
Las canalizaciones TFX le permiten orquestar su flujo de trabajo de aprendizaje automático (ML) en orquestadores, como: Apache Airflow, Apache Beam y Kubeflow Pipelines. Las canalizaciones organizan su flujo de trabajo en una secuencia de componentes, donde cada componente realiza un paso en su flujo de trabajo de ML. Los componentes estándar de TFX brindan una funcionalidad comprobada para ayudarlo a comenzar a crear fácilmente un flujo de trabajo de aprendizaje automático. También puede incluir componentes personalizados en su flujo de trabajo. Los componentes personalizados le permiten ampliar su flujo de trabajo de ML al:
- Crear componentes que se adapten a sus necesidades, como la ingesta de datos de un sistema propietario.
- Aplicar aumento de datos, muestreo ascendente o descendente.
- Realice la detección de anomalías en función de intervalos de confianza o errores de reproducción del codificador automático.
- Interfaz con sistemas externos, como mesas de ayuda, para alertas y monitoreo.
- Aplicar etiquetas a ejemplos sin etiquetar.
- Integrar herramientas creadas con lenguajes distintos de Python en su flujo de trabajo de aprendizaje automático, como realizar análisis de datos utilizando R.
Al combinar componentes estándar y componentes personalizados, puede crear un flujo de trabajo de aprendizaje automático que satisfaga sus necesidades y, al mismo tiempo, aprovechar las mejores prácticas integradas en los componentes estándar de TFX.
Esta guía describe los conceptos necesarios para comprender los componentes personalizados de TFX y las diferentes formas en que puede crear componentes personalizados.
Anatomía de un componente TFX
Esta sección proporciona una descripción general de alto nivel de la composición de un componente TFX. Si es nuevo en las canalizaciones TFX, aprenda los conceptos básicos leyendo la guía para comprender las canalizaciones TFX .
Los componentes TFX se componen de una especificación de componente y una clase ejecutora que están empaquetadas en una clase de interfaz de componente.
Una especificación de componente define el contrato de entrada y salida del componente. Este contrato especifica los artefactos de entrada y salida del componente, y los parámetros que se utilizan para la ejecución del componente.
La clase ejecutora de un componente proporciona la implementación del trabajo realizado por el componente.
Una clase de interfaz de componente combina la especificación del componente con el ejecutor para su uso como componente en una canalización TFX.
Componentes TFX en tiempo de ejecución
Cuando una canalización ejecuta un componente TFX, el componente se ejecuta en tres fases:
- En primer lugar, el controlador utiliza la especificación del componente para recuperar los artefactos necesarios del almacén de metadatos y pasarlos al componente.
- A continuación, el Ejecutor realiza el trabajo del componente.
- Luego, el publicador utiliza la especificación del componente y los resultados del ejecutor para almacenar las salidas del componente en el almacén de metadatos.
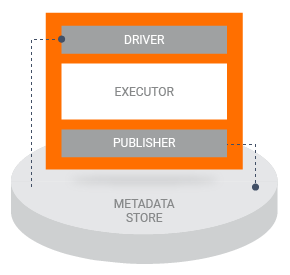
La mayoría de las implementaciones de componentes personalizados no requieren que personalice el controlador o el editor. Normalmente, las modificaciones al controlador y al editor solo deberían ser necesarias si desea cambiar la interacción entre los componentes de su canalización y el almacén de metadatos. Si solo desea cambiar las entradas, salidas o parámetros de su componente, solo necesita modificar la especificación del componente .
Tipos de componentes personalizados
Hay tres tipos de componentes personalizados: componentes basados en funciones de Python, componentes basados en contenedores y componentes totalmente personalizados. Las siguientes secciones describen los diferentes tipos de componentes y los casos en los que se debe utilizar cada enfoque.
Componentes basados en funciones de Python
Los componentes basados en funciones de Python son más fáciles de construir que los componentes basados en contenedores o los componentes totalmente personalizados. La especificación del componente se define en los argumentos de la función de Python mediante anotaciones de tipo que describen si un argumento es un artefacto de entrada, un artefacto de salida o un parámetro. El cuerpo de la función define el ejecutor del componente. La interfaz del componente se define agregando el decorador @component a su función.
Al decorar su función con el decorador @component y definir los argumentos de la función con anotaciones de tipo, puede crear un componente sin la complejidad de crear una especificación de componente, un ejecutor y una interfaz de componente.
Aprenda a crear componentes basados en funciones de Python .
Componentes basados en contenedores
Los componentes basados en contenedores brindan la flexibilidad de integrar código escrito en cualquier idioma en su canalización, siempre que pueda ejecutar ese código en un contenedor Docker. Para crear un componente basado en contenedor, debe crear una imagen de contenedor Docker que contenga el código ejecutable de su componente. Luego debes llamar a la función create_container_component para definir:
- Las entradas, salidas y parámetros de la especificación de su componente.
- La imagen del contenedor y el comando que ejecuta el ejecutor del componente.
Esta función devuelve una instancia de un componente que puede incluir en su definición de canalización.
Este enfoque es más complejo que crear un componente basado en funciones de Python, ya que requiere empaquetar su código como una imagen de contenedor. Este enfoque es más adecuado para incluir código que no sea Python en su canalización o para crear componentes Python con dependencias o entornos de ejecución complejos.
Aprenda a crear componentes basados en contenedores .
Componentes totalmente personalizados
Los componentes totalmente personalizados le permiten crear componentes definiendo la especificación del componente, el ejecutor y las clases de interfaz del componente. Este enfoque le permite reutilizar y ampliar un componente estándar para adaptarlo a sus necesidades.
Si un componente existente está definido con las mismas entradas y salidas que el componente personalizado que está desarrollando, simplemente puede anular la clase Executor del componente existente. Esto significa que puede reutilizar una especificación de componente e implementar un nuevo ejecutor que derive de un componente existente. De esta manera, reutiliza la funcionalidad integrada en los componentes existentes e implementa solo la funcionalidad necesaria.
Sin embargo, si las entradas y salidas de su nuevo componente son únicas, puede definir una especificación de componente completamente nueva.
Este enfoque es mejor para reutilizar las especificaciones y ejecutores de componentes existentes.
Aprenda a crear componentes totalmente personalizados .