
O TensorFlow Data Validation (TFDV) pode analisar dados de treinamento e exibição para:
calcular estatísticas descritivas,
inferir um esquema ,
detectar anomalias de dados .
A API principal dá suporte a cada parte da funcionalidade, com métodos de conveniência que se baseiam e podem ser chamados no contexto de notebooks.
Calculando estatísticas descritivas de dados
O TFDV pode calcular estatísticas descritivas que fornecem uma visão geral rápida dos dados em termos dos recursos presentes e das formas de suas distribuições de valor. Ferramentas como Visão geral de facetas podem fornecer uma visualização sucinta dessas estatísticas para facilitar a navegação.
Por exemplo, suponha que path aponte para um arquivo no formato TFRecord (que contém registros do tipo tensorflow.Example ). O snippet a seguir ilustra o cálculo de estatísticas usando TFDV:
stats = tfdv.generate_statistics_from_tfrecord(data_location=path)
O valor retornado é um buffer de protocolo DatasetFeatureStatisticsList . O bloco de notas de exemplo contém uma visualização das estatísticas usando a visão geral de facetas :
tfdv.visualize_statistics(stats)
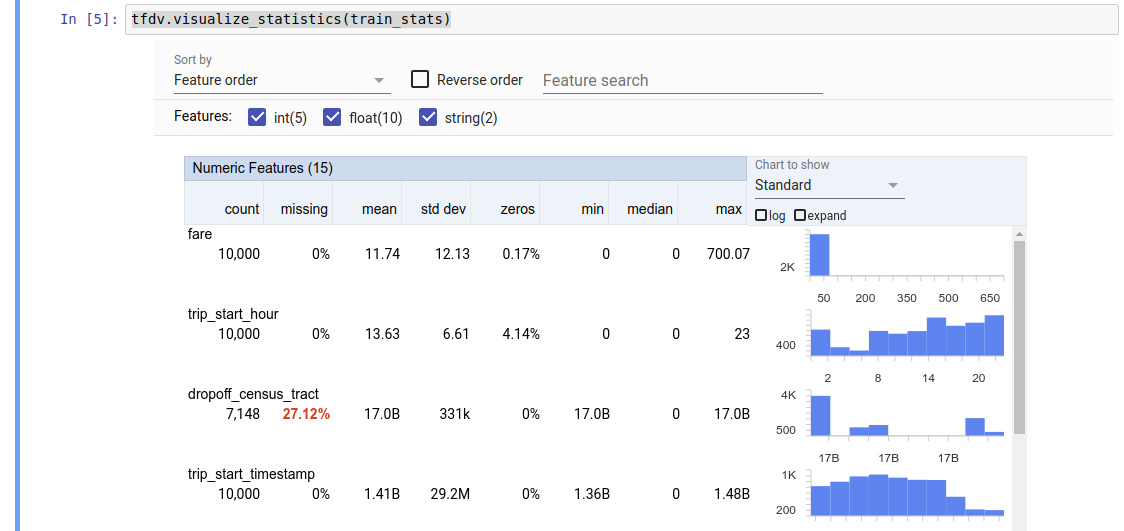
O exemplo anterior assume que os dados são armazenados em um arquivo TFRecord . O TFDV também oferece suporte ao formato de entrada CSV, com extensibilidade para outros formatos comuns. Você pode encontrar os decodificadores de dados disponíveis aqui . Além disso, o TFDV fornece a função de utilitário tfdv.generate_statistics_from_dataframe para usuários com dados na memória representados como um Pandas DataFrame.
Além de calcular um conjunto padrão de estatísticas de dados, o TFDV também pode calcular estatísticas para domínios semânticos (por exemplo, imagens, texto). Para habilitar o cálculo de estatísticas de domínio semântico, passe um objeto tfdv.StatsOptions com enable_semantic_domain_stats definido como True para tfdv.generate_statistics_from_tfrecord .
Executando no Google Cloud
Internamente, o TFDV usa a estrutura de processamento paralelo de dados do Apache Beam para escalar o cálculo de estatísticas em grandes conjuntos de dados. Para aplicativos que desejam uma integração mais profunda com o TFDV (por exemplo, anexar geração de estatísticas ao final de um pipeline de geração de dados, gerar estatísticas para dados em formato personalizado ), a API também expõe um Beam PTransform para geração de estatísticas.
Para executar o TFDV no Google Cloud, o arquivo roda TFDV deve ser baixado e fornecido aos trabalhadores do Dataflow. Baixe o arquivo wheel para o diretório atual da seguinte forma:
pip download tensorflow_data_validation \
--no-deps \
--platform manylinux2010_x86_64 \
--only-binary=:all:
O snippet a seguir mostra um exemplo de uso do TFDV no Google Cloud:
import tensorflow_data_validation as tfdv
from apache_beam.options.pipeline_options import PipelineOptions, GoogleCloudOptions, StandardOptions, SetupOptions
PROJECT_ID = ''
JOB_NAME = ''
GCS_STAGING_LOCATION = ''
GCS_TMP_LOCATION = ''
GCS_DATA_LOCATION = ''
# GCS_STATS_OUTPUT_PATH is the file path to which to output the data statistics
# result.
GCS_STATS_OUTPUT_PATH = ''
PATH_TO_WHL_FILE = ''
# Create and set your PipelineOptions.
options = PipelineOptions()
# For Cloud execution, set the Cloud Platform project, job_name,
# staging location, temp_location and specify DataflowRunner.
google_cloud_options = options.view_as(GoogleCloudOptions)
google_cloud_options.project = PROJECT_ID
google_cloud_options.job_name = JOB_NAME
google_cloud_options.staging_location = GCS_STAGING_LOCATION
google_cloud_options.temp_location = GCS_TMP_LOCATION
options.view_as(StandardOptions).runner = 'DataflowRunner'
setup_options = options.view_as(SetupOptions)
# PATH_TO_WHL_FILE should point to the downloaded tfdv wheel file.
setup_options.extra_packages = [PATH_TO_WHL_FILE]
tfdv.generate_statistics_from_tfrecord(GCS_DATA_LOCATION,
output_path=GCS_STATS_OUTPUT_PATH,
pipeline_options=options)
Nesse caso, o protocolo de estatísticas gerado é armazenado em um arquivo TFRecord gravado em GCS_STATS_OUTPUT_PATH .
OBSERVAÇÃO Ao chamar qualquer uma das funções tfdv.generate_statistics_... (por exemplo, tfdv.generate_statistics_from_tfrecord ) no Google Cloud, você deve fornecer um output_path . Especificar Nenhum pode causar um erro.
Inferir um esquema sobre os dados
O esquema descreve as propriedades esperadas dos dados. Algumas dessas propriedades são:
- quais recursos devem estar presentes
- o tipo deles
- o número de valores para um recurso em cada exemplo
- a presença de cada recurso em todos os exemplos
- os domínios esperados de recursos.
Resumindo, o esquema descreve as expectativas de dados "corretos" e pode, portanto, ser usado para detectar erros nos dados (descritos abaixo). Além disso, o mesmo esquema pode ser usado para configurar o TensorFlow Transform para transformações de dados. Observe que o esquema deve ser bastante estático, por exemplo, vários conjuntos de dados podem estar em conformidade com o mesmo esquema, enquanto as estatísticas (descritas acima) podem variar por conjunto de dados.
Como escrever um esquema pode ser uma tarefa tediosa, especialmente para conjuntos de dados com muitos recursos, o TFDV fornece um método para gerar uma versão inicial do esquema com base nas estatísticas descritivas:
schema = tfdv.infer_schema(stats)
Em geral, o TFDV usa heurística conservadora para inferir propriedades de dados estáveis das estatísticas, a fim de evitar o ajuste excessivo do esquema ao conjunto de dados específico. É altamente recomendável revisar o esquema inferido e refiná-lo conforme necessário , para capturar qualquer conhecimento de domínio sobre os dados que a heurística do TFDV possa ter perdido.
Por padrão, tfdv.infer_schema infere a forma de cada recurso necessário, se value_count.min for igual value_count.max para o recurso. Defina o argumento infer_feature_shape como False para desativar a inferência de forma.
O esquema em si é armazenado como um buffer de protocolo Schema e pode, portanto, ser atualizado/editado usando a API de buffer de protocolo padrão. O TFDV também fornece alguns métodos utilitários para facilitar essas atualizações. Por exemplo, suponha que o esquema contenha a seguinte estrofe para descrever um recurso de string obrigatório payment_type que aceita um único valor:
feature {
name: "payment_type"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
}
Para marcar que o recurso deve ser preenchido em pelo menos 50% dos exemplos:
tfdv.get_feature(schema, 'payment_type').presence.min_fraction = 0.5
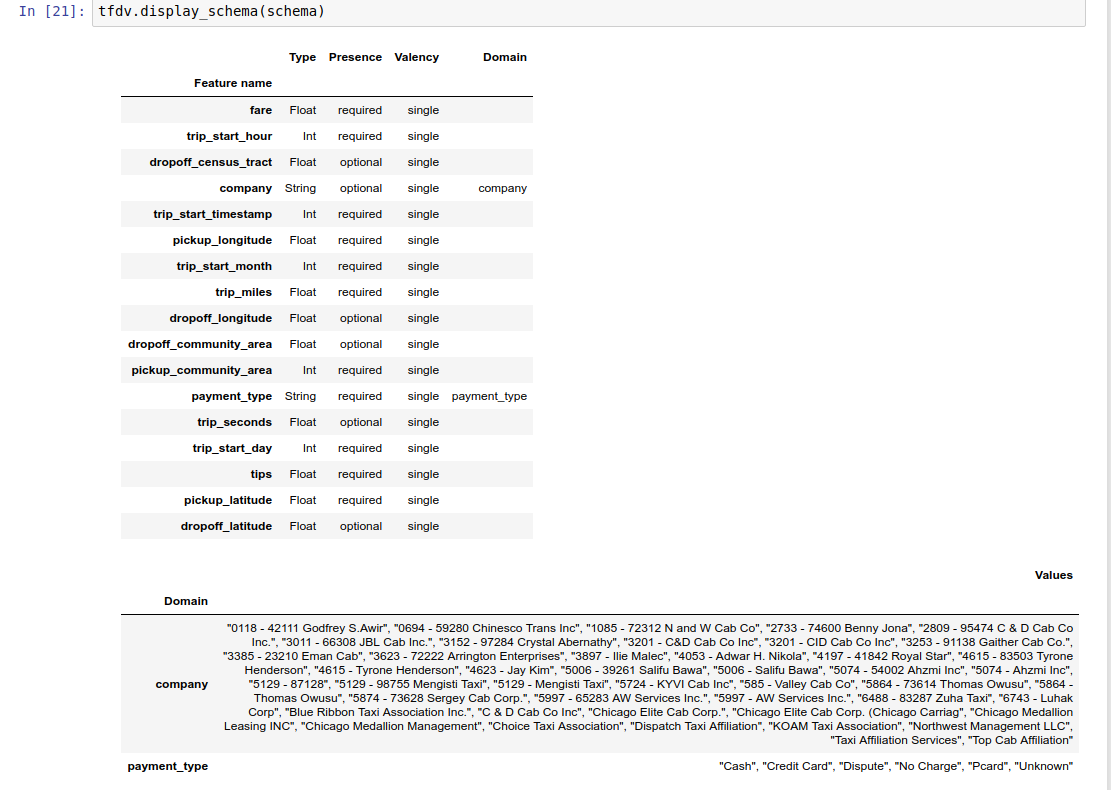
O notebook de exemplo contém uma visualização simples do esquema como uma tabela, listando cada recurso e suas principais características conforme codificadas no esquema.
Verificando os dados quanto a erros
Dado um esquema, é possível verificar se um conjunto de dados está de acordo com as expectativas definidas no esquema ou se existem anomalias de dados . Você pode verificar se há erros em seus dados (a) no agregado em todo um conjunto de dados comparando as estatísticas do conjunto de dados com o esquema ou (b) verificando erros por exemplo.
Correspondência das estatísticas do conjunto de dados com um esquema
Para verificar se há erros no agregado, o TFDV compara as estatísticas do conjunto de dados com o esquema e marca as discrepâncias. Por exemplo:
# Assume that other_path points to another TFRecord file
other_stats = tfdv.generate_statistics_from_tfrecord(data_location=other_path)
anomalies = tfdv.validate_statistics(statistics=other_stats, schema=schema)
O resultado é uma instância do buffer do protocolo Anomalies e descreve todos os erros em que as estatísticas não concordam com o esquema. Por exemplo, suponha que os dados em other_path contenham exemplos com valores para o recurso payment_type fora do domínio especificado no esquema.
Isso produz uma anomalia
payment_type Unexpected string values Examples contain values missing from the schema: Prcard (<1%).
indicando que um valor fora do domínio foi encontrado nas estatísticas em < 1% dos valores de recursos.
Se isso era esperado, o esquema pode ser atualizado da seguinte maneira:
tfdv.get_domain(schema, 'payment_type').value.append('Prcard')
Se a anomalia realmente indicar um erro de dados, os dados subjacentes devem ser corrigidos antes de serem usados para treinamento.
Os vários tipos de anomalias que podem ser detectados por este módulo são listados aqui .
O caderno de exemplo contém uma visualização simples das anomalias como uma tabela, listando as características onde os erros são detectados e uma breve descrição de cada erro.

Verificando erros em uma base por exemplo
O TFDV também oferece a opção de validar os dados por exemplo, em vez de comparar as estatísticas de todo o conjunto de dados com o esquema. O TFDV fornece funções para validar dados por exemplo e, em seguida, gerar estatísticas resumidas para os exemplos anômalos encontrados. Por exemplo:
options = tfdv.StatsOptions(schema=schema)
anomalous_example_stats = tfdv.validate_examples_in_tfrecord(
data_location=input, stats_options=options)
O anomalous_example_stats que validate_examples_in_tfrecord retorna é um buffer de protocolo DatasetFeatureStatisticsList no qual cada conjunto de dados consiste no conjunto de exemplos que exibem uma anomalia específica. Você pode usar isso para determinar o número de exemplos em seu conjunto de dados que exibem uma determinada anomalia e as características desses exemplos.
Ambientes de Esquema
Por padrão, as validações pressupõem que todos os conjuntos de dados em um pipeline aderem a um único esquema. Em alguns casos, é necessária a introdução de pequenas variações de esquema, por exemplo, recursos usados como rótulos são necessários durante o treinamento (e devem ser validados), mas estão ausentes durante a exibição.
Ambientes podem ser usados para expressar tais requisitos. Em particular, os recursos no esquema podem ser associados a um conjunto de ambientes usando default_environment, in_environment e not_in_environment.
Por exemplo, se o recurso dicas estiver sendo usado como rótulo no treinamento, mas ausente nos dados de serviço. Sem o ambiente especificado, ele aparecerá como uma anomalia.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)

Para corrigir isso, precisamos definir o ambiente padrão para todos os recursos como 'TREINAMENTO' e 'SERVIR' e excluir o recurso 'dicas' do ambiente de SERVIR.
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
Verificando a distorção e desvio de dados
Além de verificar se um conjunto de dados está de acordo com as expectativas definidas no esquema, o TFDV também fornece funcionalidades para detectar:
- desvio entre os dados de treinamento e veiculação
- deriva entre diferentes dias de dados de treinamento
O TFDV executa essa verificação comparando as estatísticas de diferentes conjuntos de dados com base nos comparadores de desvio/distorção especificados no esquema. Por exemplo, para verificar se há alguma distorção entre o recurso 'payment_type' no treinamento e no conjunto de dados de exibição:
# Assume we have already generated the statistics of training dataset, and
# inferred a schema from it.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
# Add a skew comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering skew anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').skew_comparator.infinity_norm.threshold = 0.01
skew_anomalies = tfdv.validate_statistics(
statistics=train_stats, schema=schema, serving_statistics=serving_stats)
OBSERVAÇÃO A norma L-infinity detectará apenas a inclinação para os recursos categóricos. Em vez de especificar um limite infinity_norm , especificar um limite jensen_shannon_divergence no skew_comparator detectaria a distorção para recursos numéricos e categóricos.
O mesmo que verificar se um conjunto de dados está em conformidade com as expectativas definidas no esquema, o resultado também é uma instância do buffer de protocolo Anomalies e descreve qualquer distorção entre os conjuntos de dados de treinamento e de serviço. Por exemplo, suponha que os dados de serviço contenham significativamente mais exemplos com o recurso payement_type tendo o valor Cash , isso produz uma anomalia de distorção
payment_type High L-infinity distance between serving and training The L-infinity distance between serving and training is 0.0435984 (up to six significant digits), above the threshold 0.01. The feature value with maximum difference is: Cash
Se a anomalia realmente indicar uma distorção entre os dados de treinamento e de exibição, será necessária uma investigação mais aprofundada, pois isso pode ter um impacto direto no desempenho do modelo.
O notebook de exemplo contém um exemplo simples de verificação de anomalias baseadas em distorção.
A detecção de desvio entre diferentes dias de dados de treinamento pode ser feita de maneira semelhante
# Assume we have already generated the statistics of training dataset for
# day 2, and inferred a schema from it.
train_day1_stats = tfdv.generate_statistics_from_tfrecord(data_location=train_day1_data_path)
# Add a drift comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering drift anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').drift_comparator.infinity_norm.threshold = 0.01
drift_anomalies = tfdv.validate_statistics(
statistics=train_day2_stats, schema=schema, previous_statistics=train_day1_stats)
OBSERVAÇÃO A norma L-infinity detectará apenas a inclinação para os recursos categóricos. Em vez de especificar um limite infinity_norm , especificar um limite jensen_shannon_divergence no skew_comparator detectaria a distorção para recursos numéricos e categóricos.
Gravando conector de dados personalizado
Para calcular estatísticas de dados, o TFDV fornece vários métodos convenientes para lidar com dados de entrada em vários formatos (por exemplo, TFRecord de tf.train.Example , CSV etc.). Se o seu formato de dados não estiver nesta lista, você precisará escrever um conector de dados personalizado para ler os dados de entrada e conectá-lo à API principal do TFDV para calcular estatísticas de dados.
A API principal do TFDV para computação de estatísticas de dados é uma Beam PTransform que usa uma PCollection de lotes de exemplos de entrada (um lote de exemplos de entrada é representado como um Arrow RecordBatch) e gera uma PCollection contendo um único buffer de protocolo DatasetFeatureStatisticsList .
Depois de implementar o conector de dados personalizado que agrupa seus exemplos de entrada em um Arrow RecordBatch, você precisa conectá-lo à API tfdv.GenerateStatistics para calcular as estatísticas de dados. Tome TFRecord de tf.train.Example 's por exemplo. tfx_bsl fornece o conector de dados TFExampleRecord e abaixo está um exemplo de como conectá-lo com a API tfdv.GenerateStatistics .
import tensorflow_data_validation as tfdv
from tfx_bsl.public import tfxio
import apache_beam as beam
from tensorflow_metadata.proto.v0 import statistics_pb2
DATA_LOCATION = ''
OUTPUT_LOCATION = ''
with beam.Pipeline() as p:
_ = (
p
# 1. Read and decode the data with tfx_bsl.
| 'TFXIORead' >> (
tfxio.TFExampleRecord(
file_pattern=[DATA_LOCATION],
telemetry_descriptors=['my', 'tfdv']).BeamSource())
# 2. Invoke TFDV `GenerateStatistics` API to compute the data statistics.
| 'GenerateStatistics' >> tfdv.GenerateStatistics()
# 3. Materialize the generated data statistics.
| 'WriteStatsOutput' >> WriteStatisticsToTFRecord(OUTPUT_LOCATION))
Computando estatísticas sobre fatias de dados
O TFDV pode ser configurado para calcular estatísticas sobre fatias de dados. O fatiamento pode ser ativado fornecendo funções de fatiamento que recebem um Arrow RecordBatch e geram uma sequência de tuplas de formulário (slice key, record batch) . O TFDV fornece uma maneira fácil de gerar funções de divisão baseadas em valor de recurso que podem ser fornecidas como parte de tfdv.StatsOptions ao computar estatísticas.
Quando o fatiamento está ativado, o proto DatasetFeatureStatisticsList de saída contém vários protos DatasetFeatureStatistics , um para cada fatia. Cada fatia é identificada por um nome exclusivo que é definido como o nome do conjunto de dados no proto DatasetFeatureStatistics . Por padrão, o TFDV calcula estatísticas para o conjunto de dados geral, além das fatias configuradas.
import tensorflow_data_validation as tfdv
from tensorflow_data_validation.utils import slicing_util
# Slice on country feature (i.e., every unique value of the feature).
slice_fn1 = slicing_util.get_feature_value_slicer(features={'country': None})
# Slice on the cross of country and state feature (i.e., every unique pair of
# values of the cross).
slice_fn2 = slicing_util.get_feature_value_slicer(
features={'country': None, 'state': None})
# Slice on specific values of a feature.
slice_fn3 = slicing_util.get_feature_value_slicer(
features={'age': [10, 50, 70]})
stats_options = tfdv.StatsOptions(
slice_functions=[slice_fn1, slice_fn2, slice_fn3])