| | |  Ver fonte no GitHub Ver fonte no GitHub | |
Visão geral
Usando a incorporação Projector TensorBoard, você pode representar graficamente embeddings dimensionais elevados. Isso pode ser útil para visualizar, examinar e compreender suas camadas de incorporação.

Neste tutorial, você aprenderá como visualizar esse tipo de camada treinada.
Configurar
Para este tutorial, usaremos o TensorBoard para visualizar uma camada de incorporação gerada para classificar dados de resenhas de filmes.
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
%load_ext tensorboard
import os
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorboard.plugins import projector
Dados IMDB
Usaremos um conjunto de dados de 25.000 resenhas de filmes IMDB, cada uma com um rótulo de sentimento (positivo / negativo). Cada revisão é pré-processada e codificada como uma sequência de índices de palavras (inteiros). Para simplificar, as palavras são indexadas pela frequência geral no conjunto de dados, por exemplo, o número inteiro "3" codifica a terceira palavra mais frequente que aparece em todas as revisões. Isso permite operações de filtragem rápidas, como: "considere apenas as 10.000 palavras mais comuns, mas elimine as 20 palavras mais comuns".
Como convenção, "0" não representa nenhuma palavra específica, mas, em vez disso, é usado para codificar qualquer palavra desconhecida. Posteriormente no tutorial, removeremos a linha para "0" na visualização.
(train_data, test_data), info = tfds.load(
"imdb_reviews/subwords8k",
split=(tfds.Split.TRAIN, tfds.Split.TEST),
with_info=True,
as_supervised=True,
)
encoder = info.features["text"].encoder
# Shuffle and pad the data.
train_batches = train_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
test_batches = test_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
train_batch, train_labels = next(iter(train_batches))
Camada de incorporação Keras
A camada Keras Embedding pode ser usado para treinar um mergulho para cada palavra em seu vocabulário. Cada palavra (ou subpalavra, neste caso) será associada a um vetor de 16 dimensões (ou incorporação) que será treinado pelo modelo.
Veja este tutorial para aprender mais sobre embeddings palavra.
# Create an embedding layer.
embedding_dim = 16
embedding = tf.keras.layers.Embedding(encoder.vocab_size, embedding_dim)
# Configure the embedding layer as part of a keras model.
model = tf.keras.Sequential(
[
embedding, # The embedding layer should be the first layer in a model.
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(1),
]
)
# Compile model.
model.compile(
optimizer="adam",
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"],
)
# Train model for one epoch.
history = model.fit(
train_batches, epochs=1, validation_data=test_batches, validation_steps=20
)
2500/2500 [==============================] - 13s 5ms/step - loss: 0.5330 - accuracy: 0.6769 - val_loss: 0.4043 - val_accuracy: 0.7800
Salvando dados para TensorBoard
O TensorBoard lê tensores e metadados dos registros de seus projetos de tensorflow. O caminho para o diretório de log é especificado com log_dir abaixo. Para este tutorial, vamos estar usando /logs/imdb-example/ .
Para carregar os dados no Tensorboard, precisamos salvar um checkpoint de treinamento nesse diretório, junto com os metadados que permitem a visualização de uma camada específica de interesse no modelo.
# Set up a logs directory, so Tensorboard knows where to look for files.
log_dir='/logs/imdb-example/'
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# Save Labels separately on a line-by-line manner.
with open(os.path.join(log_dir, 'metadata.tsv'), "w") as f:
for subwords in encoder.subwords:
f.write("{}\n".format(subwords))
# Fill in the rest of the labels with "unknown".
for unknown in range(1, encoder.vocab_size - len(encoder.subwords)):
f.write("unknown #{}\n".format(unknown))
# Save the weights we want to analyze as a variable. Note that the first
# value represents any unknown word, which is not in the metadata, here
# we will remove this value.
weights = tf.Variable(model.layers[0].get_weights()[0][1:])
# Create a checkpoint from embedding, the filename and key are the
# name of the tensor.
checkpoint = tf.train.Checkpoint(embedding=weights)
checkpoint.save(os.path.join(log_dir, "embedding.ckpt"))
# Set up config.
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
# The name of the tensor will be suffixed by `/.ATTRIBUTES/VARIABLE_VALUE`.
embedding.tensor_name = "embedding/.ATTRIBUTES/VARIABLE_VALUE"
embedding.metadata_path = 'metadata.tsv'
projector.visualize_embeddings(log_dir, config)
# Now run tensorboard against on log data we just saved.
%tensorboard --logdir /logs/imdb-example/

Análise
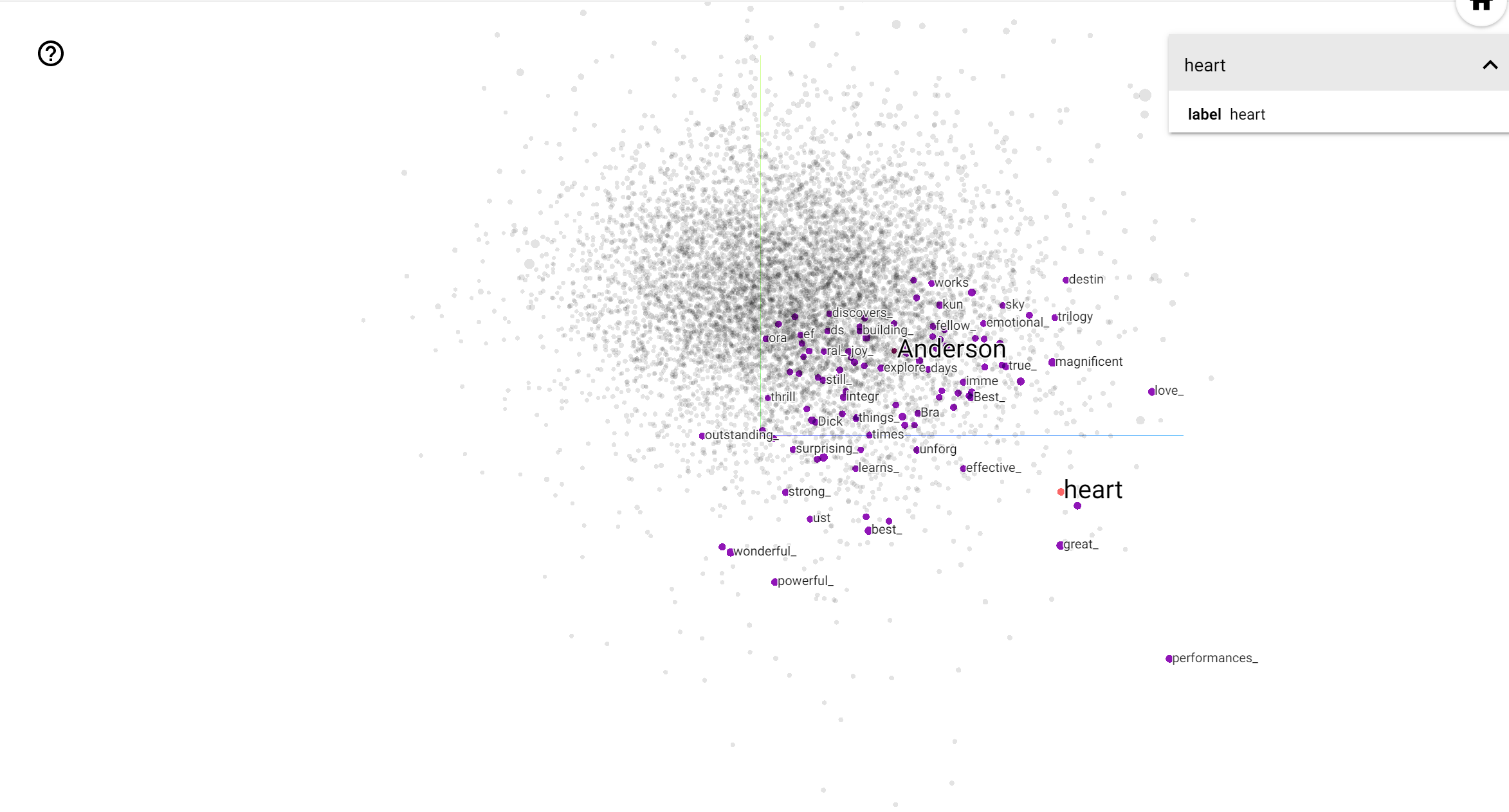
O TensorBoard Projector é uma ótima ferramenta para interpretar e visualizar a incorporação. O painel permite que os usuários pesquisem termos específicos e destaca palavras adjacentes umas às outras no espaço de incorporação (dimensional). A partir deste exemplo podemos ver que Wes Anderson e Alfred Hitchcock são termos bastante neutro, mas que eles são referenciados em diferentes contextos.
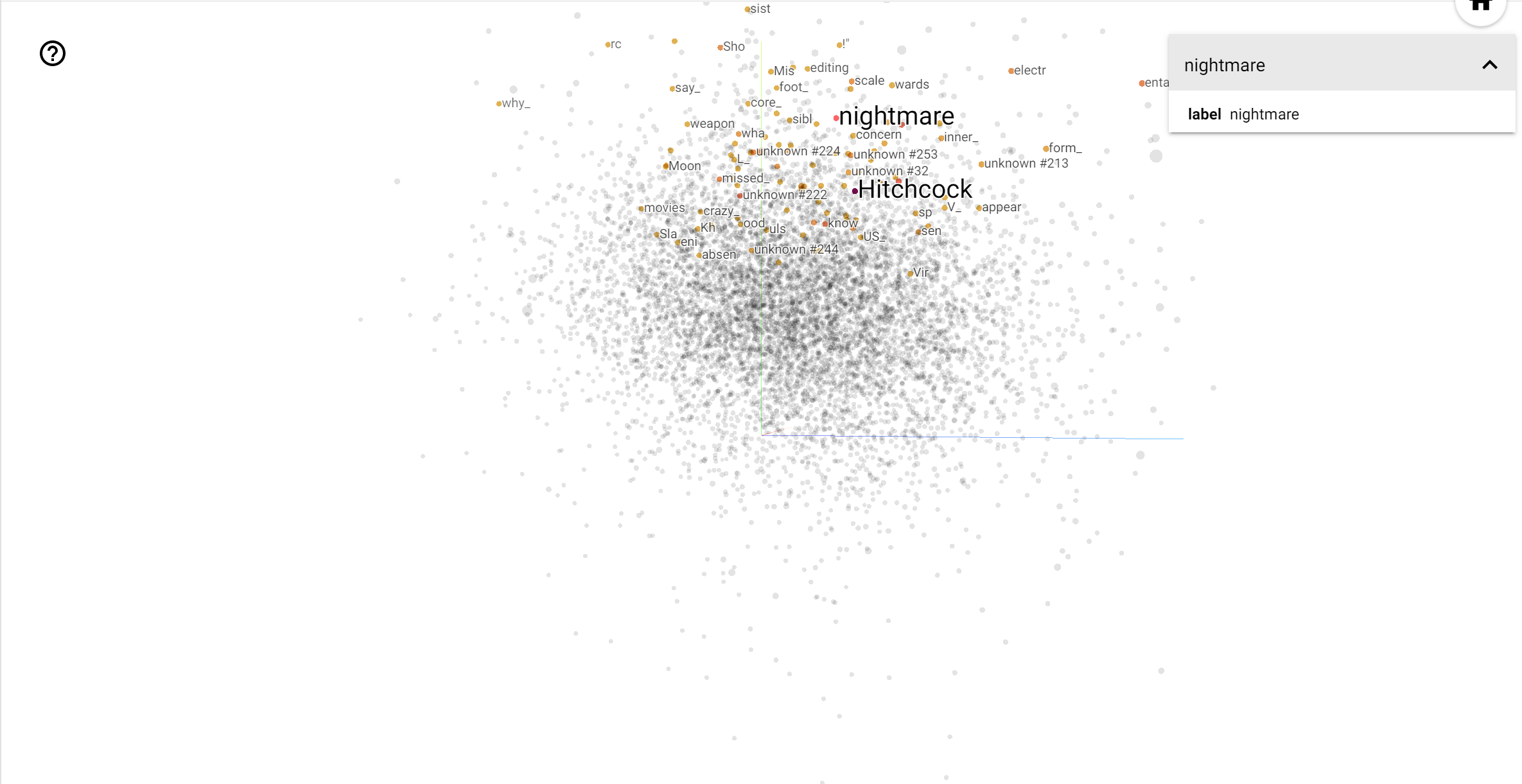
Neste espaço, Hitchcock está mais perto de palavras como nightmare , que é provavelmente devido ao fato de que ele é conhecido como o "mestre do suspense", enquanto Anderson está mais perto da palavra heart , o que é consistente com o seu estilo e implacavelmente detalhado emocionante .