
فراداده ML (MLMD) کتابخانه ای برای ضبط و بازیابی ابرداده های مرتبط با گردش کار توسعه دهندگان ML و دانشمندان داده است. MLMD بخشی جدایی ناپذیر از TensorFlow Extended (TFX) است، اما طوری طراحی شده است که بتوان از آن به طور مستقل استفاده کرد.
هر اجرای خط لوله ML تولیدی، ابرداده حاوی اطلاعاتی در مورد اجزای مختلف خط لوله، اجرای آنها (مثلاً دوره های آموزشی)، و مصنوعات حاصله (مثلاً مدل های آموزش دیده) تولید می کند. در صورت بروز رفتار یا خطاهای غیرمنتظره خط لوله، می توان از این ابرداده برای تجزیه و تحلیل سلسله اجزای خط لوله و مشکلات اشکال زدایی استفاده کرد. این ابرداده را معادل ورود به سیستم توسعه نرم افزار در نظر بگیرید.
MLMD به شما کمک می کند تا به جای تجزیه و تحلیل مجزا، تمام قسمت های به هم پیوسته خط لوله ML خود را درک و تجزیه و تحلیل کنید و می تواند به شما در پاسخ به سؤالات مربوط به خط لوله ML خود کمک کند مانند:
- مدل بر روی کدام مجموعه داده آموزش دید؟
- برای آموزش مدل از چه هایپرپارامترهایی استفاده شده است؟
- کدام خط لوله این مدل را ایجاد کرده است؟
- کدام دوره آموزشی منجر به این مدل شد؟
- کدام نسخه از TensorFlow این مدل را ایجاد کرده است؟
- چه زمانی مدل شکست خورده رانده شد؟
فروشگاه متادیتا
MLMD انواع فوق داده های زیر را در پایگاه داده ای به نام فروشگاه فراداده ثبت می کند.
- فراداده در مورد مصنوعات تولید شده از طریق مؤلفه ها / مراحل خطوط لوله ML شما
- فراداده در مورد اجرای این مؤلفه ها / مراحل
- فراداده در مورد خطوط لوله و اطلاعات مربوط به اصل و نسب
فروشگاه فراداده APIهایی را برای ضبط و بازیابی متادیتا به و از پشتیبان ذخیره سازی ارائه می دهد. پشتیبان ذخیره سازی قابل اتصال است و قابل افزایش است. MLMD پیاده سازی های مرجع را برای SQLite (که از حافظه و دیسک پشتیبانی می کند) و MySQL خارج از جعبه ارائه می دهد.
این گرافیک یک نمای کلی در سطح بالایی از اجزای مختلف که بخشی از MLMD هستند را نشان می دهد.
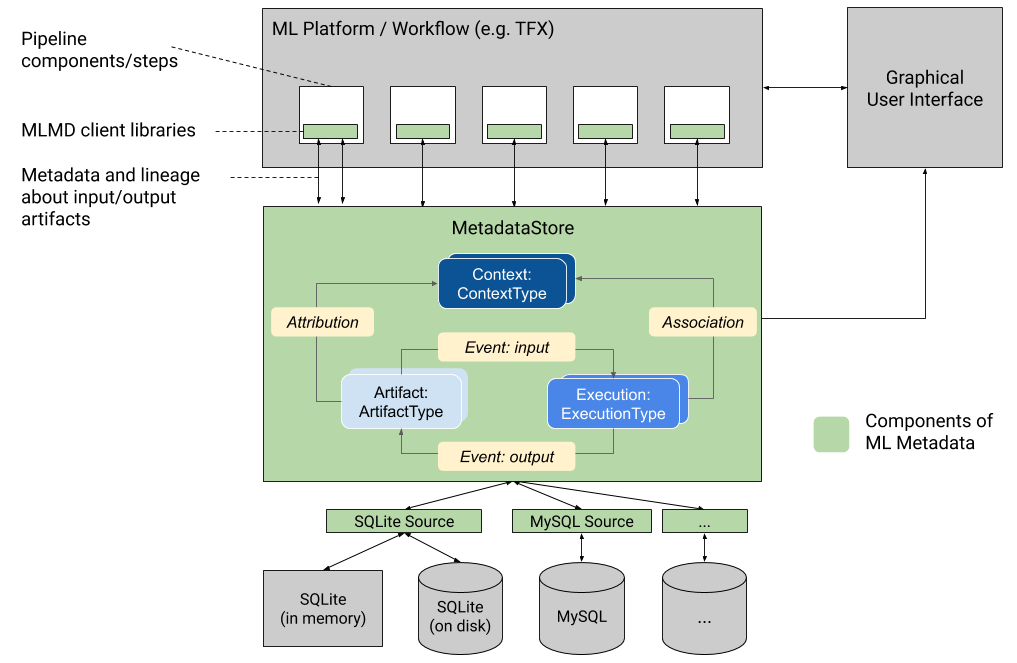
ذخیره سازی ابرداده و پیکربندی اتصال فروشگاه
شی MetadataStore یک پیکربندی اتصال را دریافت می کند که مربوط به پشتیبان ذخیره سازی استفاده شده است.
- پایگاه داده جعلی یک DB در حافظه (با استفاده از SQLite) برای آزمایش سریع و اجرای محلی فراهم می کند. هنگامی که شی فروشگاه از بین می رود پایگاه داده حذف می شود.
import ml_metadata as mlmd
from ml_metadata.metadata_store import metadata_store
from ml_metadata.proto import metadata_store_pb2
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.fake_database.SetInParent() # Sets an empty fake database proto.
store = metadata_store.MetadataStore(connection_config)
- SQLite فایل ها را از دیسک می خواند و می نویسد.
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.sqlite.filename_uri = '...'
connection_config.sqlite.connection_mode = 3 # READWRITE_OPENCREATE
store = metadata_store.MetadataStore(connection_config)
- MySQL به سرور MySQL متصل می شود.
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.mysql.host = '...'
connection_config.mysql.port = '...'
connection_config.mysql.database = '...'
connection_config.mysql.user = '...'
connection_config.mysql.password = '...'
store = metadata_store.MetadataStore(connection_config)
به طور مشابه، هنگام استفاده از یک نمونه MySQL با Google CloudSQL ( شروع سریع ، نمای کلی اتصال )، میتوان در صورت وجود از گزینه SSL نیز استفاده کرد.
connection_config.mysql.ssl_options.key = '...'
connection_config.mysql.ssl_options.cert = '...'
connection_config.mysql.ssl_options.ca = '...'
connection_config.mysql.ssl_options.capath = '...'
connection_config.mysql.ssl_options.cipher = '...'
connection_config.mysql.ssl_options.verify_server_cert = '...'
store = metadata_store.MetadataStore(connection_config)
- PostgreSQL به سرور PostgreSQL متصل می شود.
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.postgresql.host = '...'
connection_config.postgresql.port = '...'
connection_config.postgresql.user = '...'
connection_config.postgresql.password = '...'
connection_config.postgresql.dbname = '...'
store = metadata_store.MetadataStore(connection_config)
به طور مشابه، هنگام استفاده از یک نمونه PostgreSQL با Google CloudSQL ( شروع سریع ، نمای کلی اتصال )، میتوان در صورت وجود از گزینه SSL نیز استفاده کرد.
connection_config.postgresql.ssloption.sslmode = '...' # disable, allow, verify-ca, verify-full, etc.
connection_config.postgresql.ssloption.sslcert = '...'
connection_config.postgresql.ssloption.sslkey = '...'
connection_config.postgresql.ssloption.sslpassword = '...'
connection_config.postgresql.ssloption.sslrootcert = '...'
store = metadata_store.MetadataStore(connection_config)
مدل داده
فروشگاه فراداده از مدل داده زیر برای ضبط و بازیابی متادیتا از باطن ذخیره سازی استفاده می کند.
-
ArtifactTypeنوع یک آرتیفکت و ویژگی های آن را که در فروشگاه ابرداده ذخیره می شود، توصیف می کند. میتوانید این انواع را بهطور همزمان در فروشگاه ابرداده بهصورت کد ثبت کنید، یا میتوانید آنها را از یک قالب سریالی در فروشگاه بارگذاری کنید. هنگامی که یک نوع را ثبت می کنید، تعریف آن در طول عمر فروشگاه در دسترس است. -
Artifactیک نمونه خاص ازArtifactTypeو ویژگیهای آن را که در فروشگاه ابرداده نوشته میشود، توصیف میکند. -
ExecutionTypeیک نوع جزء یا مرحله در یک گردش کار و پارامترهای زمان اجرا آن را توصیف می کند. -
Executionرکوردی از اجرای یک جزء یا یک مرحله در یک گردش کار ML و پارامترهای زمان اجرا است. یک اجرا را می توان به عنوان نمونه ای ازExecutionTypeدر نظر گرفت. وقتی یک خط لوله یا مرحله ML را اجرا می کنید، اجراها ثبت می شوند. - یک
Eventسابقه ای از رابطه بین مصنوعات و اعدام ها است. هنگامی که یک اجرا اتفاق می افتد، رویدادها هر مصنوع مورد استفاده در اجرا و هر مصنوع تولید شده را ثبت می کنند. این سوابق امکان ردیابی نسب را در طول یک گردش کار فراهم می کند. با مشاهده همه رویدادها، MLMD میداند که چه اعدامهایی اتفاق افتاده و چه مصنوعاتی در نتیجه آن ایجاد شدهاند. سپس MLMD می تواند از هر آرتیفکتی به تمام ورودی های بالادستی خود بازگردد. -
ContextTypeیک نوع گروه مفهومی از مصنوعات و اجراها در یک گردش کار و ویژگیهای ساختاری آن را توصیف میکند. به عنوان مثال: پروژه ها، اجرای خط لوله، آزمایش ها، مالکان و غیره. -
Contextنمونه ای ازContextTypeاست. این اطلاعات به اشتراک گذاشته شده در گروه را ضبط می کند. به عنوان مثال: نام پروژه، شناسه تعهد لیست تغییرات، حاشیه نویسی آزمایش و غیره. این نام منحصر به فرد تعریف شده توسط کاربر درContextTypeخود دارد. -
Attributionسابقه ای از رابطه بین مصنوعات و زمینه ها است. - یک
Associationسابقه ای از رابطه بین اعدام ها و زمینه ها است.
قابلیت MLMD
ردیابی ورودیها و خروجیهای همه مؤلفهها/مراحل در یک گردش کار ML و اصل و نسب آنها به پلتفرمهای ML اجازه میدهد تا چندین ویژگی مهم را فعال کنند. فهرست زیر یک نمای کلی غیر جامع از برخی از مزایای اصلی ارائه می دهد.
- فهرست تمام مصنوعات از یک نوع خاص. مثال: تمام مدل هایی که آموزش دیده اند.
- دو مصنوع از یک نوع را برای مقایسه بارگذاری کنید. مثال: نتایج دو آزمایش را مقایسه کنید.
- یک DAG از تمام اجراهای مرتبط و مصنوعات ورودی و خروجی یک زمینه را نشان دهید. مثال: گردش کار یک آزمایش را برای اشکال زدایی و کشف تجسم کنید.
- همه وقایع را دوباره مرور کنید تا ببینید یک مصنوع چگونه ایجاد شده است. مثالها: ببینید چه دادههایی وارد یک مدل شدند. اجرای طرح های نگهداری داده ها
- تمام مصنوعاتی که با استفاده از یک مصنوع خاص ایجاد شده اند را شناسایی کنید. مثالها: تمام مدلهای آموزش دیده از یک مجموعه داده خاص را ببینید. مدل ها را بر اساس داده های بد علامت گذاری کنید.
- تعیین کنید که آیا یک اجرا قبلاً روی همان ورودی ها اجرا شده است یا خیر. مثال: تعیین کنید که آیا یک جزء/مرحله قبلاً همان کار را تکمیل کرده است و خروجی قبلی را میتوان دوباره استفاده کرد.
- ضبط و پرس و جو زمینه اجرای گردش کار. مثال: مالک و لیست تغییرات مورد استفاده برای اجرای گردش کار را ردیابی کنید. دودمان را بر اساس آزمایش گروه بندی کنید. مدیریت مصنوعات توسط پروژه ها
- قابلیت فیلتر گرههای اعلامی بر روی ویژگیها و گرههای همسایگی 1-hop. مثالها: به دنبال مصنوعات از یک نوع و تحت برخی زمینههای خط لوله باشید. مصنوعات تایپ شده را برمی گرداند که در آن مقدار یک ویژگی معین در یک محدوده باشد. اجراهای قبلی را در زمینه ای با ورودی های یکسان پیدا کنید.
برای نمونه ای به آموزش MLMD مراجعه کنید که به شما نشان می دهد چگونه از API MLMD و ذخیره ابرداده برای بازیابی اطلاعات مربوط به اصل و نسب استفاده کنید.
فراداده ML را در گردش کار ML خود ادغام کنید
اگر شما یک توسعه دهنده پلتفرم هستید که علاقه مند به ادغام MLMD در سیستم خود هستید، از گردش کار مثال زیر برای استفاده از API های سطح پایین MLMD برای پیگیری اجرای یک کار آموزشی استفاده کنید. همچنین میتوانید از APIهای سطح بالاتر پایتون در محیطهای نوتبوک برای ثبت فرادادههای آزمایشی استفاده کنید.
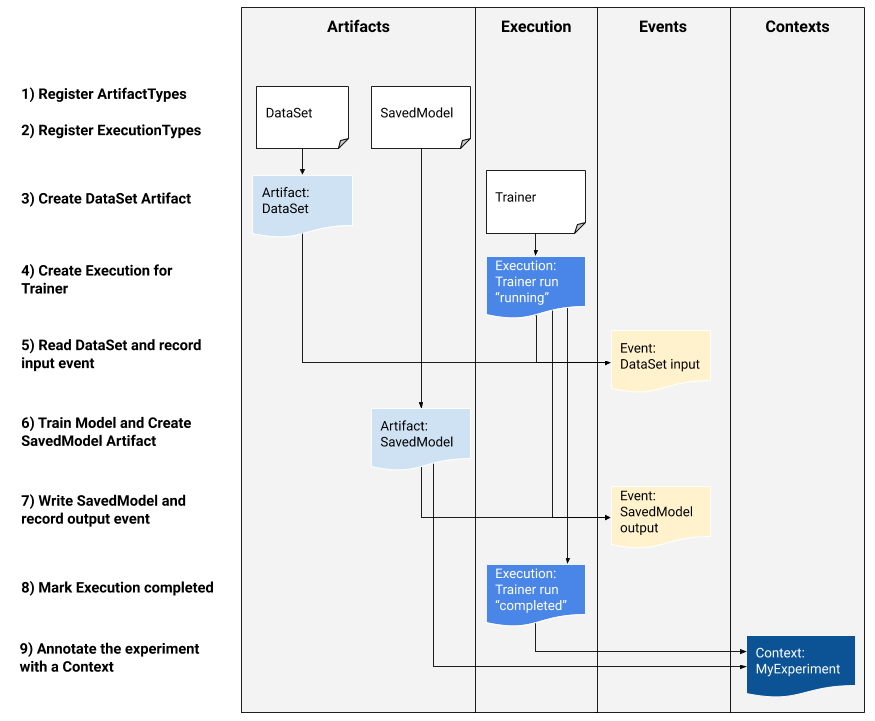
1) ثبت انواع مصنوعات
# Create ArtifactTypes, e.g., Data and Model
data_type = metadata_store_pb2.ArtifactType()
data_type.name = "DataSet"
data_type.properties["day"] = metadata_store_pb2.INT
data_type.properties["split"] = metadata_store_pb2.STRING
data_type_id = store.put_artifact_type(data_type)
model_type = metadata_store_pb2.ArtifactType()
model_type.name = "SavedModel"
model_type.properties["version"] = metadata_store_pb2.INT
model_type.properties["name"] = metadata_store_pb2.STRING
model_type_id = store.put_artifact_type(model_type)
# Query all registered Artifact types.
artifact_types = store.get_artifact_types()
2) انواع اجرا را برای تمام مراحل در گردش کار ML ثبت کنید
# Create an ExecutionType, e.g., Trainer
trainer_type = metadata_store_pb2.ExecutionType()
trainer_type.name = "Trainer"
trainer_type.properties["state"] = metadata_store_pb2.STRING
trainer_type_id = store.put_execution_type(trainer_type)
# Query a registered Execution type with the returned id
[registered_type] = store.get_execution_types_by_id([trainer_type_id])
3) یک آرتیفکت از DataSet ArtifactType ایجاد کنید
# Create an input artifact of type DataSet
data_artifact = metadata_store_pb2.Artifact()
data_artifact.uri = 'path/to/data'
data_artifact.properties["day"].int_value = 1
data_artifact.properties["split"].string_value = 'train'
data_artifact.type_id = data_type_id
[data_artifact_id] = store.put_artifacts([data_artifact])
# Query all registered Artifacts
artifacts = store.get_artifacts()
# Plus, there are many ways to query the same Artifact
[stored_data_artifact] = store.get_artifacts_by_id([data_artifact_id])
artifacts_with_uri = store.get_artifacts_by_uri(data_artifact.uri)
artifacts_with_conditions = store.get_artifacts(
list_options=mlmd.ListOptions(
filter_query='uri LIKE "%/data" AND properties.day.int_value > 0'))
4) اجرای Trainer run را ایجاد کنید
# Register the Execution of a Trainer run
trainer_run = metadata_store_pb2.Execution()
trainer_run.type_id = trainer_type_id
trainer_run.properties["state"].string_value = "RUNNING"
[run_id] = store.put_executions([trainer_run])
# Query all registered Execution
executions = store.get_executions_by_id([run_id])
# Similarly, the same execution can be queried with conditions.
executions_with_conditions = store.get_executions(
list_options = mlmd.ListOptions(
filter_query='type = "Trainer" AND properties.state.string_value IS NOT NULL'))
5) رویداد ورودی را تعریف کنید و داده ها را بخوانید
# Define the input event
input_event = metadata_store_pb2.Event()
input_event.artifact_id = data_artifact_id
input_event.execution_id = run_id
input_event.type = metadata_store_pb2.Event.DECLARED_INPUT
# Record the input event in the metadata store
store.put_events([input_event])
6) مصنوع خروجی را اعلام کنید
# Declare the output artifact of type SavedModel
model_artifact = metadata_store_pb2.Artifact()
model_artifact.uri = 'path/to/model/file'
model_artifact.properties["version"].int_value = 1
model_artifact.properties["name"].string_value = 'MNIST-v1'
model_artifact.type_id = model_type_id
[model_artifact_id] = store.put_artifacts([model_artifact])
7) رویداد خروجی را ضبط کنید
# Declare the output event
output_event = metadata_store_pb2.Event()
output_event.artifact_id = model_artifact_id
output_event.execution_id = run_id
output_event.type = metadata_store_pb2.Event.DECLARED_OUTPUT
# Submit output event to the Metadata Store
store.put_events([output_event])
8) اجرا را به عنوان تکمیل شده علامت گذاری کنید
trainer_run.id = run_id
trainer_run.properties["state"].string_value = "COMPLETED"
store.put_executions([trainer_run])
9) گروهبندی مصنوعات و اجراها تحت یک زمینه با استفاده از مصنوعات اسناد و ادعاها
# Create a ContextType, e.g., Experiment with a note property
experiment_type = metadata_store_pb2.ContextType()
experiment_type.name = "Experiment"
experiment_type.properties["note"] = metadata_store_pb2.STRING
experiment_type_id = store.put_context_type(experiment_type)
# Group the model and the trainer run to an experiment.
my_experiment = metadata_store_pb2.Context()
my_experiment.type_id = experiment_type_id
# Give the experiment a name
my_experiment.name = "exp1"
my_experiment.properties["note"].string_value = "My first experiment."
[experiment_id] = store.put_contexts([my_experiment])
attribution = metadata_store_pb2.Attribution()
attribution.artifact_id = model_artifact_id
attribution.context_id = experiment_id
association = metadata_store_pb2.Association()
association.execution_id = run_id
association.context_id = experiment_id
store.put_attributions_and_associations([attribution], [association])
# Query the Artifacts and Executions that are linked to the Context.
experiment_artifacts = store.get_artifacts_by_context(experiment_id)
experiment_executions = store.get_executions_by_context(experiment_id)
# You can also use neighborhood queries to fetch these artifacts and executions
# with conditions.
experiment_artifacts_with_conditions = store.get_artifacts(
list_options = mlmd.ListOptions(
filter_query=('contexts_a.type = "Experiment" AND contexts_a.name = "exp1"')))
experiment_executions_with_conditions = store.get_executions(
list_options = mlmd.ListOptions(
filter_query=('contexts_a.id = {}'.format(experiment_id))))
از MLMD با سرور gRPC راه دور استفاده کنید
می توانید از MLMD با سرورهای gRPC راه دور مانند شکل زیر استفاده کنید:
- یک سرور راه اندازی کنید
bazel run -c opt --define grpc_no_ares=true //ml_metadata/metadata_store:metadata_store_server
بهطور پیشفرض، سرور در هر درخواست از یک db جعلی در حافظه استفاده میکند و ابرداده را در تماسها حفظ نمیکند. همچنین میتوان آن را با MLMD MetadataStoreServerConfig پیکربندی کرد تا از فایلهای SQLite یا نمونههای MySQL استفاده کند. پیکربندی را می توان در یک فایل متنی protobuf ذخیره کرد و با --metadata_store_server_config_file=path_to_the_config_file به باینری ارسال کرد.
نمونه فایل MetadataStoreServerConfig در قالب متن پروتوباف:
connection_config {
sqlite {
filename_uri: '/tmp/test_db'
connection_mode: READWRITE_OPENCREATE
}
}
- خرد مشتری را ایجاد کنید و از آن در پایتون استفاده کنید
from grpc import insecure_channel
from ml_metadata.proto import metadata_store_pb2
from ml_metadata.proto import metadata_store_service_pb2
from ml_metadata.proto import metadata_store_service_pb2_grpc
channel = insecure_channel('localhost:8080')
stub = metadata_store_service_pb2_grpc.MetadataStoreServiceStub(channel)
- از MLMD با تماس های RPC استفاده کنید
# Create ArtifactTypes, e.g., Data and Model
data_type = metadata_store_pb2.ArtifactType()
data_type.name = "DataSet"
data_type.properties["day"] = metadata_store_pb2.INT
data_type.properties["split"] = metadata_store_pb2.STRING
request = metadata_store_service_pb2.PutArtifactTypeRequest()
request.all_fields_match = True
request.artifact_type.CopyFrom(data_type)
stub.PutArtifactType(request)
model_type = metadata_store_pb2.ArtifactType()
model_type.name = "SavedModel"
model_type.properties["version"] = metadata_store_pb2.INT
model_type.properties["name"] = metadata_store_pb2.STRING
request.artifact_type.CopyFrom(model_type)
stub.PutArtifactType(request)
منابع
کتابخانه MLMD یک API سطح بالایی دارد که می توانید به راحتی با خطوط لوله ML خود از آن استفاده کنید. برای جزئیات بیشتر به مستندات API MLMD مراجعه کنید.
برای یادگیری نحوه استفاده از قابلیتهای فیلتر گرههای اعلامی MLMD در ویژگیها و گرههای همسایگی 1-hop ، فیلترینگ گرههای اعلامی MLMD را بررسی کنید.
همچنین برای یادگیری نحوه استفاده از MLMD برای ردیابی اصل و نسب اجزای خط لوله خود ، آموزش MLMD را بررسی کنید.
MLMD ابزارهایی را برای مدیریت طرحواره و انتقال داده ها در نسخه ها فراهم می کند. برای جزئیات بیشتر به راهنمای MLMD مراجعه کنید.