
Ringkasan
Pipeline TensorFlow Model Analysis (TFMA) digambarkan sebagai berikut:
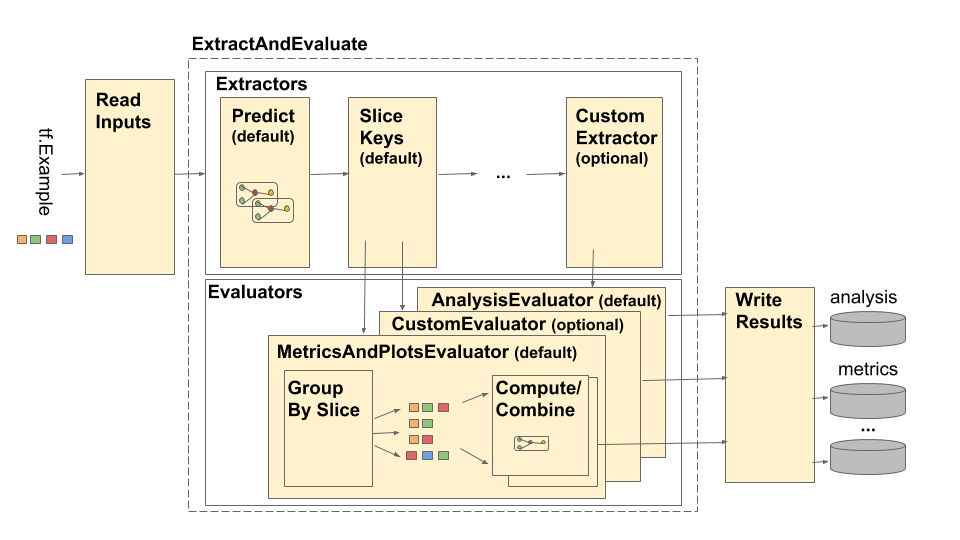
Pipa ini terdiri dari empat komponen utama:
- Baca Masukan
- Ekstraksi
- Evaluasi
- Tulis Hasil
Komponen ini menggunakan dua tipe utama: tfma.Extracts dan tfma.evaluators.Evaluation . Tipe tfma.Extracts mewakili data yang diekstraksi selama pemrosesan pipeline dan mungkin sesuai dengan satu atau lebih contoh model. tfma.evaluators.Evaluation mewakili keluaran dari evaluasi ekstrak di berbagai titik selama proses ekstraksi. Untuk menyediakan API yang fleksibel, tipe ini hanyalah dicts di mana kuncinya ditentukan (dicadangkan untuk digunakan) oleh implementasi yang berbeda. Jenisnya didefinisikan sebagai berikut:
# Extracts represent data extracted during pipeline processing.
# For example, the PredictExtractor stores the data for the
# features, labels, and predictions under the keys "features",
# "labels", and "predictions".
Extracts = Dict[Text, Any]
# Evaluation represents the output from evaluating extracts at
# particular point in the pipeline. The evaluation outputs are
# keyed by their associated output type. For example, the metric / plot
# dictionaries from evaluating metrics and plots will be stored under
# "metrics" and "plots" respectively.
Evaluation = Dict[Text, beam.pvalue.PCollection]
Perhatikan bahwa tfma.Extracts tidak pernah ditulis secara langsung, mereka harus selalu melalui evaluator untuk menghasilkan tfma.evaluators.Evaluation yang kemudian dituliskan. Perhatikan juga bahwa tfma.Extracts adalah dicts yang disimpan dalam beam.pvalue.PCollection (yaitu beam.PTransform s diambil sebagai input beam.pvalue.PCollection[tfma.Extracts] ) sedangkan tfma.evaluators.Evaluation adalah dict yang nilainya adalah beam.pvalue.PCollection s (yaitu beam.PTransform s mengambil dict itu sendiri sebagai argumen untuk input beam.value.PCollection ). Dengan kata lain tfma.evaluators.Evaluation digunakan pada waktu konstruksi pipa, tetapi tfma.Extracts digunakan pada waktu proses pipa.
Baca Masukan
Tahap ReadInputs terdiri dari transformasi yang mengambil input mentah (tf.train.Example, CSV, ...) dan mengubahnya menjadi ekstrak. Saat ini ekstrak direpresentasikan sebagai byte masukan mentah yang disimpan di bawah tfma.INPUT_KEY , namun ekstrak dapat dalam bentuk apa pun yang kompatibel dengan pipa ekstraksi -- artinya ekstrak tersebut membuat tfma.Extracts sebagai keluaran, dan ekstrak tersebut kompatibel dengan downstream ekstraktor. Masing-masing ekstraktor harus mendokumentasikan dengan jelas apa yang mereka perlukan.
Ekstraksi
Proses ekstraksi berupa daftar beam.PTransform yang dijalankan secara seri. Ekstraktor mengambil tfma.Extracts sebagai masukan dan mengembalikan tfma.Extracts sebagai keluaran. Ekstraktor tipikal adalah tfma.extractors.PredictExtractor yang menggunakan ekstrak masukan yang dihasilkan oleh transformasi masukan baca dan menjalankannya melalui model untuk menghasilkan ekstrak prediksi. Ekstraktor yang disesuaikan dapat dimasukkan kapan saja asalkan transformasinya sesuai dengan tfma.Extracts in dan tfma.Extracts out API. Ekstraktor didefinisikan sebagai berikut:
# An Extractor is a PTransform that takes Extracts as input and returns
# Extracts as output. A typical example is a PredictExtractor that receives
# an 'input' placeholder for input and adds additional 'predictions' extracts.
Extractor = NamedTuple('Extractor', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Extracts -> Extracts
Ekstraktor Masukan
tfma.extractors.InputExtractor digunakan untuk mengekstrak fitur mentah, label mentah, dan bobot contoh mentah dari catatan tf.train.Example untuk digunakan dalam pemotongan dan penghitungan metrik. Secara default, nilai masing-masing disimpan di bawah kunci ekstrak features , labels , dan example_weights . Label model keluaran tunggal dan contoh bobot disimpan langsung sebagai nilai np.ndarray . Label model multi-output dan contoh bobot disimpan sebagai dikt nilai np.ndarray (dikunci berdasarkan nama output). Jika evaluasi multi-model dilakukan, label dan contoh bobot akan disematkan lebih lanjut dalam dict lain (dikunci berdasarkan nama model).
PredictExtractor
tfma.extractors.PredictExtractor menjalankan prediksi model dan menyimpannya di bawah predictions utama dalam dikt tfma.Extracts . Prediksi model keluaran tunggal disimpan langsung sebagai nilai keluaran yang diprediksi. Prediksi model multi-output disimpan sebagai dikt nilai output (dikunci berdasarkan nama output). Jika evaluasi multi-model dilakukan, prediksi akan selanjutnya tertanam dalam dikt lain (dikunci berdasarkan nama model). Nilai output aktual yang digunakan bergantung pada model (misalnya, output pengembalian estimator TF dalam bentuk dict sedangkan keras mengembalikan nilai np.ndarray ).
Ekstraktor SliceKey
tfma.extractors.SliceKeyExtractor menggunakan spesifikasi slicing untuk menentukan irisan mana yang berlaku untuk setiap contoh input berdasarkan fitur yang diekstraksi dan menambahkan nilai slicing yang sesuai ke ekstrak untuk digunakan nanti oleh evaluator.
Evaluasi
Evaluasi adalah proses mengambil ekstrak dan mengevaluasinya. Meskipun evaluasi dilakukan pada akhir jalur ekstraksi, terdapat kasus penggunaan yang memerlukan evaluasi lebih awal dalam proses ekstraksi. Oleh karena itu, evaluator berhubungan dengan ekstraktor yang keluarannya harus dievaluasi. Seorang evaluator didefinisikan sebagai berikut:
# An evaluator is a PTransform that takes Extracts as input and
# produces an Evaluation as output. A typical example of an evaluator
# is the MetricsAndPlotsEvaluator that takes the 'features', 'labels',
# and 'predictions' extracts from the PredictExtractor and evaluates
# them using post export metrics to produce metrics and plots dictionaries.
Evaluator = NamedTuple('Evaluator', [
('stage_name', Text),
('run_after', Text), # Extractor.stage_name
('ptransform', beam.PTransform)]) # Extracts -> Evaluation
Perhatikan bahwa evaluator adalah beam.PTransform yang menggunakan tfma.Extracts sebagai input. Tidak ada yang menghentikan implementasi untuk melakukan transformasi tambahan pada ekstrak sebagai bagian dari proses evaluasi. Tidak seperti ekstraktor yang harus mengembalikan dict tfma.Extracts , tidak ada batasan pada jenis output yang dapat dihasilkan oleh evaluator meskipun sebagian besar evaluator juga mengembalikan dict (misalnya nama dan nilai metrik).
MetricsAndPlotsEvaluator
tfma.evaluators.MetricsAndPlotsEvaluator mengambil features , labels , dan predictions sebagai masukan, menjalankannya melalui tfma.slicer.FanoutSlices untuk mengelompokkannya berdasarkan irisan, lalu melakukan penghitungan metrik dan plot. Ini menghasilkan output dalam bentuk kamus metrik dan plot kunci dan nilai (ini kemudian dikonversi ke proto serial untuk output oleh tfma.writers.MetricsAndPlotsWriter ).
Tulis Hasil
Tahap WriteResults adalah tempat keluaran evaluasi ditulis ke disk. WriteResults menggunakan penulis untuk menulis data berdasarkan kunci keluaran. Misalnya, tfma.evaluators.Evaluation mungkin berisi kunci untuk metrics dan plots . Ini kemudian akan dikaitkan dengan kamus metrik dan plot yang disebut 'metrik' dan 'plot'. Penulis menentukan cara menulis setiap file:
# A writer is a PTransform that takes evaluation output as input and
# serializes the associated PCollections of data to a sink.
Writer = NamedTuple('Writer', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Evaluation -> PDone
Penulis Metrik dan Plot
Kami menyediakan tfma.writers.MetricsAndPlotsWriter yang mengonversi kamus metrik dan plot menjadi proto berseri dan menulisnya ke disk.
Jika Anda ingin menggunakan format serialisasi yang berbeda, Anda dapat membuat penulis khusus dan menggunakannya. Karena tfma.evaluators.Evaluation yang diteruskan ke penulis berisi output untuk semua evaluator yang digabungkan, transformasi pembantu tfma.writers.Write disediakan yang dapat digunakan penulis dalam implementasi ptransform mereka untuk memilih beam.PCollection yang sesuai.PCollection berdasarkan pada kunci keluaran (lihat contoh di bawah).
Kustomisasi
Metode tfma.run_model_analysis menggunakan argumen extractors , evaluators , dan writers untuk menyesuaikan ekstraktor, evaluator, dan penulis yang digunakan oleh pipeline. Jika tidak ada argumen yang diberikan maka tfma.default_extractors , tfma.default_evaluators , dan tfma.default_writers digunakan secara default.
Ekstraktor Khusus
Untuk membuat ekstraktor khusus, buat tipe tfma.extractors.Extractor yang membungkus beam.PTransform dengan mengambil tfma.Extracts sebagai masukan dan mengembalikan tfma.Extracts sebagai keluaran. Contoh ekstraktor tersedia di tfma.extractors .
Evaluator Khusus
Untuk membuat evaluator khusus, buat tipe tfma.evaluators.Evaluator yang membungkus beam.PTransform dengan mengambil tfma.Extracts sebagai input dan mengembalikan tfma.evaluators.Evaluation sebagai output. Evaluator yang sangat mendasar mungkin hanya mengambil tfma.Extracts yang masuk dan mengeluarkannya untuk disimpan dalam sebuah tabel. Inilah yang dilakukan oleh tfma.evaluators.AnalysisTableEvaluator . Evaluator yang lebih rumit mungkin melakukan pemrosesan tambahan dan agregasi data. Lihat tfma.evaluators.MetricsAndPlotsEvaluator sebagai contoh.
Perhatikan bahwa tfma.evaluators.MetricsAndPlotsEvaluator itu sendiri dapat disesuaikan untuk mendukung metrik khusus (lihat metrik untuk detail selengkapnya).
Penulis Kustom
Untuk membuat penulis kustom, buat tipe tfma.writers.Writer yang membungkus beam.PTransform dengan mengambil tfma.evaluators.Evaluation sebagai input dan mengembalikan beam.pvalue.PDone sebagai output. Berikut ini adalah contoh dasar seorang penulis untuk menulis TFRecords yang berisi metrik:
tfma.writers.Writer(
stage_name='WriteTFRecord(%s)' % tfma.METRICS_KEY,
ptransform=tfma.writers.Write(
key=tfma.METRICS_KEY,
ptransform=beam.io.WriteToTFRecord(file_path_prefix=output_file))
Masukan penulis bergantung pada keluaran evaluator terkait. Untuk contoh di atas, outputnya adalah proto serial yang dihasilkan oleh tfma.evaluators.MetricsAndPlotsEvaluator . Seorang penulis untuk tfma.evaluators.AnalysisTableEvaluator akan bertanggung jawab untuk menulis beam.pvalue.PCollection dari tfma.Extracts .
Perhatikan bahwa penulis dikaitkan dengan keluaran evaluator melalui kunci keluaran yang digunakan (misalnya tfma.METRICS_KEY , tfma.ANALYSIS_KEY , dll).
Contoh Langkah demi Langkah
Berikut ini adalah contoh langkah-langkah yang terlibat dalam alur ekstraksi dan evaluasi ketika tfma.evaluators.MetricsAndPlotsEvaluator dan tfma.evaluators.AnalysisTableEvaluator digunakan:
run_model_analysis(
...
extractors=[
tfma.extractors.InputExtractor(...),
tfma.extractors.PredictExtractor(...),
tfma.extractors.SliceKeyExtrator(...)
],
evaluators=[
tfma.evaluators.MetricsAndPlotsEvaluator(...),
tfma.evaluators.AnalysisTableEvaluator(...)
])
ReadInputs
# Out
Extracts {
'input': bytes # CSV, Proto, ...
}
ExtractAndEvaluate
# In: ReadInputs Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
}
# In: InputExtractor Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
}
# In: PredictExtractor Extracts
# Out:
Extracts {
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
'slice_key': Tuple[bytes...] # Slice
}
tfma.evaluators.MetricsAndPlotsEvaluator(run_after:SLICE_KEY_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
}
tfma.evaluators.AnalysisTableEvaluator(run_after:LAST_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'analysis': PCollection[Extracts] # Final Extracts
}
WriteResults
# In:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
'analysis': PCollection[Extracts] # Final Extracts
}
# Out: metrics, plots, and analysis files