
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
Bu öğretici, diskte depolanan düz metin dosyalarından başlayarak metin sınıflandırmasını gösterir. Bir IMDB veri kümesinde duyarlılık analizi yapmak için bir ikili sınıflandırıcıyı eğiteceksiniz. Not defterinin sonunda, Stack Overflow'ta bir programlama sorusunun etiketini tahmin etmek için çok sınıflı bir sınıflandırıcıyı eğiteceğiniz, denemeniz için bir alıştırma var.
import matplotlib.pyplot as plt
import os
import re
import shutil
import string
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import losses
print(tf.__version__)
2.8.0-rc1
duygu analizi
Bu defter, film incelemelerini inceleme metnine göre olumlu veya olumsuz olarak sınıflandırmak için bir duygu analizi modeli eğitir. Bu, önemli ve yaygın olarak uygulanabilir bir makine öğrenimi problemi türü olan ikili —veya iki sınıflı— sınıflandırmanın bir örneğidir.
İnternet Film Veritabanından 50.000 film incelemesinin metnini içeren Büyük Film İnceleme Veri Kümesini kullanacaksınız. Bunlar, eğitim için 25.000 inceleme ve test için 25.000 incelemeye bölünmüştür. Eğitim ve test setleri dengelidir , yani eşit sayıda olumlu ve olumsuz inceleme içerirler.
IMDB veri setini indirin ve keşfedin
Veri kümesini indirip çıkaralım, ardından dizin yapısını keşfedelim.
url = "https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
dataset = tf.keras.utils.get_file("aclImdb_v1", url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 6s 0us/step 84140032/84125825 [==============================] - 6s 0us/step
os.listdir(dataset_dir)
['test', 'README', 'imdbEr.txt', 'imdb.vocab', 'train']
train_dir = os.path.join(dataset_dir, 'train')
os.listdir(train_dir)
['neg', 'urls_neg.txt', 'unsup', 'unsupBow.feat', 'urls_unsup.txt', 'urls_pos.txt', 'labeledBow.feat', 'pos']
aclImdb/train/pos ve aclImdb/train/neg dizinleri, her biri tek bir film incelemesi olan birçok metin dosyası içerir. Hadi onlardan birine bir göz atalım.
sample_file = os.path.join(train_dir, 'pos/1181_9.txt')
with open(sample_file) as f:
print(f.read())
Rachel Griffiths writes and directs this award winning short film. A heartwarming story about coping with grief and cherishing the memory of those we've loved and lost. Although, only 15 minutes long, Griffiths manages to capture so much emotion and truth onto film in the short space of time. Bud Tingwell gives a touching performance as Will, a widower struggling to cope with his wife's death. Will is confronted by the harsh reality of loneliness and helplessness as he proceeds to take care of Ruth's pet cow, Tulip. The film displays the grief and responsibility one feels for those they have loved and lost. Good cinematography, great direction, and superbly acted. It will bring tears to all those who have lost a loved one, and survived.
Veri kümesini yükleyin
Ardından, verileri diskten yükleyecek ve eğitim için uygun bir formatta hazırlayacaksınız. Bunu yapmak için, aşağıdaki gibi bir dizin yapısı bekleyen yararlı text_dataset_from_directory yardımcı programını kullanacaksınız.
main_directory/
...class_a/
......a_text_1.txt
......a_text_2.txt
...class_b/
......b_text_1.txt
......b_text_2.txt
İkili sınıflandırma için bir veri kümesi hazırlamak için diskte class_a ve class_b karşılık gelen iki klasöre ihtiyacınız olacak. Bunlar, aclImdb/train/pos ve aclImdb/train/neg bulunabilecek olumlu ve olumsuz film incelemeleri olacaktır. IMDB veri kümesi ek klasörler içerdiğinden, bu yardımcı programı kullanmadan önce bunları kaldıracaksınız.
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
Ardından, etiketli bir tf.data.Dataset oluşturmak için text_dataset_from_directory yardımcı programını kullanacaksınız. tf.data , verilerle çalışmak için güçlü bir araç koleksiyonudur.
Bir makine öğrenimi denemesi çalıştırırken, veri kümenizi üç bölüme ayırmak en iyi uygulamadır: train , doğrulama ve test .
IMDB veri kümesi zaten eğitim ve test olarak bölünmüştür, ancak bir doğrulama kümesinden yoksundur. Aşağıdaki validation_split argümanını kullanarak eğitim verilerinin 80:20 bölünmesini kullanarak bir doğrulama seti oluşturalım.
batch_size = 32
seed = 42
raw_train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='training',
seed=seed)
Found 25000 files belonging to 2 classes. Using 20000 files for training.
Yukarıda da görebileceğiniz gibi, eğitim klasöründe %80'ini (veya 20.000) eğitim için kullanacağınız 25.000 örnek bulunmaktadır. Birazdan göreceğiniz gibi, bir veri kümesini doğrudan model.fit geçirerek bir modeli eğitebilirsiniz. tf.data konusunda yeniyseniz, veri kümesi üzerinde yineleme yapabilir ve aşağıdaki gibi birkaç örnek yazdırabilirsiniz.
for text_batch, label_batch in raw_train_ds.take(1):
for i in range(3):
print("Review", text_batch.numpy()[i])
print("Label", label_batch.numpy()[i])
Review b'"Pandemonium" is a horror movie spoof that comes off more stupid than funny. Believe me when I tell you, I love comedies. Especially comedy spoofs. "Airplane", "The Naked Gun" trilogy, "Blazing Saddles", "High Anxiety", and "Spaceballs" are some of my favorite comedies that spoof a particular genre. "Pandemonium" is not up there with those films. Most of the scenes in this movie had me sitting there in stunned silence because the movie wasn\'t all that funny. There are a few laughs in the film, but when you watch a comedy, you expect to laugh a lot more than a few times and that\'s all this film has going for it. Geez, "Scream" had more laughs than this film and that was more of a horror film. How bizarre is that?<br /><br />*1/2 (out of four)' Label 0 Review b"David Mamet is a very interesting and a very un-equal director. His first movie 'House of Games' was the one I liked best, and it set a series of films with characters whose perspective of life changes as they get into complicated situations, and so does the perspective of the viewer.<br /><br />So is 'Homicide' which from the title tries to set the mind of the viewer to the usual crime drama. The principal characters are two cops, one Jewish and one Irish who deal with a racially charged area. The murder of an old Jewish shop owner who proves to be an ancient veteran of the Israeli Independence war triggers the Jewish identity in the mind and heart of the Jewish detective.<br /><br />This is were the flaws of the film are the more obvious. The process of awakening is theatrical and hard to believe, the group of Jewish militants is operatic, and the way the detective eventually walks to the final violent confrontation is pathetic. The end of the film itself is Mamet-like smart, but disappoints from a human emotional perspective.<br /><br />Joe Mantegna and William Macy give strong performances, but the flaws of the story are too evident to be easily compensated." Label 0 Review b'Great documentary about the lives of NY firefighters during the worst terrorist attack of all time.. That reason alone is why this should be a must see collectors item.. What shocked me was not only the attacks, but the"High Fat Diet" and physical appearance of some of these firefighters. I think a lot of Doctors would agree with me that,in the physical shape they were in, some of these firefighters would NOT of made it to the 79th floor carrying over 60 lbs of gear. Having said that i now have a greater respect for firefighters and i realize becoming a firefighter is a life altering job. The French have a history of making great documentary\'s and that is what this is, a Great Documentary.....' Label 1
İncelemelerin ham metin içerdiğine dikkat edin (noktalama işaretleri ve ara sıra <br/> gibi HTML etiketleri ile). Bunları nasıl ele alacağınızı aşağıdaki bölümde göstereceksiniz.
Etiketler 0 veya 1'dir. Bunlardan hangisinin olumlu ve olumsuz film incelemelerine karşılık geldiğini görmek için veri kümesindeki class_names özelliğini kontrol edebilirsiniz.
print("Label 0 corresponds to", raw_train_ds.class_names[0])
print("Label 1 corresponds to", raw_train_ds.class_names[1])
Label 0 corresponds to neg Label 1 corresponds to pos
Ardından, bir doğrulama ve test veri kümesi oluşturacaksınız. Doğrulama için eğitim setinden kalan 5.000 incelemeyi kullanacaksınız.
raw_val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='validation',
seed=seed)
Found 25000 files belonging to 2 classes. Using 5000 files for validation.yer tutucu21 l10n-yer
raw_test_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/test',
batch_size=batch_size)
Found 25000 files belonging to 2 classes.
Veri kümesini eğitim için hazırlayın
Ardından, yararlı tf.keras.layers.TextVectorization katmanını kullanarak verileri standartlaştıracak, simgeleştirecek ve vektörleştireceksiniz.
Standardizasyon, tipik olarak veri kümesini basitleştirmek için noktalama işaretlerini veya HTML öğelerini kaldırmak için metnin ön işlenmesi anlamına gelir. Belirteçleştirme, dizeleri belirteçlere bölme anlamına gelir (örneğin, boşlukta bölerek bir cümleyi tek tek sözcüklere bölme). Vektörleştirme, belirteçlerin bir sinir ağına beslenebilmeleri için sayılara dönüştürülmesi anlamına gelir. Tüm bu görevler bu katmanla gerçekleştirilebilir.
Yukarıda gördüğünüz gibi, incelemeler <br /> gibi çeşitli HTML etiketleri içerir. Bu etiketler, TextVectorization katmanındaki varsayılan standartlaştırıcı tarafından kaldırılmaz (metni küçük harfe dönüştürür ve varsayılan olarak noktalama işaretlerini kaldırır, ancak HTML'yi şeritlemez). HTML'yi kaldırmak için özel bir standardizasyon işlevi yazacaksınız.
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '<br />', ' ')
return tf.strings.regex_replace(stripped_html,
'[%s]' % re.escape(string.punctuation),
'')
Ardından, bir TextVectorization katmanı oluşturacaksınız. Verilerimizi standartlaştırmak, simgelemek ve vektörleştirmek için bu katmanı kullanacaksınız. Her belirteç için benzersiz tamsayı endeksleri oluşturmak için output_mode int olarak ayarlarsınız.
Varsayılan bölme işlevini ve yukarıda tanımladığınız özel standardizasyon işlevini kullandığınızı unutmayın. Ayrıca model için, katmanın sequence_length tam olarak dizi_uzunluk değerlerine göre doldurmasına veya kısaltmasına neden olacak açık bir maksimum sequence_length gibi bazı sabitler tanımlayacaksınız.
max_features = 10000
sequence_length = 250
vectorize_layer = layers.TextVectorization(
standardize=custom_standardization,
max_tokens=max_features,
output_mode='int',
output_sequence_length=sequence_length)
Ardından, ön işleme katmanının durumunu veri kümesine uydurmak için adapt çağıracaksınız. Bu, modelin tamsayılara bir dizi dizini oluşturmasına neden olur.
# Make a text-only dataset (without labels), then call adapt
train_text = raw_train_ds.map(lambda x, y: x)
vectorize_layer.adapt(train_text)
Bazı verileri önceden işlemek için bu katmanı kullanmanın sonucunu görmek için bir fonksiyon oluşturalım.
def vectorize_text(text, label):
text = tf.expand_dims(text, -1)
return vectorize_layer(text), label
# retrieve a batch (of 32 reviews and labels) from the dataset
text_batch, label_batch = next(iter(raw_train_ds))
first_review, first_label = text_batch[0], label_batch[0]
print("Review", first_review)
print("Label", raw_train_ds.class_names[first_label])
print("Vectorized review", vectorize_text(first_review, first_label))
Review tf.Tensor(b'Great movie - especially the music - Etta James - "At Last". This speaks volumes when you have finally found that special someone.', shape=(), dtype=string)
Label neg
Vectorized review (<tf.Tensor: shape=(1, 250), dtype=int64, numpy=
array([[ 86, 17, 260, 2, 222, 1, 571, 31, 229, 11, 2418,
1, 51, 22, 25, 404, 251, 12, 306, 282, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]])>, <tf.Tensor: shape=(), dtype=int32, numpy=0>)
Yukarıda görebileceğiniz gibi, her belirteç bir tamsayı ile değiştirildi. .get_vocabulary() çağırarak her tamsayının karşılık geldiği belirteci (dize) arayabilirsiniz.
print("1287 ---> ",vectorize_layer.get_vocabulary()[1287])
print(" 313 ---> ",vectorize_layer.get_vocabulary()[313])
print('Vocabulary size: {}'.format(len(vectorize_layer.get_vocabulary())))
1287 ---> silent 313 ---> night Vocabulary size: 10000
Modelinizi eğitmeye neredeyse hazırsınız. Son bir ön işleme adımı olarak, daha önce oluşturduğunuz TextVectorization katmanını tren, doğrulama ve test veri kümesine uygulayacaksınız.
train_ds = raw_train_ds.map(vectorize_text)
val_ds = raw_val_ds.map(vectorize_text)
test_ds = raw_test_ds.map(vectorize_text)
Performans için veri kümesini yapılandırın
Bunlar, G/Ç'nin bloke olmadığından emin olmak için veri yüklerken kullanmanız gereken iki önemli yöntemdir.
.cache() , diskten yüklendikten sonra verileri bellekte tutar. Bu, modelinizi eğitirken veri setinin bir darboğaz haline gelmemesini sağlayacaktır. Veri kümeniz belleğe sığmayacak kadar büyükse, bu yöntemi, okuması birçok küçük dosyadan daha verimli olan, performanslı bir disk önbelleği oluşturmak için de kullanabilirsiniz.
.prefetch() , eğitim sırasında veri ön işleme ve model yürütme ile çakışır.
Veri performans kılavuzunda her iki yöntem hakkında ve ayrıca verilerin diske nasıl önbelleğe alınacağı hakkında daha fazla bilgi edinebilirsiniz.
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
test_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE)
modeli oluştur
Sinir ağınızı oluşturmanın zamanı geldi:
embedding_dim = 16
model = tf.keras.Sequential([
layers.Embedding(max_features + 1, embedding_dim),
layers.Dropout(0.2),
layers.GlobalAveragePooling1D(),
layers.Dropout(0.2),
layers.Dense(1)])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 16) 160016
dropout (Dropout) (None, None, 16) 0
global_average_pooling1d (G (None, 16) 0
lobalAveragePooling1D)
dropout_1 (Dropout) (None, 16) 0
dense (Dense) (None, 1) 17
=================================================================
Total params: 160,033
Trainable params: 160,033
Non-trainable params: 0
_________________________________________________________________
Sınıflandırıcıyı oluşturmak için katmanlar sırayla istiflenir:
- İlk katman bir
Embeddingkatmanıdır. Bu katman, tamsayı kodlu incelemeleri alır ve her bir kelime dizini için bir gömme vektörü arar. Bu vektörler model trenler olarak öğrenilir. Vektörler, çıktı dizisine bir boyut ekler. Ortaya çıkan boyutlar:(batch, sequence, embedding). Gömmeler hakkında daha fazla bilgi edinmek için gömme öğretici sözcüğüne bakın. - Ardından, bir
GlobalAveragePooling1Dkatmanı, dizi boyutu üzerinden ortalama alarak her örnek için sabit uzunlukta bir çıktı vektörü döndürür. Bu, modelin değişken uzunluktaki girdileri mümkün olan en basit şekilde işlemesini sağlar. - Bu sabit uzunluktaki çıktı vektörü, 16 gizli birim ile tam bağlantılı (
Dense) bir katmandan geçirilir. - Son katman, tek bir çıkış düğümü ile yoğun bir şekilde bağlantılıdır.
Kayıp fonksiyonu ve optimize edici
Bir model, eğitim için bir kayıp işlevine ve bir optimize ediciye ihtiyaç duyar. Bu bir ikili sınıflandırma problemi olduğundan ve model bir olasılık (sigmoid aktivasyonlu tek birimli bir katman) losses.BinaryCrossentropy , kayıpları kullanacaksınız.BinaryCrossentropy kayıp fonksiyonu.
Şimdi, modeli bir optimize edici ve bir kayıp işlevi kullanacak şekilde yapılandırın:
model.compile(loss=losses.BinaryCrossentropy(from_logits=True),
optimizer='adam',
metrics=tf.metrics.BinaryAccuracy(threshold=0.0))
Modeli eğit
dataset nesnesini fit yöntemine geçirerek modeli eğiteceksiniz.
epochs = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs)
Epoch 1/10 625/625 [==============================] - 4s 4ms/step - loss: 0.6644 - binary_accuracy: 0.6894 - val_loss: 0.6159 - val_binary_accuracy: 0.7696 Epoch 2/10 625/625 [==============================] - 2s 4ms/step - loss: 0.5494 - binary_accuracy: 0.8020 - val_loss: 0.4993 - val_binary_accuracy: 0.8226 Epoch 3/10 625/625 [==============================] - 2s 3ms/step - loss: 0.4450 - binary_accuracy: 0.8447 - val_loss: 0.4205 - val_binary_accuracy: 0.8466 Epoch 4/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3778 - binary_accuracy: 0.8659 - val_loss: 0.3740 - val_binary_accuracy: 0.8618 Epoch 5/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3357 - binary_accuracy: 0.8785 - val_loss: 0.3451 - val_binary_accuracy: 0.8678 Epoch 6/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3055 - binary_accuracy: 0.8885 - val_loss: 0.3260 - val_binary_accuracy: 0.8700 Epoch 7/10 625/625 [==============================] - 2s 3ms/step - loss: 0.2817 - binary_accuracy: 0.8971 - val_loss: 0.3126 - val_binary_accuracy: 0.8730 Epoch 8/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2616 - binary_accuracy: 0.9034 - val_loss: 0.3037 - val_binary_accuracy: 0.8754 Epoch 9/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2458 - binary_accuracy: 0.9110 - val_loss: 0.2965 - val_binary_accuracy: 0.8788 Epoch 10/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2319 - binary_accuracy: 0.9158 - val_loss: 0.2920 - val_binary_accuracy: 0.8792
Modeli değerlendirin
Modelin nasıl performans gösterdiğini görelim. İki değer döndürülür. Kayıp (hatamızı temsil eden bir sayı, daha düşük değerler daha iyidir) ve doğruluk.
loss, accuracy = model.evaluate(test_ds)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
782/782 [==============================] - 2s 2ms/step - loss: 0.3104 - binary_accuracy: 0.8735 Loss: 0.3104138672351837 Accuracy: 0.873520016670227
Bu oldukça naif yaklaşım, yaklaşık %86'lık bir doğruluk sağlar.
Zaman içinde bir doğruluk ve kayıp grafiği oluşturun
model.fit() , eğitim sırasında olan her şeyi içeren bir sözlük içeren bir History nesnesi döndürür:
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'binary_accuracy', 'val_loss', 'val_binary_accuracy'])
Dört giriş vardır: eğitim ve doğrulama sırasında izlenen her metrik için bir tane. Bunları, karşılaştırma için eğitim ve doğrulama kaybının yanı sıra eğitim ve doğrulama doğruluğunu çizmek için kullanabilirsiniz:
acc = history_dict['binary_accuracy']
val_acc = history_dict['val_binary_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show()
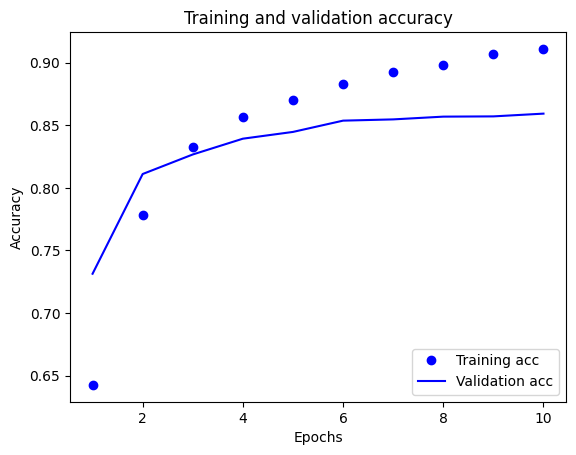
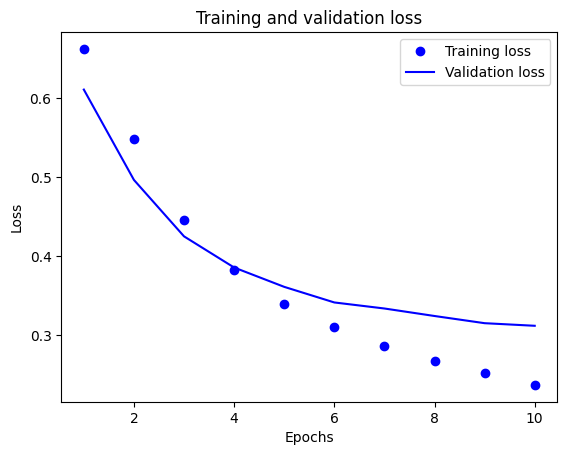
Bu çizimde, noktalar eğitim kaybını ve doğruluğunu temsil eder ve düz çizgiler doğrulama kaybı ve doğruluğunu gösterir.
Her çağda eğitim kaybının azaldığına ve her çağda eğitim doğruluğunun arttığına dikkat edin. Gradyan iniş optimizasyonu kullanılırken bu beklenir; her yinelemede istenen miktarı en aza indirmelidir.
Doğrulama kaybı ve doğruluğu için durum böyle değil - eğitim doğruluğundan önce zirveye ulaşıyor gibi görünüyorlar. Bu, fazla uydurmaya bir örnektir: model, eğitim verilerinde daha önce hiç görmediği verilerde olduğundan daha iyi performans gösterir. Bu noktadan sonra model, test verilerine genellemeyen eğitim verilerine özgü temsilleri aşırı optimize eder ve öğrenir.
Bu özel durumda, doğrulama doğruluğu artık artmadığında eğitimi basitçe durdurarak fazla takmayı önleyebilirsiniz. Bunu yapmanın bir yolu, tf.keras.callbacks.EarlyStopping geri aramasını kullanmaktır.
Modeli dışa aktar
Yukarıdaki kodda, modele metin beslemeden önce veri kümesine TextVectorization katmanını uyguladınız. Modelinizin ham dizeleri işleyebilmesini istiyorsanız (örneğin, dağıtmayı basitleştirmek için), modelinizin içine TextVectorization katmanını dahil edebilirsiniz. Bunun için az önce eğittiğiniz ağırlıkları kullanarak yeni bir model oluşturabilirsiniz.
export_model = tf.keras.Sequential([
vectorize_layer,
model,
layers.Activation('sigmoid')
])
export_model.compile(
loss=losses.BinaryCrossentropy(from_logits=False), optimizer="adam", metrics=['accuracy']
)
# Test it with `raw_test_ds`, which yields raw strings
loss, accuracy = export_model.evaluate(raw_test_ds)
print(accuracy)
782/782 [==============================] - 3s 4ms/step - loss: 0.3104 - accuracy: 0.8735 0.873520016670227
Yeni veriler üzerinde çıkarım
Yeni örnekler için tahminler almak için model.predict() çağırmanız yeterlidir.
examples = [
"The movie was great!",
"The movie was okay.",
"The movie was terrible..."
]
export_model.predict(examples)
array([[0.60320234],
[0.4262717 ],
[0.34439093]], dtype=float32)
Modelinizin içine metin ön işleme mantığını dahil etmek, dağıtımı basitleştiren ve tren/test çarpıklığı potansiyelini azaltan bir modeli üretim için dışa aktarmanıza olanak tanır.
TextVectorization katmanınızı nereye uygulayacağınızı seçerken akılda tutulması gereken bir performans farkı vardır. Modelinizin dışında kullanmak, GPU üzerinde eğitim yaparken eşzamansız CPU işleme ve verilerinizin arabelleğe alınmasını sağlar. Bu nedenle, modelinizi GPU üzerinde eğitiyorsanız, modelinizi geliştirirken en iyi performansı elde etmek için muhtemelen bu seçeneği kullanmak istersiniz, ardından dağıtıma hazırlanmaya hazır olduğunuzda TextVectorization katmanını modelinizin içine dahil etmek istersiniz. .
Modelleri kaydetme hakkında daha fazla bilgi edinmek için bu öğreticiyi ziyaret edin.
Alıştırma: Yığın Taşması sorularında çok sınıflı sınıflandırma
Bu öğretici, IMDB veri kümesinde sıfırdan bir ikili sınıflandırıcının nasıl eğitileceğini gösterdi. Alıştırma olarak, bu not defterini Stack Overflow'ta bir programlama sorusunun etiketini tahmin etmek için çok sınıflı bir sınıflandırıcı eğitmek üzere değiştirebilirsiniz.
Stack Overflow'a gönderilen birkaç bin programlama sorusunun (örneğin, "Python'da bir sözlüğü değerine göre nasıl sıralayabilirim?") gövdesini içeren, kullanmanız için bir veri kümesi hazırlanmıştır. Bunların her biri tam olarak bir etiketle (Python, CSharp, JavaScript veya Java) etiketlenir. Göreviniz, bir soruyu girdi olarak almak ve uygun etiketi, bu durumda Python'u tahmin etmektir.
Üzerinde çalışacağınız veri kümesi, 17 milyondan fazla gönderi içeren BigQuery'deki çok daha büyük genel Stack Overflow veri kümesinden alınan birkaç bin soru içerir.
Veri kümesini indirdikten sonra, daha önce çalıştığınız IMDB veri kümesine benzer bir dizin yapısına sahip olduğunu göreceksiniz:
train/
...python/
......0.txt
......1.txt
...javascript/
......0.txt
......1.txt
...csharp/
......0.txt
......1.txt
...java/
......0.txt
......1.txt
Bu alıştırmayı tamamlamak için, aşağıdaki değişiklikleri yaparak bu not defterini Yığın Taşması veri kümesiyle çalışacak şekilde değiştirmelisiniz:
Not defterinizin üst kısmında, önceden hazırlanmış olan Stack Overflow veri setini indirmek için IMDB veri setini indiren kodu kodla güncelleyin. Stack Overflow veri kümesi benzer bir dizin yapısına sahip olduğu için çok fazla değişiklik yapmanız gerekmeyecektir.
Artık dört çıktı sınıfı olduğundan, modelinizin son katmanını
Dense(4)olarak değiştirin.Modeli derlerken, kaybı
tf.keras.losses.SparseCategoricalCrossentropyolarak değiştirin. Bu, her sınıf için etiketler tamsayı olduğunda (bu durumda 0, 1 , 2 veya 3 olabilir) çok sınıflı bir sınıflandırma problemi için kullanılacak doğru kayıp işlevidir. Ayrıca, bu çok sınıflı bir sınıflandırma sorunu olduğundanmetrics=['accuracy']olarak değiştirin (tf.metrics.BinaryAccuracyyalnızca ikili sınıflandırıcılar için kullanılır).Doğruluğu zaman içinde çizerken, sırasıyla
binary_accuracyveval_binary_accuracyaccuracyveval_accuracyolarak değiştirin.Bu değişiklikler tamamlandıktan sonra, çok sınıflı bir sınıflandırıcı eğitebileceksiniz.
Daha fazlasını öğrenmek
Bu öğretici, sıfırdan metin sınıflandırmasını tanıttı. Genel olarak metin sınıflandırma iş akışı hakkında daha fazla bilgi edinmek için Google Developers'ın Metin sınıflandırma kılavuzuna bakın.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.