
هنگامی که داده های شما در خط لوله TFX قرار می گیرند، می توانید از اجزای TFX برای تجزیه و تحلیل و تبدیل آن ها استفاده کنید. حتی قبل از آموزش مدل می توانید از این ابزارها استفاده کنید.
دلایل زیادی برای تجزیه و تحلیل و تبدیل داده های شما وجود دارد:
- برای پیدا کردن مشکلات در داده های خود مشکلات رایج عبارتند از:
- داده های از دست رفته، مانند ویژگی هایی با مقادیر خالی.
- برچسبها بهعنوان ویژگی در نظر گرفته میشوند، به طوری که مدل شما در طول آموزش به پاسخ درست نگاه میکند.
- ویژگی هایی با مقادیر خارج از محدوده مورد انتظار شما.
- ناهنجاری های داده
- مدل آموخته شده انتقال دارای پیش پردازشی است که با داده های آموزشی مطابقت ندارد.
- برای مهندسی مجموعه ویژگی های موثرتر. به عنوان مثال، می توانید شناسایی کنید:
- به خصوص ویژگی های آموزنده.
- ویژگی های اضافی
- ویژگی هایی که در مقیاس بسیار متفاوت هستند که ممکن است یادگیری را کند کنند.
- ویژگیهایی با اطلاعات پیشبینی منحصربهفرد یا کم.
ابزارهای TFX هم می توانند به یافتن باگ های داده کمک کنند و هم به مهندسی ویژگی کمک کنند.
اعتبارسنجی داده های TensorFlow
نمای کلی
اعتبارسنجی دادههای TensorFlow ناهنجاریها را در آموزش و ارائه دادهها شناسایی میکند و میتواند به طور خودکار با بررسی دادهها یک طرح واره ایجاد کند. کامپوننت را می توان برای شناسایی کلاس های مختلف ناهنجاری در داده ها پیکربندی کرد. می تواند
- با مقایسه آمار داده ها با طرحواره ای که انتظارات کاربر را کدگذاری می کند، بررسی اعتبار را انجام دهید.
- با مقایسه مثالهایی در آموزش و ارائه دادهها، انحراف ارائه خدمات را تشخیص دهید.
- انحراف داده ها را با نگاه کردن به یک سری داده تشخیص دهید.
ما هر یک از این عملکردها را به طور مستقل مستند می کنیم:
اعتبار سنجی نمونه مبتنی بر طرحواره
اعتبارسنجی دادههای TensorFlow هرگونه ناهنجاری در دادههای ورودی را با مقایسه آمار دادهها با یک طرحواره شناسایی میکند. این طرح ویژگی هایی را که انتظار می رود داده های ورودی برآورده شوند، مانند انواع داده ها یا مقادیر طبقه بندی می کند، و می تواند توسط کاربر تغییر یا جایگزین شود.
اعتبارسنجی دادههای Tensorflow معمولاً چندین بار در چارچوب خط لوله TFX فراخوانی میشود: (i) برای هر تقسیم بهدستآمده از ExampleGen، (ii) برای همه دادههای از پیش تبدیل شده استفاده شده توسط Transform و (iii) برای همه دادههای پس از تبدیل تولید شده توسط تبدیل کنید. هنگامی که در زمینه Transform (ii-iii) فراخوانی می شود، گزینه های آمار و محدودیت های مبتنی بر طرحواره را می توان با تعریف stats_options_updater_fn تنظیم کرد. این به ویژه هنگام اعتبارسنجی داده های بدون ساختار (به عنوان مثال ویژگی های متن) مفید است. برای مثال کد کاربری را ببینید.
ویژگی های طرحواره پیشرفته
این بخش پیکربندی طرحواره پیشرفته تری را پوشش می دهد که می تواند به تنظیمات ویژه کمک کند.
ویژگی های پراکنده
رمزگذاری ویژگیهای پراکنده در Examples معمولا چندین ویژگی را معرفی میکند که انتظار میرود ظرفیت یکسانی برای همه مثالها داشته باشند. به عنوان مثال ویژگی پراکنده:
WeightedCategories = [('CategoryA', 0.3), ('CategoryX', 0.7)]
WeightedCategoriesIndex = ['CategoryA', 'CategoryX']
WeightedCategoriesValue = [0.3, 0.7]
sparse_feature {
name: 'WeightedCategories'
index_feature { name: 'WeightedCategoriesIndex' }
value_feature { name: 'WeightedCategoriesValue' }
}
تعریف ویژگی پراکنده به یک یا چند شاخص و یک ویژگی ارزشی نیاز دارد که به ویژگی هایی اشاره دارد که در طرحواره وجود دارد. تعریف صریح ویژگیهای پراکنده، TFDV را قادر میسازد تا بررسی کند که ظرفیتهای همه ویژگیهای ارجاعی مطابقت دارند.
برخی موارد استفاده محدودیتهای ظرفیت مشابهی را بین ویژگیها معرفی میکنند، اما لزوماً یک ویژگی پراکنده را رمزگذاری نمیکنند. استفاده از ویژگی پراکنده باید شما را رفع انسداد کند، اما ایده آل نیست.
محیط های طرحواره
بهطور پیشفرض اعتبارسنجیها فرض میکنند که همه مثالها در یک خط لوله به یک طرح منفرد پایبند هستند. در برخی موارد، ارائه تغییرات جزئی طرحواره ضروری است، برای مثال ویژگیهایی که بهعنوان برچسب در طول آموزش مورد استفاده قرار میگیرند (و باید تأیید شوند)، اما در حین ارائه از دست میروند. از محیطها میتوان برای بیان چنین الزاماتی استفاده کرد، به ویژه default_environment() , in_environment() , not_in_environment() .
به عنوان مثال، فرض کنید یک ویژگی به نام "LABEL" برای آموزش مورد نیاز است، اما انتظار می رود در ارائه وجود نداشته باشد. این را می توان به صورت زیر بیان کرد:
- دو محیط متمایز را در طرحواره تعریف کنید: ["SERVING"، "TRAINING"] و "LABEL" را فقط با محیط "TRAINING" مرتبط کنید.
- داده های آموزشی را با محیط "TRAINING" و داده های ارائه دهنده را با محیط "SERVING" مرتبط کنید.
تولید طرحواره
طرح داده های ورودی به عنوان نمونه ای از طرحواره TensorFlow مشخص می شود.
به جای ساختن یک طرح به صورت دستی از ابتدا، یک توسعهدهنده میتواند به ساخت خودکار طرحواره TensorFlow Data Validation تکیه کند. به طور خاص، اعتبارسنجی داده های TensorFlow به طور خودکار یک طرح اولیه را بر اساس آمار محاسبه شده بر روی داده های آموزشی موجود در خط لوله ایجاد می کند. کاربران می توانند به سادگی این طرح تولید شده را بررسی کنند، آن را در صورت نیاز اصلاح کنند، آن را در یک سیستم کنترل نسخه بررسی کنند، و آن را به صراحت در خط لوله برای اعتبار سنجی بیشتر فشار دهند.
TFDV شامل infer_schema() برای تولید خودکار طرحواره است. به عنوان مثال:
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
این باعث ایجاد طرحواره خودکار بر اساس قوانین زیر می شود:
اگر طرحی قبلاً به طور خودکار ایجاد شده باشد، همانطور که هست استفاده می شود.
در غیر این صورت، TensorFlow Data Validation آمار داده های موجود را بررسی می کند و طرحی مناسب برای داده ها محاسبه می کند.
توجه: طرحواره تولید خودکار بهترین تلاش است و فقط سعی می کند ویژگی های اساسی داده ها را استنتاج کند. انتظار می رود که کاربران در صورت نیاز آن را بررسی و اصلاح کنند.
Training-Serving Skew Detection
نمای کلی
اعتبارسنجی دادههای TensorFlow میتواند انحراف توزیع بین آموزش و ارائه داده را تشخیص دهد. انحراف توزیع زمانی اتفاق می افتد که توزیع مقادیر ویژگی برای داده های آموزشی به طور قابل توجهی با داده های ارائه شده متفاوت باشد. یکی از دلایل کلیدی انحراف توزیع، استفاده از یک مجموعه کاملاً متفاوت برای تولید داده های آموزشی برای غلبه بر کمبود داده های اولیه در پیکره مورد نظر است. دلیل دیگر مکانیسم نمونه گیری معیوب است که فقط یک نمونه فرعی از داده های ارائه شده را برای آموزش انتخاب می کند.
سناریوی نمونه
برای اطلاعات در مورد پیکربندی تشخیص چولگی در خدمت آموزش، به راهنمای شروع اعتبارسنجی دادههای TensorFlow مراجعه کنید.
تشخیص دریفت
تشخیص رانش بین بازههای متوالی دادهها (یعنی بین دهانه N و دهانه N+1)، مانند بین روزهای مختلف دادههای آموزشی، پشتیبانی میشود. ما رانش را بر حسب فاصله L-بی نهایت برای ویژگی های طبقه بندی و واگرایی تقریبی جنسن-شانون برای ویژگی های عددی بیان می کنیم. می توانید فاصله آستانه را به گونه ای تنظیم کنید که وقتی دریفت بالاتر از حد قابل قبول است، هشدار دریافت کنید. تنظیم فاصله صحیح معمولاً یک فرآیند تکراری است که به دانش و آزمایش دامنه نیاز دارد.
برای اطلاعات در مورد پیکربندی تشخیص دریفت، به راهنمای شروع اعتبارسنجی داده های TensorFlow مراجعه کنید.
استفاده از تجسم برای بررسی داده های خود
TensorFlow Data Validation ابزارهایی را برای تجسم توزیع مقادیر ویژگی فراهم می کند. با بررسی این توزیع ها در یک نوت بوک Jupyter با استفاده از Facets می توانید مشکلات رایج داده ها را پیدا کنید.
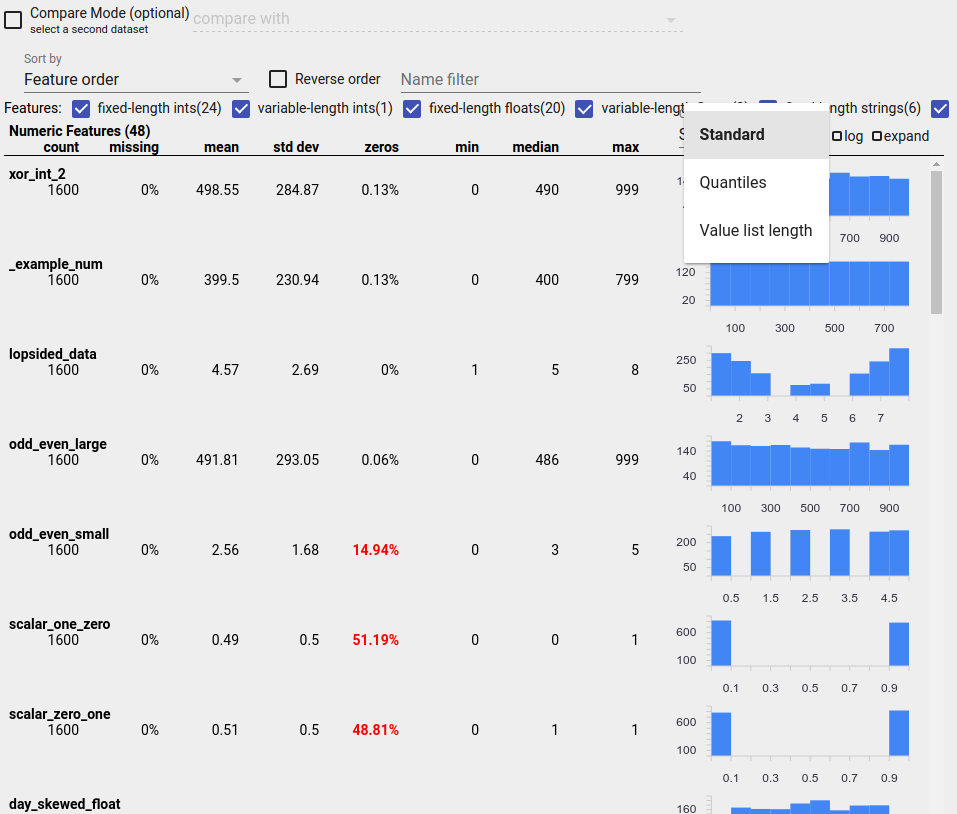
شناسایی توزیع های مشکوک
می توانید با استفاده از نمایشگر نمای کلی وجوه برای جستجوی توزیع مشکوک مقادیر ویژگی، اشکالات رایج در داده های خود را شناسایی کنید.
داده های نامتعادل
ویژگی نامتعادل ویژگی است که یک مقدار برای آن غالب است. ویژگیهای نامتعادل میتوانند به طور طبیعی رخ دهند، اما اگر یک ویژگی همیشه همان مقدار را داشته باشد، ممکن است یک باگ داده داشته باشید. برای شناسایی ویژگیهای نامتعادل در نمای کلی جنبهها، «عدم یکنواختی» را از منوی کشویی «مرتبسازی بر اساس» انتخاب کنید.
نامتعادل ترین ویژگی ها در بالای هر لیست از نوع ویژگی فهرست می شوند. به عنوان مثال، اسکرین شات زیر یک ویژگی را نشان میدهد که تمام آن صفر است، و ویژگی دومی که به شدت نامتعادل است، در بالای لیست «ویژگیهای عددی» است:

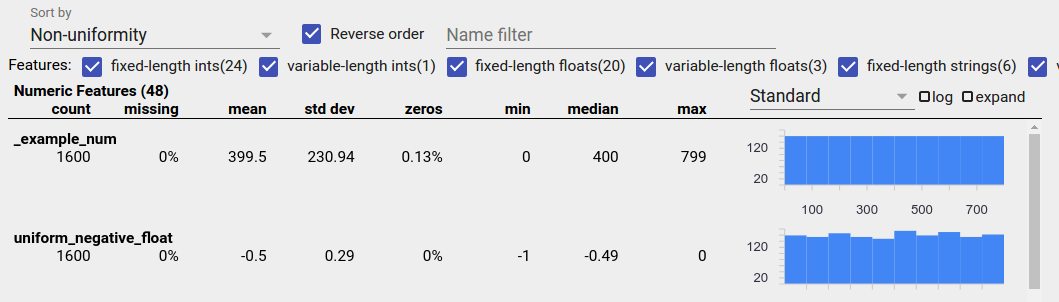
داده های توزیع شده یکنواخت
یک ویژگی توزیع یکنواخت، ویژگی ای است که تمام مقادیر ممکن برای آن با فرکانس نزدیک به یک ظاهر می شوند. مانند داده های نامتعادل، این توزیع می تواند به طور طبیعی رخ دهد، اما همچنین می تواند توسط باگ های داده تولید شود.
برای شناسایی ویژگیهای توزیع یکنواخت در نمای کلی جنبهها، «عدم یکنواختی» را از منوی کشویی «مرتبسازی بر اساس» انتخاب کنید و کادر انتخاب «ترتیب معکوس» را علامت بزنید:
داده های رشته ای با استفاده از نمودارهای میله ای در صورت وجود 20 یا کمتر مقدار منحصر به فرد و به عنوان نمودار توزیع تجمعی اگر بیش از 20 مقدار منحصر به فرد وجود داشته باشد، نمایش داده می شود. بنابراین برای دادههای رشتهای، توزیعهای یکنواخت میتوانند به صورت نمودارهای میلهای مسطح مانند تصویر بالا یا خطوط مستقیم مانند زیر ظاهر شوند:

اشکالاتی که می توانند داده های توزیع شده یکنواخت تولید کنند
در اینجا برخی از اشکالات رایج وجود دارد که می توانند داده های توزیع شده یکنواخت تولید کنند:
استفاده از رشته ها برای نمایش انواع داده های غیر رشته ای مانند تاریخ. به عنوان مثال، مقادیر منحصر به فرد زیادی برای ویژگی تاریخ با نمایش هایی مانند "2017-03-01-11-45-03" خواهید داشت. مقادیر منحصر به فرد به طور یکنواخت توزیع می شوند.
از جمله شاخص هایی مانند "شماره ردیف" به عنوان ویژگی. در اینجا دوباره شما ارزش های منحصر به فرد زیادی دارید.
داده های از دست رفته
برای بررسی اینکه آیا یک ویژگی به طور کامل مقادیر را از دست داده است:
- از منوی کشویی «مرتب سازی بر اساس» گزینه «مقدار گمشده/صفر» را انتخاب کنید.
- چک باکس "ترتیب معکوس" را علامت بزنید.
- برای مشاهده درصد موارد با مقادیر از دست رفته برای یک ویژگی، به ستون "از دست رفته" نگاه کنید.
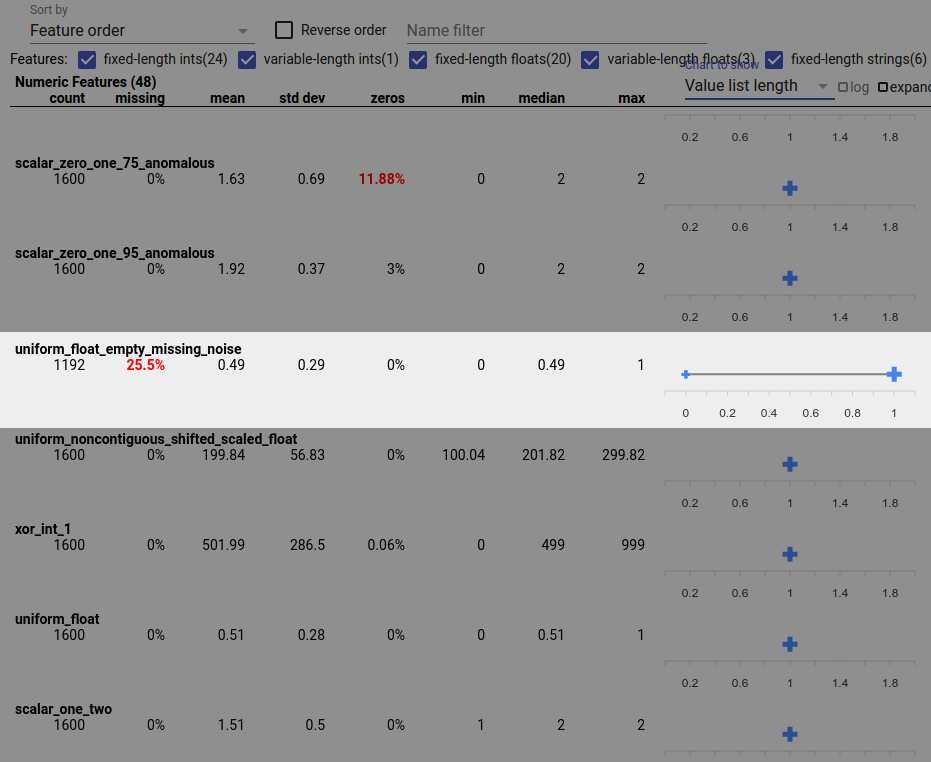
یک اشکال داده همچنین می تواند باعث ناقص بودن مقادیر ویژگی شود. برای مثال ممکن است انتظار داشته باشید که لیست ارزش یک ویژگی همیشه دارای سه عنصر باشد و متوجه شوید که گاهی اوقات فقط یک عنصر دارد. برای بررسی مقادیر ناقص یا موارد دیگر که در آن لیستهای ارزش ویژگی تعداد عناصر مورد انتظار را ندارند:
"طول لیست ارزش" را از منوی کشویی "نمودار برای نمایش" در سمت راست انتخاب کنید.
به نمودار سمت راست هر ردیف ویژگی نگاه کنید. نمودار محدوده طول لیست مقادیر برای ویژگی را نشان می دهد. به عنوان مثال، ردیف برجسته شده در تصویر زیر ویژگیای را نشان میدهد که دارای لیستهایی با طول صفر است:
تفاوت های بزرگ در مقیاس بین ویژگی ها
اگر ویژگیهای شما از نظر مقیاس بسیار متفاوت است، ممکن است مدل در یادگیری با مشکل مواجه شود. به عنوان مثال، اگر برخی از ویژگی ها از 0 تا 1 و برخی دیگر از 0 تا 1,000,000,000 متفاوت باشند، تفاوت زیادی در مقیاس دارید. ستونهای «حداکثر» و «min» را در میان ویژگیها مقایسه کنید تا مقیاسهای بسیار متفاوت را پیدا کنید.
برای کاهش این تغییرات گسترده، مقادیر ویژگی را عادی کنید.
برچسبهایی با برچسبهای نامعتبر
برآوردگرهای TensorFlow محدودیتهایی در نوع دادههایی دارند که به عنوان برچسب میپذیرند. برای مثال، طبقهبندیکنندههای باینری معمولاً فقط با برچسبهای {0، 1} کار میکنند.
مقادیر برچسب را در نمای کلی Facets مرور کنید و مطمئن شوید که با الزامات برآوردگر مطابقت دارند.