
概要
TensorFlow モデル分析 (TFMA) パイプラインは次のように表されます。
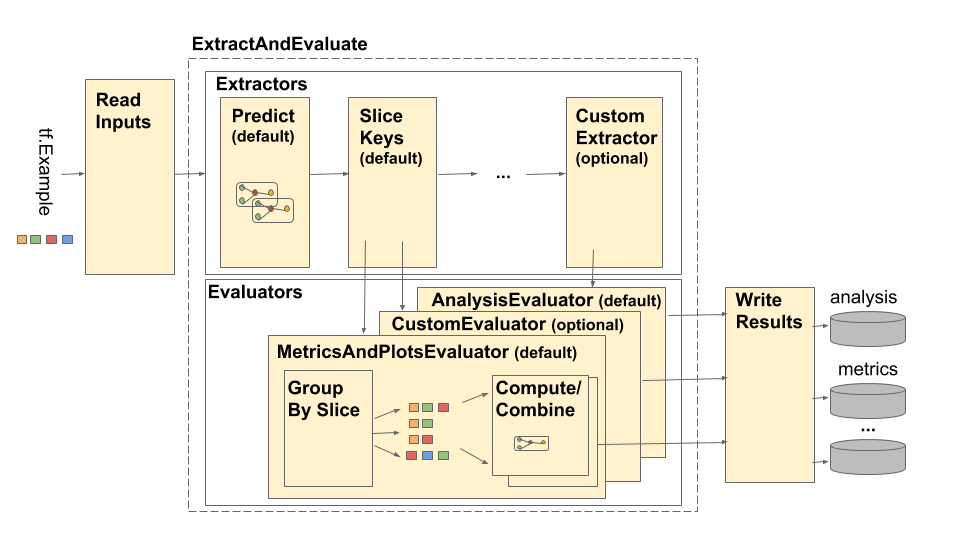
パイプラインは 4 つの主要コンポーネントで構成されます。
- 入力の読み取り
- 抽出
- 評価
- 結果の書き込み
これらのコンポーネントは、 tfma.Extractsとtfma.evaluators.Evaluationという 2 つの主要なタイプを使用します。 tfma.Extracts型は、パイプライン処理中に抽出されるデータを表し、モデルの 1 つ以上の例に対応する可能性があります。 tfma.evaluators.Evaluation 、抽出プロセス中のさまざまな時点での抽出の評価からの出力を表します。柔軟な API を提供するために、これらの型は、さまざまな実装によってキーが定義される (使用するために予約される) 単なる辞書です。タイプは次のように定義されます。
# Extracts represent data extracted during pipeline processing.
# For example, the PredictExtractor stores the data for the
# features, labels, and predictions under the keys "features",
# "labels", and "predictions".
Extracts = Dict[Text, Any]
# Evaluation represents the output from evaluating extracts at
# particular point in the pipeline. The evaluation outputs are
# keyed by their associated output type. For example, the metric / plot
# dictionaries from evaluating metrics and plots will be stored under
# "metrics" and "plots" respectively.
Evaluation = Dict[Text, beam.pvalue.PCollection]
tfma.Extractsは直接書き出されることはなく、常にエバリュエーターを経由してtfma.evaluators.Evaluationを生成し、それが書き出される必要があることに注意してください。また、 tfma.Extractsはbeam.pvalue.PCollectionに格納される dict であることにも注意してください (つまり、 beam.PTransformは入力beam.pvalue.PCollection[tfma.Extracts]を受け取ります)。一方、 tfma.evaluators.Evaluationはその値を含む dict です。は、 beam.pvalue.PCollectionです (つまり、 beam.PTransformは、dict 自体をbeam.value.PCollection入力の引数として受け取ります)。つまり、 tfma.evaluators.Evaluationはパイプライン構築時に使用されますが、 tfma.Extractsはパイプライン実行時に使用されます。
入力の読み取り
ReadInputsステージは、生の入力 (tf.train.Example、CSV など) を受け取り、それらを抽出に変換する変換で構成されます。現在、抽出はtfma.INPUT_KEYに保存された生の入力バイトとして表されますが、抽出は抽出パイプラインと互換性のある任意の形式にすることができます。つまり、出力としてtfma.Extractsが作成され、それらの抽出はダウンストリームと互換性があります。抽出器。必要なものを明確に文書化するかどうかは、さまざまな抽出者の責任です。
抽出
抽出プロセスは、連続して実行されるbeam.PTransformのリストです。エクストラクターはtfma.Extractsを入力として受け取り、 tfma.Extractsを出力として返します。プロトタイプのエクストラクターはtfma.extractors.PredictExtractorです。これは、読み取り入力変換によって生成された入力抽出を使用し、それをモデルを通して実行して予測抽出を生成します。カスタマイズされたエクストラクターは、その変換がtfma.Extracts in およびtfma.Extracts out API に準拠していれば、いつでも挿入できます。エクストラクターは次のように定義されます。
# An Extractor is a PTransform that takes Extracts as input and returns
# Extracts as output. A typical example is a PredictExtractor that receives
# an 'input' placeholder for input and adds additional 'predictions' extracts.
Extractor = NamedTuple('Extractor', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Extracts -> Extracts
入力抽出器
tfma.extractors.InputExtractorは、メトリクスのスライスと計算で使用するために、 tf.train.Exampleレコードから生の特徴、生のラベル、および生のサンプルの重みを抽出するために使用されます。デフォルトでは、値はそれぞれ抽出キーfeatures 、 labels 、 example_weightsの下に保存されます。単一出力モデルのラベルとサンプルの重みは、 np.ndarray値として直接保存されます。複数出力モデルのラベルと重みの例は、 np.ndarray値の辞書として保存されます (出力名でキー設定)。マルチモデル評価が実行される場合、ラベルとサンプルの重みは別の dict (モデル名でキー設定) 内にさらに埋め込まれます。
予測抽出
tfma.extractors.PredictExtractorモデル予測を実行し、それらをtfma.Extracts dict のキーpredictionsの下に保存します。単一出力モデルの予測は、予測出力値として直接保存されます。複数出力モデルの予測は、出力値の辞書として保存されます (出力名によってキー設定されます)。マルチモデル評価が実行される場合、予測は別の辞書 (モデル名でキー設定) 内にさらに埋め込まれます。使用される実際の出力値はモデルによって異なります (たとえば、TF 推定器は dict の形式で出力を返しますが、keras はnp.ndarray値を返します)。
スライスキーエクストラクタ
tfma.extractors.SliceKeyExtractorは、スライス仕様を使用して、抽出された特徴に基づいて各入力例に適用されるスライスを決定し、評価者が後で使用できるように、対応するスライス値を抽出に追加します。
評価
評価は、抽出してそれを評価するプロセスです。抽出パイプラインの最後に評価を実行するのが一般的ですが、抽出プロセスの早い段階で評価を必要とするユースケースもあります。そのため、エバリュエーターは、出力を評価する必要があるエクストラクターに関連付けられます。評価者は次のように定義されます。
# An evaluator is a PTransform that takes Extracts as input and
# produces an Evaluation as output. A typical example of an evaluator
# is the MetricsAndPlotsEvaluator that takes the 'features', 'labels',
# and 'predictions' extracts from the PredictExtractor and evaluates
# them using post export metrics to produce metrics and plots dictionaries.
Evaluator = NamedTuple('Evaluator', [
('stage_name', Text),
('run_after', Text), # Extractor.stage_name
('ptransform', beam.PTransform)]) # Extracts -> Evaluation
エバリュエーターはtfma.Extractsを入力として受け取るbeam.PTransformであることに注意してください。実装が評価プロセスの一環として抽出に対して追加の変換を実行することを妨げるものはありません。 tfma.Extracts dict を返さなければならないエクストラクターとは異なり、ほとんどのエバリュエーターは dict (メトリック名と値など) も返しますが、エバリュエーターが生成できる出力のタイプに制限はありません。
メトリックとプロット評価者
tfma.evaluators.MetricsAndPlotsEvaluatorは、 features 、 labels 、およびpredictions入力として受け取り、それらをtfma.slicer.FanoutSlicesで実行してスライスごとにグループ化し、メトリックとプロットの計算を実行します。メトリクスのディクショナリの形式で出力を生成し、キーと値をプロットします (これらは後でtfma.writers.MetricsAndPlotsWriterによる出力用にシリアル化されたプロトに変換されます)。
結果の書き込み
WriteResultsステージでは、評価出力がディスクに書き出されます。 WriteResults はライターを使用して、出力キーに基づいてデータを書き込みます。たとえば、 tfma.evaluators.Evaluationには、 metricsとplotsのキーが含まれる場合があります。これらは、「メトリクス」および「プロット」と呼ばれるメトリクスおよびプロットの辞書に関連付けられます。作成者は、各ファイルの書き出し方法を指定します。
# A writer is a PTransform that takes evaluation output as input and
# serializes the associated PCollections of data to a sink.
Writer = NamedTuple('Writer', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Evaluation -> PDone
メトリクスとプロットライター
メトリクスとプロットの辞書をシリアル化されたプロトに変換し、ディスクに書き込むtfma.writers.MetricsAndPlotsWriterが提供されています。
別のシリアル化形式を使用したい場合は、カスタム ライターを作成し、それを代わりに使用できます。ライターに渡されるtfma.evaluators.Evaluationには、結合されたすべてのエバリュエーターの出力がbeam.PCollectionれるため、ライターがptransform実装で使用できるtfma.writers.Writeヘルパー変換が提供され、出力キー (以下の例を参照)。
カスタマイズ
tfma.run_model_analysisメソッドは、パイプラインで使用されるエクストラクター、エバリュエーター、およびライターをカスタマイズするためのextractors 、 evaluators 、およびwriters引数を受け取ります。引数が指定されていない場合は、 tfma.default_extractors 、 tfma.default_evaluators 、およびtfma.default_writersがデフォルトで使用されます。
カスタムエクストラクター
カスタム エクストラクターを作成するには、 tfma.Extractsを入力として受け取り、 tfma.Extractsを出力として返すbeam.PTransformをラップするtfma.extractors.Extractor型を作成します。エクストラクターの例は、 tfma.extractorsで入手できます。
カスタムエバリュエーター
カスタム エバリュエーターを作成するには、 tfma.Extractsを入力として受け取り、 tfma.evaluators.Evaluationを出力として返すbeam.PTransformをラップするtfma.evaluators.Evaluator型を作成します。非常に基本的なエバリュエーターは、単に受信したtfma.Extractsを受け取り、テーブルに格納するために出力する可能性があります。これはまさにtfma.evaluators.AnalysisTableEvaluatorが行うことです。より複雑なエバリュエーターでは、追加の処理とデータ集計が実行される場合があります。例としてtfma.evaluators.MetricsAndPlotsEvaluatorを参照してください。
tfma.evaluators.MetricsAndPlotsEvaluator自体は、カスタム メトリクスをサポートするようにカスタマイズできることに注意してください (詳細については、 「メトリクス」を参照)。
カスタムライター
カスタム ライターを作成するには、 tfma.evaluators.Evaluationを入力として受け取り、 beam.pvalue.PDoneを出力として返すbeam.PTransformをラップするtfma.writers.Writer型を作成します。以下は、メトリクスを含む TFRecord を書き出すためのライターの基本的な例です。
tfma.writers.Writer(
stage_name='WriteTFRecord(%s)' % tfma.METRICS_KEY,
ptransform=tfma.writers.Write(
key=tfma.METRICS_KEY,
ptransform=beam.io.WriteToTFRecord(file_path_prefix=output_file))
ライターの入力は、関連する評価者の出力に依存します。上記の例の場合、出力はtfma.evaluators.MetricsAndPlotsEvaluatorによって生成されたシリアル化されたプロトです。 tfma.evaluators.AnalysisTableEvaluatorのライターは、 tfma.Extractsのbeam.pvalue.PCollectionを書き出す責任があります。
ライターは、使用される出力キー ( tfma.METRICS_KEY 、 tfma.ANALYSIS_KEYなど) を介して評価器の出力に関連付けられることに注意してください。
ステップバイステップの例
以下は、 tfma.evaluators.MetricsAndPlotsEvaluatorとtfma.evaluators.AnalysisTableEvaluatorの両方が使用される場合の、抽出および評価パイプラインに含まれるステップの例です。
run_model_analysis(
...
extractors=[
tfma.extractors.InputExtractor(...),
tfma.extractors.PredictExtractor(...),
tfma.extractors.SliceKeyExtrator(...)
],
evaluators=[
tfma.evaluators.MetricsAndPlotsEvaluator(...),
tfma.evaluators.AnalysisTableEvaluator(...)
])
ReadInputs
# Out
Extracts {
'input': bytes # CSV, Proto, ...
}
ExtractAndEvaluate
# In: ReadInputs Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
}
# In: InputExtractor Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
}
# In: PredictExtractor Extracts
# Out:
Extracts {
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
'slice_key': Tuple[bytes...] # Slice
}
tfma.evaluators.MetricsAndPlotsEvaluator(実行後:SLICE_KEY_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
}
tfma.evaluators.AnalysisTableEvaluator(実行後:LAST_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'analysis': PCollection[Extracts] # Final Extracts
}
WriteResults
# In:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
'analysis': PCollection[Extracts] # Final Extracts
}
# Out: metrics, plots, and analysis files