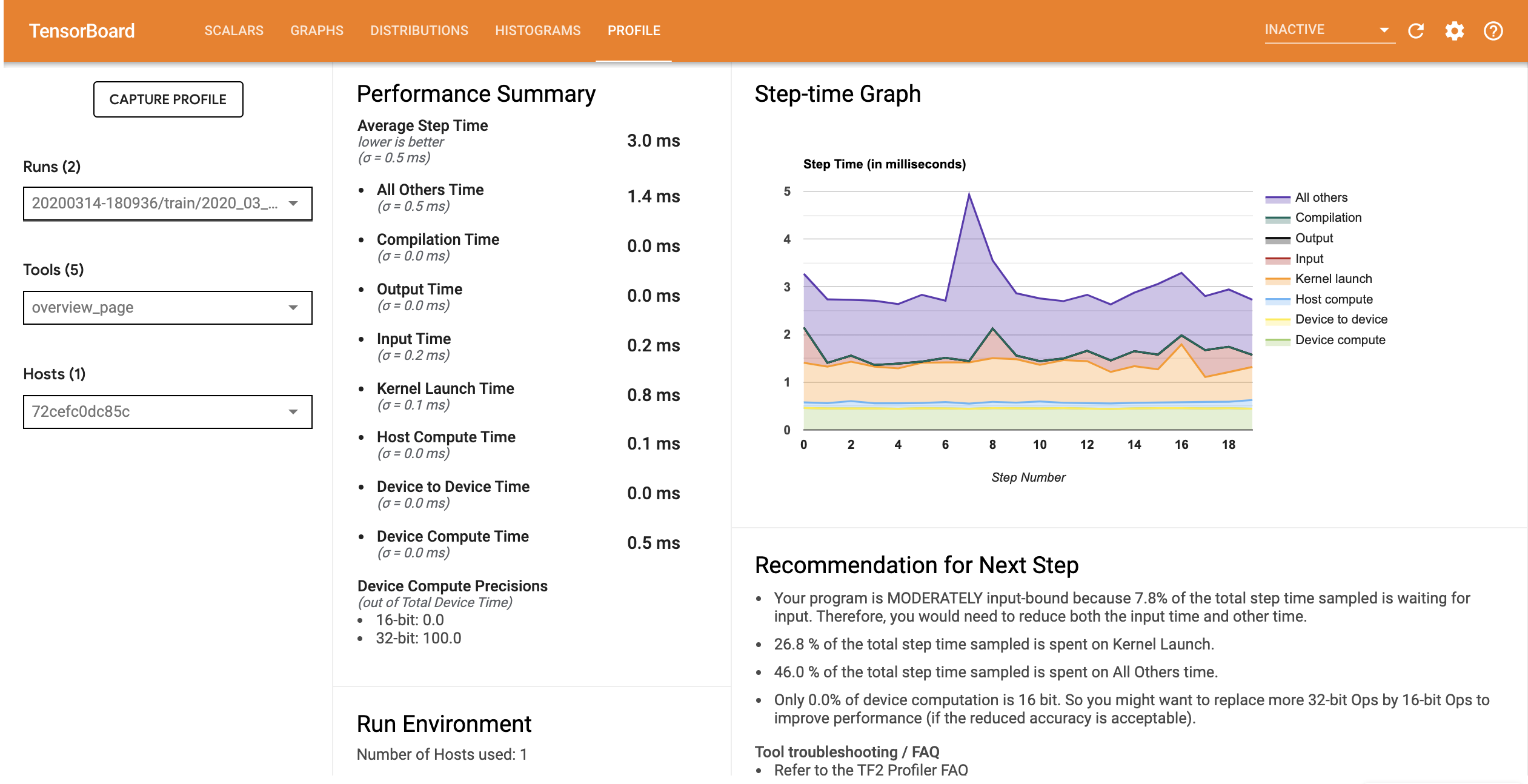
En la página Resumen, puede ver que el tiempo de paso promedio se ha reducido al igual que el tiempo de paso de entrada. El gráfico paso a paso también indica que el modelo ya no está muy ligado a los insumos. Abra el Visor de seguimiento para examinar los eventos de seguimiento con la canalización de entrada optimizada.
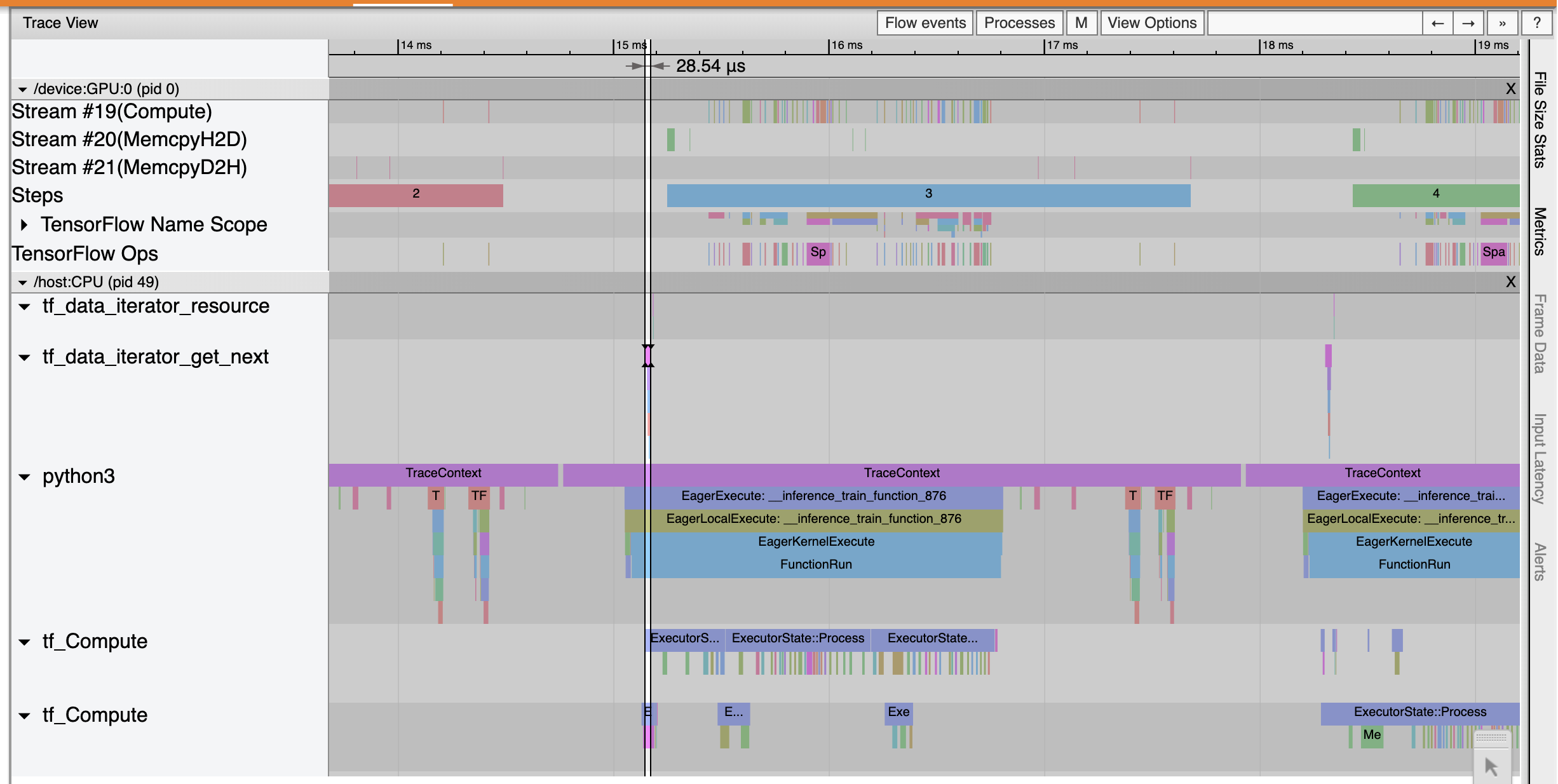
Los espectáculos Visor de seguimiento que el tf_data_iterator_get_next op ejecuta mucho más rápido. Por lo tanto, la GPU obtiene un flujo constante de datos para realizar el entrenamiento y logra una utilización mucho mejor a través del entrenamiento de modelos.
Resumen
Usa TensorFlow Profiler para perfilar y depurar el rendimiento del entrenamiento del modelo. Lea la guía de perfiles y ver el perfil de rendimiento en TF 2 habla de la Cumbre TensorFlow Dev 2020 para obtener más información sobre la TensorFlow Profiler.