
Как только ваши данные попадут в конвейер TFX, вы сможете использовать компоненты TFX для их анализа и преобразования. Вы можете использовать эти инструменты еще до обучения модели.
Есть много причин для анализа и преобразования ваших данных:
- Чтобы найти проблемы в ваших данных. Общие проблемы включают в себя:
- Отсутствующие данные, например объекты с пустыми значениями.
- Метки рассматриваются как функции, поэтому ваша модель может увидеть правильный ответ во время обучения.
- Объекты со значениями, выходящими за рамки ожидаемого диапазона.
- Аномалии данных.
- Модель переноса обучения имеет предварительную обработку, которая не соответствует обучающим данным.
- Для разработки более эффективных наборов функций. Например, вы можете определить:
- Особо информативные функции.
- Избыточные функции.
- Функции, которые настолько сильно различаются по масштабу, что могут замедлить обучение.
- Функции с небольшим количеством уникальной прогнозной информации или без нее.
Инструменты TFX могут помочь как найти ошибки в данных, так и помочь в разработке функций.
Проверка данных TensorFlow
- Обзор
- Проверка примера на основе схемы
- Обнаружение перекосов при обучении и обслуживании
- Обнаружение дрейфа
Обзор
Проверка данных TensorFlow выявляет аномалии в обучении и обслуживании данных и может автоматически создавать схему путем проверки данных. Компонент можно настроить на обнаружение различных классов аномалий в данных. Он может
- Выполняйте проверки достоверности, сравнивая статистику данных со схемой, которая кодифицирует ожидания пользователя.
- Выявляйте перекосы в обучении и обслуживании, сравнивая примеры данных обучения и обслуживания.
- Обнаруживайте дрейф данных, просматривая серию данных.
Мы документируем каждую из этих функций независимо:
- Проверка примера на основе схемы
- Обнаружение перекосов при обучении и обслуживании
- Обнаружение дрейфа
Проверка примера на основе схемы
Проверка данных TensorFlow выявляет любые аномалии во входных данных путем сравнения статистики данных со схемой. Схема кодифицирует свойства, которым, как ожидается, будут соответствовать входные данные, такие как типы данных или категориальные значения, и могут быть изменены или заменены пользователем.
Проверка данных Tensorflow обычно вызывается несколько раз в контексте конвейера TFX: (i) для каждого разделения, полученного из SampleGen, (ii) для всех предварительно преобразованных данных, используемых Transform, и (iii) для всех данных после преобразования, сгенерированных Преобразовать. При вызове в контексте Transform (ii-iii) параметры статистики и ограничения на основе схемы могут быть установлены путем определения stats_options_updater_fn . Это особенно полезно при проверке неструктурированных данных (например, текстовых объектов). См. пример кода пользователя .
Расширенные возможности схемы
В этом разделе описываются более сложные настройки схемы, которые могут помочь при специальных настройках.
Редкие функции
Кодирование разреженных функций в примерах обычно приводит к появлению нескольких функций, которые, как ожидается, будут иметь одинаковую валентность для всех примеров. Например, разреженная функция:
WeightedCategories = [('CategoryA', 0.3), ('CategoryX', 0.7)]
WeightedCategoriesIndex = ['CategoryA', 'CategoryX']
WeightedCategoriesValue = [0.3, 0.7]
sparse_feature {
name: 'WeightedCategories'
index_feature { name: 'WeightedCategoriesIndex' }
value_feature { name: 'WeightedCategoriesValue' }
}
Для определения разреженного объекта требуется один или несколько индексных и один значащий объект, которые относятся к объектам, существующим в схеме. Явное определение разреженных объектов позволяет TFDV проверять совпадение валентностей всех упомянутых объектов.
Некоторые варианты использования вводят аналогичные ограничения валентности между функциями, но не обязательно кодируют разреженную функцию. Использование разреженной функции должно разблокировать вас, но это не идеальный вариант.
Среды схемы
По умолчанию проверки предполагают, что все примеры в конвейере соответствуют одной схеме. В некоторых случаях необходимо вносить небольшие изменения в схему, например, функции, используемые в качестве меток, необходимы во время обучения (и должны быть проверены), но отсутствуют во время обслуживания. Для выражения таких требований можно использовать среды, в частности default_environment() , in_environment() , not_in_environment() .
Например, предположим, что функция под названием «LABEL» необходима для обучения, но ожидается, что она будет отсутствовать при обслуживании. Это может быть выражено:
- Определите в схеме две отдельные среды: ["СЕРВИНГ", "ОБУЧЕНИЕ"] и свяжите "ЯРЛЫК" только со средой "ОБУЧЕНИЕ".
- Свяжите данные обучения со средой «ОБУЧЕНИЕ», а данные обслуживания — со средой «ОБСЛУЖИВАНИЕ».
Генерация схемы
Схема входных данных указывается как экземпляр схемы TensorFlow.
Вместо того, чтобы создавать схему вручную с нуля, разработчик может положиться на автоматическое построение схемы TensorFlow Data Validation. В частности, проверка данных TensorFlow автоматически создает исходную схему на основе статистики, вычисленной на основе обучающих данных, доступных в конвейере. Пользователи могут просто просмотреть эту автоматически созданную схему, изменить ее по мере необходимости, зарегистрировать в системе контроля версий и напрямую отправить в конвейер для дальнейшей проверки.
TFDV включает infer_schema() для автоматического создания схемы. Например:
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
Это запускает автоматическое создание схемы на основе следующих правил:
Если схема уже была сгенерирована автоматически, она используется как есть.
В противном случае проверка данных TensorFlow проверяет доступную статистику данных и вычисляет подходящую схему для данных.
Примечание. Автоматически созданная схема является максимально эффективной и пытается определить только основные свойства данных. Ожидается, что пользователи просматривают и изменяют его по мере необходимости.
Обнаружение перекосов при обучении и обслуживании
Обзор
Проверка данных TensorFlow может обнаружить перекос в распределении между обучающими и обслуживающими данными. Неравномерность распределения возникает, когда распределение значений признаков для обучающих данных значительно отличается от обслуживающих данных. Одной из ключевых причин неравномерности распределения является использование совершенно другого корпуса для генерации обучающих данных, чтобы преодолеть недостаток исходных данных в желаемом корпусе. Другая причина — неисправный механизм выборки, который выбирает для обучения только подвыборку обслуживающих данных.
Пример сценария
Информацию о настройке обнаружения перекосов при обслуживании обучения см . в руководстве по началу работы с проверкой данных TensorFlow .
Обнаружение дрейфа
Обнаружение дрейфа поддерживается между последовательными интервалами данных (т. е. между интервалом N и диапазоном N+1), например, между разными днями обучающих данных. Мы выражаем дрейф через расстояние L-бесконечности для категориальных признаков и приблизительное расхождение Дженсена-Шеннона для числовых признаков. Вы можете установить пороговое расстояние, чтобы получать предупреждения, когда смещение превышает допустимое. Установка правильного расстояния обычно представляет собой итеративный процесс, требующий знаний предметной области и экспериментирования.
Информацию о настройке обнаружения дрейфа см. в руководстве по началу работы с проверкой данных TensorFlow .
Использование визуализаций для проверки ваших данных
Проверка данных TensorFlow предоставляет инструменты для визуализации распределения значений функций. Изучая эти распределения в блокноте Jupyter с помощью Facets, вы можете обнаружить типичные проблемы с данными.
Выявление подозрительных дистрибутивов
Вы можете выявить распространенные ошибки в своих данных, используя экран «Обзор фасетов» для поиска подозрительных распределений значений признаков.
Несбалансированные данные
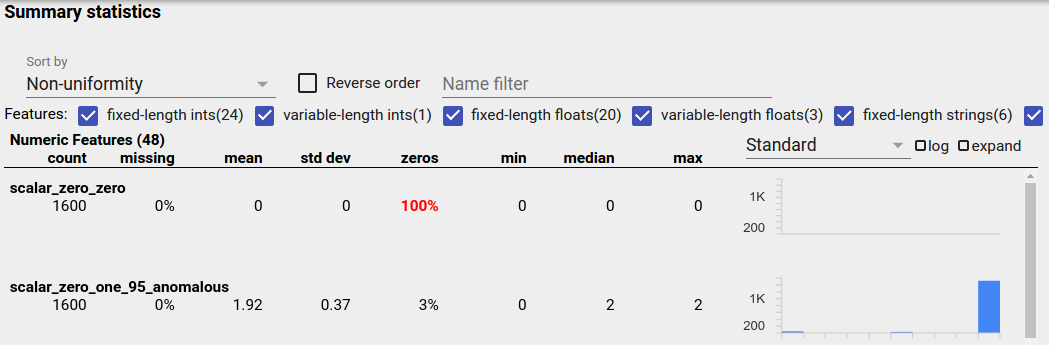
Несбалансированный признак – это признак, у которого преобладает одно значение. Несбалансированные функции могут возникать естественным образом, но если функция всегда имеет одно и то же значение, возможно, возникла ошибка в данных. Чтобы обнаружить несбалансированные функции в обзоре фасетов, выберите «Неоднородность» в раскрывающемся списке «Сортировать по».
Наиболее несбалансированные функции будут перечислены вверху списка каждого типа объектов. Например, на следующем снимке экрана показана одна функция, состоящая только из нулей, и вторая, которая сильно несбалансирована, в верхней части списка «Числовые функции»:
Равномерно распределенные данные
Равномерно распределенный признак — это объект, для которого все возможные значения появляются примерно с одинаковой частотой. Как и в случае с несбалансированными данными, такое распределение может происходить естественным образом, но также может быть вызвано ошибками в данных.
Чтобы обнаружить равномерно распределенные функции в обзоре фасетов, выберите «Неоднородность» в раскрывающемся списке «Сортировать по» и установите флажок «Обратный порядок»:
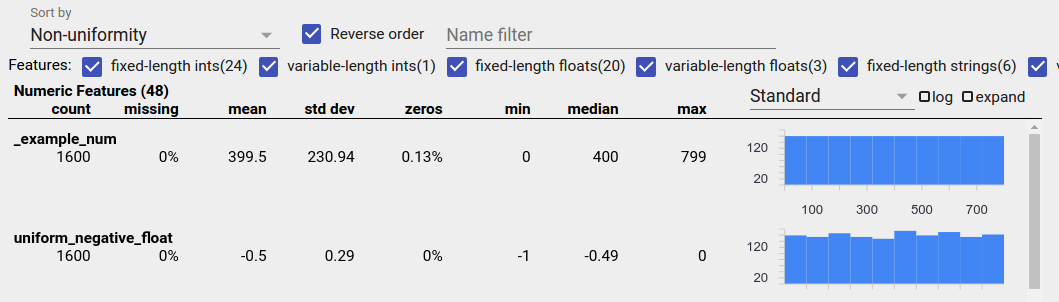
Строковые данные представляются с помощью гистограмм, если имеется 20 или менее уникальных значений, и в виде совокупного графика распределения, если имеется более 20 уникальных значений. Таким образом, для строковых данных равномерное распределение может выглядеть либо в виде плоской гистограммы, как показано выше, либо в виде прямых линий, как показано ниже:

Ошибки, которые могут создавать равномерно распределенные данные
Вот некоторые распространенные ошибки, которые могут привести к созданию равномерно распределенных данных:
Использование строк для представления нестроковых типов данных, таких как даты. Например, у вас будет много уникальных значений для функции даты и времени с такими представлениями, как «2017-03-01-11-45-03». Уникальные значения будут распределены равномерно.
Включение таких индексов, как «номер строки», в качестве функций. И здесь у вас много уникальных ценностей.
Отсутствующие данные
Чтобы проверить, полностью ли отсутствуют значения для объекта:
- В раскрывающемся списке «Сортировать по» выберите «Сумма отсутствует/ноль».
- Установите флажок «Обратный порядок».
- Посмотрите в столбце «отсутствует», чтобы увидеть процент экземпляров с отсутствующими значениями для функции.
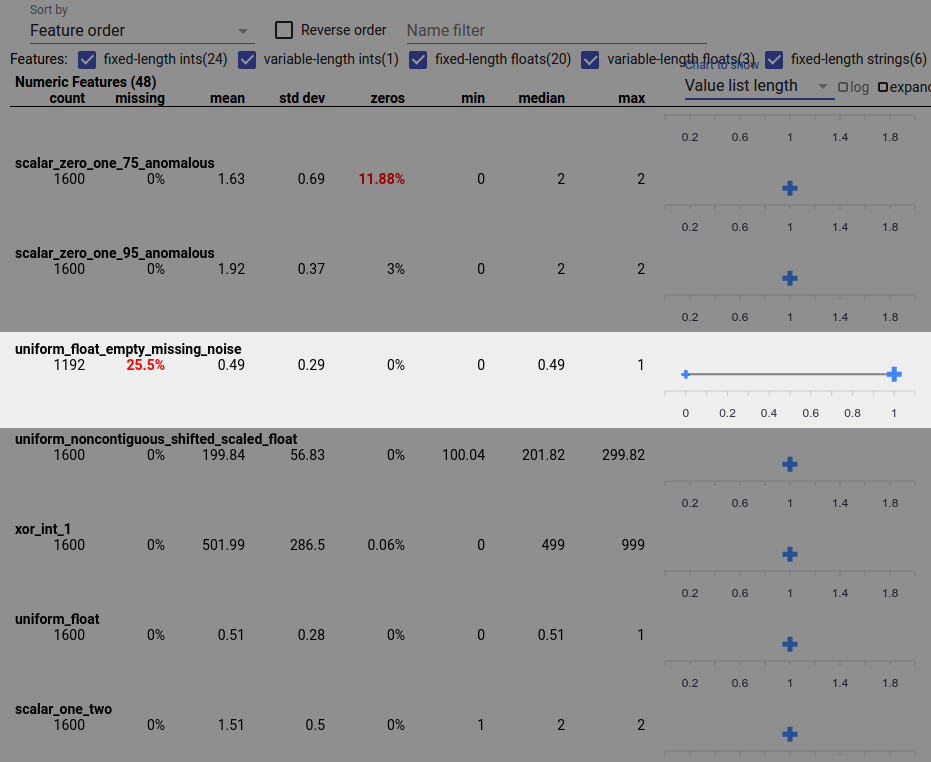
Ошибка данных также может привести к неполным значениям объектов. Например, вы можете ожидать, что список значений функции всегда будет состоять из трех элементов, но обнаружите, что иногда он имеет только один. Чтобы проверить наличие неполных значений или других случаев, когда списки значений функций не содержат ожидаемого количества элементов:
Выберите «Длина списка значений» в раскрывающемся меню «Диаграмма для отображения» справа.
Посмотрите на диаграмму справа от каждой строки функции. На диаграмме показан диапазон длин списка значений для функции. Например, выделенная строка на снимке экрана ниже показывает объект, который имеет списки значений нулевой длины:
Большие различия в масштабах между объектами
Если ваши функции сильно различаются по масштабу, у модели могут возникнуть трудности с обучением. Например, если некоторые функции изменяются от 0 до 1, а другие — от 0 до 1 000 000 000, у вас большая разница в масштабе. Сравните столбцы «Макс» и «Мин» для разных функций, чтобы обнаружить сильно различающиеся масштабы.
Рассмотрите возможность нормализации значений функций, чтобы уменьшить эти широкие различия.
Этикетки с недопустимыми метками
Оценщики TensorFlow имеют ограничения на тип данных, которые они принимают в качестве меток. Например, бинарные классификаторы обычно работают только с метками {0, 1}.
Просмотрите значения меток в обзоре фасетов и убедитесь, что они соответствуют требованиям оценщиков .