
تم تصميم مؤشرات العدالة لدعم الفرق في تقييم وتحسين النماذج المتعلقة بمخاوف العدالة بالشراكة مع مجموعة أدوات Tensorflow الأوسع. يتم حاليًا استخدام الأداة بشكل نشط داخليًا بواسطة العديد من منتجاتنا، وهي متاحة الآن في الإصدار التجريبي لتجربة حالات الاستخدام الخاصة بك.
ما هي مؤشرات العدالة؟
مؤشرات الإنصاف هي مكتبة تتيح الحساب السهل لمقاييس الإنصاف المحددة بشكل شائع للمصنفات الثنائية ومتعددة الفئات. العديد من الأدوات الحالية لتقييم المخاوف المتعلقة بالعدالة لا تعمل بشكل جيد مع مجموعات البيانات والنماذج واسعة النطاق. في Google، من المهم بالنسبة لنا أن يكون لدينا أدوات يمكنها العمل على أنظمة تضم مليار مستخدم. ستسمح لك مؤشرات العدالة بالتقييم عبر أي حجم لحالة الاستخدام.
وعلى وجه الخصوص، تتضمن مؤشرات العدالة القدرة على:
- تقييم توزيع مجموعات البيانات
- تقييم أداء النموذج، مقسمًا إلى مجموعات محددة من المستخدمين
- اشعر بالثقة بشأن نتائجك من خلال فترات الثقة والتقييمات عند عتبات متعددة
- تعمق في الشرائح الفردية لاستكشاف الأسباب الجذرية وفرص التحسين
يتضمن تنزيل حزمة النقطة ما يلي:
- التحقق من صحة بيانات Tensorflow (TFDV)
- تحليل نموذج Tensorflow (TFMA)
- مؤشرات العدالة
- أداة ماذا لو (WIT)
استخدام مؤشرات العدالة مع نماذج Tensorflow
بيانات
لتشغيل مؤشرات العدالة باستخدام TFMA، تأكد من تصنيف مجموعة بيانات التقييم للميزات التي ترغب في تقسيمها. إذا لم تكن لديك ميزات الشريحة الدقيقة لمخاوفك المتعلقة بالعدالة، فيمكنك استكشاف محاولة العثور على مجموعة تقييم توفر ذلك، أو التفكير في ميزات الوكيل ضمن مجموعة الميزات الخاصة بك والتي قد تسلط الضوء على تباينات النتائج. للحصول على إرشادات إضافية، انظر هنا .
نموذج
يمكنك استخدام فئة Tensorflow Estimator لبناء النموذج الخاص بك. سيتوفر الدعم لنماذج Keras قريبًا إلى TFMA. إذا كنت ترغب في تشغيل TFMA على طراز Keras، فيرجى الاطلاع على قسم "TFMA غير النموذجي" أدناه.
بعد تدريب المقدر الخاص بك، ستحتاج إلى تصدير نموذج محفوظ لأغراض التقييم. لمعرفة المزيد، راجع دليل TFMA .
تكوين الشرائح
بعد ذلك، حدد الشرائح التي ترغب في تقييمها:
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur color’])
]
إذا كنت تريد تقييم الشرائح المتقاطعة (على سبيل المثال، لون الفراء وارتفاعه)، فيمكنك تعيين ما يلي:
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur_color’, ‘height’])
]`
حساب مقاييس العدالة
أضف رد اتصال مؤشرات الإنصاف إلى قائمة metrics_callback . في رد الاتصال، يمكنك تحديد قائمة بالحدود التي سيتم تقييم النموذج عندها.
from tensorflow_model_analysis.addons.fairness.post_export_metrics import fairness_indicators
# Build the fairness metrics. Besides the thresholds, you also can config the example_weight_key, labels_key here. For more details, please check the api.
metrics_callbacks = \
[tfma.post_export_metrics.fairness_indicators(thresholds=[0.1, 0.3,
0.5, 0.7, 0.9])]
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path=tfma_export_dir,
add_metrics_callbacks=metrics_callbacks)
قبل تشغيل التكوين، حدد ما إذا كنت تريد تمكين حساب فترات الثقة أم لا. يتم حساب فترات الثقة باستخدام Poisson bootstrapping وتتطلب إعادة حساب أكثر من 20 عينة.
compute_confidence_intervals = True
قم بتشغيل مسار تقييم TFMA:
validate_dataset = tf.data.TFRecordDataset(filenames=[validate_tf_file])
# Run the fairness evaluation.
with beam.Pipeline() as pipeline:
_ = (
pipeline
| beam.Create([v.numpy() for v in validate_dataset])
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
slice_spec=slice_spec,
compute_confidence_intervals=compute_confidence_intervals,
output_path=tfma_eval_result_path)
)
eval_result = tfma.load_eval_result(output_path=tfma_eval_result_path)
تقديم مؤشرات العدالة
from tensorflow_model_analysis.addons.fairness.view import widget_view
widget_view.render_fairness_indicator(eval_result=eval_result)
نصائح لاستخدام مؤشرات العدالة:
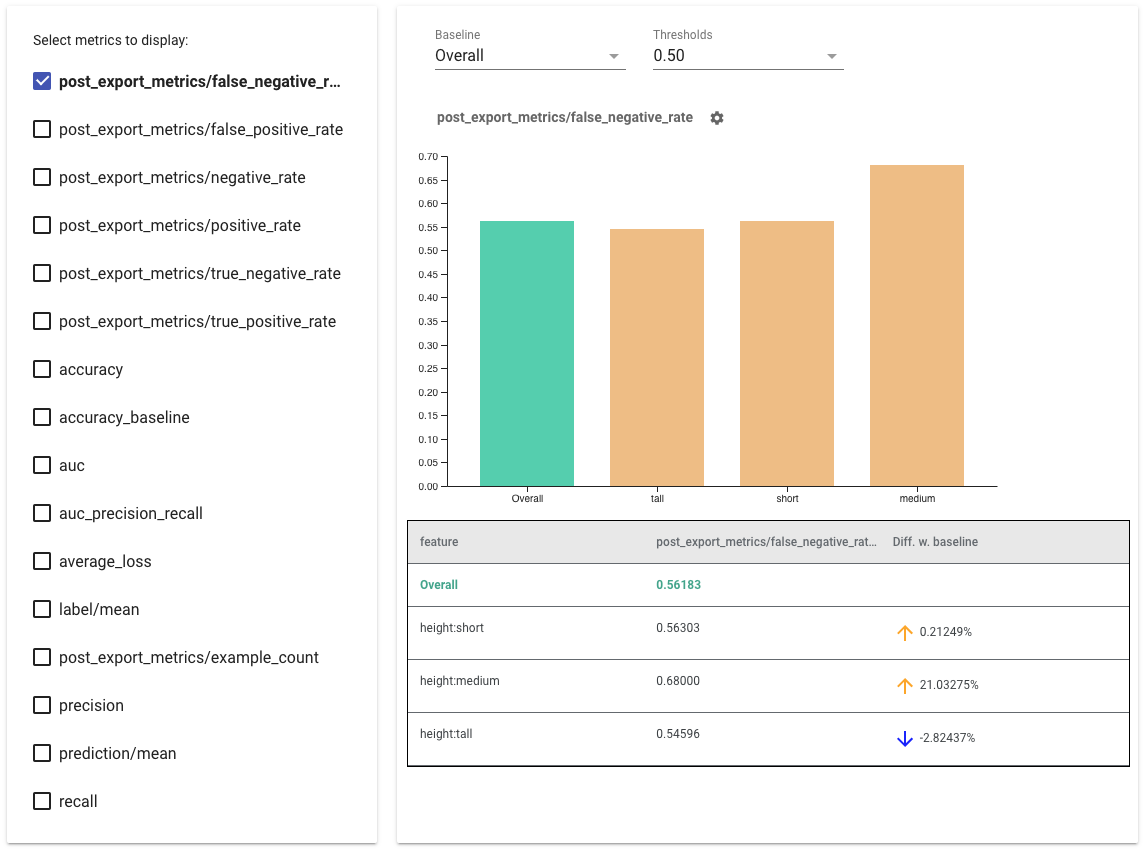
- حدد المقاييس التي تريد عرضها عن طريق تحديد المربعات الموجودة على الجانب الأيسر. ستظهر الرسوم البيانية الفردية لكل من المقاييس في الأداة بالترتيب.
- قم بتغيير الشريحة الأساسية ، الشريط الأول في الرسم البياني، باستخدام محدد القائمة المنسدلة. سيتم حساب الدلتا باستخدام قيمة خط الأساس هذه.
- حدد العتبات باستخدام محدد القائمة المنسدلة. يمكنك عرض عتبات متعددة على نفس الرسم البياني. ستكون الحدود المحددة بالخط العريض، ويمكنك النقر فوق الحد الغامق لإلغاء تحديده.
- قم بالتمرير فوق أحد الأشرطة لرؤية مقاييس تلك الشريحة.
- تحديد التباينات مع خط الأساس باستخدام العمود "Diff w. baseline"، الذي يحدد النسبة المئوية للفرق بين الشريحة الحالية وخط الأساس.
- استكشف نقاط البيانات الخاصة بالشريحة بعمق باستخدام أداة What-If . انظر هنا للحصول على مثال.
تقديم مؤشرات العدالة لنماذج متعددة
يمكن أيضًا استخدام مؤشرات العدالة لمقارنة النماذج. بدلاً من تمرير eval_result واحد، قم بتمرير كائن multi_eval_results، وهو عبارة عن قاموس يقوم بتعيين اسمي نموذجين لكائنات eval_result.
from tensorflow_model_analysis.addons.fairness.view import widget_view
eval_result1 = tfma.load_eval_result(...)
eval_result2 = tfma.load_eval_result(...)
multi_eval_results = {"MyFirstModel": eval_result1, "MySecondModel": eval_result2}
widget_view.render_fairness_indicator(multi_eval_results=multi_eval_results)
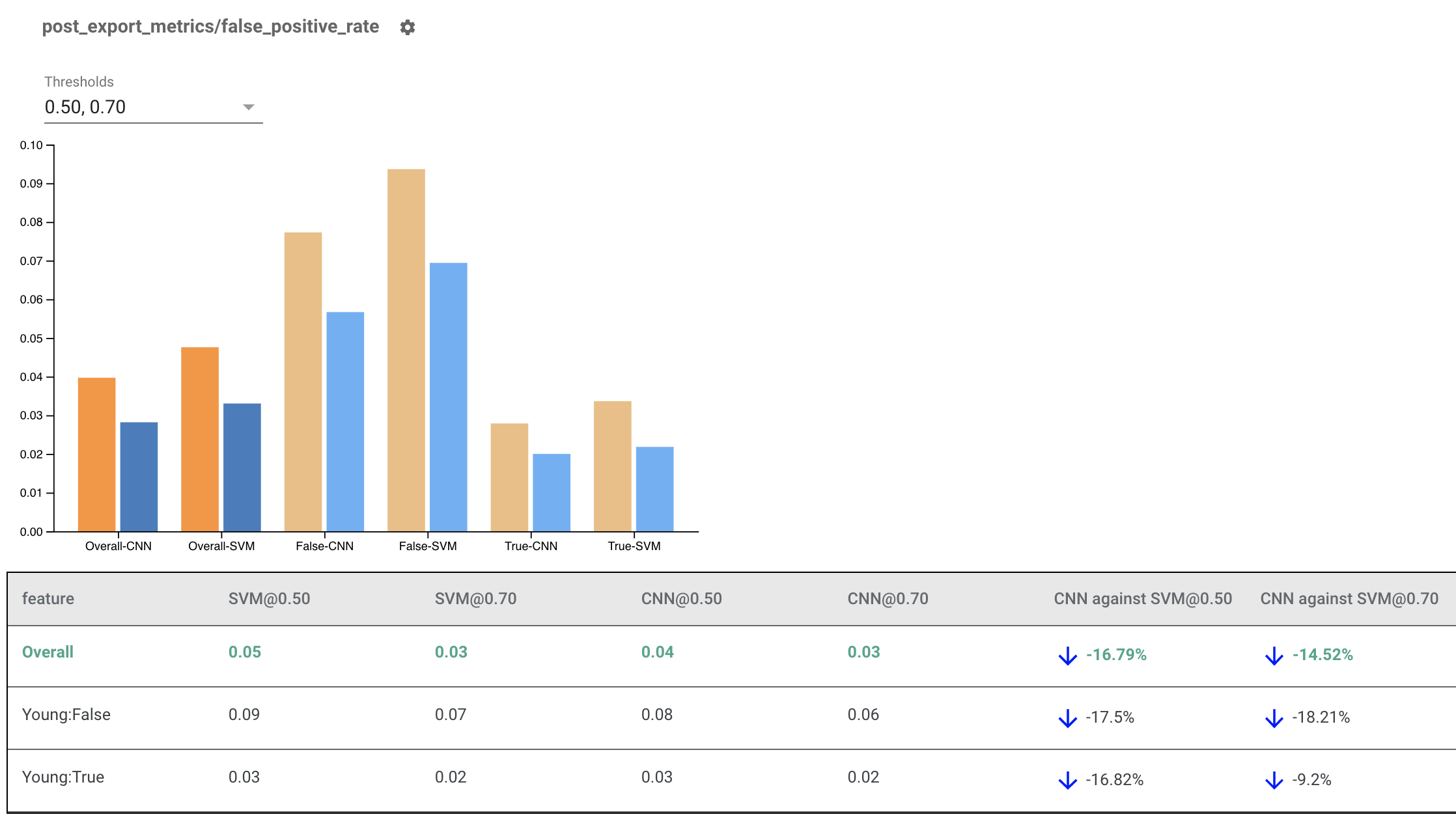
يمكن استخدام مقارنة النماذج جنبًا إلى جنب مع مقارنة العتبة. على سبيل المثال، يمكنك مقارنة نموذجين في مجموعتين من الحدود للعثور على المجموعة المثالية لمقاييس الإنصاف الخاصة بك.
استخدام مؤشرات الإنصاف مع نماذج غير TensorFlow
لدعم العملاء الذين لديهم نماذج وسير عمل مختلفة بشكل أفضل، قمنا بتطوير مكتبة تقييم لا تتفق مع النموذج الذي يتم تقييمه.
يمكن لأي شخص يريد تقييم نظام التعلم الآلي الخاص به استخدام هذا، خاصة إذا كان لديك نماذج غير مستندة إلى TensorFlow. باستخدام Apache Beam Python SDK، يمكنك إنشاء ثنائي تقييم TFMA مستقل ثم تشغيله لتحليل النموذج الخاص بك.
بيانات
تهدف هذه الخطوة إلى توفير مجموعة البيانات التي تريد تشغيل التقييمات عليها. يجب أن يكون بتنسيق tf.Example proto الذي يحتوي على تسميات وتنبؤات وميزات أخرى قد ترغب في تقسيمها.
tf.Example {
features {
feature {
key: "fur_color" value { bytes_list { value: "gray" } }
}
feature {
key: "height" value { bytes_list { value: "tall" } }
}
feature {
key: "prediction" value { float_list { value: 0.9 } }
}
feature {
key: "label" value { float_list { value: 1.0 } }
}
}
}
نموذج
بدلاً من تحديد نموذج، يمكنك إنشاء تكوين تقييم غير محدد للنموذج ومستخرج لتحليل وتوفير البيانات التي يحتاجها TFMA لحساب المقاييس. تحدد مواصفات ModelAgnosticConfig الميزات والتنبؤات والتسميات التي سيتم استخدامها من أمثلة الإدخال.
لهذا، قم بإنشاء خريطة المعالم بمفاتيح تمثل جميع الميزات بما في ذلك مفاتيح التسمية والتنبؤ والقيم التي تمثل نوع بيانات الميزة.
feature_map[label_key] = tf.FixedLenFeature([], tf.float32, default_value=[0])
قم بإنشاء تكوين غير محدد للنموذج باستخدام مفاتيح التسمية ومفاتيح التنبؤ وخريطة الميزات.
model_agnostic_config = model_agnostic_predict.ModelAgnosticConfig(
label_keys=list(ground_truth_labels),
prediction_keys=list(predition_labels),
feature_spec=feature_map)
إعداد النازع الملحد النموذجي
يتم استخدام النازع لاستخراج الميزات والتسميات والتنبؤات من المدخلات باستخدام التكوين الحيادي للنموذج. وإذا كنت تريد تقسيم بياناتك إلى شرائح، فأنت بحاجة أيضًا إلى تحديد مواصفات مفتاح الشريحة ، التي تحتوي على معلومات حول الأعمدة التي تريد تقسيمها.
model_agnostic_extractors = [
model_agnostic_extractor.ModelAgnosticExtractor(
model_agnostic_config=model_agnostic_config, desired_batch_size=3),
slice_key_extractor.SliceKeyExtractor([
slicer.SingleSliceSpec(),
slicer.SingleSliceSpec(columns=[‘height’]),
])
]
حساب مقاييس العدالة
كجزء من EvalSharedModel ، يمكنك توفير جميع المقاييس التي تريد تقييم نموذجك عليها. يتم توفير المقاييس في شكل ردود اتصال للمقاييس مثل تلك المحددة في post_export_metrics أو fairness_indicators .
metrics_callbacks.append(
post_export_metrics.fairness_indicators(
thresholds=[0.5, 0.9],
target_prediction_keys=[prediction_key],
labels_key=label_key))
كما أنه يأخذ construct_fn الذي يتم استخدامه لإنشاء رسم بياني لتدفق Tensorflow لإجراء التقييم.
eval_shared_model = types.EvalSharedModel(
add_metrics_callbacks=metrics_callbacks,
construct_fn=model_agnostic_evaluate_graph.make_construct_fn(
add_metrics_callbacks=metrics_callbacks,
fpl_feed_config=model_agnostic_extractor
.ModelAgnosticGetFPLFeedConfig(model_agnostic_config)))
بمجرد إعداد كل شيء، استخدم إحدى وظائف ExtractEvaluate أو ExtractEvaluateAndWriteResults التي توفرها model_eval_lib لتقييم النموذج.
_ = (
examples |
'ExtractEvaluateAndWriteResults' >>
model_eval_lib.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
output_path=output_path,
extractors=model_agnostic_extractors))
eval_result = tensorflow_model_analysis.load_eval_result(output_path=tfma_eval_result_path)
وأخيرًا، قم بتقديم مؤشرات الإنصاف باستخدام الإرشادات الواردة في قسم "تقديم مؤشرات الإنصاف" أعلاه.
المزيد من الأمثلة
يحتوي دليل أمثلة مؤشرات الإنصاف على عدة أمثلة:
- يقدم Fairness_Indicators_Example_Colab.ipynb نظرة عامة على مؤشرات العدالة في تحليل نموذج TensorFlow وكيفية استخدامها مع مجموعة بيانات حقيقية. يتناول هذا الكمبيوتر الدفتري أيضًا التحقق من صحة بيانات TensorFlow وأداة What-If ، وهما أداتان لتحليل نماذج TensorFlow المزودة بمؤشرات العدالة.
- يوضح Fairness_Indicators_on_TF_Hub.ipynb كيفية استخدام مؤشرات Fairness لمقارنة النماذج التي تم تدريبها على تضمينات نصية مختلفة. يستخدم هذا الكمبيوتر الدفتري تضمينات نصية من TensorFlow Hub ، مكتبة TensorFlow لنشر مكونات النموذج واكتشافها وإعادة استخدامها.
- Fairness_Indicators_TensorBoard_Plugin_Example_Colab.ipynb يوضح كيفية تصور مؤشرات العدالة في TensorBoard.