Инструменты обработки текста для TensorFlow
TensorFlow предоставляет две библиотеки для обработки текста и естественного языка: KerasNLP и TensorFlow Text. KerasNLP — это высокоуровневая библиотека обработки естественного языка (NLP), которая включает в себя современные модели на основе преобразователя, а также утилиты токенизации более низкого уровня. Это рекомендуемое решение для большинства случаев использования НЛП. Построенный на TensorFlow Text, KerasNLP абстрагирует низкоуровневые операции обработки текста в API, разработанный для простоты использования. Но если вы предпочитаете не работать с Keras API или вам нужен доступ к операциям обработки текста более низкого уровня, вы можете напрямую использовать TensorFlow Text.
КерасНЛП
import keras_nlp import tensorflow_datasets as tfds imdb_train, imdb_test = tfds.load( "imdb_reviews", split=["train", "test"], as_supervised=True, batch_size=16, ) # Load a BERT model. classifier = keras_nlp.models.BertClassifier.from_preset("bert_base_en_uncased") # Fine-tune on IMDb movie reviews. classifier.fit(imdb_train, validation_data=imdb_test) # Predict two new examples. classifier.predict(["What an amazing movie!", "A total waste of my time."])
Самый простой способ начать обработку текста в TensorFlow — использовать KerasNLP. KerasNLP — это библиотека обработки естественного языка, которая поддерживает рабочие процессы, построенные из модульных компонентов с современными предустановленными весами и архитектурами. Вы можете использовать компоненты KerasNLP с их готовой конфигурацией. Если вам нужно больше контроля, вы можете легко настроить компоненты. KerasNLP уделяет особое внимание вычислениям в графе для всех рабочих процессов, поэтому вы можете рассчитывать на простоту производства с использованием экосистемы TensorFlow.
KerasNLP является расширением основного API Keras, и все высокоуровневые модули KerasNLP являются слоями или моделями. Если вы знакомы с Keras, вы уже понимаете большую часть KerasNLP.
Чтобы узнать больше, см. KerasNLP .
Текст TensorFlow
import tensorflow as tf import tensorflow_text as tf_text def preprocess(vocab_lookup_table, example_text): # Normalize text tf_text.normalize_utf8(example_text) # Tokenize into words word_tokenizer = tf_text.WhitespaceTokenizer() tokens = word_tokenizer.tokenize(example_text) # Tokenize into subwords subword_tokenizer = tf_text.WordpieceTokenizer( vocab_lookup_table, token_out_type=tf.int64) subtokens = subword_tokenizer.tokenize(tokens).merge_dims(1, -1) # Apply padding padded_inputs = tf_text.pad_model_inputs(subtokens, max_seq_length=16) return padded_inputs
KerasNLP предоставляет высокоуровневые модули обработки текста, которые доступны в виде слоев или моделей. Если вам нужен доступ к инструментам более низкого уровня, вы можете использовать TensorFlow Text. TensorFlow Text предоставляет вам богатую коллекцию операций и библиотек, которые помогут вам работать с вводом в текстовой форме, такой как необработанные текстовые строки или документы. Эти библиотеки могут выполнять предварительную обработку, обычно необходимую для текстовых моделей, и включают другие функции, полезные для моделирования последовательностей.
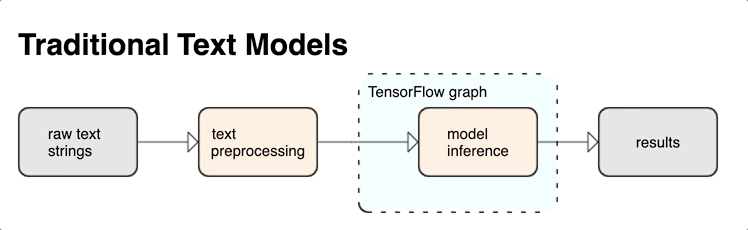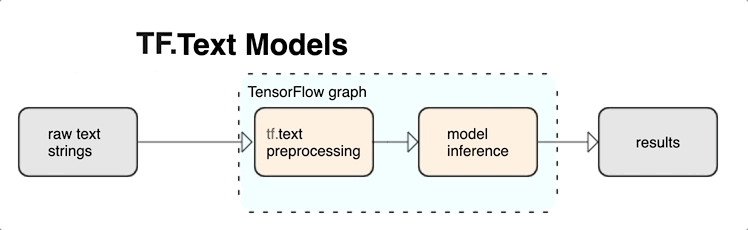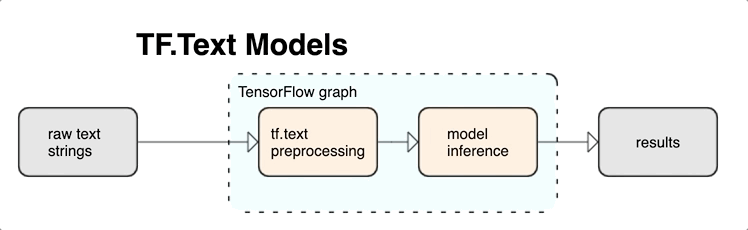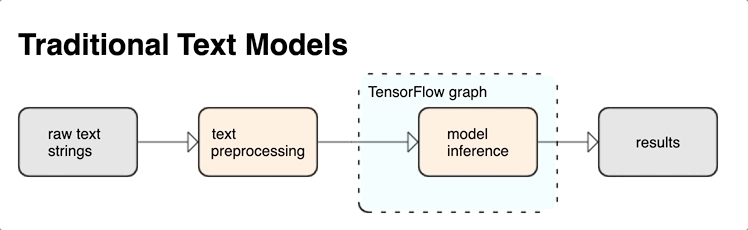
Вы можете извлекать мощные синтаксические и семантические функции текста из графа TensorFlow в качестве входных данных для вашей нейронной сети.
Интеграция предварительной обработки с графом TensorFlow дает следующие преимущества:
- Облегчает большой набор инструментов для работы с текстом
- Обеспечивает интеграцию с большим набором инструментов TensorFlow для поддержки проектов от определения проблемы до обучения, оценки и запуска.
- Снижает сложность подачи времени и предотвращает перекос между обучением и обслуживанием.
В дополнение к вышесказанному вам не нужно беспокоиться о том, что токенизация при обучении отличается от токенизации при выводе или управлении сценариями предварительной обработки.