
| | |  GitHub'da görüntüle GitHub'da görüntüle | | |
Bu öğretici, düz metin IMDB film incelemelerinden oluşan bir veri kümesinde duyarlılık analizi yapmak üzere BERT'ye ince ayar yapmak için eksiksiz bir kod içerir. Bir modeli eğitmeye ek olarak, metni uygun bir formatta nasıl önişleyeceğinizi öğreneceksiniz.
Bu defterde şunları yapacaksınız:
- IMDB veri kümesini yükleyin
- TensorFlow Hub'dan bir BERT modeli yükleyin
- BERT ile bir sınıflandırıcıyı birleştirerek kendi modelinizi oluşturun
- Kendi modelinizi eğitin, bunun bir parçası olarak BERT'ye ince ayar yapın
- Modelinizi kaydedin ve cümleleri sınıflandırmak için kullanın
Eğer IMDB veri kümesi ile çalışma konusunda yeniyseniz, lütfen bkz Temel metin sınıflandırma fazla ayrıntı için.
BERT hakkında
Bert ve diğer Trafo kodlayıcı mimariler NLP çeşitli görevlerin (doğal dil işleme) üzerine çılgınca başarılı olmuştur. Derin öğrenme modellerinde kullanım için uygun olan doğal dilin vektör-uzay temsillerini hesaplarlar. BERT model ailesi, giriş metninin her bir belirtecini, önce ve sonra tüm belirteçlerin tam bağlamında işlemek için Transformer kodlayıcı mimarisini kullanır, dolayısıyla adı: Transformer'lardan Çift Yönlü Kodlayıcı Temsilleri.
BERT modelleri genellikle büyük bir metin topluluğu üzerinde önceden eğitilir, ardından belirli görevler için ince ayar yapılır.
Kurmak
# A dependency of the preprocessing for BERT inputspip install -q -U tensorflow-text
Sen den AdamW optimize edici kullanacak tensorflow / modelleri .
pip install -q tf-models-official
import os
import shutil
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_text as text
from official.nlp import optimization # to create AdamW optimizer
import matplotlib.pyplot as plt
tf.get_logger().setLevel('ERROR')
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py:119: PkgResourcesDeprecationWarning: 0.18ubuntu0.18.04.1 is an invalid version and will not be supported in a future release PkgResourcesDeprecationWarning,
duygu analizi
Bu defter yorum metne dayalı pozitif veya negatif olarak sınıflandırmak film yorumları, bir duygu analizi modeli eğitir.
Sen kullanacağız Büyük Film İnceleme Dataset 50.000 film incelemeleri metnini içerir Internet Movie Database .
IMDB veri setini indirin
Veri kümesini indirip çıkaralım, ardından dizin yapısını keşfedelim.
url = 'https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz'
dataset = tf.keras.utils.get_file('aclImdb_v1.tar.gz', url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
train_dir = os.path.join(dataset_dir, 'train')
# remove unused folders to make it easier to load the data
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 7s 0us/step 84140032/84125825 [==============================] - 7s 0us/step
Sonra, kullanacağı text_dataset_from_directory etiketlenmiş yardımcı programını oluşturmak için tf.data.Dataset .
IMDB veri kümesi zaten eğitim ve test olarak bölünmüştür, ancak bir doğrulama kümesinden yoksundur. En kullanarak eğitim verilerinin 80:20 bölünmüş kullanarak bir doğrulama kümesi oluşturmak Let validation_split altında argüman.
AUTOTUNE = tf.data.AUTOTUNE
batch_size = 32
seed = 42
raw_train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='training',
seed=seed)
class_names = raw_train_ds.class_names
train_ds = raw_train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='validation',
seed=seed)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
test_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/test',
batch_size=batch_size)
test_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE)
Found 25000 files belonging to 2 classes. Using 20000 files for training. Found 25000 files belonging to 2 classes. Using 5000 files for validation. Found 25000 files belonging to 2 classes.
Birkaç incelemeye göz atalım.
for text_batch, label_batch in train_ds.take(1):
for i in range(3):
print(f'Review: {text_batch.numpy()[i]}')
label = label_batch.numpy()[i]
print(f'Label : {label} ({class_names[label]})')
Review: b'"Pandemonium" is a horror movie spoof that comes off more stupid than funny. Believe me when I tell you, I love comedies. Especially comedy spoofs. "Airplane", "The Naked Gun" trilogy, "Blazing Saddles", "High Anxiety", and "Spaceballs" are some of my favorite comedies that spoof a particular genre. "Pandemonium" is not up there with those films. Most of the scenes in this movie had me sitting there in stunned silence because the movie wasn\'t all that funny. There are a few laughs in the film, but when you watch a comedy, you expect to laugh a lot more than a few times and that\'s all this film has going for it. Geez, "Scream" had more laughs than this film and that was more of a horror film. How bizarre is that?<br /><br />*1/2 (out of four)' Label : 0 (neg) Review: b"David Mamet is a very interesting and a very un-equal director. His first movie 'House of Games' was the one I liked best, and it set a series of films with characters whose perspective of life changes as they get into complicated situations, and so does the perspective of the viewer.<br /><br />So is 'Homicide' which from the title tries to set the mind of the viewer to the usual crime drama. The principal characters are two cops, one Jewish and one Irish who deal with a racially charged area. The murder of an old Jewish shop owner who proves to be an ancient veteran of the Israeli Independence war triggers the Jewish identity in the mind and heart of the Jewish detective.<br /><br />This is were the flaws of the film are the more obvious. The process of awakening is theatrical and hard to believe, the group of Jewish militants is operatic, and the way the detective eventually walks to the final violent confrontation is pathetic. The end of the film itself is Mamet-like smart, but disappoints from a human emotional perspective.<br /><br />Joe Mantegna and William Macy give strong performances, but the flaws of the story are too evident to be easily compensated." Label : 0 (neg) Review: b'Great documentary about the lives of NY firefighters during the worst terrorist attack of all time.. That reason alone is why this should be a must see collectors item.. What shocked me was not only the attacks, but the"High Fat Diet" and physical appearance of some of these firefighters. I think a lot of Doctors would agree with me that,in the physical shape they were in, some of these firefighters would NOT of made it to the 79th floor carrying over 60 lbs of gear. Having said that i now have a greater respect for firefighters and i realize becoming a firefighter is a life altering job. The French have a history of making great documentary\'s and that is what this is, a Great Documentary.....' Label : 1 (pos) 2021-12-01 12:17:32.795514: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
TensorFlow Hub'dan model yükleme
Burada TensorFlow Hub'dan hangi BERT modelini yükleyeceğinizi seçebilir ve ince ayar yapabilirsiniz. Birden fazla BERT modeli mevcuttur.
- Bert-Baz , kılıfsız ve yedi fazla model orijinal Bert yazarlar tarafından yayımlanan eğitilmiş ağırlıklarla.
- Küçük Yolcu Yatak hız, boyut ve kalite arasında seçim yapmak keşfetmenize olanak tanır aynı genel mimarisini ancak daha az ve / veya daha küçük Trafo blokları var.
- ALBERT : katmanları arasında parametreleri paylaşarak modeli boyutunu (ancak hesaplama süresi) azaltır "Bir Lite bert" dört farklı boyutları.
- Bert Uzmanlar : sekiz modeller tüm bu Bert-baz mimariye sahip ancak hedef görev ile daha yakından uyum sağlamak, farklı antrenman öncesi etki alanı arasında bir seçenek sunuyoruz.
- Electra (üç farklı boyutta) bert ile aynı mimariye sahiptir, ancak bir dizi çekim bir ayırım düzeni olarak önceden eğitilmiş olur andıran bir Üretken olarak rakip Ağı (GAN).
- Konuşan-Başlıkları Dikkat ve geçitli gelu [ile Bert tabanı , geniş ] Transformatör mimarisinin çekirdek iki iyileştirmeler bulunur.
TensorFlow Hub'daki model dokümantasyonu daha fazla ayrıntıya ve araştırma literatürüne referanslara sahiptir. Yukarıdaki bağlantıları izleyin veya tıklayın tfhub.dev sonraki hücre yürütme sonrasında baskılı URL'ye.
Öneri, ince ayar yapmak için daha hızlı olduklarından Küçük BERT (daha az parametreli) ile başlamaktır. Küçük bir modelden hoşlanıyorsanız ancak daha yüksek doğrulukta bir model istiyorsanız, ALBERT bir sonraki seçeneğiniz olabilir. Daha da iyi doğruluk istiyorsanız, klasik BERT boyutlarından birini veya Electra, Talking Heads veya BERT Expert gibi son iyileştirmelerini seçin.
Kenara aşağıda mevcut modellerden vardır birden fazla sürümü daha büyüktür ve daha da iyi doğruluğunu verebilmesidir modellerin, ancak ince ayar tek GPU üzerinde olamayacak kadar büyük. Sen üzerinde yapmak mümkün olacak bir TPU CoLab Bert kullanarak çözün YAPIŞTIRICI görevleri .
Aşağıdaki kodda, bu modellerden herhangi birini denemek için tfhub.dev URL'sini değiştirmenin yeterli olduğunu göreceksiniz, çünkü aralarındaki tüm farklar TF Hub'dan SavedModels'de özetlenmiştir.
İnce ayar yapmak için bir BERT modeli seçin
bert_model_name = 'small_bert/bert_en_uncased_L-4_H-512_A-8'
map_name_to_handle = {
'bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/3',
'bert_en_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_cased_L-12_H-768_A-12/3',
'bert_multi_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_multi_cased_L-12_H-768_A-12/3',
'small_bert/bert_en_uncased_L-2_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-128_A-2/1',
'small_bert/bert_en_uncased_L-2_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-256_A-4/1',
'small_bert/bert_en_uncased_L-2_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-512_A-8/1',
'small_bert/bert_en_uncased_L-2_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-768_A-12/1',
'small_bert/bert_en_uncased_L-4_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-128_A-2/1',
'small_bert/bert_en_uncased_L-4_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-256_A-4/1',
'small_bert/bert_en_uncased_L-4_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1',
'small_bert/bert_en_uncased_L-4_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-768_A-12/1',
'small_bert/bert_en_uncased_L-6_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-128_A-2/1',
'small_bert/bert_en_uncased_L-6_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-256_A-4/1',
'small_bert/bert_en_uncased_L-6_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-512_A-8/1',
'small_bert/bert_en_uncased_L-6_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-768_A-12/1',
'small_bert/bert_en_uncased_L-8_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-128_A-2/1',
'small_bert/bert_en_uncased_L-8_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-256_A-4/1',
'small_bert/bert_en_uncased_L-8_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-512_A-8/1',
'small_bert/bert_en_uncased_L-8_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-768_A-12/1',
'small_bert/bert_en_uncased_L-10_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-128_A-2/1',
'small_bert/bert_en_uncased_L-10_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-256_A-4/1',
'small_bert/bert_en_uncased_L-10_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-512_A-8/1',
'small_bert/bert_en_uncased_L-10_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-768_A-12/1',
'small_bert/bert_en_uncased_L-12_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-128_A-2/1',
'small_bert/bert_en_uncased_L-12_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-256_A-4/1',
'small_bert/bert_en_uncased_L-12_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-512_A-8/1',
'small_bert/bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-768_A-12/1',
'albert_en_base':
'https://tfhub.dev/tensorflow/albert_en_base/2',
'electra_small':
'https://tfhub.dev/google/electra_small/2',
'electra_base':
'https://tfhub.dev/google/electra_base/2',
'experts_pubmed':
'https://tfhub.dev/google/experts/bert/pubmed/2',
'experts_wiki_books':
'https://tfhub.dev/google/experts/bert/wiki_books/2',
'talking-heads_base':
'https://tfhub.dev/tensorflow/talkheads_ggelu_bert_en_base/1',
}
map_model_to_preprocess = {
'bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'bert_en_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_cased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'bert_multi_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_multi_cased_preprocess/3',
'albert_en_base':
'https://tfhub.dev/tensorflow/albert_en_preprocess/3',
'electra_small':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'electra_base':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'experts_pubmed':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'experts_wiki_books':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'talking-heads_base':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
}
tfhub_handle_encoder = map_name_to_handle[bert_model_name]
tfhub_handle_preprocess = map_model_to_preprocess[bert_model_name]
print(f'BERT model selected : {tfhub_handle_encoder}')
print(f'Preprocess model auto-selected: {tfhub_handle_preprocess}')
BERT model selected : https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1 Preprocess model auto-selected: https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3
ön işleme modeli
Metin girişlerinin, BERT'ye girilmeden önce sayısal belirteç kimliklerine dönüştürülmesi ve birkaç Tensörde düzenlenmesi gerekir. TensorFlow Hub, yukarıda tartışılan BERT modellerinin her biri için, bu dönüşümü TF.text kitaplığındaki TF işlemlerini kullanarak uygulayan eşleşen bir ön işleme modeli sağlar. Metni önceden işlemek için TensorFlow modelinizin dışında saf Python kodu çalıştırmanız gerekmez.
Ön işleme modeli, yukarıda basılı URL'de okuyabileceğiniz BERT modelinin belgelerinde referans verilen model olmalıdır. Yukarıdaki açılır menüden BERT modelleri için ön işleme modeli otomatik olarak seçilir.
bert_preprocess_model = hub.KerasLayer(tfhub_handle_preprocess)
Bir metin üzerinde ön işleme modelini deneyelim ve çıktıyı görelim:
text_test = ['this is such an amazing movie!']
text_preprocessed = bert_preprocess_model(text_test)
print(f'Keys : {list(text_preprocessed.keys())}')
print(f'Shape : {text_preprocessed["input_word_ids"].shape}')
print(f'Word Ids : {text_preprocessed["input_word_ids"][0, :12]}')
print(f'Input Mask : {text_preprocessed["input_mask"][0, :12]}')
print(f'Type Ids : {text_preprocessed["input_type_ids"][0, :12]}')
Keys : ['input_word_ids', 'input_mask', 'input_type_ids'] Shape : (1, 128) Word Ids : [ 101 2023 2003 2107 2019 6429 3185 999 102 0 0 0] Input Mask : [1 1 1 1 1 1 1 1 1 0 0 0] Type Ids : [0 0 0 0 0 0 0 0 0 0 0 0]
Gördüğünüz gibi, şimdi bir Bert modeli (kullanacağı konusunda ön işleme 3 çıkışları vardır input_words_id , input_mask ve input_type_ids ).
Diğer bazı önemli noktalar:
- Girdi 128 jetona kesilir. Jeton sayısını özelleştirilebilir ve daha fazla ayrıntı görebilirsiniz bir TPU CoLab Bert kullanarak çözün YAPIŞTIRICI görevleri .
-
input_type_idsbu, tek bir cümle girişi için yalnızca bir değer (0) bulunur. Çoklu cümle girişi için, her giriş için bir numara olacaktır.
Bu metin önişlemcisi bir TensorFlow modeli olduğundan, modelinize doğrudan dahil edilebilir.
BERT modelini kullanma
BERT'yi kendi modelinize koymadan önce çıktılarına bir göz atalım. TF Hub'dan yükleyecek ve döndürülen değerleri göreceksiniz.
bert_model = hub.KerasLayer(tfhub_handle_encoder)
bert_results = bert_model(text_preprocessed)
print(f'Loaded BERT: {tfhub_handle_encoder}')
print(f'Pooled Outputs Shape:{bert_results["pooled_output"].shape}')
print(f'Pooled Outputs Values:{bert_results["pooled_output"][0, :12]}')
print(f'Sequence Outputs Shape:{bert_results["sequence_output"].shape}')
print(f'Sequence Outputs Values:{bert_results["sequence_output"][0, :12]}')
Loaded BERT: https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1 Pooled Outputs Shape:(1, 512) Pooled Outputs Values:[ 0.76262873 0.99280983 -0.1861186 0.36673835 0.15233682 0.65504444 0.9681154 -0.9486272 0.00216158 -0.9877732 0.0684272 -0.9763061 ] Sequence Outputs Shape:(1, 128, 512) Sequence Outputs Values:[[-0.28946388 0.3432126 0.33231565 ... 0.21300787 0.7102078 -0.05771166] [-0.28742015 0.31981024 -0.2301858 ... 0.58455074 -0.21329722 0.7269209 ] [-0.66157013 0.6887685 -0.87432927 ... 0.10877253 -0.26173282 0.47855264] ... [-0.2256118 -0.28925604 -0.07064401 ... 0.4756601 0.8327715 0.40025353] [-0.29824278 -0.27473143 -0.05450511 ... 0.48849759 1.0955356 0.18163344] [-0.44378197 0.00930723 0.07223766 ... 0.1729009 1.1833246 0.07897988]]
Bert modelleri 3 önemli tuşlarıyla bir harita döndürür: pooled_output , sequence_output , encoder_outputs :
-
pooled_outputbir bütün olarak her giriş dizisini göstermektedir. Şekil[batch_size, H]. Bunu, tüm film incelemesi için bir yerleştirme olarak düşünebilirsiniz. -
sequence_outputbağlamında belirteci her giriş temsil eder. Şekil[batch_size, seq_length, H]. Bunu, film incelemesindeki her belirteç için bağlamsal bir yerleştirme olarak düşünebilirsiniz. -
encoder_outputsara aktivasyonu,LTransformatör blokları.outputs["encoder_outputs"][i]şekilli bir tensör olan[batch_size, seq_length, 1024]i-inci Transformatör bloğun çıkışları ile,0 <= i < L. Listenin son değer eşittirsequence_output.
İnce ayar için kullanmak için gidiyoruz pooled_output dizisi.
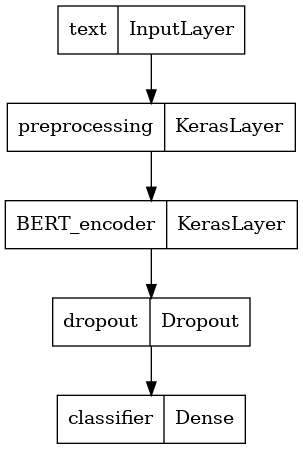
Modelinizi tanımlayın
Ön işleme modeli, seçilen BERT modeli, bir Yoğun ve bir Bırakma katmanı ile çok basit ince ayarlı bir model oluşturacaksınız.
def build_classifier_model():
text_input = tf.keras.layers.Input(shape=(), dtype=tf.string, name='text')
preprocessing_layer = hub.KerasLayer(tfhub_handle_preprocess, name='preprocessing')
encoder_inputs = preprocessing_layer(text_input)
encoder = hub.KerasLayer(tfhub_handle_encoder, trainable=True, name='BERT_encoder')
outputs = encoder(encoder_inputs)
net = outputs['pooled_output']
net = tf.keras.layers.Dropout(0.1)(net)
net = tf.keras.layers.Dense(1, activation=None, name='classifier')(net)
return tf.keras.Model(text_input, net)
Modelin ön işleme modelinin çıktısı ile çalıştığını kontrol edelim.
classifier_model = build_classifier_model()
bert_raw_result = classifier_model(tf.constant(text_test))
print(tf.sigmoid(bert_raw_result))
tf.Tensor([[0.6749899]], shape=(1, 1), dtype=float32)
Çıktı elbette anlamsız çünkü model henüz eğitilmedi.
Şimdi modelin yapısına bir göz atalım.
tf.keras.utils.plot_model(classifier_model)
Model eğitimi
Artık bir modeli eğitmek için ön işleme modülü, BERT kodlayıcı, veri ve sınıflandırıcı dahil tüm parçalara sahipsiniz.
kayıp fonksiyonu
Bu bir ikili sınıflandırma problemidir ve model bir olasılık (tek ünite katmanı) çıkışı olduğundan, kullanacağız losses.BinaryCrossentropy kaybı fonksiyonu.
loss = tf.keras.losses.BinaryCrossentropy(from_logits=True)
metrics = tf.metrics.BinaryAccuracy()
Optimize Edici
İnce ayar için, BERT'nin ilk olarak eğitildiği aynı optimize ediciyi kullanalım: "Uyarlanabilir Anlar" (Adam). Bu iyileştirici tahmin kaybını en aza indirir ve olarak da bilinir ağırlık çürüme (değil kullanarak anları) tarafından düzene koymayı yapar AdamW .
Öğrenme oranı için ( init_lr adımları (eğitim ilk% 10 üzerinde bir lineer ısıtma fazında ile başlayan bir kavramsal ilk öğrenme hızının lineer zayıflama: Bert-eğitim ön gibi), aynı programı kullanır num_warmup_steps ). BERT belgesine uygun olarak, ilk öğrenme oranı ince ayar için daha küçüktür (5e-5, 3e-5, 2e-5'in en iyisi).
epochs = 5
steps_per_epoch = tf.data.experimental.cardinality(train_ds).numpy()
num_train_steps = steps_per_epoch * epochs
num_warmup_steps = int(0.1*num_train_steps)
init_lr = 3e-5
optimizer = optimization.create_optimizer(init_lr=init_lr,
num_train_steps=num_train_steps,
num_warmup_steps=num_warmup_steps,
optimizer_type='adamw')
BERT modelinin yüklenmesi ve eğitim
Kullanılması classifier_model önce oluşturduğunuz, sen kaybı, metrik ve iyileştirici ile modelini derlemek olabilir.
classifier_model.compile(optimizer=optimizer,
loss=loss,
metrics=metrics)
print(f'Training model with {tfhub_handle_encoder}')
history = classifier_model.fit(x=train_ds,
validation_data=val_ds,
epochs=epochs)
Training model with https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1 Epoch 1/5 625/625 [==============================] - 91s 138ms/step - loss: 0.4776 - binary_accuracy: 0.7513 - val_loss: 0.3791 - val_binary_accuracy: 0.8380 Epoch 2/5 625/625 [==============================] - 85s 136ms/step - loss: 0.3266 - binary_accuracy: 0.8547 - val_loss: 0.3659 - val_binary_accuracy: 0.8486 Epoch 3/5 625/625 [==============================] - 86s 138ms/step - loss: 0.2521 - binary_accuracy: 0.8928 - val_loss: 0.3975 - val_binary_accuracy: 0.8518 Epoch 4/5 625/625 [==============================] - 86s 137ms/step - loss: 0.1910 - binary_accuracy: 0.9269 - val_loss: 0.4180 - val_binary_accuracy: 0.8522 Epoch 5/5 625/625 [==============================] - 86s 137ms/step - loss: 0.1509 - binary_accuracy: 0.9433 - val_loss: 0.4641 - val_binary_accuracy: 0.8522
Modeli değerlendirin
Modelin nasıl performans gösterdiğini görelim. İki değer döndürülür. Kayıp (hatayı temsil eden bir sayı, daha düşük değerler daha iyidir) ve doğruluk.
loss, accuracy = classifier_model.evaluate(test_ds)
print(f'Loss: {loss}')
print(f'Accuracy: {accuracy}')
782/782 [==============================] - 61s 78ms/step - loss: 0.4495 - binary_accuracy: 0.8554 Loss: 0.4494614601135254 Accuracy: 0.8553599715232849
Zaman içindeki doğruluğu ve kaybı çizin
Göre History tarafından döndürülen nesne model.fit() . Karşılaştırma için eğitim ve doğrulama kaybının yanı sıra eğitim ve doğrulama doğruluğunu çizebilirsiniz:
history_dict = history.history
print(history_dict.keys())
acc = history_dict['binary_accuracy']
val_acc = history_dict['val_binary_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
fig = plt.figure(figsize=(10, 6))
fig.tight_layout()
plt.subplot(2, 1, 1)
# r is for "solid red line"
plt.plot(epochs, loss, 'r', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
# plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.subplot(2, 1, 2)
plt.plot(epochs, acc, 'r', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
dict_keys(['loss', 'binary_accuracy', 'val_loss', 'val_binary_accuracy']) <matplotlib.legend.Legend at 0x7fee7cdb4450>
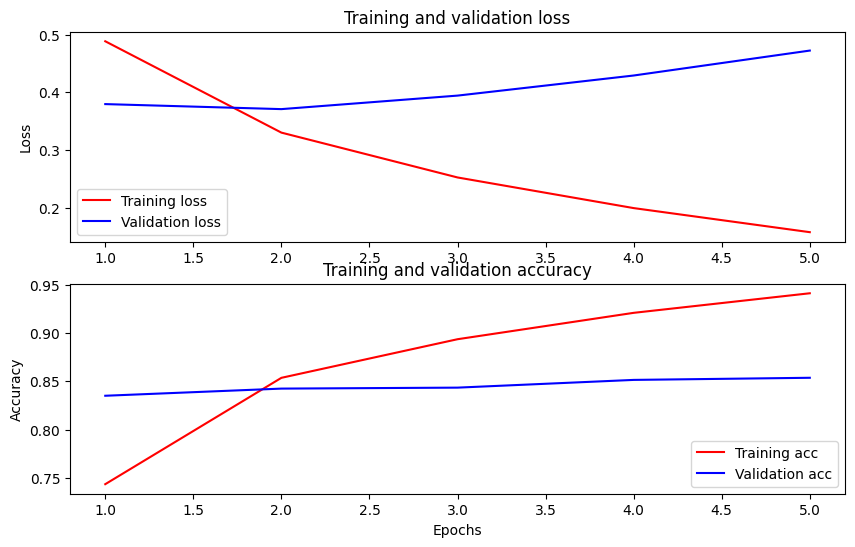
Bu grafikte, kırmızı çizgiler eğitim kaybını ve doğruluğunu temsil eder ve mavi çizgiler doğrulama kaybını ve doğruluğunu gösterir.
Çıkarım için dışa aktar
Şimdi ince ayarlı modelinizi daha sonra kullanmak üzere kaydedin.
dataset_name = 'imdb'
saved_model_path = './{}_bert'.format(dataset_name.replace('/', '_'))
classifier_model.save(saved_model_path, include_optimizer=False)
2021-12-01 12:26:06.207608: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:Found untraced functions such as restored_function_body, restored_function_body, restored_function_body, restored_function_body, restored_function_body while saving (showing 5 of 310). These functions will not be directly callable after loading.
Modeli yeniden yükleyelim, böylece hala hafızada olan modelle yan yana deneyebilirsiniz.
reloaded_model = tf.saved_model.load(saved_model_path)
Burada modelinizi istediğiniz herhangi bir cümle üzerinde test edebilirsiniz, sadece aşağıdaki örnekler değişkenine ekleyin.
def print_my_examples(inputs, results):
result_for_printing = \
[f'input: {inputs[i]:<30} : score: {results[i][0]:.6f}'
for i in range(len(inputs))]
print(*result_for_printing, sep='\n')
print()
examples = [
'this is such an amazing movie!', # this is the same sentence tried earlier
'The movie was great!',
'The movie was meh.',
'The movie was okish.',
'The movie was terrible...'
]
reloaded_results = tf.sigmoid(reloaded_model(tf.constant(examples)))
original_results = tf.sigmoid(classifier_model(tf.constant(examples)))
print('Results from the saved model:')
print_my_examples(examples, reloaded_results)
print('Results from the model in memory:')
print_my_examples(examples, original_results)
Results from the saved model: input: this is such an amazing movie! : score: 0.999521 input: The movie was great! : score: 0.997015 input: The movie was meh. : score: 0.988535 input: The movie was okish. : score: 0.079138 input: The movie was terrible... : score: 0.001622 Results from the model in memory: input: this is such an amazing movie! : score: 0.999521 input: The movie was great! : score: 0.997015 input: The movie was meh. : score: 0.988535 input: The movie was okish. : score: 0.079138 input: The movie was terrible... : score: 0.001622
Eğer üzerinde modeli kullanmak istiyorsanız TF Sunum , onun adlandırılmış imzaların biri üzerinden SavedModel arayacak unutmayın. Python'da bunları aşağıdaki gibi test edebilirsiniz:
serving_results = reloaded_model \
.signatures['serving_default'](tf.constant(examples))
serving_results = tf.sigmoid(serving_results['classifier'])
print_my_examples(examples, serving_results)
input: this is such an amazing movie! : score: 0.999521 input: The movie was great! : score: 0.997015 input: The movie was meh. : score: 0.988535 input: The movie was okish. : score: 0.079138 input: The movie was terrible... : score: 0.001622
Sonraki adımlar
Bir sonraki adım olarak, deneyebileceğiniz bir TPU öğretici üzerinde bert kullanarak YAPIŞTIRICI görevlerini çözün TPU ve gösterileri nasıl Çok girdili çalışmalarına üzerinde çalışır.