
Os pipelines do TFX permitem orquestrar seu fluxo de trabalho de aprendizado de máquina (ML) em orquestradores, como: Apache Airflow, Apache Beam e Kubeflow Pipelines. Os pipelines organizam seu fluxo de trabalho em uma sequência de componentes, em que cada componente executa uma etapa em seu fluxo de trabalho de ML. Os componentes padrão do TFX fornecem funcionalidade comprovada para ajudá-lo a começar a criar um fluxo de trabalho de ML com facilidade. Você também pode incluir componentes personalizados em seu fluxo de trabalho. Os componentes personalizados permitem estender seu fluxo de trabalho de ML:
- Construir componentes personalizados para atender às suas necessidades, como a ingestão de dados de um sistema proprietário.
- Aplicação de aumento de dados, upsampling ou downsampling.
- Execute a detecção de anomalias com base em intervalos de confiança ou erro de reprodução do autoencoder.
- Interface com sistemas externos, como help desks, para alertas e monitoramento.
- Aplicando rótulos a exemplos não rotulados.
- Integrar ferramentas criadas com linguagens diferentes do Python em seu fluxo de trabalho de ML, como realizar análise de dados usando R.
Ao misturar componentes padrão e componentes personalizados, você pode criar um fluxo de trabalho de ML que atenda às suas necessidades enquanto aproveita as melhores práticas incorporadas aos componentes padrão do TFX.
Este guia descreve os conceitos necessários para entender os componentes personalizados do TFX e as diferentes maneiras de criar componentes personalizados.
Anatomia de um componente TFX
Esta seção fornece uma visão geral de alto nível da composição de um componente TFX. Se você é novo nos pipelines do TFX, aprenda os conceitos principais lendo o guia para entender os pipelines do TFX .
Os componentes do TFX são compostos por uma especificação de componente e uma classe de executor que são empacotados em uma classe de interface de componente.
Uma especificação de componente define o contrato de entrada e saída do componente. Este contrato especifica os artefatos de entrada e saída do componente e os parâmetros que são usados para a execução do componente.
A classe executora de um componente fornece a implementação para o trabalho realizado pelo componente.
Uma classe de interface de componente combina a especificação do componente com o executor para uso como um componente em um pipeline do TFX.
Componentes TFX em tempo de execução
Quando um pipeline executa um componente TFX, o componente é executado em três fases:
- Primeiro, o Driver usa a especificação do componente para recuperar os artefatos necessários do repositório de metadados e passá-los para o componente.
- Em seguida, o Executor realiza o trabalho do componente.
- Em seguida, o Publicador usa a especificação do componente e os resultados do executor para armazenar as saídas do componente no repositório de metadados.
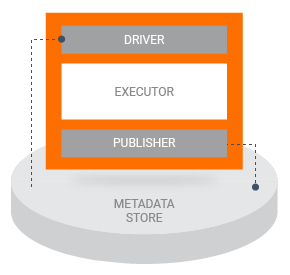
A maioria das implementações de componentes personalizados não exige que você personalize o Driver ou o Publicador. Normalmente, as modificações no Driver e no Publicador devem ser necessárias apenas se você quiser alterar a interação entre os componentes do pipeline e o repositório de metadados. Se você deseja alterar apenas as entradas, saídas ou parâmetros do seu componente, basta modificar a especificação do componente .
Tipos de componentes personalizados
Existem três tipos de componentes personalizados: componentes baseados em função Python, componentes baseados em contêiner e componentes totalmente personalizados. As seções a seguir descrevem os diferentes tipos de componentes e os casos em que você deve usar cada abordagem.
Componentes baseados em função do Python
Os componentes baseados em função do Python são mais fáceis de construir do que os componentes baseados em contêiner ou componentes totalmente personalizados. A especificação do componente é definida nos argumentos da função Python usando anotações de tipo que descrevem se um argumento é um artefato de entrada, um artefato de saída ou um parâmetro. O corpo da função define o executor do componente. A interface do componente é definida adicionando o decorador @component à sua função.
Decorando sua função com o decorador @component e definindo os argumentos da função com anotações de tipo, você pode criar um componente sem a complexidade de construir uma especificação de componente, um executor e uma interface de componente.
Saiba como criar componentes baseados em função do Python .
Componentes baseados em contêiner
Os componentes baseados em contêiner fornecem a flexibilidade de integrar código escrito em qualquer linguagem em seu pipeline, desde que você possa executar esse código em um contêiner do Docker. Para criar um componente baseado em contêiner, você deve criar uma imagem de contêiner do Docker que contenha o código executável do seu componente. Então você deve chamar a função create_container_component para definir:
- As entradas, saídas e parâmetros da especificação do seu componente.
- A imagem do contêiner e o comando que o executor do componente executa.
Essa função retorna uma instância de um componente que você pode incluir em sua definição de pipeline.
Essa abordagem é mais complexa do que criar um componente baseado em função do Python, pois requer o empacotamento de seu código como uma imagem de contêiner. Essa abordagem é mais adequada para incluir código não Python em seu pipeline ou para criar componentes Python com dependências ou ambientes de tempo de execução complexos.
Saiba como criar componentes baseados em contêiner .
Componentes totalmente personalizados
Componentes totalmente personalizados permitem que você crie componentes definindo a especificação do componente, o executor e as classes de interface do componente. Essa abordagem permite reutilizar e estender um componente padrão para atender às suas necessidades.
Se um componente existente for definido com as mesmas entradas e saídas do componente personalizado que você está desenvolvendo, você pode simplesmente substituir a classe Executor do componente existente. Isso significa que você pode reutilizar uma especificação de componente e implementar um novo executor derivado de um componente existente. Dessa forma, você reutiliza a funcionalidade incorporada aos componentes existentes e implementa apenas a funcionalidade necessária.
Se, no entanto, as entradas e saídas de seu novo componente forem exclusivas, você poderá definir uma especificação de componente totalmente nova.
Essa abordagem é melhor para reutilizar especificações e executores de componentes existentes.
Aprenda a construir componentes totalmente personalizados .