
اعتبارسنجی دادههای TensorFlow (TFDV) میتواند دادههای آموزشی و ارائهدهی را تجزیه و تحلیل کند:
محاسبه آمار توصیفی،
استنتاج یک طرحواره ،
تشخیص ناهنجاری های داده ها
هسته API از هر بخش از عملکرد پشتیبانی می کند، با روش های راحتی که در بالا ساخته می شوند و می توان آنها را در زمینه نوت بوک فراخوانی کرد.
محاسبه آمار داده های توصیفی
TFDV می تواند آمار توصیفی را محاسبه کند که یک نمای کلی سریع از داده ها از نظر ویژگی های موجود و شکل توزیع ارزش آنها ارائه می دهد. ابزارهایی مانند Facets Overview می توانند تصویری مختصر از این آمار را برای مرور آسان ارائه دهند.
برای مثال، فرض کنید که path به فایلی با فرمت TFRecord (که رکوردهایی از نوع tensorflow.Example را در خود نگه می دارد. مثال) اشاره می کند. قطعه زیر محاسبه آمار را با استفاده از TFDV نشان می دهد:
stats = tfdv.generate_statistics_from_tfrecord(data_location=path)
مقدار بازگشتی یک بافر پروتکل DatasetFeatureStatisticsList است. دفترچه یادداشت نمونه شامل تجسم آمار با استفاده از نمای کلی جنبهها است:
tfdv.visualize_statistics(stats)

مثال قبلی فرض می کند که داده ها در یک فایل TFRecord ذخیره می شوند. TFDV همچنین از فرمت ورودی CSV با قابلیت گسترش برای سایر فرمت های رایج پشتیبانی می کند. می توانید رمزگشاهای داده موجود را در اینجا بیابید. علاوه بر این، TFDV تابع ابزار tfdv.generate_statistics_from_dataframe را برای کاربرانی که دادههای درون حافظه دارند ارائه میکند که بهعنوان DataFrame پانداها نمایش داده میشوند.
علاوه بر محاسبه یک مجموعه پیشفرض از آمار دادهها، TFDV همچنین میتواند آمار حوزههای معنایی (مانند تصاویر، متن) را محاسبه کند. برای فعال کردن محاسبه آمار دامنه معنایی، یک شی tfdv.StatsOptions را با enable_semantic_domain_stats به True به tfdv.generate_statistics_from_tfrecord ارسال کنید.
در حال اجرا در Google Cloud
در داخل، TFDV از چارچوب پردازش موازی داده Apache Beam برای مقیاسبندی محاسبه آمار بر روی مجموعه دادههای بزرگ استفاده میکند. برای برنامههایی که مایل به ادغام عمیقتر با TFDV هستند (مثلاً پیوست کردن تولید آمار در انتهای خط لوله تولید داده، تولید آمار برای دادهها در قالب سفارشی )، API همچنین یک Beam PTtransform را برای تولید آمار نشان میدهد.
برای اجرای TFDV در Google Cloud، فایل چرخ TFDV باید دانلود شده و در اختیار کارکنان Dataflow قرار گیرد. فایل چرخ را به صورت زیر در دایرکتوری فعلی دانلود کنید:
pip download tensorflow_data_validation \
--no-deps \
--platform manylinux2010_x86_64 \
--only-binary=:all:
قطعه زیر نمونه ای از استفاده از TFDV را در Google Cloud نشان می دهد:
import tensorflow_data_validation as tfdv
from apache_beam.options.pipeline_options import PipelineOptions, GoogleCloudOptions, StandardOptions, SetupOptions
PROJECT_ID = ''
JOB_NAME = ''
GCS_STAGING_LOCATION = ''
GCS_TMP_LOCATION = ''
GCS_DATA_LOCATION = ''
# GCS_STATS_OUTPUT_PATH is the file path to which to output the data statistics
# result.
GCS_STATS_OUTPUT_PATH = ''
PATH_TO_WHL_FILE = ''
# Create and set your PipelineOptions.
options = PipelineOptions()
# For Cloud execution, set the Cloud Platform project, job_name,
# staging location, temp_location and specify DataflowRunner.
google_cloud_options = options.view_as(GoogleCloudOptions)
google_cloud_options.project = PROJECT_ID
google_cloud_options.job_name = JOB_NAME
google_cloud_options.staging_location = GCS_STAGING_LOCATION
google_cloud_options.temp_location = GCS_TMP_LOCATION
options.view_as(StandardOptions).runner = 'DataflowRunner'
setup_options = options.view_as(SetupOptions)
# PATH_TO_WHL_FILE should point to the downloaded tfdv wheel file.
setup_options.extra_packages = [PATH_TO_WHL_FILE]
tfdv.generate_statistics_from_tfrecord(GCS_DATA_LOCATION,
output_path=GCS_STATS_OUTPUT_PATH,
pipeline_options=options)
در این مورد، پروتوی آماری تولید شده در یک فایل TFRecord که به GCS_STATS_OUTPUT_PATH نوشته شده ذخیره می شود.
توجه هنگام فراخوانی هر یک از توابع tfdv.generate_statistics_... (به عنوان مثال، tfdv.generate_statistics_from_tfrecord ) در Google Cloud، باید یک output_path ارائه کنید. مشخص کردن None ممکن است باعث خطا شود.
استنتاج یک طرحواره بر روی داده ها
این طرح ویژگی های مورد انتظار داده ها را توصیف می کند. برخی از این خواص عبارتند از:
- که انتظار می رود ویژگی هایی وجود داشته باشد
- نوع آنها
- تعداد مقادیر یک ویژگی در هر مثال
- وجود هر ویژگی در تمام نمونه ها
- حوزه های مورد انتظار ویژگی ها
به طور خلاصه، طرح واره انتظارات برای داده های "صحیح" را توصیف می کند و بنابراین می تواند برای تشخیص خطاها در داده ها (در زیر توضیح داده شده) استفاده شود. علاوه بر این، از همان طرحواره می توان برای راه اندازی TensorFlow Transform برای تبدیل داده ها استفاده کرد. توجه داشته باشید که انتظار می رود این طرح نسبتاً ثابت باشد، به عنوان مثال، چندین مجموعه داده می توانند با یک طرح مطابقت داشته باشند، در حالی که آمار (توضیح داده شده در بالا) می تواند در هر مجموعه داده متفاوت باشد.
از آنجایی که نوشتن یک طرحواره می تواند یک کار خسته کننده باشد، به ویژه برای مجموعه داده هایی با ویژگی های زیاد، TFDV روشی را برای تولید نسخه اولیه طرح بر اساس آمار توصیفی ارائه می دهد:
schema = tfdv.infer_schema(stats)
به طور کلی، TFDV از روش های اکتشافی محافظه کارانه برای استنتاج ویژگی های داده های پایدار از آمار استفاده می کند تا از تطبیق بیش از حد طرح با مجموعه داده خاص جلوگیری شود. اکیداً توصیه میشود طرحواره استنباطشده را بازبینی کنید و در صورت نیاز آن را اصلاح کنید ، تا هرگونه دانش دامنه در مورد دادههایی را که ممکن است اکتشافات TFDV از دست داده باشد، بدست آورید.
به طور پیش فرض، tfdv.infer_schema شکل هر ویژگی مورد نیاز را استنباط می کند، اگر value_count.min برابر value_count.max برای ویژگی باشد. برای غیرفعال کردن استنتاج شکل، آرگومان infer_feature_shape را روی False قرار دهید.
خود طرحواره به عنوان یک بافر پروتکل Schema ذخیره می شود و بنابراین می توان با استفاده از استاندارد پروتکل بافر API به روز رسانی/ویرایش کرد. TFDV همچنین چند روش کاربردی برای آسانتر کردن این بهروزرسانیها ارائه میکند. به عنوان مثال، فرض کنید که طرحواره شامل مصراع زیر برای توصیف یک ویژگی رشته مورد نیاز payment_type است که یک مقدار را می گیرد:
feature {
name: "payment_type"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
}
برای مشخص کردن این که ویژگی باید حداقل در 50٪ نمونه ها پر شود:
tfdv.get_feature(schema, 'payment_type').presence.min_fraction = 0.5
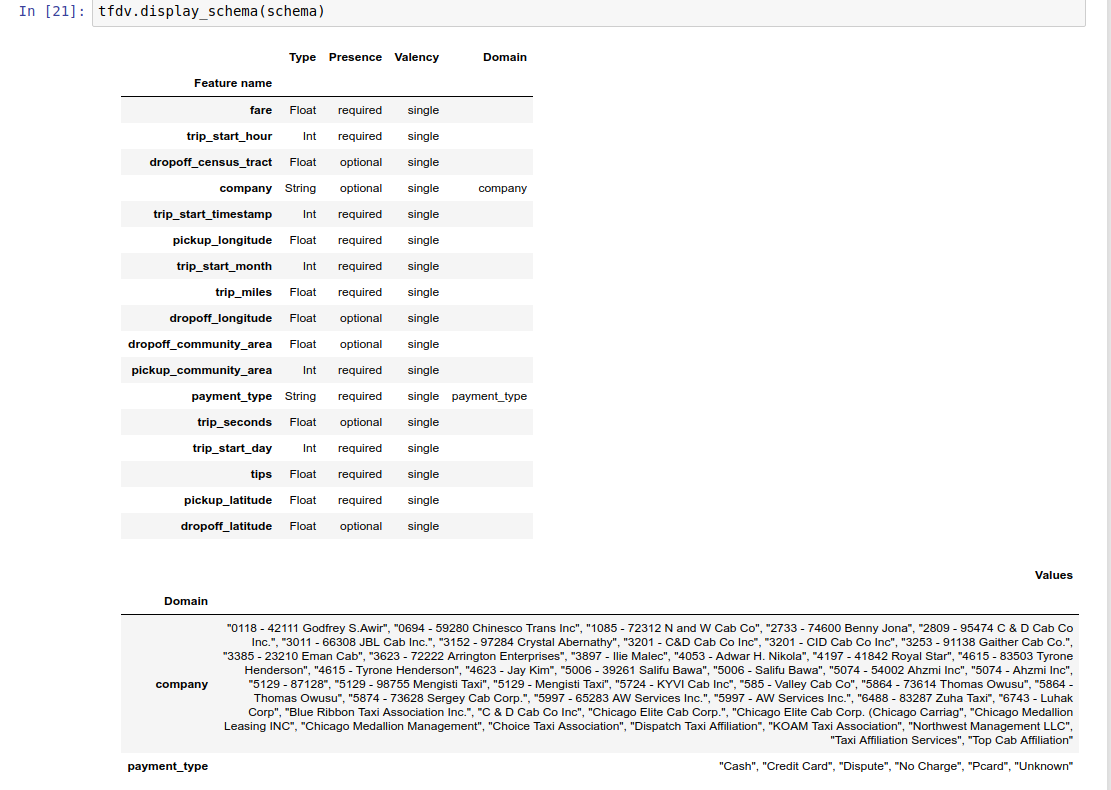
دفترچه یادداشت نمونه شامل یک تجسم ساده از طرحواره به عنوان یک جدول است که هر ویژگی و ویژگی های اصلی آن را به صورت کدگذاری شده در طرح فهرست می کند.
بررسی داده ها برای وجود خطا
با توجه به یک طرح، می توان بررسی کرد که آیا یک مجموعه داده با انتظارات تنظیم شده در طرح مطابقت دارد یا اینکه آیا ناهنجاری های داده وجود دارد یا خیر. میتوانید دادههای خود را برای خطاهای (الف) در مجموع در کل مجموعه داده با تطبیق آمار مجموعه داده با طرحواره، یا (ب) با بررسی خطاها بر اساس هر مثال بررسی کنید.
تطبیق آمار مجموعه داده با یک طرحواره
برای بررسی خطاها در مجموع، TFDV آمار مجموعه داده را با طرح تطبیق می دهد و هرگونه مغایرت را علامت گذاری می کند. به عنوان مثال:
# Assume that other_path points to another TFRecord file
other_stats = tfdv.generate_statistics_from_tfrecord(data_location=other_path)
anomalies = tfdv.validate_statistics(statistics=other_stats, schema=schema)
نتیجه نمونه ای از بافر پروتکل Anomalies است و هر گونه خطا را که در آن آمار با طرح مطابقت ندارد، توصیف می کند. برای مثال، فرض کنید که دادههای other_path حاوی نمونههایی با مقادیر ویژگی payment_type خارج از دامنه مشخصشده در طرح است.
این یک ناهنجاری ایجاد می کند
payment_type Unexpected string values Examples contain values missing from the schema: Prcard (<1%).
نشان می دهد که مقدار خارج از دامنه در آمار کمتر از 1٪ از مقادیر ویژگی پیدا شده است.
اگر این مورد انتظار بود، پس طرحواره را می توان به صورت زیر به روز کرد:
tfdv.get_domain(schema, 'payment_type').value.append('Prcard')
اگر ناهنجاری واقعاً نشاندهنده یک خطای داده باشد، قبل از استفاده از آن برای آموزش، دادههای اساسی باید برطرف شوند.
انواع مختلف ناهنجاری که می تواند توسط این ماژول شناسایی شود در اینجا فهرست شده است.
دفترچه یادداشت نمونه شامل یک تجسم ساده از ناهنجاری ها به عنوان یک جدول است که ویژگی هایی را که در آن خطاها شناسایی می شوند و شرح کوتاهی از هر خطا را فهرست می کند.

بررسی خطاها بر اساس هر نمونه
TFDV همچنین گزینه ای را برای اعتبارسنجی داده ها بر اساس هر مثال، به جای مقایسه آمارهای کل مجموعه داده با طرحواره فراهم می کند. TFDV توابعی را برای اعتبارسنجی داده ها بر اساس هر مثال و سپس تولید آمار خلاصه برای نمونه های غیرعادی یافت شده فراهم می کند. به عنوان مثال:
options = tfdv.StatsOptions(schema=schema)
anomalous_example_stats = tfdv.validate_examples_in_tfrecord(
data_location=input, stats_options=options)
anomalous_example_stats که validate_examples_in_tfrecord برمی گرداند، یک بافر پروتکل DatasetFeatureStatisticsList است که در آن هر مجموعه داده شامل مجموعه ای از نمونه هایی است که ناهنجاری خاصی را نشان می دهد. میتوانید از این برای تعیین تعداد نمونههایی در مجموعه دادهتان که یک ناهنجاری خاص را نشان میدهند و ویژگیهای آن نمونهها استفاده کنید.
محیط های طرحواره
بهطور پیشفرض، اعتبارسنجیها فرض میکنند که همه مجموعههای داده در یک خط لوله به یک طرح واحد پایبند هستند. در برخی موارد، ارائه تغییرات جزئی طرحواره ضروری است، برای مثال ویژگیهایی که بهعنوان برچسب در طول آموزش مورد استفاده قرار میگیرند (و باید تأیید شوند)، اما در حین ارائه از دست میروند.
برای بیان چنین الزاماتی می توان از محیط ها استفاده کرد. به طور خاص، ویژگیها در schema میتوانند با مجموعهای از محیطها با استفاده از default_environment، in_environment و not_in_environment مرتبط شوند.
به عنوان مثال، اگر ویژگی نکات به عنوان برچسب در آموزش استفاده می شود، اما در داده های ارائه وجود ندارد. بدون محیط مشخص شده، به عنوان یک ناهنجاری نشان داده می شود.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)

برای رفع این مشکل، باید محیط پیشفرض را برای همه ویژگیها «TRAINING» و «SERVING» تنظیم کنیم و ویژگی «نکات» را از محیط SERVING حذف کنیم.
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
بررسی انحراف و انحراف داده ها
علاوه بر بررسی اینکه آیا یک مجموعه داده با انتظارات تعیین شده در طرح مطابقت دارد یا خیر، TFDV همچنین قابلیت هایی را برای شناسایی فراهم می کند:
- انحراف بین آموزش و ارائه داده ها
- رانش بین روزهای مختلف داده های آموزشی
TFDV این بررسی را با مقایسه آمار مجموعه داده های مختلف بر اساس مقایسه کننده های drift/skew مشخص شده در طرح انجام می دهد. بهعنوان مثال، برای بررسی اینکه آیا بین ویژگی «نوع_پرداخت» در مجموعه دادههای آموزشی و سرویسدهی اختلاف وجود دارد یا خیر:
# Assume we have already generated the statistics of training dataset, and
# inferred a schema from it.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
# Add a skew comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering skew anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').skew_comparator.infinity_norm.threshold = 0.01
skew_anomalies = tfdv.validate_statistics(
statistics=train_stats, schema=schema, serving_statistics=serving_stats)
توجه هنجار L-infinity فقط برای ویژگیهای طبقهبندی انحراف را تشخیص میدهد. به جای تعیین یک آستانه infinity_norm ، تعیین یک آستانه jensen_shannon_divergence در skew_comparator ، چولگی را برای ویژگیهای عددی و طبقهای تشخیص میدهد.
همانند بررسی اینکه آیا یک مجموعه داده با انتظارات تنظیم شده در طرح مطابقت دارد یا خیر، نتیجه نیز نمونه ای از بافر پروتکل Anomalies است و هرگونه انحراف بین مجموعه داده های آموزشی و سرویس دهی را توصیف می کند. برای مثال، فرض کنید دادههای ارائهشده حاوی نمونههای بسیار بیشتری با ویژگی payement_type دارای ارزش Cash هستند، این یک ناهنجاری انحرافی ایجاد میکند.
payment_type High L-infinity distance between serving and training The L-infinity distance between serving and training is 0.0435984 (up to six significant digits), above the threshold 0.01. The feature value with maximum difference is: Cash
اگر این ناهنجاری واقعاً نشاندهنده انحراف بین آموزش و ارائه دادهها باشد، بررسی بیشتر ضروری است زیرا این امر میتواند تأثیر مستقیمی بر عملکرد مدل داشته باشد.
دفترچه یادداشت نمونه شامل یک مثال ساده از بررسی ناهنجاری های مبتنی بر چولگی است.
تشخیص انحراف بین روزهای مختلف داده های آموزشی می تواند به روشی مشابه انجام شود
# Assume we have already generated the statistics of training dataset for
# day 2, and inferred a schema from it.
train_day1_stats = tfdv.generate_statistics_from_tfrecord(data_location=train_day1_data_path)
# Add a drift comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering drift anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').drift_comparator.infinity_norm.threshold = 0.01
drift_anomalies = tfdv.validate_statistics(
statistics=train_day2_stats, schema=schema, previous_statistics=train_day1_stats)
توجه: هنجار L-infinity فقط برای ویژگیهای طبقهبندی انحراف را تشخیص میدهد. به جای تعیین یک آستانه infinity_norm ، تعیین یک آستانه jensen_shannon_divergence در skew_comparator ، چولگی را برای ویژگیهای عددی و طبقهای تشخیص میدهد.
نوشتن کانکتور داده سفارشی
برای محاسبه آمار دادهها، TFDV چندین روش راحت را برای مدیریت دادههای ورودی در قالبهای مختلف (مانند TFRecord of tf.train.Example ، CSV، و غیره) ارائه میکند. اگر فرمت داده شما در این لیست نیست، باید یک رابط داده سفارشی برای خواندن داده های ورودی بنویسید و آن را با API هسته TFDV برای محاسبه آمار داده ها متصل کنید.
API هسته TFDV برای محاسبه آمار داده ها یک Beam PTransform است که مجموعه ای از نمونه های ورودی را جمع آوری می کند (مجموعه ای از نمونه های ورودی به عنوان یک Arrow RecordBatch نشان داده می شود)، و یک PCCollection حاوی یک بافر پروتکل DatasetFeatureStatisticsList را خروجی می دهد.
هنگامی که اتصال دهنده داده سفارشی را که نمونه های ورودی شما را در یک Arrow RecordBatch دسته بندی می کند، پیاده سازی کردید، باید آن را با tfdv.GenerateStatistics API برای محاسبه آمار داده ها متصل کنید. برای مثال TFRecord از tf.train.Example را در نظر بگیرید. tfx_bsl رابط داده TFExampleRecord را ارائه می دهد و در زیر نمونه ای از نحوه اتصال آن با tfdv.GenerateStatistics API آورده شده است.
import tensorflow_data_validation as tfdv
from tfx_bsl.public import tfxio
import apache_beam as beam
from tensorflow_metadata.proto.v0 import statistics_pb2
DATA_LOCATION = ''
OUTPUT_LOCATION = ''
with beam.Pipeline() as p:
_ = (
p
# 1. Read and decode the data with tfx_bsl.
| 'TFXIORead' >> (
tfxio.TFExampleRecord(
file_pattern=[DATA_LOCATION],
telemetry_descriptors=['my', 'tfdv']).BeamSource())
# 2. Invoke TFDV `GenerateStatistics` API to compute the data statistics.
| 'GenerateStatistics' >> tfdv.GenerateStatistics()
# 3. Materialize the generated data statistics.
| 'WriteStatsOutput' >> WriteStatisticsToTFRecord(OUTPUT_LOCATION))
محاسبه آمار بر روی برش هایی از داده ها
TFDV را می توان برای محاسبه آمار بر روی تکه های داده پیکربندی کرد. برش را می توان با ارائه توابع برش فعال کرد که یک Arrow RecordBatch را می گیرند و دنباله ای از چند شکل (slice key, record batch) را تولید می کنند. TFDV یک راه آسان برای تولید توابع برش مبتنی بر ارزش ویژگی ارائه می دهد که می تواند به عنوان بخشی از tfdv.StatsOptions هنگام محاسبه آمار ارائه شود.
هنگامی که برش فعال است، پروتو خروجی DatasetFeatureStatisticsList حاوی چندین پروتز DatasetFeatureStatistics است، یکی برای هر برش. هر برش با یک نام منحصر به فرد شناسایی می شود که به عنوان نام مجموعه داده در پروتو DatasetFeatureStatistics تنظیم شده است. به طور پیشفرض TFDV علاوه بر برشهای پیکربندی شده، آمار کل مجموعه داده را محاسبه میکند.
import tensorflow_data_validation as tfdv
from tensorflow_data_validation.utils import slicing_util
# Slice on country feature (i.e., every unique value of the feature).
slice_fn1 = slicing_util.get_feature_value_slicer(features={'country': None})
# Slice on the cross of country and state feature (i.e., every unique pair of
# values of the cross).
slice_fn2 = slicing_util.get_feature_value_slicer(
features={'country': None, 'state': None})
# Slice on specific values of a feature.
slice_fn3 = slicing_util.get_feature_value_slicer(
features={'age': [10, 50, 70]})
stats_options = tfdv.StatsOptions(
slice_functions=[slice_fn1, slice_fn2, slice_fn3])