
ML Metadata (MLMD) é uma biblioteca para registrar e recuperar metadados associados a fluxos de trabalho de desenvolvedores de ML e cientistas de dados. O MLMD é parte integrante do TensorFlow Extended (TFX) , mas foi projetado para que possa ser usado de forma independente.
Cada execução de um pipeline de ML de produção gera metadados contendo informações sobre os vários componentes do pipeline, suas execuções (por exemplo, execuções de treinamento) e artefatos resultantes (por exemplo, modelos treinados). No caso de erros ou comportamento inesperado do pipeline, esses metadados podem ser aproveitados para analisar a linhagem dos componentes do pipeline e depurar problemas. Pense nesses metadados como o equivalente ao registro no desenvolvimento de software.
O MLMD ajuda você a compreender e analisar todas as partes interconectadas do seu pipeline de ML, em vez de analisá-las isoladamente, e pode ajudá-lo a responder perguntas sobre o seu pipeline de ML, como:
- Em qual conjunto de dados o modelo foi treinado?
- Quais foram os hiperparâmetros usados para treinar o modelo?
- Qual execução de pipeline criou o modelo?
- Qual treinamento levou a esse modelo?
- Qual versão do TensorFlow criou este modelo?
- Quando o modelo fracassado foi empurrado?
Armazenamento de metadados
O MLMD registra os seguintes tipos de metadados em um banco de dados chamado Metadata Store .
- Metadados sobre os artefatos gerados por meio dos componentes/etapas dos seus pipelines de ML
- Metadados sobre as execuções desses componentes/etapas
- Metadados sobre pipelines e informações de linhagem associadas
O Metadata Store fornece APIs para registrar e recuperar metadados de e para o back-end de armazenamento. O back-end de armazenamento é conectável e pode ser estendido. O MLMD fornece implementações de referência para SQLite (que suporta memória e disco) e MySQL prontos para uso.
Este gráfico mostra uma visão geral resumida dos vários componentes que fazem parte do MLMD.
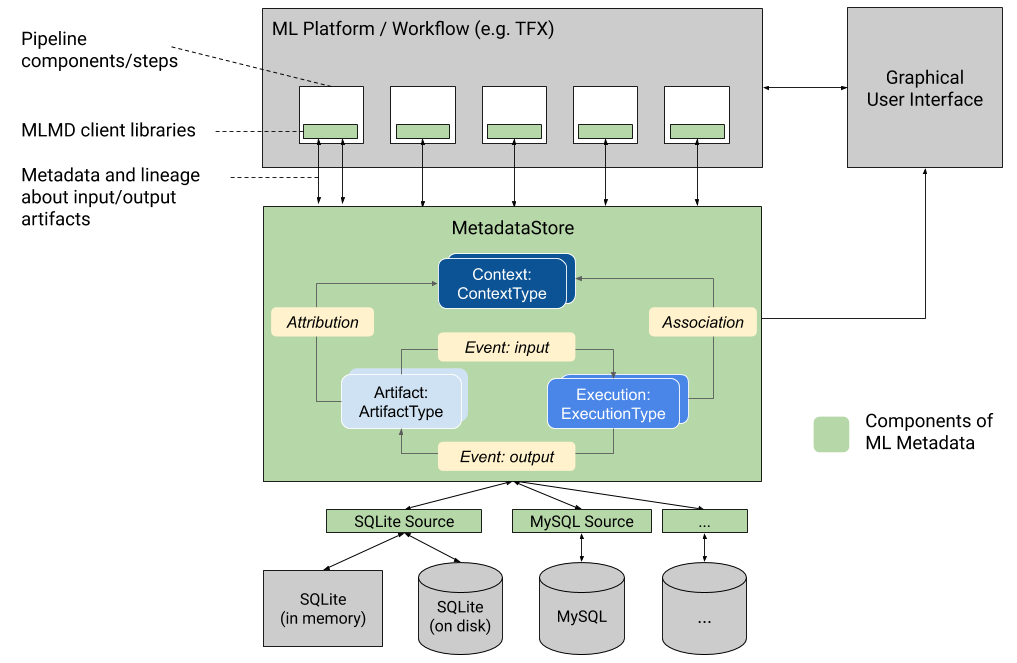
Back-ends de armazenamento de metadados e configuração de conexão de armazenamento
O objeto MetadataStore recebe uma configuração de conexão que corresponde ao backend de armazenamento utilizado.
- O Fake Database fornece um banco de dados na memória (usando SQLite) para experimentação rápida e execuções locais. O banco de dados é excluído quando o objeto de armazenamento é destruído.
import ml_metadata as mlmd
from ml_metadata.metadata_store import metadata_store
from ml_metadata.proto import metadata_store_pb2
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.fake_database.SetInParent() # Sets an empty fake database proto.
store = metadata_store.MetadataStore(connection_config)
- SQLite lê e grava arquivos do disco.
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.sqlite.filename_uri = '...'
connection_config.sqlite.connection_mode = 3 # READWRITE_OPENCREATE
store = metadata_store.MetadataStore(connection_config)
- MySQL se conecta a um servidor MySQL.
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.mysql.host = '...'
connection_config.mysql.port = '...'
connection_config.mysql.database = '...'
connection_config.mysql.user = '...'
connection_config.mysql.password = '...'
store = metadata_store.MetadataStore(connection_config)
Da mesma forma, ao usar uma instância MySQL com Google CloudSQL ( quickstart , connect-overview ), também é possível usar a opção SSL, se aplicável.
connection_config.mysql.ssl_options.key = '...'
connection_config.mysql.ssl_options.cert = '...'
connection_config.mysql.ssl_options.ca = '...'
connection_config.mysql.ssl_options.capath = '...'
connection_config.mysql.ssl_options.cipher = '...'
connection_config.mysql.ssl_options.verify_server_cert = '...'
store = metadata_store.MetadataStore(connection_config)
- PostgreSQL se conecta a um servidor PostgreSQL.
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.postgresql.host = '...'
connection_config.postgresql.port = '...'
connection_config.postgresql.user = '...'
connection_config.postgresql.password = '...'
connection_config.postgresql.dbname = '...'
store = metadata_store.MetadataStore(connection_config)
Da mesma forma, ao usar uma instância PostgreSQL com Google CloudSQL ( quickstart , connect-overview ), também é possível usar a opção SSL, se aplicável.
connection_config.postgresql.ssloption.sslmode = '...' # disable, allow, verify-ca, verify-full, etc.
connection_config.postgresql.ssloption.sslcert = '...'
connection_config.postgresql.ssloption.sslkey = '...'
connection_config.postgresql.ssloption.sslpassword = '...'
connection_config.postgresql.ssloption.sslrootcert = '...'
store = metadata_store.MetadataStore(connection_config)
Modelo de dados
O Armazenamento de Metadados usa o modelo de dados a seguir para registrar e recuperar metadados do back-end de armazenamento.
-
ArtifactTypedescreve o tipo de artefato e suas propriedades armazenadas no armazenamento de metadados. Você pode registrar esses tipos dinamicamente com o armazenamento de metadados em código ou pode carregá-los no armazenamento a partir de um formato serializado. Depois de registrar um tipo, sua definição fica disponível durante todo o tempo de vida da loja. - Um
Artifactdescreve uma instância específica de umArtifactTypee suas propriedades que são gravadas no armazenamento de metadados. - Um
ExecutionTypedescreve um tipo de componente ou etapa em um fluxo de trabalho e seus parâmetros de tempo de execução. - Uma
Executioné um registro da execução de um componente ou de uma etapa em um fluxo de trabalho de ML e dos parâmetros de tempo de execução. Uma execução pode ser considerada uma instância deExecutionType. As execuções são registradas quando você executa um pipeline ou etapa de ML. - Um
Eventé um registro do relacionamento entre artefatos e execuções. Quando ocorre uma execução, os eventos registram todos os artefatos usados pela execução e todos os artefatos produzidos. Esses registros permitem o rastreamento de linhagem em todo um fluxo de trabalho. Ao observar todos os eventos, o MLMD sabe quais execuções aconteceram e quais artefatos foram criados como resultado. O MLMD pode então recorrer de qualquer artefato para todas as suas entradas upstream. - Um
ContextTypedescreve um tipo de grupo conceitual de artefatos e execuções em um fluxo de trabalho e suas propriedades estruturais. Por exemplo: projetos, execuções de pipeline, experimentos, proprietários etc. - Um
Contexté uma instância de umContextType. Ele captura as informações compartilhadas dentro do grupo. Por exemplo: nome do projeto, ID de commit da lista de alterações, anotações de experimentos, etc. Ele possui um nome exclusivo definido pelo usuário em seuContextType. - Uma
Attributioné um registro do relacionamento entre artefatos e contextos. - Uma
Associationé um registro do relacionamento entre execuções e contextos.
Funcionalidade MLMD
Rastrear as entradas e saídas de todos os componentes/etapas em um fluxo de trabalho de ML e sua linhagem permite que as plataformas de ML habilitem vários recursos importantes. A lista a seguir fornece uma visão geral não exaustiva de alguns dos principais benefícios.
- Liste todos os artefatos de um tipo específico. Exemplo: todos os modelos que foram treinados.
- Carregue dois artefatos do mesmo tipo para comparação. Exemplo: compare resultados de dois experimentos.
- Mostre um DAG de todas as execuções relacionadas e seus artefatos de entrada e saída de um contexto. Exemplo: visualize o fluxo de trabalho de um experimento para depuração e descoberta.
- Recorra a todos os eventos para ver como um artefato foi criado. Exemplos: veja quais dados foram inseridos em um modelo; aplicar planos de retenção de dados.
- Identifique todos os artefatos que foram criados usando um determinado artefato. Exemplos: veja todos os modelos treinados a partir de um conjunto de dados específico; marcar modelos com base em dados incorretos.
- Determine se uma execução já foi executada nas mesmas entradas antes. Exemplo: determine se um componente/etapa já concluiu o mesmo trabalho e a saída anterior pode apenas ser reutilizada.
- Registrar e consultar o contexto das execuções do fluxo de trabalho. Exemplos: rastrear o proprietário e a lista de alterações usados para uma execução de fluxo de trabalho; agrupar a linhagem por experimentos; gerenciar artefatos por projetos.
- Capacidades de filtragem de nós declarativos em propriedades e nós de vizinhança de 1 salto. Exemplos: procure artefatos de um tipo e em algum contexto de pipeline; retornar artefatos digitados onde o valor de uma determinada propriedade está dentro de um intervalo; encontre execuções anteriores em um contexto com as mesmas entradas.
Consulte o tutorial do MLMD para obter um exemplo que mostra como usar a API do MLMD e o armazenamento de metadados para recuperar informações de linhagem.
Integre metadados de ML em seus fluxos de trabalho de ML
Se você for um desenvolvedor de plataforma interessado em integrar o MLMD ao seu sistema, use o exemplo de fluxo de trabalho abaixo para usar as APIs do MLMD de baixo nível para rastrear a execução de uma tarefa de treinamento. Você também pode usar APIs Python de nível superior em ambientes de notebook para registrar metadados de experimentos.
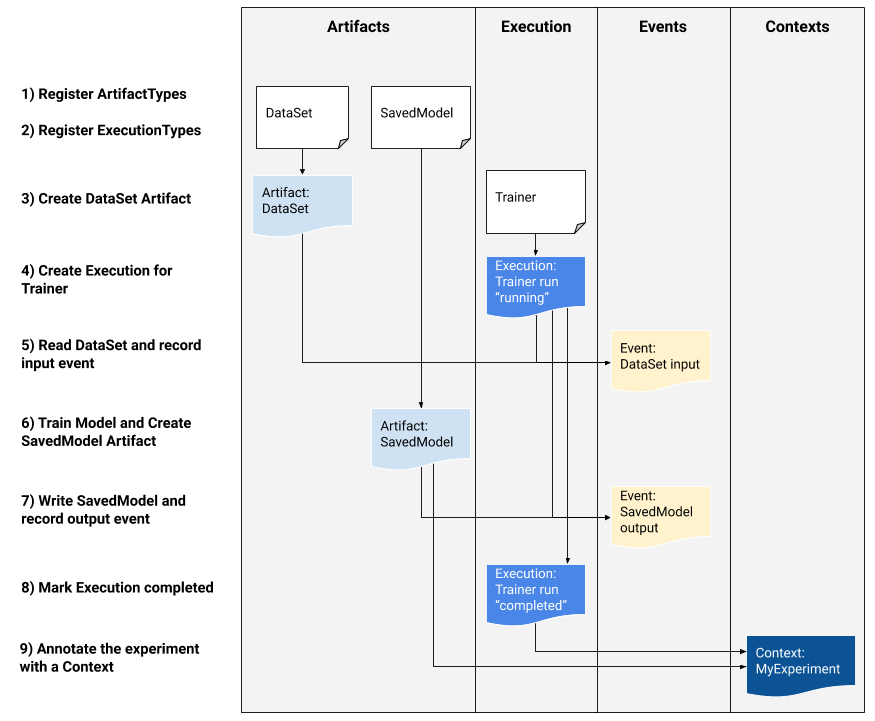
1) Registre tipos de artefatos
# Create ArtifactTypes, e.g., Data and Model
data_type = metadata_store_pb2.ArtifactType()
data_type.name = "DataSet"
data_type.properties["day"] = metadata_store_pb2.INT
data_type.properties["split"] = metadata_store_pb2.STRING
data_type_id = store.put_artifact_type(data_type)
model_type = metadata_store_pb2.ArtifactType()
model_type.name = "SavedModel"
model_type.properties["version"] = metadata_store_pb2.INT
model_type.properties["name"] = metadata_store_pb2.STRING
model_type_id = store.put_artifact_type(model_type)
# Query all registered Artifact types.
artifact_types = store.get_artifact_types()
2) Registre os tipos de execução para todas as etapas do fluxo de trabalho de ML
# Create an ExecutionType, e.g., Trainer
trainer_type = metadata_store_pb2.ExecutionType()
trainer_type.name = "Trainer"
trainer_type.properties["state"] = metadata_store_pb2.STRING
trainer_type_id = store.put_execution_type(trainer_type)
# Query a registered Execution type with the returned id
[registered_type] = store.get_execution_types_by_id([trainer_type_id])
3) Crie um artefato de DataSet ArtifactType
# Create an input artifact of type DataSet
data_artifact = metadata_store_pb2.Artifact()
data_artifact.uri = 'path/to/data'
data_artifact.properties["day"].int_value = 1
data_artifact.properties["split"].string_value = 'train'
data_artifact.type_id = data_type_id
[data_artifact_id] = store.put_artifacts([data_artifact])
# Query all registered Artifacts
artifacts = store.get_artifacts()
# Plus, there are many ways to query the same Artifact
[stored_data_artifact] = store.get_artifacts_by_id([data_artifact_id])
artifacts_with_uri = store.get_artifacts_by_uri(data_artifact.uri)
artifacts_with_conditions = store.get_artifacts(
list_options=mlmd.ListOptions(
filter_query='uri LIKE "%/data" AND properties.day.int_value > 0'))
4) Crie uma execução da execução do Trainer
# Register the Execution of a Trainer run
trainer_run = metadata_store_pb2.Execution()
trainer_run.type_id = trainer_type_id
trainer_run.properties["state"].string_value = "RUNNING"
[run_id] = store.put_executions([trainer_run])
# Query all registered Execution
executions = store.get_executions_by_id([run_id])
# Similarly, the same execution can be queried with conditions.
executions_with_conditions = store.get_executions(
list_options = mlmd.ListOptions(
filter_query='type = "Trainer" AND properties.state.string_value IS NOT NULL'))
5) Defina o evento de entrada e leia os dados
# Define the input event
input_event = metadata_store_pb2.Event()
input_event.artifact_id = data_artifact_id
input_event.execution_id = run_id
input_event.type = metadata_store_pb2.Event.DECLARED_INPUT
# Record the input event in the metadata store
store.put_events([input_event])
6) Declare o artefato de saída
# Declare the output artifact of type SavedModel
model_artifact = metadata_store_pb2.Artifact()
model_artifact.uri = 'path/to/model/file'
model_artifact.properties["version"].int_value = 1
model_artifact.properties["name"].string_value = 'MNIST-v1'
model_artifact.type_id = model_type_id
[model_artifact_id] = store.put_artifacts([model_artifact])
7) Grave o evento de saída
# Declare the output event
output_event = metadata_store_pb2.Event()
output_event.artifact_id = model_artifact_id
output_event.execution_id = run_id
output_event.type = metadata_store_pb2.Event.DECLARED_OUTPUT
# Submit output event to the Metadata Store
store.put_events([output_event])
8) Marque a execução como concluída
trainer_run.id = run_id
trainer_run.properties["state"].string_value = "COMPLETED"
store.put_executions([trainer_run])
9) Agrupar artefatos e execuções sob um contexto usando artefatos de atribuições e asserções
# Create a ContextType, e.g., Experiment with a note property
experiment_type = metadata_store_pb2.ContextType()
experiment_type.name = "Experiment"
experiment_type.properties["note"] = metadata_store_pb2.STRING
experiment_type_id = store.put_context_type(experiment_type)
# Group the model and the trainer run to an experiment.
my_experiment = metadata_store_pb2.Context()
my_experiment.type_id = experiment_type_id
# Give the experiment a name
my_experiment.name = "exp1"
my_experiment.properties["note"].string_value = "My first experiment."
[experiment_id] = store.put_contexts([my_experiment])
attribution = metadata_store_pb2.Attribution()
attribution.artifact_id = model_artifact_id
attribution.context_id = experiment_id
association = metadata_store_pb2.Association()
association.execution_id = run_id
association.context_id = experiment_id
store.put_attributions_and_associations([attribution], [association])
# Query the Artifacts and Executions that are linked to the Context.
experiment_artifacts = store.get_artifacts_by_context(experiment_id)
experiment_executions = store.get_executions_by_context(experiment_id)
# You can also use neighborhood queries to fetch these artifacts and executions
# with conditions.
experiment_artifacts_with_conditions = store.get_artifacts(
list_options = mlmd.ListOptions(
filter_query=('contexts_a.type = "Experiment" AND contexts_a.name = "exp1"')))
experiment_executions_with_conditions = store.get_executions(
list_options = mlmd.ListOptions(
filter_query=('contexts_a.id = {}'.format(experiment_id))))
Use MLMD com um servidor gRPC remoto
Você pode usar MLMD com servidores gRPC remotos conforme mostrado abaixo:
- Iniciar um servidor
bazel run -c opt --define grpc_no_ares=true //ml_metadata/metadata_store:metadata_store_server
Por padrão, o servidor usa um banco de dados falso na memória por solicitação e não persiste os metadados nas chamadas. Ele também pode ser configurado com MLMD MetadataStoreServerConfig para usar arquivos SQLite ou instâncias MySQL. A configuração pode ser armazenada em um arquivo de texto protobuf e passada para o binário com --metadata_store_server_config_file=path_to_the_config_file .
Um exemplo de arquivo MetadataStoreServerConfig em formato de texto protobuf:
connection_config {
sqlite {
filename_uri: '/tmp/test_db'
connection_mode: READWRITE_OPENCREATE
}
}
- Crie o stub do cliente e use-o em Python
from grpc import insecure_channel
from ml_metadata.proto import metadata_store_pb2
from ml_metadata.proto import metadata_store_service_pb2
from ml_metadata.proto import metadata_store_service_pb2_grpc
channel = insecure_channel('localhost:8080')
stub = metadata_store_service_pb2_grpc.MetadataStoreServiceStub(channel)
- Use MLMD com chamadas RPC
# Create ArtifactTypes, e.g., Data and Model
data_type = metadata_store_pb2.ArtifactType()
data_type.name = "DataSet"
data_type.properties["day"] = metadata_store_pb2.INT
data_type.properties["split"] = metadata_store_pb2.STRING
request = metadata_store_service_pb2.PutArtifactTypeRequest()
request.all_fields_match = True
request.artifact_type.CopyFrom(data_type)
stub.PutArtifactType(request)
model_type = metadata_store_pb2.ArtifactType()
model_type.name = "SavedModel"
model_type.properties["version"] = metadata_store_pb2.INT
model_type.properties["name"] = metadata_store_pb2.STRING
request.artifact_type.CopyFrom(model_type)
stub.PutArtifactType(request)
Recursos
A biblioteca MLMD possui uma API de alto nível que você pode usar prontamente com seus pipelines de ML. Consulte a documentação da API MLMD para obter mais detalhes.
Confira Filtragem de nós declarativos MLMD para aprender como usar os recursos de filtragem de nós declarativos MLMD em propriedades e nós de vizinhança de 1 salto.
Confira também o tutorial do MLMD para aprender como usar o MLMD para rastrear a linhagem dos componentes do pipeline.
O MLMD fornece utilitários para lidar com migrações de esquemas e dados entre versões. Consulte o Guia MLMD para obter mais detalhes.