Strumenti di elaborazione del testo per TensorFlow
TensorFlow fornisce due librerie per l'elaborazione del testo e del linguaggio naturale: KerasNLP e TensorFlow Text. KerasNLP è una libreria di elaborazione del linguaggio naturale (NLP) di alto livello che include modelli moderni basati su trasformatori e utilità di tokenizzazione di livello inferiore. È la soluzione consigliata per la maggior parte dei casi d'uso della PNL. Basato su TensorFlow Text, KerasNLP astrae le operazioni di elaborazione del testo di basso livello in un'API progettata per la facilità d'uso. Ma se preferisci non lavorare con l'API Keras o hai bisogno di accedere alle operazioni di elaborazione del testo di livello inferiore, puoi utilizzare direttamente TensorFlow Text.
KerasNLP
import keras_nlp import tensorflow_datasets as tfds imdb_train, imdb_test = tfds.load( "imdb_reviews", split=["train", "test"], as_supervised=True, batch_size=16, ) # Load a BERT model. classifier = keras_nlp.models.BertClassifier.from_preset("bert_base_en_uncased") # Fine-tune on IMDb movie reviews. classifier.fit(imdb_train, validation_data=imdb_test) # Predict two new examples. classifier.predict(["What an amazing movie!", "A total waste of my time."])
Il modo più semplice per iniziare a elaborare il testo in TensorFlow è utilizzare KerasNLP. KerasNLP è una libreria di elaborazione del linguaggio naturale che supporta flussi di lavoro costruiti da componenti modulari che hanno pesi e architetture preimpostate all'avanguardia. Puoi utilizzare i componenti di KerasNLP con la loro configurazione pronta all'uso. Se hai bisogno di più controllo, puoi facilmente personalizzare i componenti. KerasNLP enfatizza il calcolo in-graph per tutti i flussi di lavoro, quindi puoi aspettarti una facile produzione utilizzando l'ecosistema TensorFlow.
KerasNLP è un'estensione dell'API Keras principale e tutti i moduli KerasNLP di alto livello sono livelli o modelli. Se hai familiarità con Keras, conosci già la maggior parte di KerasNLP.
Per saperne di più, vedi KerasNLP .
Testo TensorFlow
import tensorflow as tf import tensorflow_text as tf_text def preprocess(vocab_lookup_table, example_text): # Normalize text tf_text.normalize_utf8(example_text) # Tokenize into words word_tokenizer = tf_text.WhitespaceTokenizer() tokens = word_tokenizer.tokenize(example_text) # Tokenize into subwords subword_tokenizer = tf_text.WordpieceTokenizer( vocab_lookup_table, token_out_type=tf.int64) subtokens = subword_tokenizer.tokenize(tokens).merge_dims(1, -1) # Apply padding padded_inputs = tf_text.pad_model_inputs(subtokens, max_seq_length=16) return padded_inputs
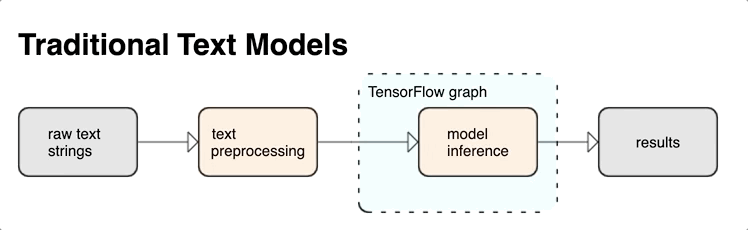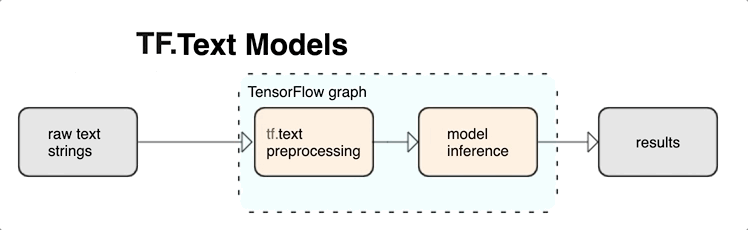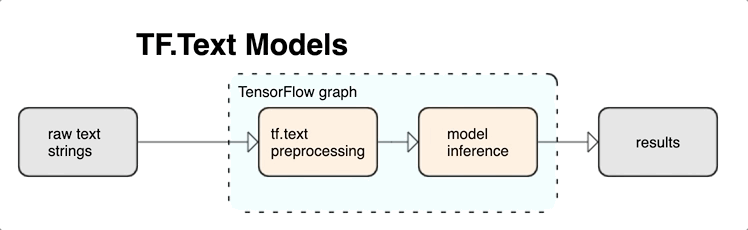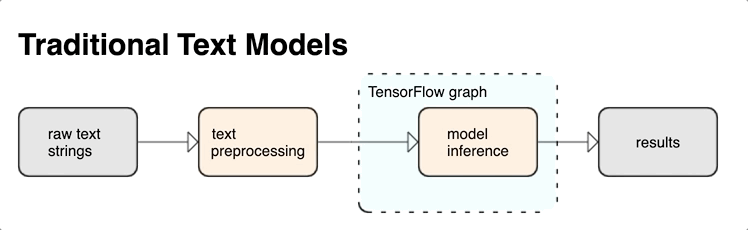
KerasNLP fornisce moduli di elaborazione del testo di alto livello disponibili come livelli o modelli. Se hai bisogno di accedere a strumenti di livello inferiore, puoi utilizzare TensorFlow Text. TensorFlow Text ti offre una ricca raccolta di operazioni e librerie per aiutarti a lavorare con input in forma di testo come stringhe di testo non elaborate o documenti. Queste librerie possono eseguire la preelaborazione regolarmente richiesta dai modelli basati su testo e includono altre funzionalità utili per la modellazione di sequenze.
Puoi estrarre potenti funzionalità di testo sintattico e semantico dall'interno del grafico TensorFlow come input per la tua rete neurale.
L'integrazione della pre-elaborazione con il grafico TensorFlow offre i seguenti vantaggi:
- Facilita un ampio toolkit per lavorare con il testo
- Consente l'integrazione con un'ampia suite di strumenti TensorFlow per supportare i progetti dalla definizione del problema attraverso la formazione, la valutazione e il lancio
- Riduce la complessità al momento del servizio e previene l'asimmetria del servizio di formazione
Oltre a quanto sopra, non devi preoccuparti che la tokenizzazione durante l'addestramento sia diversa dalla tokenizzazione durante l'inferenza o dalla gestione degli script di pre-elaborazione.