
TensorFlow Data Validation (TFDV) puede analizar datos de entrenamiento y entrega para:
calcular estadísticas descriptivas,
inferir un esquema ,
detectar anomalías en los datos .
La API principal admite cada pieza de funcionalidad, con métodos convenientes que se basan en la parte superior y se pueden llamar en el contexto de los cuadernos.
Calcular estadísticas de datos descriptivos
TFDV puede calcular estadísticas descriptivas que proporcionan una descripción general rápida de los datos en términos de las características presentes y las formas de sus distribuciones de valores. Herramientas como Facets Overview pueden proporcionar una visualización sucinta de estas estadísticas para facilitar la navegación.
Por ejemplo, supongamos que la path apunta a un archivo en formato TFRecord (que contiene registros de tipo tensorflow.Example ). El siguiente fragmento ilustra el cálculo de estadísticas utilizando TFDV:
stats = tfdv.generate_statistics_from_tfrecord(data_location=path)
El valor devuelto es un búfer de protocolo DatasetFeatureStatisticsList . El cuaderno de ejemplo contiene una visualización de las estadísticas utilizando Facets Overview :
tfdv.visualize_statistics(stats)
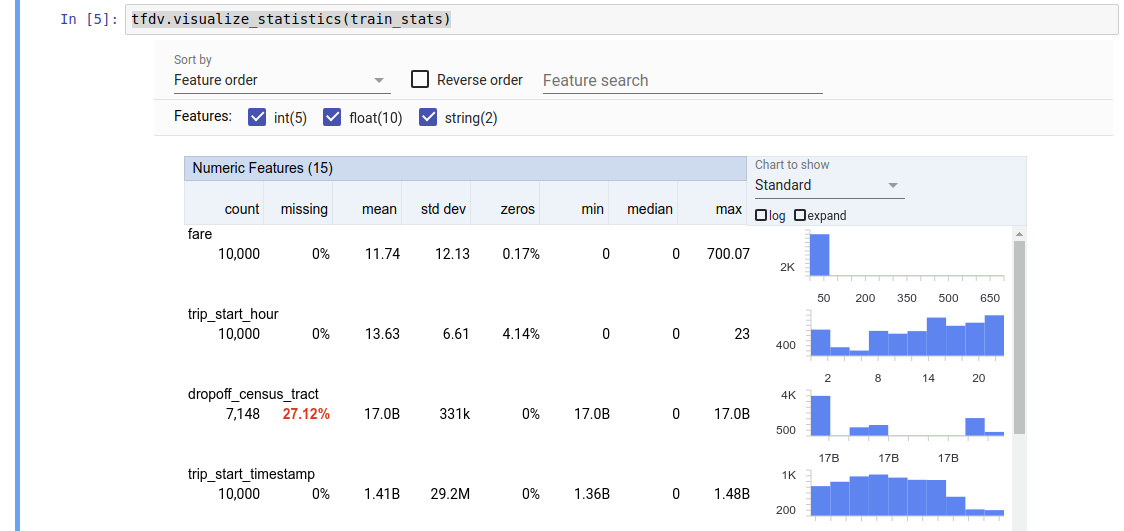
El ejemplo anterior supone que los datos están almacenados en un archivo TFRecord . TFDV también admite el formato de entrada CSV, con extensibilidad a otros formatos comunes. Puede encontrar los decodificadores de datos disponibles aquí . Además, TFDV proporciona la función de utilidad tfdv.generate_statistics_from_dataframe para usuarios con datos en memoria representados como un DataFrame de pandas.
Además de calcular un conjunto predeterminado de estadísticas de datos, TFDV también puede calcular estadísticas para dominios semánticos (por ejemplo, imágenes, texto). Para habilitar el cálculo de las estadísticas del dominio semántico, pase un objeto tfdv.StatsOptions con enable_semantic_domain_stats establecido en True a tfdv.generate_statistics_from_tfrecord .
Ejecutando en Google Cloud
Internamente, TFDV utiliza el marco de procesamiento de datos paralelo de Apache Beam para escalar el cálculo de estadísticas en grandes conjuntos de datos. Para las aplicaciones que desean una integración más profunda con TFDV (por ejemplo, adjuntar generación de estadísticas al final de un proceso de generación de datos, generar estadísticas para datos en formato personalizado ), la API también expone un Beam PTransform para la generación de estadísticas.
Para ejecutar TFDV en Google Cloud, el archivo de rueda TFDV debe descargarse y proporcionarse a los trabajadores de Dataflow. Descargue el archivo wheel al directorio actual de la siguiente manera:
pip download tensorflow_data_validation \
--no-deps \
--platform manylinux2010_x86_64 \
--only-binary=:all:
El siguiente fragmento muestra un ejemplo de uso de TFDV en Google Cloud:
import tensorflow_data_validation as tfdv
from apache_beam.options.pipeline_options import PipelineOptions, GoogleCloudOptions, StandardOptions, SetupOptions
PROJECT_ID = ''
JOB_NAME = ''
GCS_STAGING_LOCATION = ''
GCS_TMP_LOCATION = ''
GCS_DATA_LOCATION = ''
# GCS_STATS_OUTPUT_PATH is the file path to which to output the data statistics
# result.
GCS_STATS_OUTPUT_PATH = ''
PATH_TO_WHL_FILE = ''
# Create and set your PipelineOptions.
options = PipelineOptions()
# For Cloud execution, set the Cloud Platform project, job_name,
# staging location, temp_location and specify DataflowRunner.
google_cloud_options = options.view_as(GoogleCloudOptions)
google_cloud_options.project = PROJECT_ID
google_cloud_options.job_name = JOB_NAME
google_cloud_options.staging_location = GCS_STAGING_LOCATION
google_cloud_options.temp_location = GCS_TMP_LOCATION
options.view_as(StandardOptions).runner = 'DataflowRunner'
setup_options = options.view_as(SetupOptions)
# PATH_TO_WHL_FILE should point to the downloaded tfdv wheel file.
setup_options.extra_packages = [PATH_TO_WHL_FILE]
tfdv.generate_statistics_from_tfrecord(GCS_DATA_LOCATION,
output_path=GCS_STATS_OUTPUT_PATH,
pipeline_options=options)
En este caso, el protocolo de estadísticas generado se almacena en un archivo TFRecord escrito en GCS_STATS_OUTPUT_PATH .
NOTA Al llamar a cualquiera de las funciones tfdv.generate_statistics_... (por ejemplo, tfdv.generate_statistics_from_tfrecord ) en Google Cloud, debes proporcionar una output_path . Si especifica Ninguno, puede producirse un error.
Inferir un esquema sobre los datos.
El esquema describe las propiedades esperadas de los datos. Algunas de estas propiedades son:
- qué características se espera que estén presentes
- su tipo
- el número de valores para una característica en cada ejemplo
- la presencia de cada característica en todos los ejemplos
- los dominios esperados de características.
En resumen, el esquema describe las expectativas de datos "correctos" y, por lo tanto, puede usarse para detectar errores en los datos (que se describen a continuación). Además, se puede utilizar el mismo esquema para configurar TensorFlow Transform para transformaciones de datos. Tenga en cuenta que se espera que el esquema sea bastante estático; por ejemplo, varios conjuntos de datos pueden ajustarse al mismo esquema, mientras que las estadísticas (descritas anteriormente) pueden variar según el conjunto de datos.
Dado que escribir un esquema puede ser una tarea tediosa, especialmente para conjuntos de datos con muchas características, TFDV proporciona un método para generar una versión inicial del esquema basada en estadísticas descriptivas:
schema = tfdv.infer_schema(stats)
En general, TFDV utiliza heurísticas conservadoras para inferir propiedades de datos estables a partir de las estadísticas para evitar sobreajustar el esquema al conjunto de datos específico. Se recomienda encarecidamente revisar el esquema inferido y perfeccionarlo según sea necesario , para capturar cualquier conocimiento de dominio sobre los datos que la heurística de TFDV podría haber omitido.
De forma predeterminada, tfdv.infer_schema infiere la forma de cada característica requerida, si value_count.min es igual a value_count.max para la característica. Establezca el argumento infer_feature_shape en False para deshabilitar la inferencia de formas.
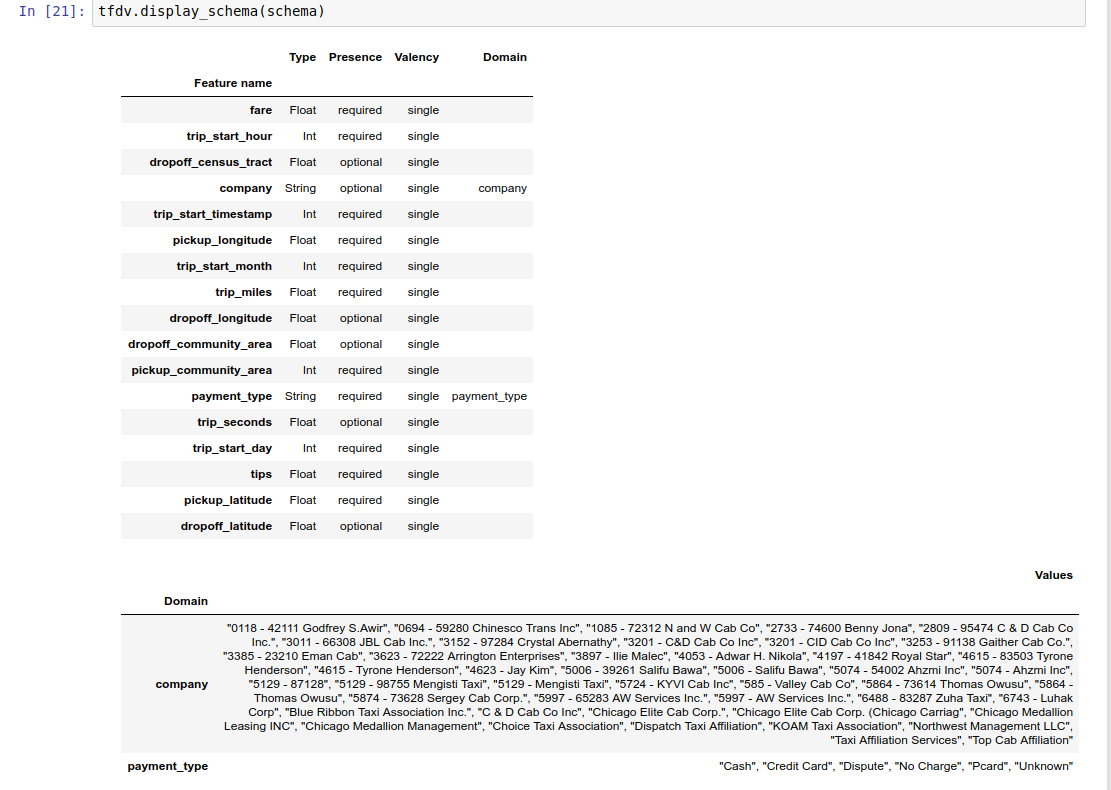
El esquema en sí se almacena como un búfer de protocolo de esquema y, por lo tanto, se puede actualizar/editar utilizando la API de búfer de protocolo estándar. TFDV también proporciona algunos métodos de utilidad para facilitar estas actualizaciones. Por ejemplo, supongamos que el esquema contiene la siguiente estrofa para describir una característica de cadena requerida payment_type que toma un único valor:
feature {
name: "payment_type"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
}
Para marcar que la función debe completarse en al menos el 50 % de los ejemplos:
tfdv.get_feature(schema, 'payment_type').presence.min_fraction = 0.5
El cuaderno de ejemplo contiene una visualización simple del esquema como una tabla, que enumera cada característica y sus características principales codificadas en el esquema.
Comprobar los datos en busca de errores.
Dado un esquema, es posible comprobar si un conjunto de datos se ajusta a las expectativas establecidas en el esquema o si existe alguna anomalía en los datos . Puede verificar sus datos en busca de errores (a) en conjunto en un conjunto de datos completo comparando las estadísticas del conjunto de datos con el esquema, o (b) verificando errores por ejemplo.
Hacer coincidir las estadísticas del conjunto de datos con un esquema
Para comprobar si hay errores en el conjunto, TFDV compara las estadísticas del conjunto de datos con el esquema y marca cualquier discrepancia. Por ejemplo:
# Assume that other_path points to another TFRecord file
other_stats = tfdv.generate_statistics_from_tfrecord(data_location=other_path)
anomalies = tfdv.validate_statistics(statistics=other_stats, schema=schema)
El resultado es una instancia del búfer del protocolo Anomalías y describe cualquier error en el que las estadísticas no concuerden con el esquema. Por ejemplo, supongamos que los datos en other_path contienen ejemplos con valores para la característica payment_type fuera del dominio especificado en el esquema.
Esto produce una anomalía
payment_type Unexpected string values Examples contain values missing from the schema: Prcard (<1%).
lo que indica que se encontró un valor fuera del dominio en las estadísticas en <1% de los valores de las características.
Si esto era lo esperado, entonces el esquema se puede actualizar de la siguiente manera:
tfdv.get_domain(schema, 'payment_type').value.append('Prcard')
Si la anomalía realmente indica un error de datos, entonces los datos subyacentes deben corregirse antes de usarlos para el entrenamiento.
Los distintos tipos de anomalías que este módulo puede detectar se enumeran aquí .
El cuaderno de ejemplo contiene una visualización simple de las anomalías en forma de tabla, enumera las características donde se detectan errores y una breve descripción de cada error.

Comprobación de errores por ejemplo
TFDV también ofrece la opción de validar datos por ejemplo, en lugar de comparar estadísticas de todo el conjunto de datos con el esquema. TFDV proporciona funciones para validar datos por ejemplo y luego generar estadísticas resumidas para los ejemplos anómalos encontrados. Por ejemplo:
options = tfdv.StatsOptions(schema=schema)
anomalous_example_stats = tfdv.validate_examples_in_tfrecord(
data_location=input, stats_options=options)
El anomalous_example_stats que devuelve validate_examples_in_tfrecord es un búfer de protocolo DatasetFeatureStatisticsList en el que cada conjunto de datos consta del conjunto de ejemplos que exhiben una anomalía particular. Puede usar esto para determinar la cantidad de ejemplos en su conjunto de datos que exhiben una anomalía determinada y las características de esos ejemplos.
Entornos de esquema
De forma predeterminada, las validaciones suponen que todos los conjuntos de datos de una canalización se adhieren a un único esquema. En algunos casos, es necesario introducir ligeras variaciones en el esquema; por ejemplo, las funciones utilizadas como etiquetas son necesarias durante el entrenamiento (y deben validarse), pero faltan durante la publicación.
Los entornos se pueden utilizar para expresar dichos requisitos. En particular, las características del esquema se pueden asociar con un conjunto de entornos utilizando default_environment, in_environment y not_in_environment.
Por ejemplo, si la función de sugerencias se utiliza como etiqueta en el entrenamiento, pero falta en los datos de publicación. Sin un entorno especificado, se mostrará como una anomalía.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)

Para solucionar este problema, debemos configurar el entorno predeterminado para todas las funciones para que sean tanto "ENTRENAMIENTO" como "SERVICIO", y excluir la función "consejos" del entorno de SERVICIO.
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
Comprobación de sesgo y desviación de datos
Además de comprobar si un conjunto de datos se ajusta a las expectativas marcadas en el esquema, TFDV también proporciona funcionalidades para detectar:
- sesgo entre entrenamiento y entrega de datos
- deriva entre diferentes días de datos de entrenamiento
TFDV realiza esta verificación comparando las estadísticas de diferentes conjuntos de datos en función de los comparadores de deriva/sesgo especificados en el esquema. Por ejemplo, para comprobar si hay alguna desviación entre la función 'tipo_pago' dentro del conjunto de datos de entrenamiento y de entrega:
# Assume we have already generated the statistics of training dataset, and
# inferred a schema from it.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
# Add a skew comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering skew anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').skew_comparator.infinity_norm.threshold = 0.01
skew_anomalies = tfdv.validate_statistics(
statistics=train_stats, schema=schema, serving_statistics=serving_stats)
NOTA La norma L-infinito solo detectará sesgos para las características categóricas. En lugar de especificar un umbral infinity_norm , especificar un umbral jensen_shannon_divergence en skew_comparator detectaría asimetrías tanto para características numéricas como categóricas.
Lo mismo ocurre con la comprobación de si un conjunto de datos se ajusta a las expectativas establecidas en el esquema; el resultado también es una instancia del búfer del protocolo de anomalías y describe cualquier desviación entre los conjuntos de datos de entrenamiento y de servicio. Por ejemplo, supongamos que los datos de publicación contienen muchos más ejemplos con la característica payement_type que tiene el valor Cash , esto produce una anomalía de sesgo.
payment_type High L-infinity distance between serving and training The L-infinity distance between serving and training is 0.0435984 (up to six significant digits), above the threshold 0.01. The feature value with maximum difference is: Cash
Si la anomalía realmente indica una desviación entre el entrenamiento y la entrega de datos, entonces es necesaria una mayor investigación, ya que esto podría tener un impacto directo en el rendimiento del modelo.
El cuaderno de ejemplo contiene un ejemplo sencillo de comprobación de anomalías basadas en sesgos.
La detección de desviaciones entre diferentes días de datos de entrenamiento se puede realizar de manera similar
# Assume we have already generated the statistics of training dataset for
# day 2, and inferred a schema from it.
train_day1_stats = tfdv.generate_statistics_from_tfrecord(data_location=train_day1_data_path)
# Add a drift comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering drift anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').drift_comparator.infinity_norm.threshold = 0.01
drift_anomalies = tfdv.validate_statistics(
statistics=train_day2_stats, schema=schema, previous_statistics=train_day1_stats)
NOTA La norma L-infinito solo detectará sesgos para las características categóricas. En lugar de especificar un umbral infinity_norm , especificar un umbral jensen_shannon_divergence en skew_comparator detectaría asimetrías tanto para características numéricas como categóricas.
Escribir conector de datos personalizado
Para calcular estadísticas de datos, TFDV proporciona varios métodos convenientes para manejar datos de entrada en varios formatos (por ejemplo, TFRecord de tf.train.Example , CSV, etc.). Si su formato de datos no está en esta lista, debe escribir un conector de datos personalizado para leer los datos de entrada y conectarlo con la API principal de TFDV para calcular estadísticas de datos.
La API principal de TFDV para calcular estadísticas de datos es un Beam PTransform que toma una PCollection de lotes de ejemplos de entrada (un lote de ejemplos de entrada se representa como un Arrow RecordBatch) y genera una PCollection que contiene un único búfer de protocolo DatasetFeatureStatisticsList .
Una vez que haya implementado el conector de datos personalizado que agrupa sus ejemplos de entrada en un Arrow RecordBatch, debe conectarlo con la API tfdv.GenerateStatistics para calcular las estadísticas de datos. Tome TFRecord de tf.train.Example , por ejemplo. tfx_bsl proporciona el conector de datos TFExampleRecord y a continuación se muestra un ejemplo de cómo conectarlo con la API tfdv.GenerateStatistics .
import tensorflow_data_validation as tfdv
from tfx_bsl.public import tfxio
import apache_beam as beam
from tensorflow_metadata.proto.v0 import statistics_pb2
DATA_LOCATION = ''
OUTPUT_LOCATION = ''
with beam.Pipeline() as p:
_ = (
p
# 1. Read and decode the data with tfx_bsl.
| 'TFXIORead' >> (
tfxio.TFExampleRecord(
file_pattern=[DATA_LOCATION],
telemetry_descriptors=['my', 'tfdv']).BeamSource())
# 2. Invoke TFDV `GenerateStatistics` API to compute the data statistics.
| 'GenerateStatistics' >> tfdv.GenerateStatistics()
# 3. Materialize the generated data statistics.
| 'WriteStatsOutput' >> WriteStatisticsToTFRecord(OUTPUT_LOCATION))
Calcular estadísticas sobre porciones de datos
TFDV se puede configurar para calcular estadísticas sobre sectores de datos. La división se puede habilitar proporcionando funciones de división que toman un Arrow RecordBatch y generan una secuencia de tuplas de forma (slice key, record batch) . TFDV proporciona una manera fácil de generar funciones de división basadas en valores de características que se pueden proporcionar como parte de tfdv.StatsOptions al calcular estadísticas.
Cuando la división está habilitada, el proto DatasetFeatureStatisticsList de salida contiene varios protos DatasetFeatureStatistics , uno para cada segmento. Cada segmento se identifica mediante un nombre único que se establece como el nombre del conjunto de datos en el protocolo DatasetFeatureStatistics . De forma predeterminada, TFDV calcula estadísticas para el conjunto de datos general además de los sectores configurados.
import tensorflow_data_validation as tfdv
from tensorflow_data_validation.utils import slicing_util
# Slice on country feature (i.e., every unique value of the feature).
slice_fn1 = slicing_util.get_feature_value_slicer(features={'country': None})
# Slice on the cross of country and state feature (i.e., every unique pair of
# values of the cross).
slice_fn2 = slicing_util.get_feature_value_slicer(
features={'country': None, 'state': None})
# Slice on specific values of a feature.
slice_fn3 = slicing_util.get_feature_value_slicer(
features={'age': [10, 50, 70]})
stats_options = tfdv.StatsOptions(
slice_functions=[slice_fn1, slice_fn2, slice_fn3])