כלי עיבוד טקסט עבור TensorFlow
TensorFlow מספקת שתי ספריות לעיבוד טקסט ושפה טבעית: KerasNLP ו-TensorFlow Text. KerasNLP היא ספריית עיבוד שפה טבעית ברמה גבוהה (NLP) הכוללת מודלים מודרניים מבוססי שנאים וכן כלי עזר לטוקניזציה ברמה נמוכה יותר. זה הפתרון המומלץ עבור רוב מקרי השימוש ב-NLP. נבנה על TensorFlow Text, KerasNLP מופשט פעולות עיבוד טקסט ברמה נמוכה לתוך API שתוכנן לקלות שימוש. אבל אם אתה מעדיף לא לעבוד עם ה-API של Keras, או שאתה צריך גישה לאופציות לעיבוד טקסט ברמה נמוכה יותר, אתה יכול להשתמש ב- TensorFlow Text ישירות.
KerasNLP
import keras_nlp import tensorflow_datasets as tfds imdb_train, imdb_test = tfds.load( "imdb_reviews", split=["train", "test"], as_supervised=True, batch_size=16, ) # Load a BERT model. classifier = keras_nlp.models.BertClassifier.from_preset("bert_base_en_uncased") # Fine-tune on IMDb movie reviews. classifier.fit(imdb_train, validation_data=imdb_test) # Predict two new examples. classifier.predict(["What an amazing movie!", "A total waste of my time."])
הדרך הקלה ביותר להתחיל בעיבוד טקסט ב-TensorFlow היא להשתמש ב-KerasNLP. KerasNLP היא ספריית עיבוד שפה טבעית התומכת בזרימות עבודה הבנויות מרכיבים מודולריים שיש להם משקלים וארכיטקטורות מוגדרות מראש עדכניות. אתה יכול להשתמש ברכיבי KerasNLP עם התצורה שלהם מחוץ לקופסה. אם אתה צריך יותר שליטה, אתה יכול בקלות להתאים אישית רכיבים. KerasNLP מדגישה חישוב בגרף עבור כל זרימות העבודה, כך שתוכל לצפות לייצור קל באמצעות מערכת האקולוגית של TensorFlow.
KerasNLP היא הרחבה של הליבה של Keras API, וכל מודולי KerasNLP ברמה גבוהה הם שכבות או מודלים. אם אתה מכיר את Keras, אתה כבר מבין את רוב KerasNLP.
למידע נוסף, ראה KerasNLP .
טקסט TensorFlow
import tensorflow as tf import tensorflow_text as tf_text def preprocess(vocab_lookup_table, example_text): # Normalize text tf_text.normalize_utf8(example_text) # Tokenize into words word_tokenizer = tf_text.WhitespaceTokenizer() tokens = word_tokenizer.tokenize(example_text) # Tokenize into subwords subword_tokenizer = tf_text.WordpieceTokenizer( vocab_lookup_table, token_out_type=tf.int64) subtokens = subword_tokenizer.tokenize(tokens).merge_dims(1, -1) # Apply padding padded_inputs = tf_text.pad_model_inputs(subtokens, max_seq_length=16) return padded_inputs
KerasNLP מספקת מודולי עיבוד טקסט ברמה גבוהה הזמינים כשכבות או מודלים. אם אתה צריך גישה לכלים ברמה נמוכה יותר, אתה יכול להשתמש ב-TensorFlow Text. TensorFlow Text מספק לך אוסף עשיר של פעולות וספריות כדי לעזור לך לעבוד עם קלט בצורת טקסט כגון מחרוזות טקסט גולמיות או מסמכים. ספריות אלו יכולות לבצע את העיבוד המקדים הנדרש באופן קבוע על ידי מודלים מבוססי טקסט, ולכלול תכונות אחרות שימושיות עבור מודלים של רצף.
אתה יכול לחלץ תכונות טקסט תחביריות וסמנטיות חזקות מתוך גרף TensorFlow כקלט לרשת העצבית שלך.
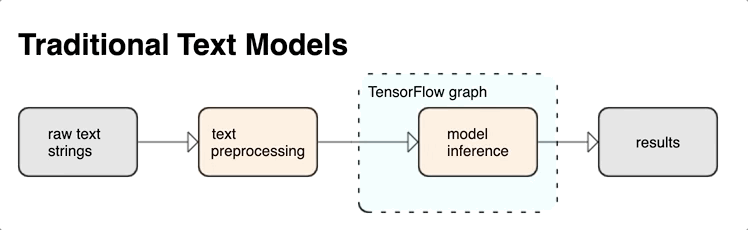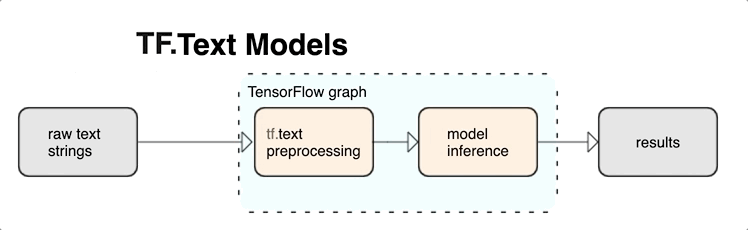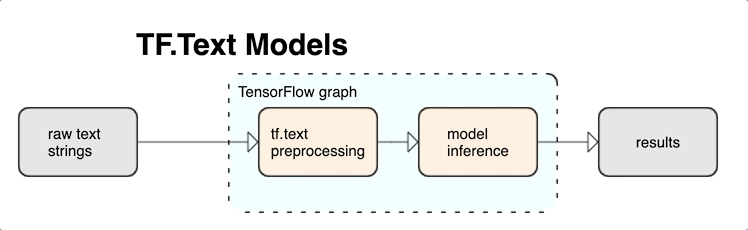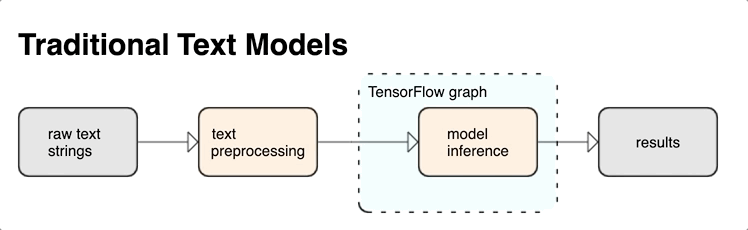
שילוב עיבוד מקדים עם גרף TensorFlow מספק את היתרונות הבאים:
- מאפשר ערכת כלים גדולה לעבודה עם טקסט
- מאפשר אינטגרציה עם חבילה גדולה של כלים של TensorFlow לתמיכה בפרויקטים מהגדרת בעיות דרך הדרכה, הערכה והשקה
- מפחית את המורכבות בזמן ההגשה ומונע הטיית אימון-הגשה
בנוסף לאמור לעיל, אינך צריך לדאוג שהטוקניזציה באימון תהיה שונה מהאסימון בהסקת ההסקה, או ניהול סקריפטים בעיבוד מקדים.