
공정성 지표는 보다 광범위한 Tensorflow 도구 키트와 함께 사용하여 공정성 문제에 대한 모델을 평가하고 개선하는 팀을 지원하도록 설계되었습니다. 이 도구는 현재 많은 제품에서 내부적으로 활발히 사용되고 있고, 이제 베타 버전으로 제공되므로 고유한 사례에 직접 사용해볼 수 있는 기회가 생겼습니다.
공정성 지표란?
공정성 지표는 바이너리 및 다중 클래스 분류자에서 일반적으로 볼 수 있는 공정성 메트릭을 쉽게 계산할 수 있도록 해주는 라이브러리입니다. 공정성 문제를 평가하기 위한 기존의 많은 도구는 대규모 데이터세트 및 모델에서 제대로 동작하지 않습니다. Google에서는 수십억 명의 사용자 시스템에서 동작할 수 있는 도구를 보유하는 것이 중요합니다. 공정성 지표를 사용하면 모든 규모의 사용 사례에서 평가가 가능합니다.
특히, 공정성 지표를 통해 다음이 가능합니다.
- 데이터세트의 분포 평가
- 정의된 사용자 그룹에 걸쳐 분할된 모델 성능 평가
- 여러 임계값에서 신뢰 구간 및 평가를 통해 결과에 대한 신뢰도 확인
- 개별 조각을 심층 분석하여 근본 원인과 개선 기회 모색
비디오 및 프로그래밍 실습이 모두 포함된 이 사례 연구는 공정성 지표를 고유 제품 중 하나에 사용하여 시간 경과에 따른 공정성 문제를 평가하는 방법을 보여줍니다.

pip 패키지 다운로드에는 다음이 포함됩니다.
- Tensorflow Data Validation(TFDV)
- Tensorflow Model Analysis(TFMA)
- 공정성 지표(Fairness Indicators)
- WIT(What-If 도구)
Tensorflow 모델에서 공정성 지표 사용하기
데이터
TFMA를 사용하여 공정성 지표를 실행하려면 평가 데이터세트에 분할하려는 특성에 대한 레이블이 지정되어 있어야 합니다. 공정성 문제에 대한 정확한 조각 특성이 없는 경우, 해당하는 평가 세트를 찾거나 결과 불일치를 부각시킬 수 있는 특성 세트 내에서 프록시 특성을 고려할 수 있습니다. 자세한 지침은 여기를 참조하세요.
모델
Tensorflow Estimator 클래스를 사용하여 모델을 빌드할 수 있습니다. Keras 모델에 대한 지원이 TFMA에 곧 제공될 예정입니다. Keras 모델에서 TFMA를 실행하려면, 아래 "모델에 구애받지 않는 TFMA" 섹션을 참조하세요.
Estimator를 훈련한 후에는 평가 목적으로 저장된 모델을 내보내야 합니다. 자세한 내용은 TFMA 가이드를 참조하세요.
조각 구성하기
다음으로, 평가할 조각을 정의합니다.
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur color’])
]
교차 조각(예: 털 색상 및 높이)를 평가하려는 경우, 다음을 설정할 수 있습니다.
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur_color’, ‘height’])
]`
공정성 메트릭 계산하기
metrics_callback 목록에 공정성 지표 콜백을 추가합니다. 콜백에서 모델이 평가될 임계값 목록을 정의할 수 있습니다.
from tensorflow_model_analysis.addons.fairness.post_export_metrics import fairness_indicators
# Build the fairness metrics. Besides the thresholds, you also can config the example_weight_key, labels_key here. For more details, please check the api.
metrics_callbacks = \
[tfma.post_export_metrics.fairness_indicators(thresholds=[0.1, 0.3,
0.5, 0.7, 0.9])]
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path=tfma_export_dir,
add_metrics_callbacks=metrics_callbacks)
구성을 실행하기 전에 신뢰 구간 계산을 사용할지 여부를 결정합니다. 신뢰 구간은 포아송(Poisson) 부트스트래핑을 사용하여 계산되며 20개 샘플에 대한 재계산이 필요합니다.
compute_confidence_intervals = True
TFMA 평가 파이프라인을 실행합니다.
validate_dataset = tf.data.TFRecordDataset(filenames=[validate_tf_file])
# Run the fairness evaluation.
with beam.Pipeline() as pipeline:
_ = (
pipeline
| beam.Create([v.numpy() for v in validate_dataset])
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
slice_spec=slice_spec,
compute_confidence_intervals=compute_confidence_intervals,
output_path=tfma_eval_result_path)
)
eval_result = tfma.load_eval_result(output_path=tfma_eval_result_path)
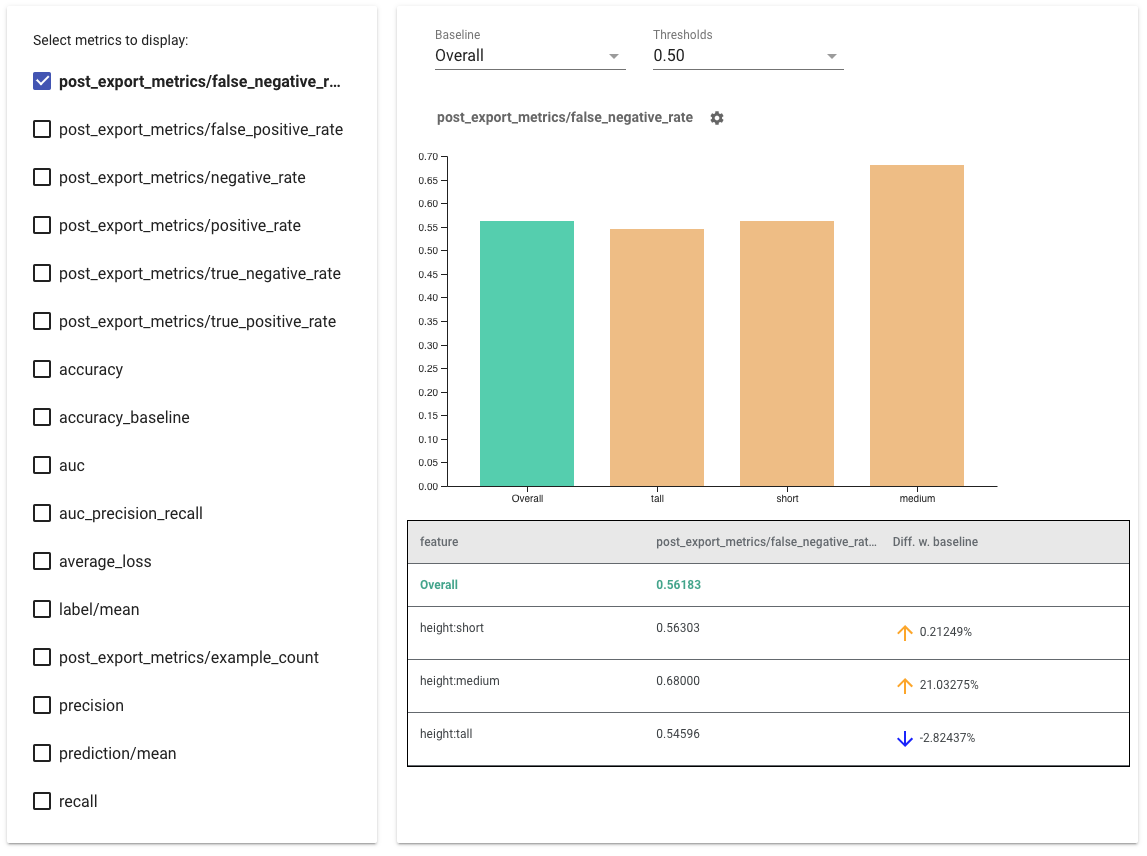
공정성 지표 렌더링하기
from tensorflow_model_analysis.addons.fairness.view import widget_view
widget_view.render_fairness_indicator(eval_result=eval_result)
공정성 지표 사용을 위한 팁:
- 왼쪽에 있는 상자를 선택하여 표시할 메트릭을 선택합니다. 각 메트릭에 대한 개별 그래프가 순서대로 위젯에 표시됩니다.
- 드롭다운 선택기를 사용하여 그래프의 첫 번째 막대인 기준선 조각을 변경합니다. 이 기준선 값을 이용해 델타가 계산됩니다.
- 드롭다운 선택기를 사용하여 임계값을 선택합니다. 같은 그래프에서 여러 임계값을 볼 수 있습니다. 선택한 임계값은 굵게 표시되며 굵게 표시된 임계값을 클릭하여 선택을 취소할 수 있습니다.
- 막대 위로 마우스를 가져가면 해당 조각에 대한 메트릭을 볼 수 있습니다.
- 현재 조각과 기준선 사이의 백분율 차이를 식별하는 "Diff w. baseline" 열을 사용하여 기준선과의 불일치를 확인합니다.
- What-If 도구를 사용하여 조각의 데이터 포인트를 심층적으로 검토합니다. 예를 보려면 여기를 확인하세요.
여러 모델에 대한 공정성 지표 렌더링하기
공정성 지표를 사용하여 모델을 비교할 수도 있습니다. 단일 eval_result를 전달하는 대신, 두 모델 이름을 eval_result 객체에 매핑하는 사전인 multi_eval_results 객체를 전달합니다.
from tensorflow_model_analysis.addons.fairness.view import widget_view
eval_result1 = tfma.load_eval_result(...)
eval_result2 = tfma.load_eval_result(...)
multi_eval_results = {"MyFirstModel": eval_result1, "MySecondModel": eval_result2}
widget_view.render_fairness_indicator(multi_eval_results=multi_eval_results)
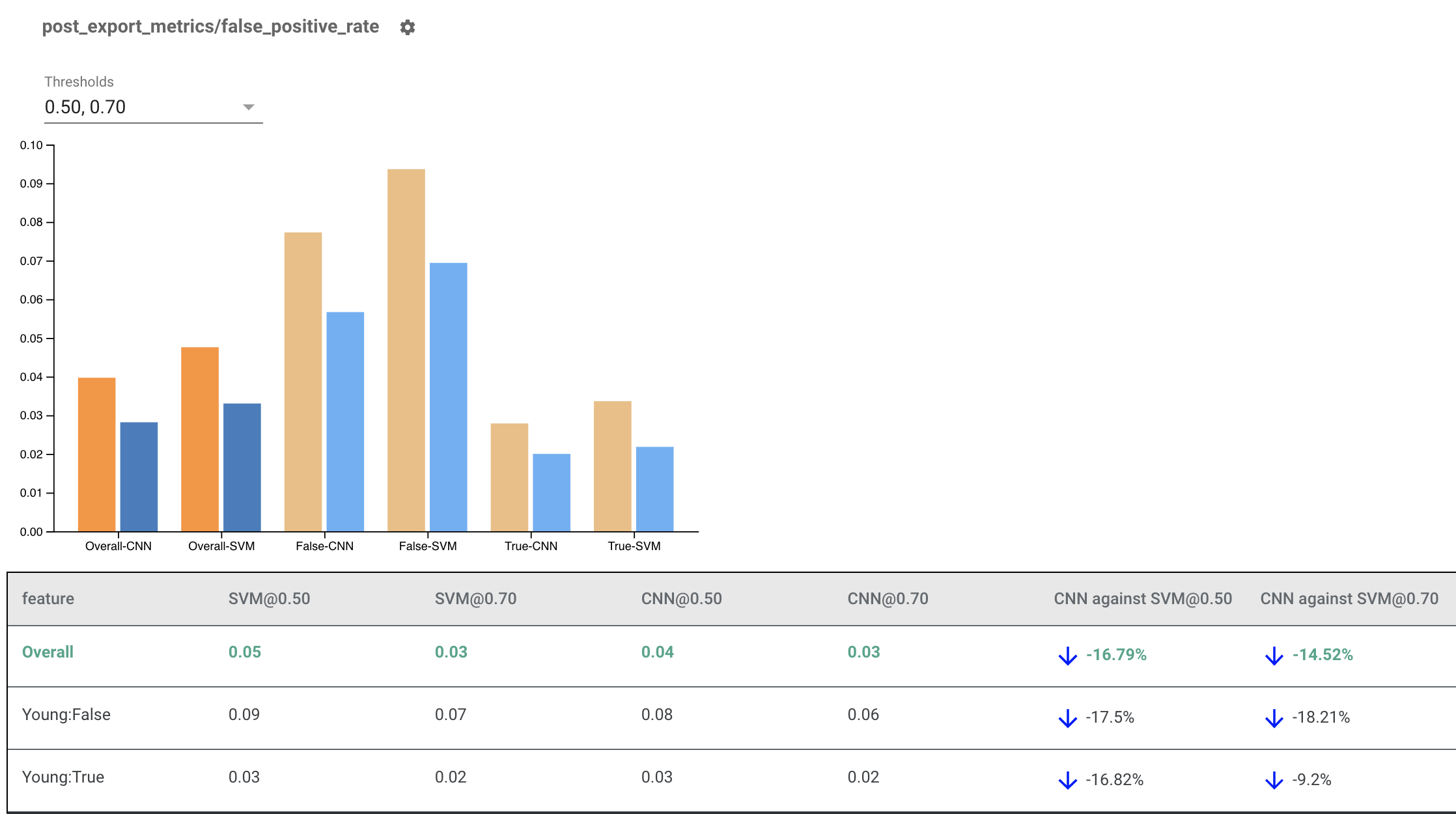
임계값 비교와 함께 모델 비교를 사용할 수 있습니다. 예를 들어, 두 임계값 세트에서 두 모델을 비교하여 공정성 메트릭에 대한 최적의 조합을 찾을 수 있습니다.
비 TensorFlow 모델에서 공정성 지표 사용하기
여러 모델과 워크플로를 가진 클라이언트를 보다 잘 지원하기 위해 평가 중인 모델에 구애받지 않는 평가 라이브러리를 개발했습니다.
머신러닝 시스템을 평가하려는 사람은 누구나 이 라이브러리를 사용할 수 있습니다. 특히, TensorFlow 기반이 아닌 모델을 사용하는 경우에 유용합니다. Apache Beam Python SDK를 사용하면 독립형 TFMA 평가 바이너리를 만든 다음 실행하여 모델을 분석할 수 있습니다.
데이터
이 단계에서는 평가를 실행할 데이터세트를 제공합니다. 이 데이터세트는 레이블, 예측값 및 조각으로 분할하려는 기타 특성이 있는 tf.Example proto 형식이어야 합니다.
tf.Example {
features {
feature {
key: "fur_color" value { bytes_list { value: "gray" } }
}
feature {
key: "height" value { bytes_list { value: "tall" } }
}
feature {
key: "prediction" value { float_list { value: 0.9 } }
}
feature {
key: "label" value { float_list { value: 1.0 } }
}
}
}
모델
모델을 지정하는 대신, 모델에 구애받지 않는 평가 구성과 추출기를 생성하여 TFMA가 메트릭을 계산하는 데 필요한 데이터를 구문 분석하고 제공합니다. ModelAgnosticConfig 사양은 입력 예에서 사용할 특성, 예측값 및 레이블을 정의합니다.
이를 위해 레이블 및 예측 키를 포함한 모든 특성을 나타내는 키와 특성의 데이터 유형을 나타내는 값으로 특성 맵을 만듭니다.
feature_map[label_key] = tf.FixedLenFeature([], tf.float32, default_value=[0])
레이블 키, 예측 키 및 특성 맵을 사용하여 모델에 구애받지 않는 구성을 만듭니다.
model_agnostic_config = model_agnostic_predict.ModelAgnosticConfig(
label_keys=list(ground_truth_labels),
prediction_keys=list(predition_labels),
feature_spec=feature_map)
모델에 구애받지 않는 추출기 설정하기
추출기는 모델에 구애받지 않는 구성을 사용하여 입력에서 특성, 레이블 및 예측값을 추출하는 데 사용됩니다. 데이터를 조각화하려면 조각화할 열에 대한 정보를 포함하는 조각 키 사양도 정의해야 합니다.
model_agnostic_extractors = [
model_agnostic_extractor.ModelAgnosticExtractor(
model_agnostic_config=model_agnostic_config, desired_batch_size=3),
slice_key_extractor.SliceKeyExtractor([
slicer.SingleSliceSpec(),
slicer.SingleSliceSpec(columns=[‘height’]),
])
]
공정성 메트릭 계산하기
EvalSharedModel의 일부로 모델을 평가할 모든 메트릭을 제공할 수 있습니다. 메트릭은 post_export_metrics 또는 fairness_indicators에 정의된 것과 같은 메트릭 콜백의 형태로 제공됩니다.
metrics_callbacks.append(
post_export_metrics.fairness_indicators(
thresholds=[0.5, 0.9],
target_prediction_keys=[prediction_key],
labels_key=label_key))
평가를 수행하하기 위해 tensorflow 그래프를 만드는 데 사용되는 construct_fn도 입력으로 받습니다.
eval_shared_model = types.EvalSharedModel(
add_metrics_callbacks=metrics_callbacks,
construct_fn=model_agnostic_evaluate_graph.make_construct_fn(
add_metrics_callbacks=metrics_callbacks,
fpl_feed_config=model_agnostic_extractor
.ModelAgnosticGetFPLFeedConfig(model_agnostic_config)))
설정이 모두 끝나면 model_eval_lib에서 제공하는 ExtractEvaluate 또는 ExtractEvaluateAndWriteResults 함수 중 하나를 사용하여 모델을 평가합니다.
_ = (
examples |
'ExtractEvaluateAndWriteResults' >>
model_eval_lib.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
output_path=output_path,
extractors=model_agnostic_extractors))
eval_result = tensorflow_model_analysis.load_eval_result(output_path=tfma_eval_result_path)
마지막으로, 위의 "공정성 지표 렌더링하기" 섹션의 지침에 따라 공정성 지표를 렌더링합니다.
더 많은 예
공정성 지표 예제 디렉토리에 몇 가지 예제가 포함되어 있습니다.
- Fairness_Indicators_Example_Colab.ipynb는 TensorFlow 모델 분석의 공정성 지표에 대한 개요와 이를 실제 데이터세트와 함께 사용하는 방법을 제공합니다. 이 노트북에서는 또한 공정성 지표가 함께 구성된 TensorFlow 모델을 분석하기 위한 두 가지 도구인 TensorFlow 데이터 검증 및 What-If 도구에 대한 내용도 다룹니다.
- Fairness_Indicators_on_TF_Hub.ipynb는 다른 여러 텍스트 임베딩에서 훈련된 모델을 비교하기 위해 공정성 지표를 사용하는 방법을 보여줍니다. 이 노트북은 TensorFlow 라이브러리인 TensorFlow Hub의 텍스트 임베딩을 사용하여 모델 구성 요소를 게시, 검색 및 재사용합니다.
- Fairness_Indicators_TensorBoard_Plugin_Example_Colab.ipynb는 TensorBoard에서 공정성 지표를 시각화하는 방법을 보여줍니다.