
TensorFlow Data Validation (TFDV) может анализировать данные обучения и обслуживания, чтобы:
вычислять описательную статистику ,
сделать вывод о схеме ,
обнаруживать аномалии данных .
Базовый API поддерживает каждую часть функциональности с помощью удобных методов, которые создаются на его основе и могут вызываться в контексте записных книжек.
Вычисление описательной статистики данных
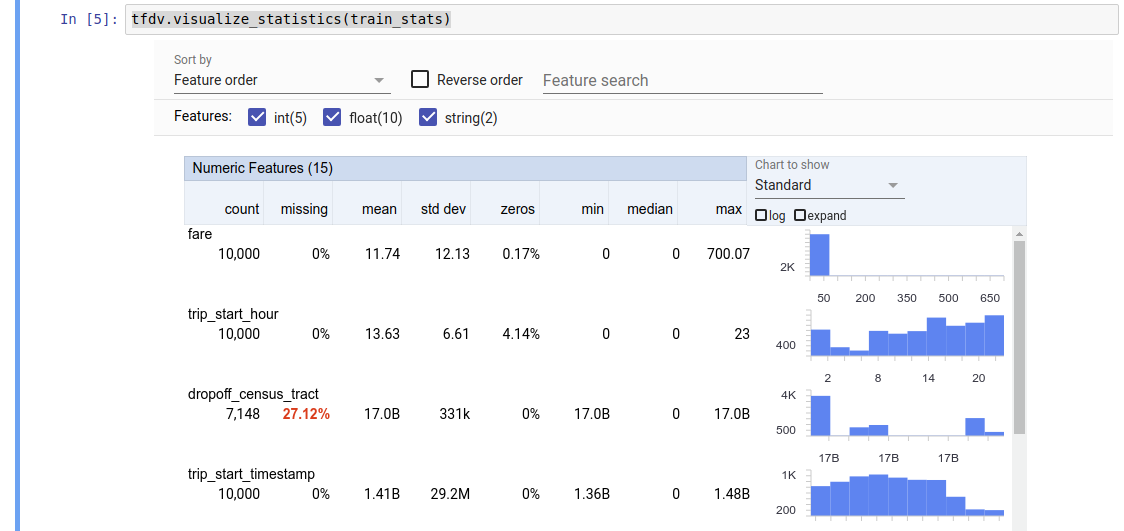
TFDV может рассчитывать описательную статистику , которая обеспечивает быстрый обзор данных с точки зрения присутствующих функций и форм распределения их значений. Такие инструменты, как Обзор аспектов, могут обеспечить краткую визуализацию этой статистики для удобства просмотра.
Например, предположим, что path указывает на файл в формате TFRecord (который содержит записи типа tensorflow.Example ). Следующий фрагмент иллюстрирует вычисление статистики с использованием TFDV:
stats = tfdv.generate_statistics_from_tfrecord(data_location=path)
Возвращаемое значение представляет собой буфер протокола DatasetFeatureStatisticsList . Пример блокнота содержит визуализацию статистики с помощью Обзора аспектов :
tfdv.visualize_statistics(stats)
В предыдущем примере предполагается, что данные хранятся в файле TFRecord . TFDV также поддерживает входной формат CSV с возможностью расширения для других распространенных форматов. Доступные декодеры данных вы можете найти здесь . Кроме того, TFDV предоставляет служебную функцию tfdv.generate_statistics_from_dataframe для пользователей с данными в памяти, представленными в виде DataFrame pandas.
Помимо вычисления набора статистики данных по умолчанию, TFDV также может вычислять статистику для семантических областей (например, изображений, текста). Чтобы включить вычисление статистики семантического домена, передайте объект tfdv.StatsOptions с enable_semantic_domain_stats , установленным в True, в tfdv.generate_statistics_from_tfrecord .
Запуск в Google Cloud
Внутри TFDV используется платформа параллельной обработки данных Apache Beam для масштабирования вычислений статистики по большим наборам данных. Для приложений, которые хотят глубже интегрироваться с TFDV (например, подключить генерацию статистики в конце конвейера генерации данных, генерировать статистику для данных в пользовательском формате ), API также предоставляет Beam PTransform для генерации статистики.
Чтобы запустить TFDV в Google Cloud, необходимо загрузить файл колеса TFDV и предоставить его работникам Dataflow. Загрузите файл колеса в текущий каталог следующим образом:
pip download tensorflow_data_validation \
--no-deps \
--platform manylinux2010_x86_64 \
--only-binary=:all:
В следующем фрагменте показан пример использования TFDV в Google Cloud:
import tensorflow_data_validation as tfdv
from apache_beam.options.pipeline_options import PipelineOptions, GoogleCloudOptions, StandardOptions, SetupOptions
PROJECT_ID = ''
JOB_NAME = ''
GCS_STAGING_LOCATION = ''
GCS_TMP_LOCATION = ''
GCS_DATA_LOCATION = ''
# GCS_STATS_OUTPUT_PATH is the file path to which to output the data statistics
# result.
GCS_STATS_OUTPUT_PATH = ''
PATH_TO_WHL_FILE = ''
# Create and set your PipelineOptions.
options = PipelineOptions()
# For Cloud execution, set the Cloud Platform project, job_name,
# staging location, temp_location and specify DataflowRunner.
google_cloud_options = options.view_as(GoogleCloudOptions)
google_cloud_options.project = PROJECT_ID
google_cloud_options.job_name = JOB_NAME
google_cloud_options.staging_location = GCS_STAGING_LOCATION
google_cloud_options.temp_location = GCS_TMP_LOCATION
options.view_as(StandardOptions).runner = 'DataflowRunner'
setup_options = options.view_as(SetupOptions)
# PATH_TO_WHL_FILE should point to the downloaded tfdv wheel file.
setup_options.extra_packages = [PATH_TO_WHL_FILE]
tfdv.generate_statistics_from_tfrecord(GCS_DATA_LOCATION,
output_path=GCS_STATS_OUTPUT_PATH,
pipeline_options=options)
В этом случае сгенерированный прототип статистики сохраняется в файле TFRecord, записанном в GCS_STATS_OUTPUT_PATH .
ПРИМЕЧАНИЕ. При вызове любой функции tfdv.generate_statistics_... (например, tfdv.generate_statistics_from_tfrecord ) в Google Cloud необходимо указать output_path . Указание «Нет» может привести к ошибке.
Вывод схемы по данным
Схема описывает ожидаемые свойства данных. Некоторые из этих свойств:
- какие функции должны присутствовать
- их тип
- количество значений для признака в каждом примере
- наличие каждой функции во всех примерах
- ожидаемые области функций.
Короче говоря, схема описывает ожидания «правильных» данных и, таким образом, может использоваться для обнаружения ошибок в данных (описанных ниже). Более того, ту же схему можно использовать для настройки TensorFlow Transform для преобразования данных. Обратите внимание, что схема, как ожидается, будет довольно статичной, например, несколько наборов данных могут соответствовать одной и той же схеме, тогда как статистика (описанная выше) может различаться для каждого набора данных.
Поскольку написание схемы может быть утомительной задачей, особенно для наборов данных с большим количеством функций, TFDV предоставляет метод для создания начальной версии схемы на основе описательной статистики:
schema = tfdv.infer_schema(stats)
В общем, TFDV использует консервативную эвристику для вывода стабильных свойств данных из статистики, чтобы избежать переподгонки схемы под конкретный набор данных. Настоятельно рекомендуется просмотреть выведенную схему и при необходимости уточнить ее , чтобы получить всю информацию о предметной области о данных, которые могли быть пропущены эвристикой TFDV.
По умолчанию tfdv.infer_schema определяет форму каждого требуемого объекта, если value_count.min равно value_count.max для объекта. Установите для аргумента infer_feature_shape значение False, чтобы отключить выведение формы.
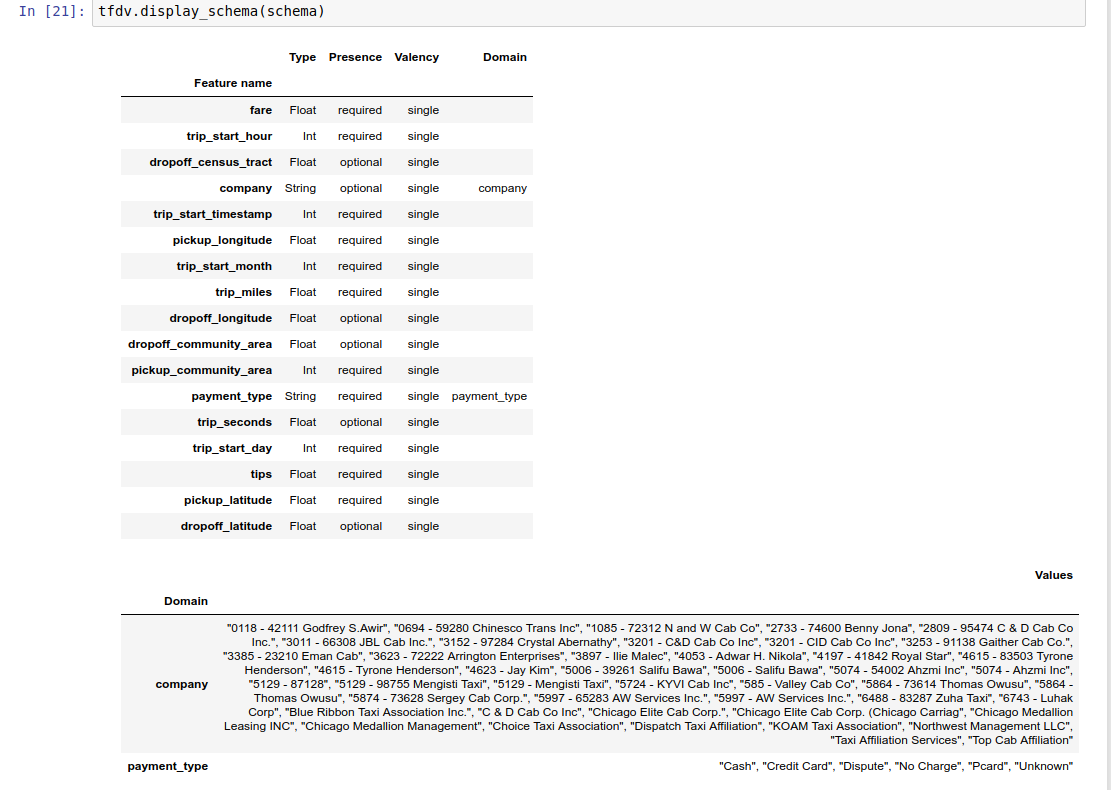
Сама схема хранится в виде буфера протокола Schema и, таким образом, может обновляться/редактироваться с помощью стандартного API буфера протокола. TFDV также предоставляет несколько служебных методов, упрощающих эти обновления. Например, предположим, что схема содержит следующий раздел для описания обязательной строковой функции payment_type , которая принимает одно значение:
feature {
name: "payment_type"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
}
Чтобы отметить, что функция должна быть заполнена как минимум в 50% примеров:
tfdv.get_feature(schema, 'payment_type').presence.min_fraction = 0.5
Пример записной книжки содержит простую визуализацию схемы в виде таблицы, в которой перечислены все функции и их основные характеристики, закодированные в схеме.
Проверка данных на наличие ошибок
Имея схему, можно проверить, соответствует ли набор данных ожиданиям, установленным в схеме, или существуют ли какие-либо аномалии данных . Вы можете проверить свои данные на наличие ошибок (а) в совокупности по всему набору данных, сопоставляя статистику набора данных со схемой, или (б) проверяя наличие ошибок для каждого примера.
Сопоставление статистики набора данных со схемой
Чтобы проверить наличие ошибок в совокупности, TFDV сопоставляет статистику набора данных со схемой и отмечает любые несоответствия. Например:
# Assume that other_path points to another TFRecord file
other_stats = tfdv.generate_statistics_from_tfrecord(data_location=other_path)
anomalies = tfdv.validate_statistics(statistics=other_stats, schema=schema)
Результатом является экземпляр буфера протокола аномалий , который описывает все ошибки, статистика которых не соответствует схеме. Например, предположим, что данные по other_path содержат примеры значений функции payment_type за пределами домена, указанного в схеме.
Это приводит к аномалии
payment_type Unexpected string values Examples contain values missing from the schema: Prcard (<1%).
что указывает на то, что значение, выходящее за пределы домена, было обнаружено в статистике в <1% значений функции.
Если это было ожидаемо, то схему можно обновить следующим образом:
tfdv.get_domain(schema, 'payment_type').value.append('Prcard')
Если аномалия действительно указывает на ошибку данных, то базовые данные следует исправить, прежде чем использовать их для обучения.
Здесь перечислены различные типы аномалий, которые может обнаружить этот модуль.
Пример блокнота содержит простую визуализацию аномалий в виде таблицы, в которой перечислены функции, в которых обнаружены ошибки, и краткое описание каждой ошибки.

Проверка ошибок на каждом примере
TFDV также предоставляет возможность проверять данные для каждого примера вместо сравнения статистики всего набора данных со схемой. TFDV предоставляет функции для проверки данных для каждого примера и последующего создания сводной статистики для найденных аномальных примеров. Например:
options = tfdv.StatsOptions(schema=schema)
anomalous_example_stats = tfdv.validate_examples_in_tfrecord(
data_location=input, stats_options=options)
anomalous_example_stats , возвращаемый validate_examples_in_tfrecord , представляет собой буфер протокола DatasetFeatureStatisticsList , в котором каждый набор данных состоит из набора примеров, демонстрирующих определенную аномалию. Вы можете использовать это, чтобы определить количество примеров в вашем наборе данных, демонстрирующих данную аномалию, и характеристики этих примеров.
Среды схемы
По умолчанию проверки предполагают, что все наборы данных в конвейере соответствуют одной схеме. В некоторых случаях необходимо вносить небольшие изменения в схему, например, функции, используемые в качестве меток, необходимы во время обучения (и должны быть проверены), но отсутствуют во время обслуживания.
Окружения могут использоваться для выражения таких требований. В частности, объекты в схеме могут быть связаны с набором сред с помощью default_environment, in_environment и not_in_environment.
Например, если функция подсказок используется в качестве метки при обучении, но отсутствует в данных об обслуживании. Без указания среды это будет отображаться как аномалия.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)

Чтобы исправить это, нам нужно установить среду по умолчанию для всех функций как «ОБУЧЕНИЕ» и «ОБСЛУЖИВАНИЕ», а также исключить функцию «Советы» из среды ОБСЛУЖИВАНИЯ.
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
Проверка асимметрии и дрейфа данных
Помимо проверки соответствия набора данных ожиданиям, установленным в схеме, TFDV также предоставляет функции для обнаружения:
- несоответствие между обучением и предоставлением данных
- дрейф между разными днями тренировочных данных
TFDV выполняет эту проверку, сравнивая статистику различных наборов данных на основе компараторов дрейфа/перекоса, указанных в схеме. Например, чтобы проверить, есть ли какое-либо несоответствие между функцией «pay_type» в наборе обучающих и обслуживающих данных:
# Assume we have already generated the statistics of training dataset, and
# inferred a schema from it.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
# Add a skew comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering skew anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').skew_comparator.infinity_norm.threshold = 0.01
skew_anomalies = tfdv.validate_statistics(
statistics=train_stats, schema=schema, serving_statistics=serving_stats)
ПРИМЕЧАНИЕ. Норма L-бесконечности обнаруживает асимметрию только для категориальных признаков. Вместо указания порога infinity_norm , указание порога jensen_shannon_divergence в skew_comparator позволит обнаружить перекос как для числовых, так и для категориальных признаков.
То же самое и с проверкой того, соответствует ли набор данных ожиданиям, установленным в схеме, результатом также является экземпляр буфера протокола аномалий , который описывает любой перекос между наборами обучающих и обслуживающих данных. Например, предположим, что данные обслуживания содержат значительно больше примеров с функцией payement_type , имеющей значение Cash , это приводит к аномалии перекоса.
payment_type High L-infinity distance between serving and training The L-infinity distance between serving and training is 0.0435984 (up to six significant digits), above the threshold 0.01. The feature value with maximum difference is: Cash
Если аномалия действительно указывает на несоответствие между обучающими и обслуживающими данными, то необходимо дальнейшее исследование, поскольку это может оказать прямое влияние на производительность модели.
В блокноте-примере приведен простой пример проверки аномалий, связанных с асимметрией.
Обнаружение дрейфа между разными днями обучающих данных можно выполнить аналогичным образом.
# Assume we have already generated the statistics of training dataset for
# day 2, and inferred a schema from it.
train_day1_stats = tfdv.generate_statistics_from_tfrecord(data_location=train_day1_data_path)
# Add a drift comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering drift anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').drift_comparator.infinity_norm.threshold = 0.01
drift_anomalies = tfdv.validate_statistics(
statistics=train_day2_stats, schema=schema, previous_statistics=train_day1_stats)
ПРИМЕЧАНИЕ. Норма L-бесконечности обнаруживает асимметрию только для категориальных признаков. Вместо указания порога infinity_norm , указание порога jensen_shannon_divergence в skew_comparator позволит обнаружить перекос как для числовых, так и для категориальных признаков.
Написание специального соединителя данных
Для расчета статистики данных TFDV предоставляет несколько удобных методов обработки входных данных в различных форматах (например, TFRecord tf.train.Example , CSV и т. д.). Если вашего формата данных нет в этом списке, вам необходимо написать собственный соединитель данных для чтения входных данных и подключить его к основному API TFDV для вычисления статистики данных.
Базовый API TFDV для вычисления статистики данных — это Beam PTransform , который принимает PCollection пакетов входных примеров (пакет входных примеров представлен как Arrow RecordBatch) и выводит PCollection, содержащую один буфер протокола DatasetFeatureStatisticsList .
После того как вы реализовали пользовательский соединитель данных, который группирует примеры входных данных в Arrow RecordBatch, вам необходимо соединить его с API tfdv.GenerateStatistics для вычисления статистики данных. Возьмем, к примеру, TFRecord tf.train.Example . tfx_bsl предоставляет соединитель данных TFExampleRecord , и ниже приведен пример его подключения к API tfdv.GenerateStatistics .
import tensorflow_data_validation as tfdv
from tfx_bsl.public import tfxio
import apache_beam as beam
from tensorflow_metadata.proto.v0 import statistics_pb2
DATA_LOCATION = ''
OUTPUT_LOCATION = ''
with beam.Pipeline() as p:
_ = (
p
# 1. Read and decode the data with tfx_bsl.
| 'TFXIORead' >> (
tfxio.TFExampleRecord(
file_pattern=[DATA_LOCATION],
telemetry_descriptors=['my', 'tfdv']).BeamSource())
# 2. Invoke TFDV `GenerateStatistics` API to compute the data statistics.
| 'GenerateStatistics' >> tfdv.GenerateStatistics()
# 3. Materialize the generated data statistics.
| 'WriteStatsOutput' >> WriteStatisticsToTFRecord(OUTPUT_LOCATION))
Вычисление статистики по срезам данных
TFDV можно настроить для вычисления статистики по срезам данных. Нарезку можно включить, предоставив функции нарезки, которые принимают Arrow RecordBatch и выводят последовательность кортежей формы (slice key, record batch) . TFDV предоставляет простой способ создания функций среза на основе значений признаков , которые можно предоставить как часть tfdv.StatsOptions при вычислении статистики.
Если срез включен, выходной прототип DatasetFeatureStatisticsList содержит несколько прототипов DatasetFeatureStatistics , по одному для каждого среза. Каждый срез идентифицируется уникальным именем, которое задается как имя набора данных в прототипе DatasetFeatureStatistics . По умолчанию TFDV вычисляет статистику для всего набора данных в дополнение к настроенным срезам.
import tensorflow_data_validation as tfdv
from tensorflow_data_validation.utils import slicing_util
# Slice on country feature (i.e., every unique value of the feature).
slice_fn1 = slicing_util.get_feature_value_slicer(features={'country': None})
# Slice on the cross of country and state feature (i.e., every unique pair of
# values of the cross).
slice_fn2 = slicing_util.get_feature_value_slicer(
features={'country': None, 'state': None})
# Slice on specific values of a feature.
slice_fn3 = slicing_util.get_feature_value_slicer(
features={'age': [10, 50, 70]})
stats_options = tfdv.StatsOptions(
slice_functions=[slice_fn1, slice_fn2, slice_fn3])